2017-2018-2 1723《程序设计与数据结构》问题汇总 (更新完毕)
主目录
第 00 周 - 预备作业 03 问题与解答
-
【问题1】关于markdown格式,有些同学的markdown中的标题没有对齐,评论了之后也没有修改,如下图:

- 解答 :这种排版错误,有两种情况:
① 上一部分的内容与下一个标题之间没有空行,由于使用了-修饰文字,导致后面标题与前面的内容连在一起,原格式如下:
## 1. 虚拟机的安装
- XXXXXX
## 2. Linux命令
- XXXXXX
## 3. 感悟
- XXXXXX
效果如下:
1. 虚拟机的安装
- XXXXXX
2. Linux命令
- XXXXXX
3. 感悟
- XXXXXX
② 空行了但是下一行的前面空了四格,出现这种错误的同学应该不多,原格式如下:
## 1. 虚拟机的安装
- XXXXXX
## 2. Linux命令 //##前面空了四格
- XXXXXX
## 3. 感悟
- XXXXXX
效果如下:
1. 虚拟机的安装
-
XXXXXX
2. Linux命令
-
XXXXXX
3. 感悟
-
XXXXXX
建议将原格式修改为:
## 1. 虚拟机的安装
- XXXXXX
## 2. Linux命令
- XXXXXX
## 3. 感悟
- XXXXXX
当然如果标题格式前面空了1~3格或者5格以上,也不会有修饰效果,可以自己尝试一下,所以标题修饰符前面不要加空格,各部分之间加几个空行,原格式看着也比较舒展,markdown格式需要同学们在以后的作业中慢慢体会,从一篇博客的markdown就可以看出对待博客的态度!
-
【问题2】安装虚拟机时,ubuntu只有32位的选项,而没有像流程中的那样有64位的选项。在建立32位ubuntu时显示:
This kernel requires an x86-64 CPU,but only detected an i686 CPU.Unable to boot - please use a kernel appropriate for your CPU.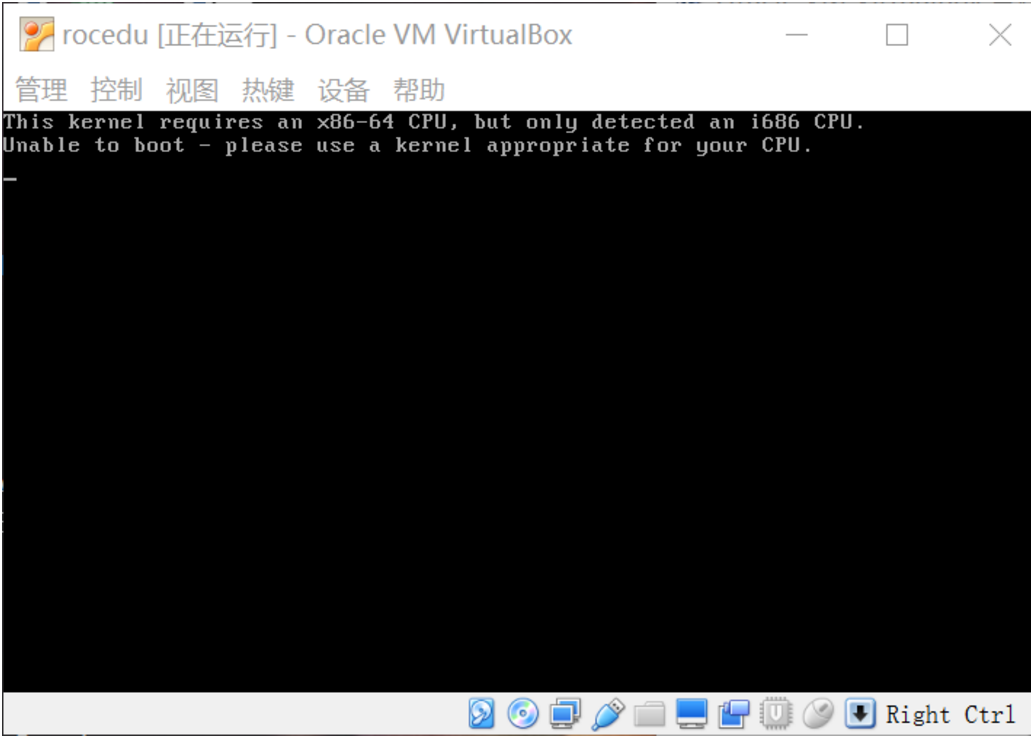
-
解答 :在安装虚拟机时选择的是32位的,且没有打开intel vt-x(虚拟化技术),i686是intel系列的CPU,是32位的,所以会提示这个问题。intel vt-x的好处就是可以在32位的机器上虚拟出64位操作系统。修改BIOS配置,把virtualization参数改为enable即可:

关于如何修改
Inter Virtual Technology,可以参考OracleVMVirtualBox不能创建64位的虚拟机办法,也可以参考这篇博客再了解一下。
-
【问题3】在安装Ubuntu的时候打开教程里给的网址到最后下载的时候网页总是显示
404 Not Found。
-
解答 :戳此链接去Ubuntu的中文官网下的系统软件,可以下载Ubuntu 16.04 LTS(长期支持)版本或者Ubuntu 17.04版本。
-
【问题4】使用
sudo apt-get install Vim来安装Vim的时候出现问题:E: 无法定位软件包
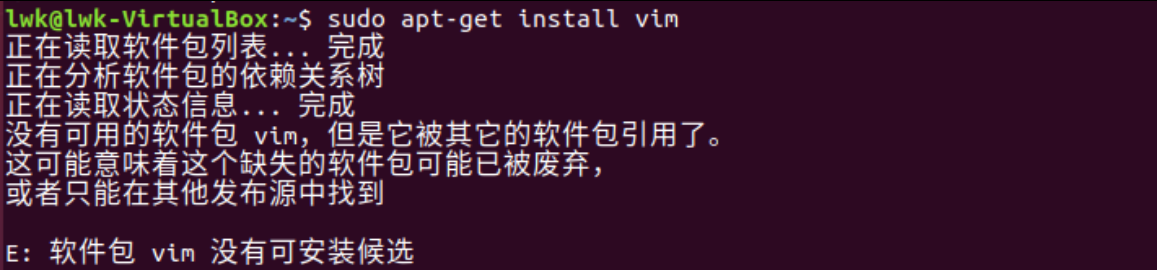
-
解答 :无法定位软件包,主要是软件源的问题(被封了,或者失效了),可以先使用
sudo apt-get update更新,或者可以使用下面的命令更新,但是要注意路径。
etc/apt/source.list中更新软件源:sudo gedit /etc/apt/source.list
- 【问题5】在下载好了VirtualBox后装Ubuntu系统的时候,运行到一半突然弹出错误提示框:
Host system reported disk full. VM execution is suspended. You can resume after freeing some space.
-
解答 :电脑的磁盘文件类型是FAT32文件格式,而在FAT32下,单个文件的最大是4GB,不支持超过4GB的文件。NTFS和FAT32都是文件系统的一种,而NTFS相对FAT32推出的要晚,所以技术也就更先进,但是对于早期的系统,比如Windows95的支持,FAT32要更好,具体的区别有下面几点:
- NTFS可以支持最大64G的单个文件和2048G的分区。FAT32支持最大4G的单个文件和32G的分区。
- NTFS不需要整理磁盘碎片。
- NTFS支持对分区、文件夹和文件的压缩。
- NTFS采用更小的簇,能更有效地管理硬盘空间,最大限度的避免磁盘空间浪费。
- NTFS分区上,可以为共享资源、文件夹和文件设置访问许可权限。比FAT32安全性要高很多。而且基于NTFS的WIN 2000/XP运行要快于基于FAT32的WIN 2000/XP;但在WIN 9X系统的兼容性方面,FAT32优于NTFS。
把文件系统从FAT32升级到NTFS即可:
> 1.单击开始→运行。
2.打开窗口以后,在光标的提示符下输入“convert X:/FS:NTFS”,然后回车。注意在“convert”的后面有一个空格。
3.接着系统会要求你输入X盘的卷标,然后回车。(卷标在“我的电脑”中点X盘,然后看它的属性可以找到。)工作界面这样就可简单地转换分区格式为NTFS了。这个方法只用于FAT32转为NTFS,不能将NTFS转为FAT32
4.重启电脑,虚拟机的安装问题得以解决。
(引用自[余坤澎同学的博客](http://www.cnblogs.com/yu-kunpeng/p/8459098.html))
- 其他问题详见答疑论坛:https://group.cnblogs.com/pdds/
第 01 周 - 作业问题与解答
-
【问题1】上传到码云发现自己的文件位置不理想,想要修改就删掉了码云上已上传的文件,导致远程和本地不同步,使得上传出现问题。
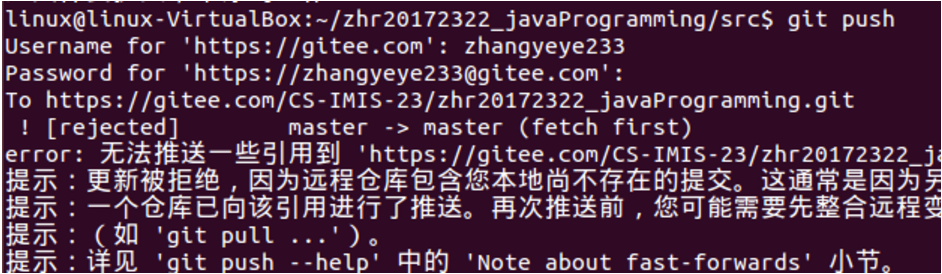
-
解答 :将本地(虚拟机上)同名文件删除,git pull 然后可继续上传。
-
【问题2】安装插件时出现:无法获得锁 /var/lib/dpkg/lock -open (11: 资源暂时不可用)。
-
解答 :参考ubuntu 解决“无法获得锁 /var/lib/dpkg/lock -open”的方法
解决办法如下:
1、终端输入 ps aux ,列出进程。找到含有apt-get的进程,直接sudo kill PID。
2、强制解锁,命令
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lock
- 此后若想重新安装则可输入
sudo apt-get install XXX, 但此时又可能会提示 “E: dpkg 被中断,您必须手工运行 sudo dpkg --configure -a 解决此问题”, 手工输入 " sudo dpkg --configure -a" 后,若又出现 “依赖关系问题 - 仍未被配置”这一提示的话,直接运行 “sudo apt-get -f install” 即可。
-
【问题3】用
sudo apt-get install atom安装atom时软件包无法定位

-
解答 :输入sudo add-apt-repository ppa:webupd8team/atom
按一下回车键,等待一会儿后
sudo apt-get update,之后sudo apt-get install atom等待安装即可。
-
【问题4】脚本文件设置好以后无法打开。

-
解答 :参考:http://www.cnblogs.com/hester/p/5575658.html
chmod命令用来改变文件的模式,给系统中所有用户这个源文件的执行许可。
然后我们可以直接通过指定源文件的位置来执行程序。
我们使用./来指示程序位于当前目录。
【附】如果用"./"+"脚本名"命令不能执行shell脚本,可以试试换用 bash 脚本名 执行。
-
【问题5】虚拟机突然打不开,错误问题提示“不能打开一个新任务”。
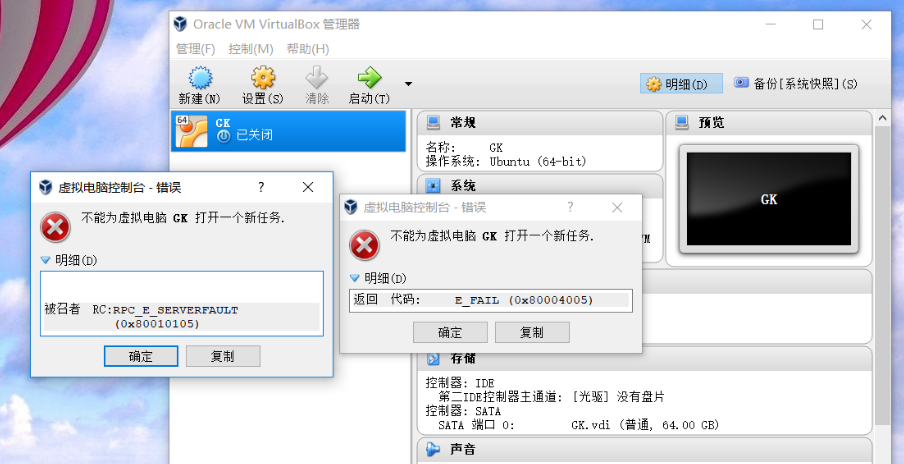
-
解答 :那是因为vboxdrv服务没有安装或没有成功启动,找到安装目录下的vboxdrv文件夹,如D:\Program\Files\Oracle\VirtualBox\drivers\vboxdrv,右击VBoxDrv.inf,选安装,然后重启。重新安装多次后仍然提示打开错误,并且尝试过兼容模式运行,管理员身份运行,重新安装VBoxDrv.inf,或者可以去官网重新安装的最新版的5.2.6的版本,实测有效果。(下载地址:https://www.virtualbox.org/wiki/Downloads)
如果还是不行,卸载virtualbox,选择下载vmware。
-
【问题6】编写好的东西push不上去。
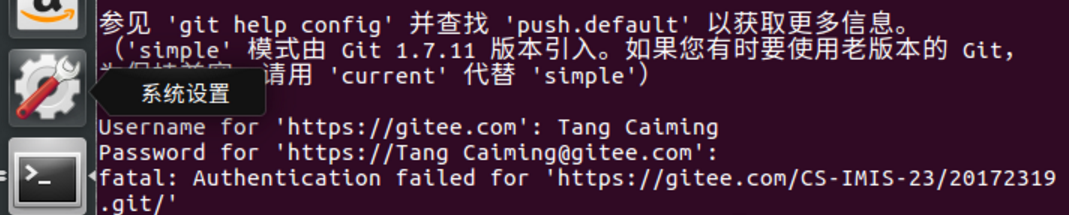
-
解答 :参考:http://blog.csdn.net/Lea__DongYang/article/details/78134882 ,重新执行git config命令配置用户名和邮箱即可。
-
【问题7】和问题一有些相似,关于git push上传失败:
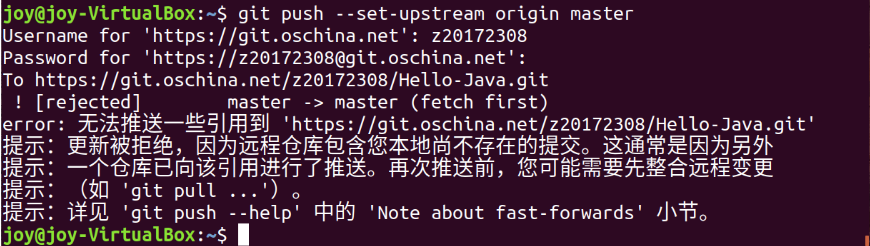
-
解答 :在码云新建过项目后复制链接到电脑本地git clone之后会在相应目录下自动创建一个和项目名称相同的目录,要进入项目名称目录下上传文件,git push才不会显示当前分支没有对应的上游分支,并且上传成功。
-
【问题8】如何实现“虚拟机”和“物理机”直接的复制粘贴?
-
解答 :参考:https://jingyan.baidu.com/article/cbf0e500f88a4f2eaa289338.html
或者按照以下这种方式设置:
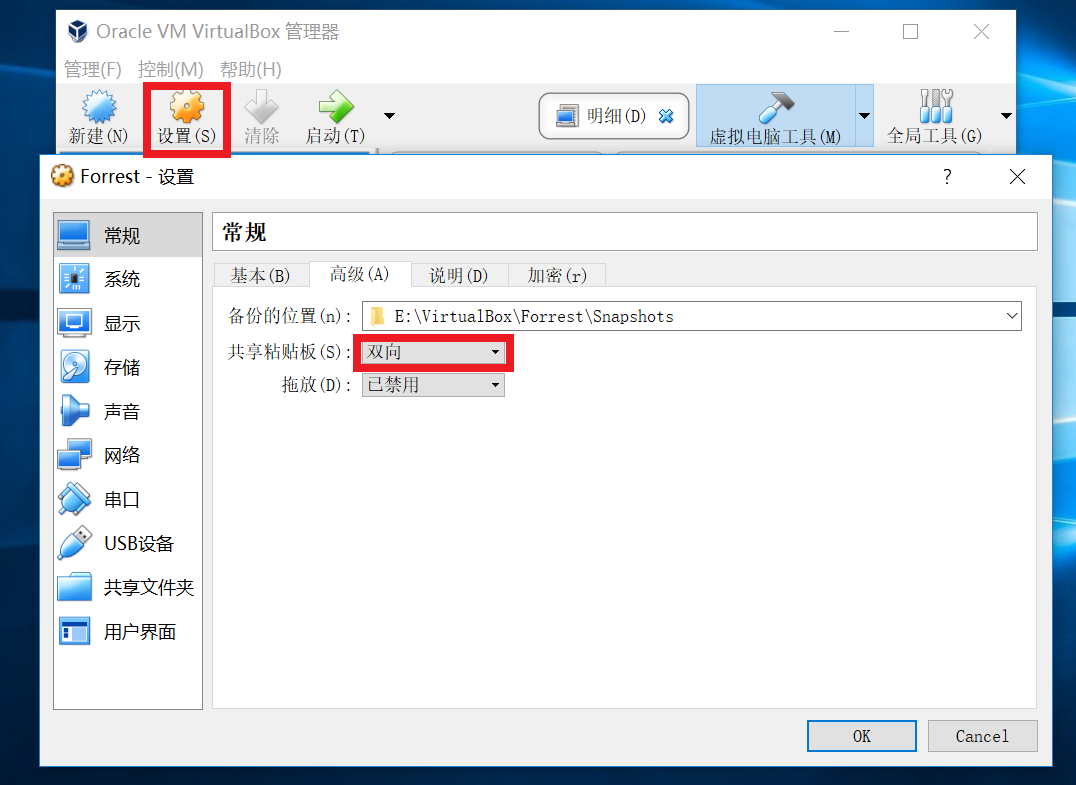
- 其他问题详见答疑论坛:https://group.cnblogs.com/pdds/
第 02 周 - 作业问题与解答
-
【问题1】在做PP2.4时觉得输入的代码没有问题,但是为什么有一行的输入会出现,但是不能输入呢?
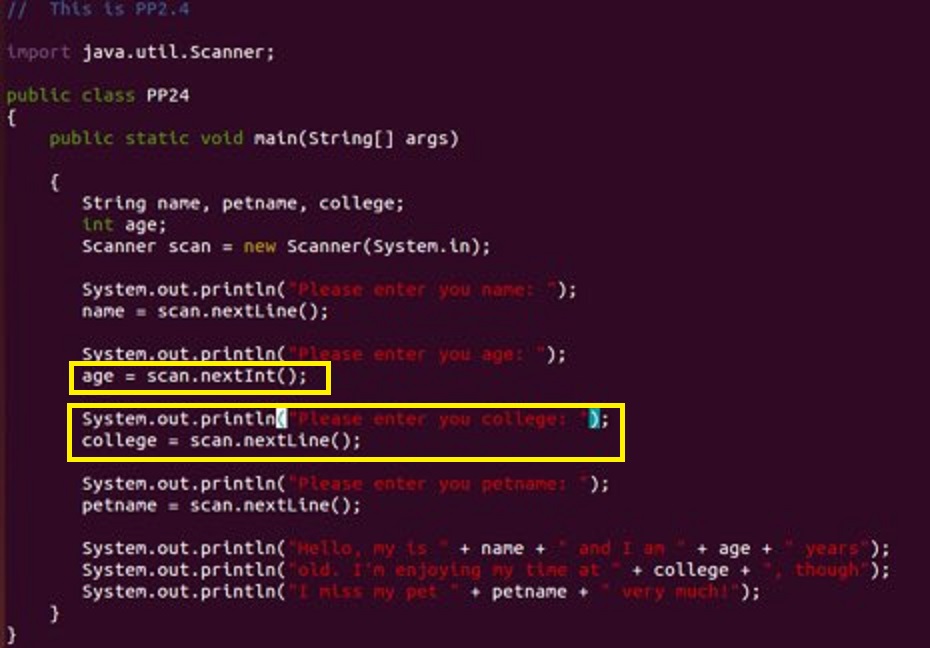
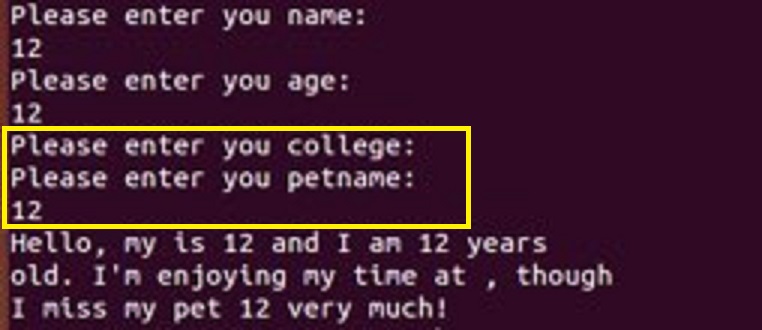
-
解答 :把 collage = 那条语句再复制一条在它下面,再加一个nextLine。
nextInt只读取整数,并没有读取输入进去的\n,也就是说后面的nextLine会读取\n,但并不返回,会导致后面的一个语句显示没有读取输入,直接跳过了。
-
【问题2】为什么使用 final int 来定义变量而之后却可以改变该变量的值?
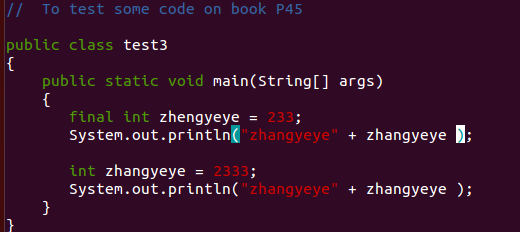
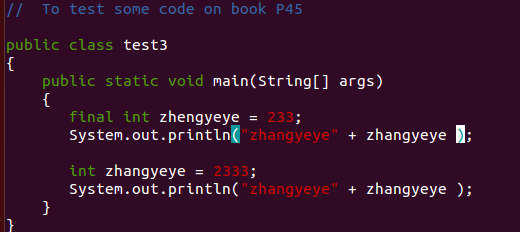
-
解答 :后面改变了变量类型,如果直接写zhengyeye = 2333是不能编译的。运行的应该是之前编译好的class文件。重新定义相同的变量会提示问题。
-
【问题3】书中写的类无法单独编译运行:
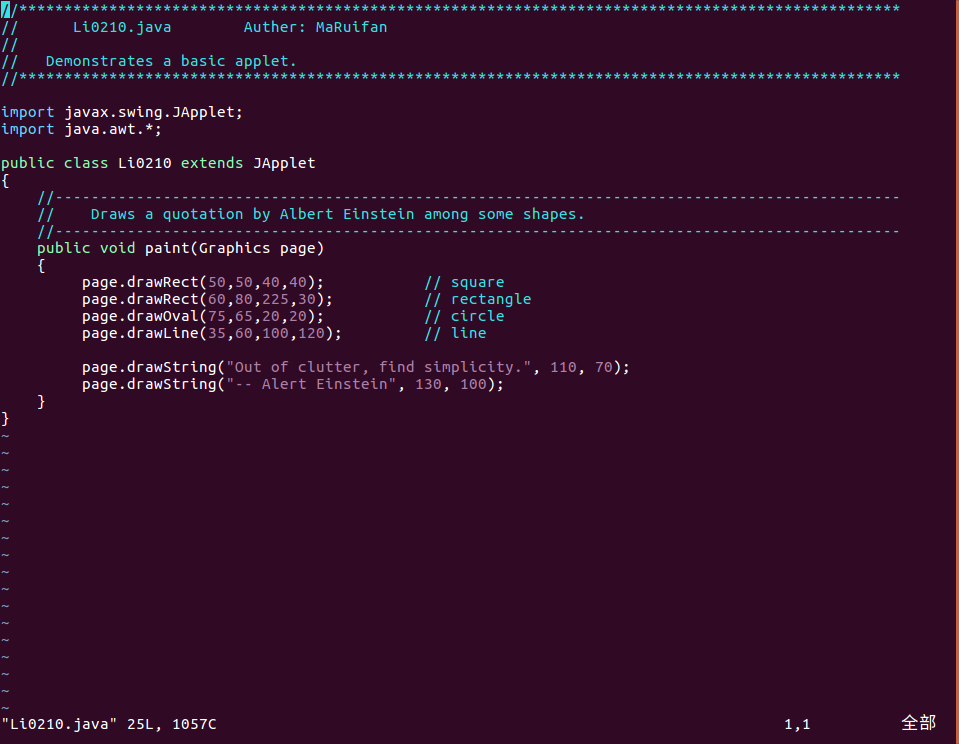
-
解答 :自定义的类只能编译,需要在有main函数的类中创建对象调用。
-
【问题4】类名以美元开头,但依旧无法编译?
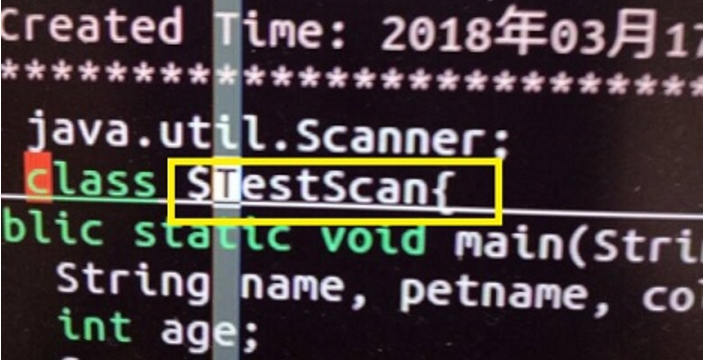
-
解答 :类名虽然可以以美元开头,但是由于类名和文件名要求一致文件名一般不允许以美元开头。文件名使用
$开头有特殊的涵义:取变量值,导致文件名被自动修改为.java,上图中以$开头的文件名自动变为.java,最终结果导致类名和文件名不一致,所以会提示class xxx is not public ,should be declared in a file name xxx。
-
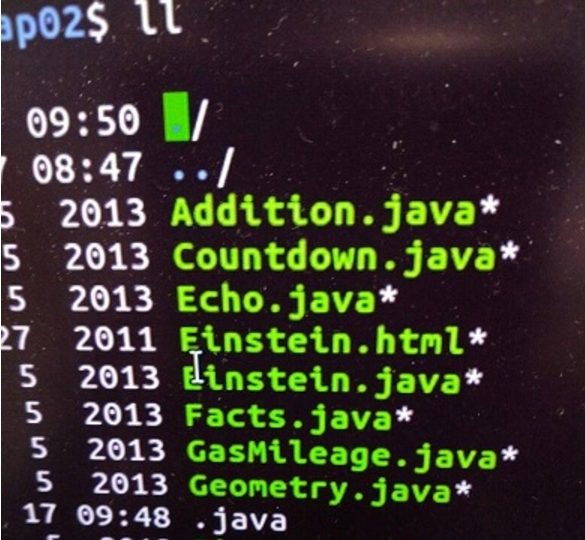
【问题5】运行老师给的AutoCompileX.sh总显示找不到文件。
-
解答 :需要把文件移动到相应的目录下进行操作才能够使用对应的脚本文件。
-
【问题6】1.2+2.4=3.5999999999999?
-
解答 :由于计算机程序设计环境中二进制和十进制的浮点数是有IEEE二进位浮点数算数标准表示的,导致计算时有偏差。
-
【问题7】运算符的应用问题,写成如下形式但运算时只计算了前面的减法而自动忽略了后面的乘法:

-
解答 :未进行调整为浮点小数,计算时将后面的结果自动变为1,导致了错误的结果。
-
【问题8】关于书上概念型问题:
(1)字符型究竟是什么?
(2)什么是参数?
(3)什么是变量声明?
(4)请写出程序中使用符号变量而不是它所表示的常数值的三个好处。 -
解答 :(1)字符型量包括字符常量和字符变量。字符串常量是由一对双引号括起的字符序列。字符变量的取值是字符常量,即单个字符。
字符变量的类型说明符是char。字符变量类型说明的格式和书写规则都与整型变量相同。
(2)参数是当调用方法时传递给方法的数据。参数分为实参和形参。方法名括号里面的参数是形参,调用方法或者函数的括号里面的是实参。
(3)变量声明确定了一个变量名及该变量可存储数据的类型。告诉编译器在程序中使用了哪些变量,及这些变量的数据类型以及变量的长度,然后为变量分配存储空间。
(4)a.通过给常量值赋予符号名,是程序代码比直接使用常熟之更容易直接理解;b.常数值在整个程序中使不可变的;c.如果需要修改程序中的常量值,只需在声明语句中修改一次该常量初始值。
-
【问题9】转义序列中的"\t"、"\n"、"\r"的作用不清楚
-
解答 :仿照例2.4在程序中试用,但是刚开始的时候在System.out.println("Roses are red.")的开头位置添加,结果"\n" 与 "\r"效果一样,在听过老师的讲解和教学视频的解析,明白两者在效果上是一样的,但是在意义上是不一致的,"\n"表示是单纯的换行,"\r"表示是回车换行。
\r与\n合起来就是回车换行的意思,回车是将光标移到当前行的行首;换行是将光标移到当前行的下一行,但还是同一列,不会回到行首。它们合起来可以将光标移到下一行的行首,也就是回车并换行。但在不同的系统中它们的功能也不太相同。比如在windows里,\r\n表示回车换行;但在linux中\n就代表回车换行。这也是为什么在linux下用vim打开windows编辑的文件会发现在每一行尾都有个^M字符的原因。
-
【问题10】组合运算符与正常的运算符之间的区别
-
解答 :在形式上组合运算符比正常的运算符在运用上更为简洁,在教学视频上的讲解,给出了更为明确的解释,例如同样是"short s = 4" 后面用两种不同的形式,"s = s +5"与"s +=5"却是一个true,一个false。原因在于开始的4是以两个字节的存储空间进行存储,而后面的5以int的存储空间进行的,为4个字节,两次运算,先相加在赋值,不能自动转换。而后者是一次运算,左右两边的和赋值给左边,可以自动换行。
-
【问题11】在编写temp程序时,检查了多遍编写内容是没有问题的,但是输出时一直提示错误,有一个错误是一不小心删掉了import的i,还有一个问题“需要class,interface或enum解决方案”不知道怎么办。
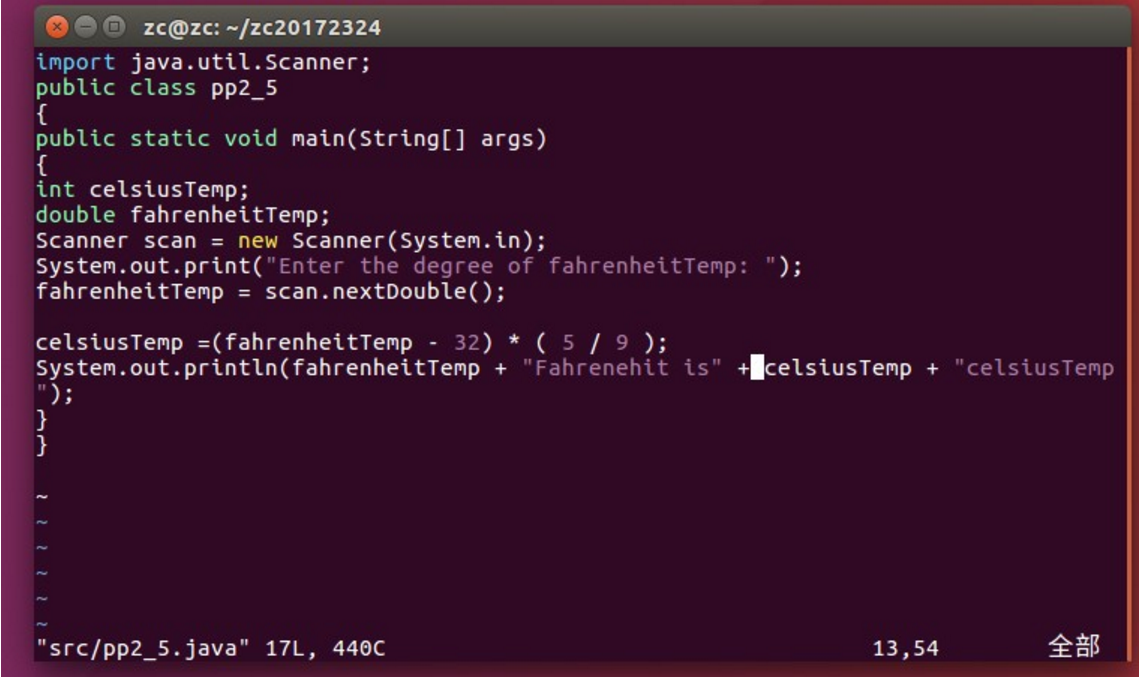
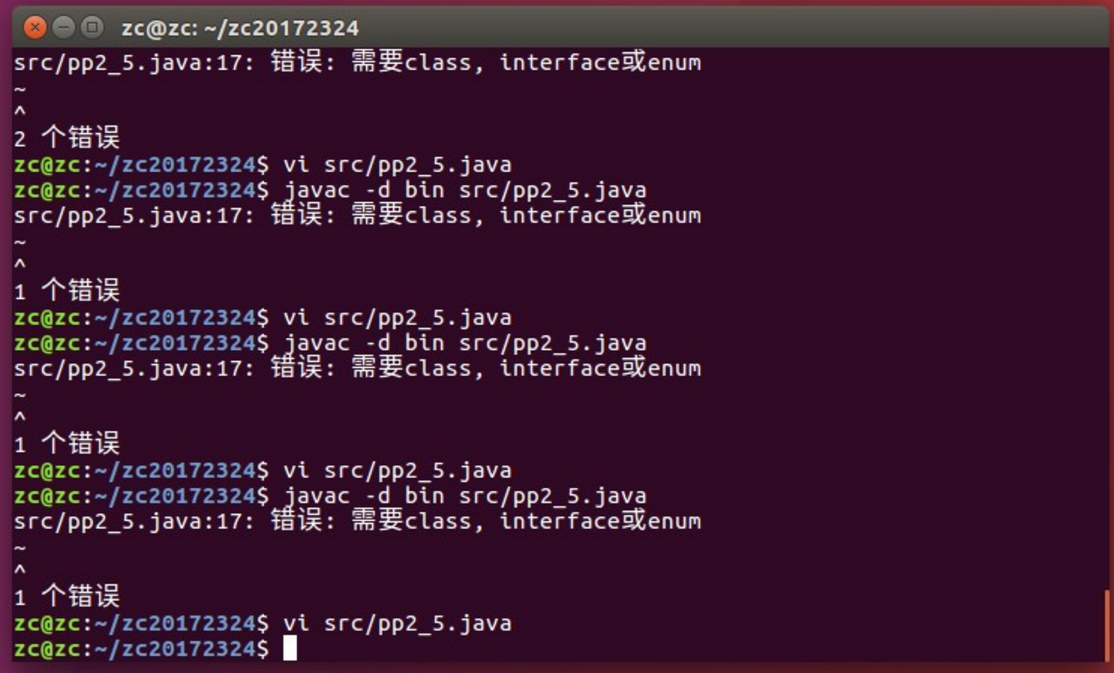
-
解答 :主要是用非记事本编写代码文件,存在编码格式转换问题。重新先建一个记事本程序,然后把源代码粘贴到该文件下,用javac 类名.java编译,java 文件名运行该程序即可。这是由于Java文件的编码导致的问题。 通常使用“javac FirstSample.java”编译UTF-8编码的.java源文件。 没有指定编码参数encoding的情况下,默认使用的是GBK编码。 当编译器用GBK编码来编译UTF-8文件时,就会把UTF-8编码文件的3个字节的文件头,按照GBK中汉字占2字节、英文占1字节的特性解码成了“乱码”的两个汉字。 这个源文件应该是用记事本另存为UTF-8编码。
- 【问题12】如果执行下列代码,得到的b的值是什么?(注意过程)
int a=4;
int b=(a++)+(--a)+(++a);
-
解答 :
1.先算b1=(a++)
2.b2=b1+(--a)
3.b=b2+(++a)1.b1=a=4,a=a+1=5
2.a=a-1=5-1=4,b2=b1+a=4+4=8
3.a=a+1=4+1=5,b=b2+a=8+5=13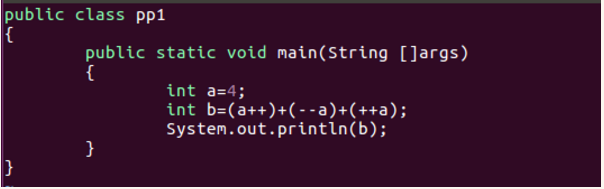

自增自减符号的后缀可以说是先把原本的变量值赋给结果值,再把原来的变量值+1或者-1,而前缀可以说是先把变量值+1或者-1,然后再把新的出的变量值赋给结果值。这题中a就是变量值,b就是结果值。(摘自:于欣月同学的精彩回答)
- 其他问题详见答疑论坛:https://group.cnblogs.com/pdds/
第 03 周 - 作业问题与解答
-
【问题1】IntelliJ IDEA2017.3 或者其他版本的激活方法?
-
解答 :使用学校.edu邮箱或者参考:IntelliJ IDEA2017.3 激活;Intellij Idea免费激活方法。
-
【问题2】激活 IntelliJ IDEA 时修改Hosts文件提示没有权限怎么办?
-
解答 :参考:https://jingyan.baidu.com/article/8ebacdf0cf184b49f65cd50b.html?qq-pf-to=pcqq.group
-
【问题3】安装好IDEA之后从码云上克隆项目没有反应?
-
解答 :如果按clone后没有反应,可进行如下尝试:点击左上角file,点击settings,双击Version Control那一栏的小标志,点击git,在第一栏找到你下载的git.exe,然后点击OK。再重新clone即可。
-
【问题4】关于PP3.3电话号码各部分首位无法输出0的解决方法:(格式化输出)

-
解答 :参考张旭升的代码:(稍有改动)
import java.text.DecimalFormat;
import java.util.Random;
public class TelNum {
public static void main(String[] args) {
DecimalFormat decimalFormat = new DecimalFormat("000");
DecimalFormat decimalFormat1 = new DecimalFormat("0000");
Random random = new Random();
int num = random.nextInt(8);
int num1 = random.nextInt(8);
int num2 = random.nextInt(8);
int num3 = random.nextInt(656);
int num4 = random.nextInt(10000);
System.out.println("电话号码:" + num + num1 + num2 + "-" + decimalFormat.format(num3) + "-" + decimalFormat1.format(num4));
}
}
-
补充问题:做习题3_3的时候虽然代码上写的能够输出三位数字,但只能输出两位数字,甚至有时候只能输出一位。

-
解答:输出时在前面没有字符串的情况下,系统自动把结果默认为相加所以也就最多只能输出三位了,只要在前面加上字符串就默认后面的数是字符串了。

-
【问题5】在有关将数字变成货币格式的时候,按照书中的例子做了,但是结果显示的不是$而是¥。

-
解答 :当初设置虚拟机时所选的地区是中国,所以它会转化为当地的货币符号。
如果想要在中国地区显示美元符号$,先声明一下import java.util.Locale;再把那一行代码改成:NumberFormat fmt1=NumberFormat.getCurrencyInstance(Locale.US);
参考:http://download.oracle.com/technetwork/java/javase/6/docs/zh/api/java/util/Locale.html
https://zhidao.baidu.com/question/552422997551378132.html最后的输出结果如下:
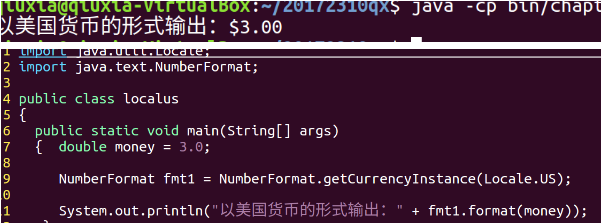
-
【问题6】为什么用 public 修饰类名时文件名与类名相同?

-
【问题7】为什么String不需要显式地导入到程序中?
-
解答 :String属于lang类,有以下几种:
1、String,八种基本数据类型的包装类都在这个包中;
2、Object:类层次结构的根类;
3、Math:执行基本数学方法运算;
4、StringBuffer:线程安全的可变字符序列;
5、thread:是程序中的执行线程。Java虚拟机允许应用程序并发地运行多个执行线程。
-
【问题8】如何将虚拟机中bin文件夹上传到码云?
-
解答 :可以设置不忽略.class文件。这样就可以把bin文件夹和class文件上传上去。
-
【问题9】如何使用JDK API?
-
解答 :参考:https://blog.csdn.net/l4432321/article/details/52600426
-
【问题10】空字符串和空引用的区别?
-
解答 :
空字符串“”:
1、类型:“”是一个空字符串(String),长度为0,占内存,在内存中分配一个空间,可以使用Object对象中的方法。(例如:“”.toString()等)
2、内存分配:表示声明一个字符串类型的引用,其值为“”空字符串,这个引用指向str1的内存空间。
> 空引用null:
1、类型:null是空引用,表示一个对象的值,没有分配内存,调用null的字符串的方法会抛出空指针异常。(例如:str1.endsWith(str2); java.lang.NullPointerException)
2、内存分配:表示声明一个字符串对象的引用,但指向null,也就是说没有指向任何内存空间。
- 例:
String str1 = ""; //str1对应一个空串,声明对象的引用
String str2 = null; //str2引用为空
String str3 = new String(); //str3将指向具体的String实例,默认值为“”
-
【问题11】如何理解Java枚举类型(enum)?
-
解答 :参考:深入理解Java枚举类型(enum)
-
【问题12】格式化输出中的DecimalFormat类“#”和“0”的区别?
-
解答:针对DecimalFormat类的“#”和“0”的区别,试了好几次,并且每次运用的“#”和“0”的长度也不同,其中“#”的作用表示该位无数字则自动省略,“0”表示该位无数字则补零。两种都要进行四舍五入,进行保留。而且书中的例题很有意思,其中的“The circle's area:78.5398”在格式化为“0.####”如果为“0.###”的时候,8进位,9变10结果应该为78.530,但由于“#”的作用使得末尾的0去掉了。
参考:https://www.cnblogs.com/yelongsan/p/5482774.html
“#”:如果该位四舍五入后数字为0,那么就省略这个0,
“0”:如果该位四舍五入后没有数字,那么就自动补0。
- 其他问题详见答疑论坛:https://group.cnblogs.com/pdds/
第 04 周 - 作业问题与解答
-
【问题1】如何理解静态变量,静态方法和静态类?
-
解答 :静态变量由所有实例共享。静态方法可以通过类名称来调用。main方法只能访问静态变量或局部变量。
静态变量有两种情况:
静态变量是基本数据类型,这种情况下在类的外部不必创建该类的实例就可以直接使用
静态变量是一个引用。这种情况比较特殊,主要问题是由于静态变量是一个对象的引用,那么必须初始化这个对象之后才能将引用指向它。
因此如果要把一个引用定义成static的,就必须在定义的时候就对其对象进行初始化。静态方法:与类变量不同,方法(静态方法与实例方法)在内存中只有一份,无论该类有多少个实例,都共用一个方法。
静态方法与实例方法的不同主要有:
静态方法可以直接使用,而实例方法必须在类实例化之后通过对象来调用。在外部调用静态方法时,可以使用
类名.方法名或者对象名.方法名的形式。实例方法只能使用后面这种方式。
静态方法只允许访问静态成员。而实例方法中可以访问静态成员和实例成员。
静态方法中不能使用this(因为this是与实例相关的)。关于静态类,参考:http://blog.sina.com.cn/s/blog_605f5b4f0100zbps.html
静态类仅包含静态成员,不能被实例化,静态变量可以由所有的类实例共享,静态方法可以通过类名称调用。静态类是密封的,因此不可被继承。静态类不能包含构造函数,但仍可声明静态构造函数以分配初始值或设置某个静态状态。 -
【附】实例变量和静态变量的区别?
静态变量也叫类变量,这种变量前加了static修饰符。可以直接用类名调用,也可以用对象调用,而且所有对象的同一个类变量 都是共享同一块内存空间。
实例变量也叫对象变量,这种变量没有加static修饰符。只能通过对象调用, 而且所有对象的同一个实例变量是共享不同的内存空间的。
静态变量是所有对象共有的,某一个对象将它的值改变了,其他对象再去获取它的值,得到的是改变后的值;
实例变量则是每一个对象私有的,某一个对象将它的值改变了,不影响其他对象取值的结果,其他对象仍会得到实例变量一开始就被赋予的值。
-
【问题2】如何使用return语句?return与void的关系?
-
解答 :方法的返回值类型必须与方法声明首部中规定的返回值类型一致。当方法不返回任何值时,用void作为返回值类型。一条return语句由保留字return和后续的可选表达式组成。执行return语句时,控制立即返回到调用方法,并返回表达定义式的返回值。
每一个方法中可以有多个return,但并不是返回的多次,而是在不同情况下进行的返回。同时,在构造方法中没有返回值。不返回值的方法通常不包含return语句,当 该方法执行结束时将自动返回调用方法。
-
【问题3】如何理解“接口”?
-
解答 :对于接口,是一组常量和抽象方法的集合,抽象方法是指没有实现的方法,即没有代码体,接口中没有实现的方法,参数列表的方法声明头后面仅跟着分号。接口不能被实例化,类通过实现定义在接口中的每个抽象方法来实现这个接口,实现接口的类需在类声明头部使用保留字implements,再给出接口名,类中必须实现至少一个接口中的抽象方法,同时也可以定义其他方法。多个类可以实现同一个接口,一个类也可以实现多个接口。实现一个接口的类时,在接口中可以定义额外的方法。示例为一个简单的接口:
public interface Nameable
{
public static setName(String Name);
public String getName();
}
-
【问题4】为什么非要去写一个接口?
-
解答 :接口的应用,大大提高了方法步骤的灵活性。
“接口是个规范”,这句没错。“不如直接就在这个类中写实现方法岂不是更便捷”,你怎么保证这个接口就一个类去实现呢?如果多个类去实现同一个接口,程序怎么知道他们是有关联的呢?既然不是一个类去实现,那就是有很多地方有用到,大家需要统一标准。甚至有的编程语言(Object-C)已经不把接口叫 interface,直接叫 protocol。统一标准的目的,是大家都知道这个是做什么的,但是具体不用知道具体怎么做。比如说:我知道 Comparable 这个接口是用来比较两个对象的,那么如何去比较呢?数字有数字的比较方法,字符串有字符串的比较方法,学生(自己定义的类)也有自己的比较方法。然后,在另外一个负责对象排序(不一定是数字喔)的代码里面,肯定需要将两个对象比较。这两个对象是什么类型呢?Object a,b?肯定不行,a > b 这样的语法无法通过编译。int a,b?也不行?一开始就说了,不一定是数字。....所以,Comparable 就来了。他告诉编译器,a b 两个对象都满足 Comparable 接口,也就是他们是可以进行比较的。具体怎么比较,这段程序不需要知道。所以,他需要一些具体的实现,Comparable 接口有一个方法,叫 compareTo。那么这个方法就是用来取代 <、> 这样的运算符。因为运算符是编译器保留给内置类型(整数、浮点数)进行比较用的,而不是一个广义的比较运算。如果你可以明白 JDK 自身库里面诸如 Comparable 这样已经有的接口,那么就很容易理解自己在开发程序的时候为什么需要用到接口了。
四点关于JAVA中接口存在的意义:
1、重要性:在Java语言中, abstract class 和interface 是支持抽象类定义的两种机制。正是由于这两种机制的存在,才赋予了Java强大的 面向对象能力。
2、简单、规范性:如果一个项目比较庞大,那么就需要一个能理清所有业务的架构师来定义一些主要的接口,这些接口不仅告诉开发人员你需要实现那些业务,而且也将命名规范限制住了(防止一些开发人员随便命名导致别的程序员无法看明白)。
3、维护、拓展性:比如你要做一个画板程序,其中里面有一个面板类,主要负责绘画功能,然后你就这样定义了这个类。可是在不久将来,你突然发现这个类满足不了你了,然后你又要重新设计这个类,更糟糕是你可能要放弃这个类,那么其他地方可能有引用他,这样修改起来很麻烦。如果你一开始定义一个接口,把绘制功能放在接口里,然后定义类时实现这个接口,然后你只要用这个接口去引用实现它的类就行了,以后要换的话只不过是引用另一个类而已,这样就达到维护、拓展的方便性。
4、安全、严密性:接口是实现软件松耦合的重要手段,它描叙了系统对外的所有服务,而不涉及任何具体的实现细节。这样就比较安全、严密一些(一般软件服务商考虑的比较多)。
-
【问题5】对于调用toString方法不是很理解,不调用也能完成输出,为什么非要去调用它?
-
解答 :用
System.out.println()输出一个对象的时候,java默认调用对象的toString()方法。一般你要覆盖这个方法,这样根据覆盖逻辑你就可以输出自己的对象。比如你定义一个类User,有id,name属性,你直接输出一个user对象的话System.out.println(user),得到的只是全限定名 @ 地址首地址 。如果你在User类里面覆盖这个toString方法的话就能输出你要的。如果一个java对象改写了toString方法,就不会打印出内存地址,而是直接调用了他的toString方法。在源码中,比如
System.out.println()方法,用它来打印一个对象。它会首先判断一下该对象是否为null,如果为null,就直接打印出一个null的字符串。如果不为null,就自动调用该对象的toString方法。所以,如果改写了toString,就会直接调用toString方法了。如果没有,就是调用父类Object中的toString方法,也就是打印出内存地址。可以继续参考侯泽洋同学这篇博客中的教材问题1和代码问题2进一步了解。
-
【问题6】在做PP4.2,编写bulb类的时候为什么会输出一段乱码?(可以当成对问题5的补充)
-
解答 :你的对象没有重写这个方法的时候调用会输出地址!你的对象需要被打印或者需以某种方式转换为字符串时就需要重写方法!因为你很多时候都会去做一个转换或者打印的操作所以最好重写一下。
可继续参考:每个Java类都有的toString方法
-
【问题7】普通方法和构造方法的区别?
-
解答 :1. 构造函数的命名必须和类名完全相同;在java中普通函数可以和构造函数同名,但是必须带有返回值。
-
构造函数的功能主要用于在类的对象创建时定义初始化的状态。它没有返回值,也不能用void来修饰。这就保证了它不仅什么也不用自动返回,而且根本不能有任何选择。而其他方法都有返回值。即使是 void 返回值,尽管方法体本身不会自动返回什么,但仍然可以让它返回一些东西,而这些东西可能是不安全的。
-
构造函数不能被直接调用,必须通过new运算符在创建对象时才会自动调用,一般方法在程序执行到它的时候被调用。
-
当定义一个类的时候,通常情况下都会显示该类的构造函数,并在函数中指定初始化的工作也可省略,不过Java编译器会提供一个默认的构造函数。此默认构造函数是不带参数的,而一般方法不存在这一特点。
构造方法是创建对象时自动调用的,普通方法需要对象去调用,只要创建对象就一定会调用构造方法,可以显式的指定某个构造方法,如果不指定就调用默认的。
-
【问题8】形式参数和实际参数的区别?
-
解答 :形式参数是函数定义中的,系统没有为其分配内存空间,但是在定义里面可以使用的参数。例如:fun(int a)。这里a就是形式参数。
实际参数是函数调用的时候传给函数的变量。这个是系统实实在在分配了内存空间的变量。
简单点说,就是形式参数给个形式,实际参数放进去用。例如:fun(a);
函数声明的用处是告诉编译器声明的函数在后面有定义。如果你将函数定义放在调用的前面,就不需要声明。另外声明就是函数定义后面加上分号的形式。
例如:定义是fun(int a),声明就是fun(int a);可参考:形参和实参的区别
-
【问题9】使用命令行运行Java程序的时候无响应。
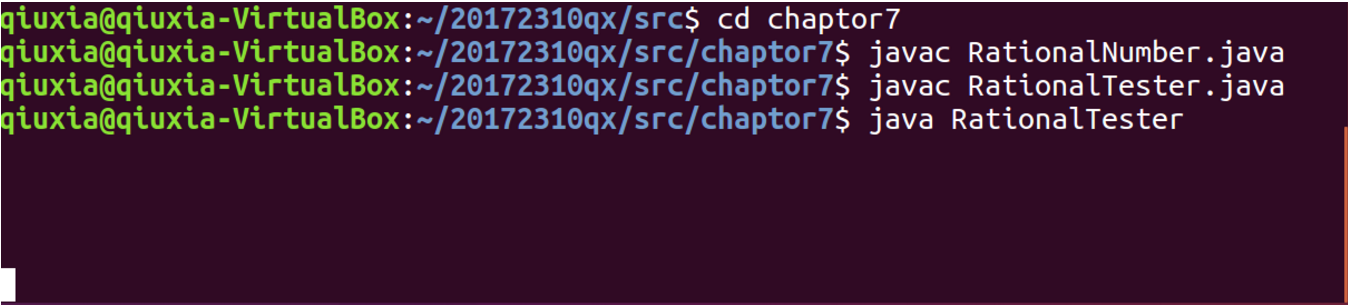
-
解答 :检查一下自己程序中有没有死循环的条件。
(ps:看到张旭升都没有解决,我也特意查了一大堆资料,可惜具体没有查到,只查到了关于“Java程序运行超时”的相关内容,
具体参考:java 方法执行超时处理 和 Java程序运行超时后退出或进行其他操作的实现)
-
【问题10】如何撤销 git add?
-
解答 :git rm --cached <added_file_to_undo>
如需撤销文件夹加上 -r
git rm -r --cached <added_file_to_undo>
-
【问题11】在做例4.3-例4.4时,Account.java编译成功后,运行时出现如图所示的情况。

-
解答 :编辑Account.java的目的是定义一个Account类,使Transaction类可以运用其中定义的方法从而顺利运行,所以Account类不需要main方法,所以单独编译此Java文件会出现如此错误提示。
-
【问题12】在编写课堂作业即pp47的时候,编写的book类可以运行成功,但是在Java编译的时候显示的就是null.
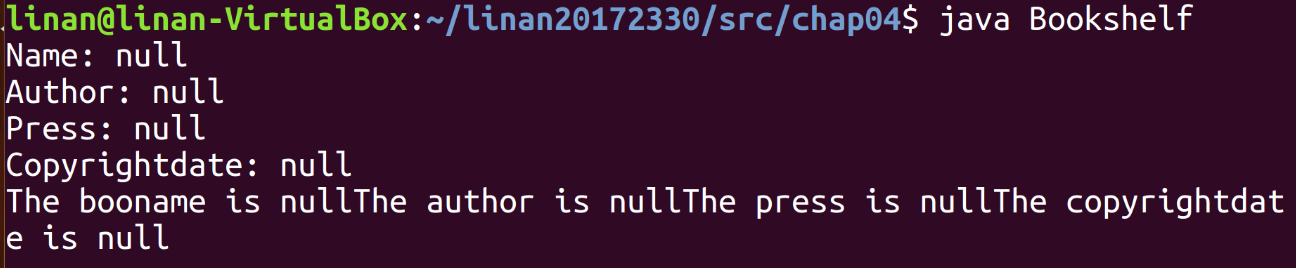
-
解答 :编写的类变量和定义方法(构造函数)的参数名字是一样的导致错误最终输出null,于是改为this。参考课本第七章对于this的引用,this引用是可以允许对象引用自己的,而且this引用还可以引用于当前正在运行的对象。
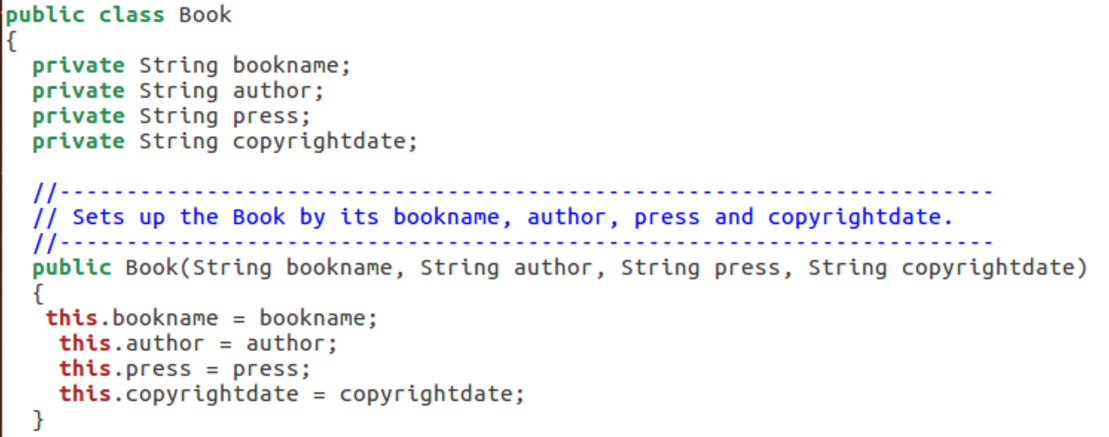
在上述构造方法中,this引用特指对象的实例变量,赋值语句右边的变量是构造方法的形参变量。
这种方法避免了对含义相同的变量要给出不同命名以示区别的问题。有时,这种情况发生在其他的方法中,但更经常出现在构造方法中。
- 其他问题详见答疑论坛:https://group.cnblogs.com/pdds/
第 05 周 - 作业问题与解答
-
【问题1】
=和==的区别? -
解答 :
=是赋值,==是判断,输出的是 boolean 结果——true、false。
-
【问题2】
==和equals的区别? -
解答 :
==是一个操作符,比较对象的存放地址(是否彼此互为别名),equals是一种方法,一般比较两个对象的值。
参考:(1)Java中==号与equals()方法的区别(3)equals和==的区别
-
【问题3】Java中几种循环语句各有什么特点?
-
解答 :①while循环(先判断,执行0次或者多次);②do循环(至少执行一次后再判断);③for循环(先判断,循环次数确定或者容易计算)④for-each循环((迭代器)简单的处理对象中的各项元素)

(上图还添加了 switch 语句)
-
【问题4】关于 switch 语句的优缺点?
-
【问题5】如何理解书上【例5.10】提到的IO流和迭代器?
-
解答 :关于Java的IO流参考:Java IO最详解
关于迭代器参考:Java中迭代器的使用和深入理解Java中的迭代器
-
【问题6】如果两个字符串,长度不同,多个对应位置索引处的字符不同,compareTo如何比较?
-
解答 :字符和字符串的比较以Unicode字符集为基础。这种比较称为字典顺序比较。而其只比较第一个字符,如果不同则其后不再比较。
compareTo() 的返回值是int, 它是先比较对应字符的大小(ASCII码顺序)
1、如果字符串相等返回值0
2、如果第一个字符和参数的第一个字符不等,结束比较,返回他们之间的差值(ascii码值)(负值前字符串的值小于后字符串,正值前字符串大于后字符串)
3、如果第一个字符和参数的第一个字符相等,则以第二个字符和参数的第二个字符做比较,以此类推,直至比较的字符或被比较的字符有一方全比较完,这时就比较字符的长度。
-
【问题7】如何理解并使用 ArrayList 类中的一些方法和其与数组的关系?
-
【问题8】不理解循环语句中 break 与 continue 的区别?
-
解答 :break和continue都是用来控制循环结构的,主要是停止循环。
(1)break:
有时候我们想在某种条件出现的时候终止循环而不是等到循环条件为false才终止。这时我们可以使用break来完成。break用于完全结束一个循环,跳出循环体执行循环后面的语句。
(2)continue:
continue和break有点类似,区别在于continue只是终止本次循环,接着还执行后面的循环,break则完全终止循环。可以理解为continue是跳过当次循环中剩下的语句,执行下一次循环。
可参考:(1)break和continue的区别
-
【问题9】关于pp5.7只能进行一次,不能让游戏继续下去的问题?
-
解答 :之前已经提过nextInt()方法与nextLine()的区别,再总结一遍:
nextInt()读取一个键盘获取的数字之后焦点并不会移动到下一行,这时候如果下面语句中跟了一句nextLine()的话就读不到输入的内容了。因为nextLine()是遇到换行符结束读取,nextInt()读取的内容还没有换行,所以紧跟着nextInt()的nextLine()就只是读取到了最后的换行符。所以并没有接收到在上述程序中的y/n。
参考:Scanner中nextLine()方法和next()方法的区别和Java中关于nextInt()、next()和nextLine()的理解
-
【问题10】关于博客中的皮肤、标题样式、如何加目录等排版美化问题。
-
解答 :参考:(1)如何让博客变得稍稍好看
- 其他问题详见答疑论坛:https://group.cnblogs.com/pdds/
第 06 周 - 作业问题与解答
-
【问题1】关于foreach循环方式不太熟悉?foreach语句和for语句的比较?
-
解答 :参考java中for循环的几种方式和深入理解java中for和foreach循环

(1).如果只是遍历集合或者数组,用foreach好些,快些。
(2).如果对集合中的值进行修改,就要用for循环了。其实foreach的内部原理其实也是Iterator,但它不能像Iterator一样可以人为的控制,而且也不能调用iterator.remove();更不能使用下标来访问每个元素,所以不能用于增加,删除等复杂的操作。
(3).总的来说,当你想要对很多变量进行相同的操作时,foreach是较为简单快捷的;而当你想要更加精确具体的控制很多变量进行不同操作时,for语句将会是更好的选择。
-
【问题2】虚拟机登录后蓝屏怎么解决?
-
解答 :首先, 按下Ctrl + Alt + F4 进入一个界面。输入用户名和密码,进入root模式。
然后,需要安装相应的服务然后重置。
sudo apt-get install xserver-xorg-lts-utopicsudo dpkg-reconfigure xserver-xorg-lts-utopicreboot如果前面第一个操作有问题,需要重置
dpkg后再试sudo dpkg --configure -a
-
【问题3】为什么数组的索引值的从0开始的?
-
解答 :1、数组在内存中申请是,所申请的内存是一段连续的内存地址;
2、例:int[] a=new int[3];申请一段:int 数据类型的数组,a 为变量,数组长度为:[3];
3、这个数组所申请的内存地址是连续的(假设所申请的:第一个内存地址为:1008,第二个为:1009,第三个为:1010);,但我们只知道:一、变量:a,它只拿到第一个内存地址1008;二、它的数组空间为3个;
4、a[0]——把a拿到的内存地址:1008 + 0 = 1008 (指向第一个内存地址);
a[1]——把a拿到的内存地址:1008 + 1 = 1009 (指向第二个内存地址);
a[2]——把a拿到的内存地址:1008 + 2 = 1010 (指向第三个内存地址);所以:数据下标从 [0] 开始的意义也在于此!
可参考:为什么数组是从0开始的
-
【问题4】parseInt 方法在将后面的字符转换为数值类型时要如何使用?
-
解答 :1.基本用法(只接受一个参数,可以当做第二个参数默认是10):parseInt的返回值只有两种可能,不是一个十进制整数,就是NaN。
a.将字符串转为整数。
parseInt('123') // 123
b.如果字符串头部有空格,空格会被自动去除。
parseInt(' 81') // 81
c.如果parseInt的参数不是字符串,则会先转为字符串再转换。这个很重要
d.字符串转为整数的时候,是一个个字符依次转换,如果遇到不能转为数字的字符,就不再进行下去,返回已经转好的部分。
e.如果字符串的第一个字符不能转化为数字(后面跟着数字的正负号除外),返回NaN。
f.如果字符串以0x或0X开头,parseInt会将其按照十六进制数解析。
parseInt('0x10') // 16
g.如果字符串以0开头,将其按照10进制解析。
parseInt('011') // 11
h.如果参数以0开头,但不是字符串,则会先将数值转成字符串,然后解析,见规则c
parseInt(011) // 9
i.对于那些会自动转为科学计数法的数字,parseInt会将科学计数法的表示方法视为字符串,因此导致一些奇怪的结果。
parseInt(1000000000000000000000.5) // 1
// 等同于
parseInt('1e+21') // 1
parseInt(0.0000008) // 8
// 等同于
parseInt('8e-7') // 8
2.进制转换(接收两个参数):parseInt方法还可以接受第二个参数(2到36之间),表示被解析的值的进制,返回该值对应的十进制数。默认情况下,parseInt的第二个参数为10,即默认是十进制转十进制。
a.第一个参数解析规则参照第一条基本用法
b.如果第二个参数不是数值,会被自动转为一个整数。这个整数只有在2到36之间,才能得到有意义的结果,超出这个范围,则返回NaN。如果第二个参数是0、undefined和null,则直接忽略。
-
【问题5】类/对象/变量/参数的含义?区别?联系?
-
解答 :类:类是组成java程序的基本要素,它封装了一类对象的属性和方法。
对象:类是创建对象的模板,当使用一个类创建了一个对象时,也就是说给出了这个类的一个实例。
变量:区别于常量的一种可变数据。java中的三大变量是静态变量、实例变量和局部变量。局部变量就是本地变量,在方法、构造器或者块中使用,在方法、构造器或者块进入时被创建。实例变量在类中声明,但是它在方法、构造器之外。静态变量在类中用static关键字声明,但是它在方法、构造器或者块之外。
参数:参数分两种,一种叫形参,一种叫实参。在方法名后面括号里面用逗号分开的就是形参。当方法没有参数时,如果想要使用这个方法的话必须在调用这个方法时给它传递形参的实际值(这就是实参)
联系:

(图片来自范雯琪同学的博客)
-
【问题6】对数组的命令行参数如何理解?
-
【问题7】对于数组可变长度参数要如何使用?
-
【问题8】对象数组是什么?
-
解答 :参考java对象数组的概述和使用
-
【问题9】例题8.3中字符之间相减怎么理解?
-
解答 :例题8.3部分代码如下:
for (int ch = 0;ch<line.length();ch++)
{
current = line.charAt(ch);
if (current>='A' && current<='Z')
upper[current-'A']++;
else
if (current>='a' && current<='z')
lower[current-'a']++;
else
other++;
}
首先在char中,对应的不是理解中的字母,而是Unicode码,例如A是65,所以是减去A对应着减去其uincode码。从中可以锁定句中的字母的索引。而又已知的是数组默认值为0,所以,如果有相应字母,那么通过upper[]++来增加对应索引的内容。
对应的,在输出时,有:
// Print the results
System.out.println();
for (int letter=0; letter < upper.length;letter++)
{
System.out.print((char)(letter + 'A'));
System.out.print(": " + upper[letter]);
System.out.print("\t\t" + (char)(letter + 'a'));
System.out.print(":" + lower[letter]);
}
继续利用Unicode码,从A开始,A为65,则对应的letter从0开始。可以轻易的将数字转化为字符。
- 【问题10】如何理解书上的这句话:
将一个数组作为参数的方法可以实际改变改数组元素,因为该方法引用的是原始数组的元素值。但该方法不能改变数组引用本身,因为它接受的参数是原始数据引用的副本。这个规则与管理任何对象类型的规则一致。
-
解答 :使用值传参(pass_by_value)的方式来传递函数参数,只是值传递方式在处理原始数据类型参数与引用类型参数时候有不同,如果一个参数是原始数据类型,那么参数变量的值传递进去。如果是引用类型,是传进了引用变量的值(也就是说,只是将指向数据的引用的值给传进去了,也就是被调用的函数新建的空间放的是这个引用的值,那么也就是也指向了数组存在的内存),所以同样是值传递,引用类型的传入的当然是引用变量的值,指向了同一数组,那么函数内对数组进行的修改在函数退出后依旧是有效的。
- 其他问题详见答疑论坛或云班课:https://group.cnblogs.com/pdds/
第 07 周 - 作业问题与解答
-
【问题1】Java 四种可见性修饰符的类型和区别、非可见性修饰符的特点?
-
解答 :(Java 修饰符主要分为可见性和非可见性修饰符(又称访问修饰符和非访问修饰符))
四种可见性修饰符可参考Java中访问修饰符public、private、protect、default范围:
public:被声明为 public 的类、方法、构造方法和接口能够被任何其他类访问。由于类的继承性,类所有的公有方法和变量都能被其子类继承。
private:私有访问修饰符是最严格的访问级别,所以被声明为 private 的方法、变量和构造方法只能被所属类访问,并且类和接口不能声明为 private。
protected:当父类和子类在同一个包中时,被声明为 protected 的变量、方法能被同一个包中的任何其他类访问;当父类和子类不在同一个包中时,子类实例可以访问其从父类继承而来的 protected 方法,而不能访问父类实例的protected方法。
default:在同一包内可见,不使用任何修饰符。使用对象:类、接口、变量、方法。
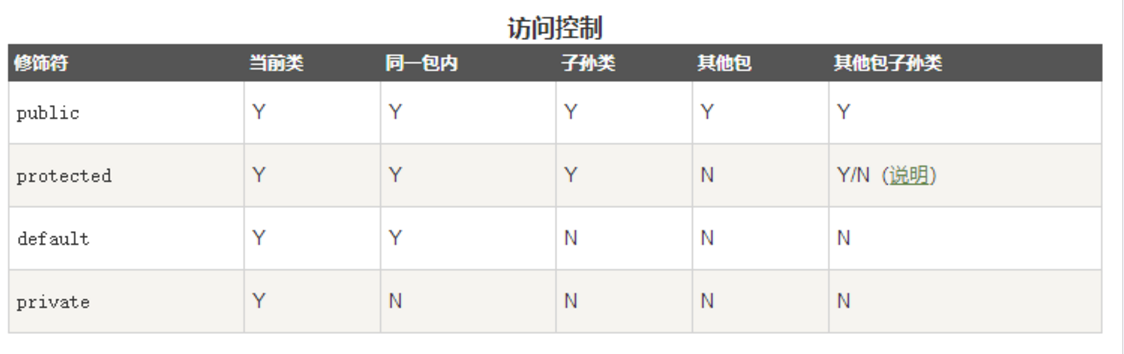
非可见性修饰符已学的有三种:
static:用于声明静态变量或静态方法。
final:final 变量能被显式地初始化并且只能初始化一次。类中的 final 方法可以被子类继承,但是不能被子类修改。
abstract:抽象类不能用来实例化对象,声明抽象类的唯一目的是为了将来对该类进行扩充。关于权限修饰符还要注意几个问题:
1.并不是每个修饰符都可以修饰类(指外部类),只有public和default可以;
2.所有修饰符都可以修饰数据成员,方法成员,构造方法;
3.为了代码安全起见,修饰符不要尽量使用权限大的,而是适用即可。比如,数据成员,如果没有特殊需要,尽可能用private。加强封装性;
4.修饰符修饰的是“被访问”的权限。
-
【问题2】
super.message();与super(message);的区别? -
解答 :
super.message();是调用父类的方法并且这里的message是方法名,super(message);是调用父类的构造方法并且这里的message是形参名。
-
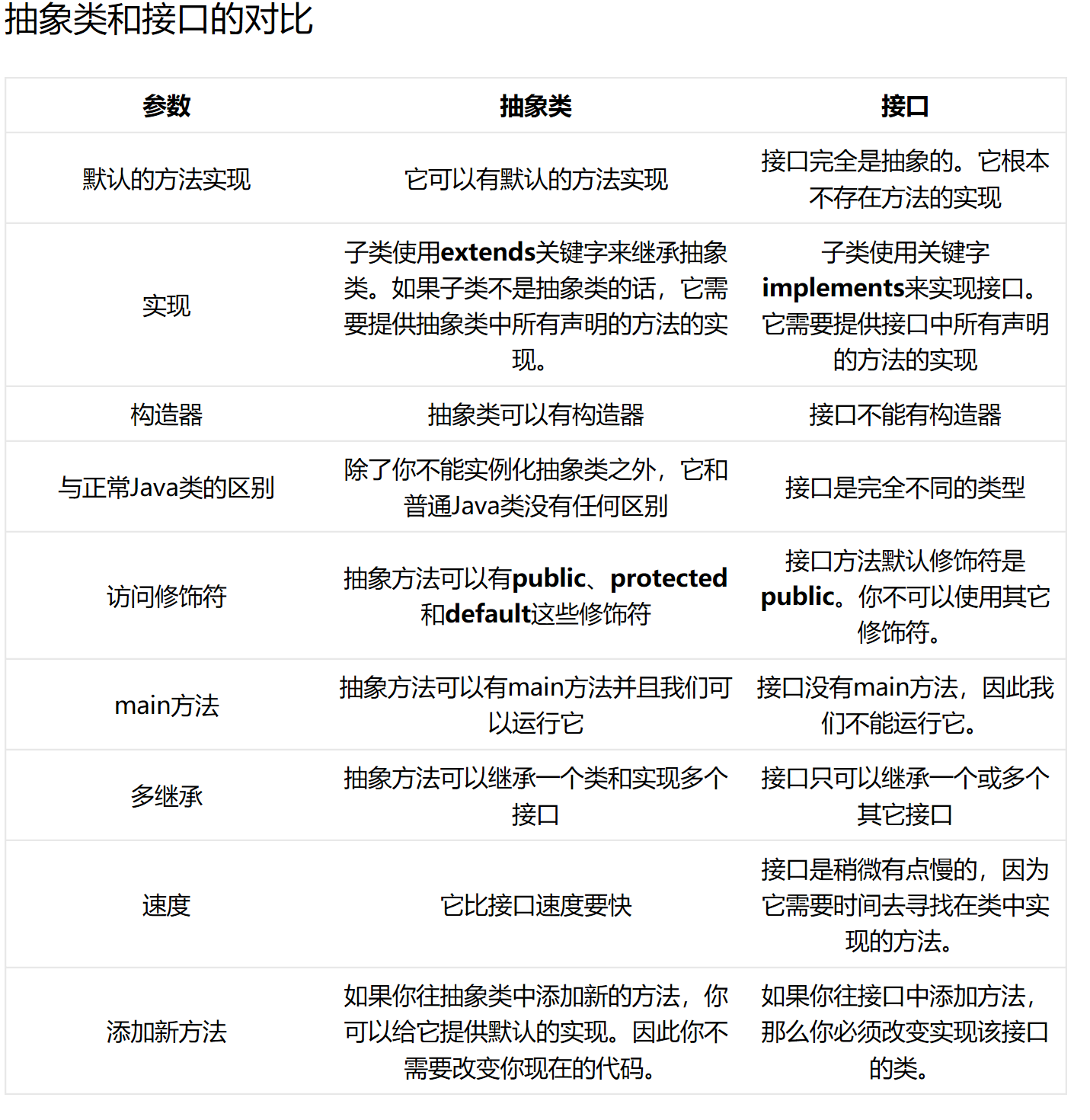
【问题3】接口类与抽象类的区别?
-
解答 :(参考王老师的上课讲义)
接口类:常量 + 抽象方法
抽象类:常量/变量 + 抽象/非抽象方法(Notes:抽象类可以不包含抽象方法)和接口类一样,抽象类不能被实例化!(包含未实现的方法)
和接口类不同,抽象类中的方法必须使用abstract修饰。(接口中所有方法都是抽象的,可以省略abstract,也可以使用!)
//接口类
public interface Complexity{
public void setComplexity(int complexity);//抽象方法
public int getComplexity();//抽象方法
}
//抽象类
public abstract Complexity{
private int reality;
public abstract void setComplexity(int complexity);//抽象方法
public int getComplexity(){//非抽象方法
return reality;
}
}
可参考:[深入理解Java的接口和抽象类](http://www.importnew.com/18780.html)和[Java中的抽象类](https://www.cnblogs.com/pssp/p/6296677.html)
-
【问题4】super 引用时为什么出现错误?
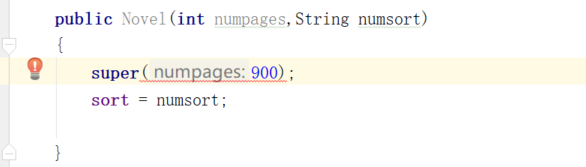
-
解答 : 父类的构造方法中包括参数,则参数列表为必选项,用于指定父类构造方法的入口参数。
因为前面的父类构造方法包含了参数列表,所以引用时需要键入所有的访问变量以此来指定父类构造方法中的参数。
-
【问题5】代码编译时无法通过?

-
解答 :该类是子类,如果子类创建构造方法的话,那么需要用super语句把父类的构建方法也输入,(主要是把父类的对象也初始化),否则会有错误。并且一定要注意,super语句要放在第一行。
-
【问题6】super 和 this 的异同?
-
解答 :

-
【问题8】如何理解Java中的“影子变量”?
-
解答 :参考JAVA中方法和变量在继承中的覆盖和隐藏
-
【问题9】重写和重载的区别?
-
【问题10】软件复用是什么?
-
解答 :软件复用是使用现有软件组件实现或更新软件系统的过程。
它可以降低成本和开发时间,产生可靠的软件实现标准化,在不同应用中保持一致 。
- 其他问题详见答疑论坛或云班课:https://group.cnblogs.com/pdds/
第 08 周 - 作业问题与解答
-
【问题1】接口的实现和意义?多态和接口的关系?
-
解答 :参考接口实现多态、接口(interface)与多态、Java中接口、接口的实现和多态的问题?和举例:接口的定义,实现,为什么要用接口,意义何在?
接口的格式为:

-
【问题2】关于后绑定(动态绑定)已经前绑定(静态绑定)的理解和比较?
-
解答 :参考java — 静态绑定和动态绑定和Java静态绑定与动态绑定

<1>前期绑定就是说在编译过程中就已经知道这个方法到底是哪个类中的方法,此时由编译器或其它连接程序实现。java当中的方法只有final,static,private和构造方法是前期绑定。
<2>后期绑定是在运行时根据具体对象的类型进行绑定。动态绑定的过程:
1.虚拟机提取对象的实际类型的方法表;
2.虚拟机搜索方法签名;
3.调用方法。
-
【问题3】关于多态中的向上转型和向下转型要怎么理解?
-
解答 :参考重新认识java(五) ---- 面向对象之多态(向上转型与向下转型)、java多态向上转型向下转型的问题、java向上转型和向下转型或者唐才铭同学的博客问题
-
【问题4】对象及对象引用变量的理解?
-
解答 :参考Java对象及对象引用变量、Java对象和引用变量或者郭恺同学的博客问题2
-
【问题5】书中提到的两种查找算法的比较?
-
解答 :参考线性查找与二分查找法的差异
-
【问题6】不理解这句话:“实际调用的方法版本取决于对象的类型而不是引用变量的类型”?
-
解答 :参考被引用对象的类型而不是引用变量的类型决定了调用谁的成员方法,一个经典实例:
public class Polymorphism {
public static void main(String[] args) {
//既然是多态,java 中重载和重写都是多态的体现,你问的这句话肯定不属于重载则用重写来解释
// 这里声明了一把枪,变量为gun,但他却指向了一把Ak47对象,也就是说 gun虽然是Gun的引用,但实际是一个Ak47对象
//那么gun.shot其实调用的是Ak47.shot 而不是Gun自己的shot
Gun gun = new Ak47();
gun.shot();
}
}
class Gun {
public void shot() {
System.out.println("突!");
}
}
class Ak47 extends Gun {
public void shot() {
System.out.println("突!突!突!突!突!");
}
}
多态机制遵循的原则概括为:当超类对象引用变量引用子类对象时,被引用对象的类型而不是引用变量的类型决定了调用谁的成员方法,但是这个被调用的方法必须是在超类中定义过的,也就是说被子类覆盖的方法,但是它仍然要根据继承链中方法调用的优先级来确认方法,该优先级为:this.show(O)、super.show(O)、this.show((super)O)、super.show((super)O)。
-
【问题7】关于函数重载和重写的区别比较?
-
解答 :参考重载与重写的区别和重写、覆盖、重载、多态几个概念的区别分析
-
【问题8】关于多种排序算法的比较?
-
解答 :参考八大排序算法Java和视觉直观感受 7 种常用的排序算法
- 其他问题详见答疑论坛或云班课:https://group.cnblogs.com/pdds/
第 09 周 - 作业问题与解答
-
【问题1】异常中throw和throws区别?
-
解答 :参考throws和throw抛出异常的使用规则和
throw是语句抛出一个异常。 语法:throw (异常对象);
throws是方法可能抛出异常的声明。(用在声明方法时,表示该方法可能要抛出异常)。
语法:
(修饰符)(方法名)([参数列表])[throws(异常类)]{......}1、throws出现在方法函数头;而throw出现在函数体。
2、throws表示出现异常的一种可能性,并不一定会发生这些异常;throw则是抛出了异常,执行throw则一定抛出了某种异常对象。
3、两者都是消极处理异常的方式(这里的消极并不是说这种方式不好),只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
-
【问题2】错误和异常有什么区别?
-
解答 :参考Java----异常类(错误和异常,两者区别)
1).java.lang.Error: Throwable的子类,用于标记严重错误。合理的应用程序不应该去try/catch这种错误。绝大多数的错误都是非正常的,就根本不该出现的。
java.lang.Exception: Throwable的子类,用于指示一种合理的程序想去catch的条件。即它仅仅是一种程序运行条件,而非严重错误,并且鼓励用户程序去catch它。
2).Error和RuntimeException 及其子类都是未检查的异常(unchecked exceptions),而所有其他的Exception类都是检查了的异常(checked exceptions).
checked exceptions: 通常是从一个可以恢复的程序中抛出来的,并且最好能够从这种异常中使用程序恢复。比如FileNotFoundException, ParseException等。检查了的异常发生在编译阶段,必须要使用try…catch(或者throws)否则编译不通过。
unchecked exceptions: 通常是如果一切正常的话本不该发生的异常,但是的确发生了。发生在运行期,具有不确定性,主要是由于程序的逻辑问题所引起的。比如ArrayIndexOutOfBoundException, ClassCastException等。从语言本身的角度讲,程序不该去catch这类异常,虽然能够从诸如RuntimeException这样的异常中catch并恢复,但是并不鼓励终端程序员这么做,因为完全没要必要。因为这类错误本身就是bug,应该被修复,出现此类错误时程序就应该立即停止执行。 因此,面对Errors和unchecked exceptions应该让程序自动终止执行,程序员不该做诸如try/catch这样的事情,而是应该查明原因,修改代码逻辑。
RuntimeException:RuntimeException体系包括错误的类型转换、数组越界访问和试图访问空指针等等。
处理RuntimeException的原则是:如果出现 RuntimeException,那么一定是程序员的错误。例如,可以通过检查数组下标和数组边界来避免数组越界访问异常。其他(IOException等等)checked异常一般是外部错误,例如试图从文件尾后读取数据等,这并不是程序本身的错误,而是在应用环境中出现的外部错误。
-
【问题3】递归和迭代具体应该怎么去区分使用,两者具体的分别在哪些方面,哪些问题使用哪种更加方便?
-
解答 :参考深究递归和迭代的区别、联系、优缺点及实例对比
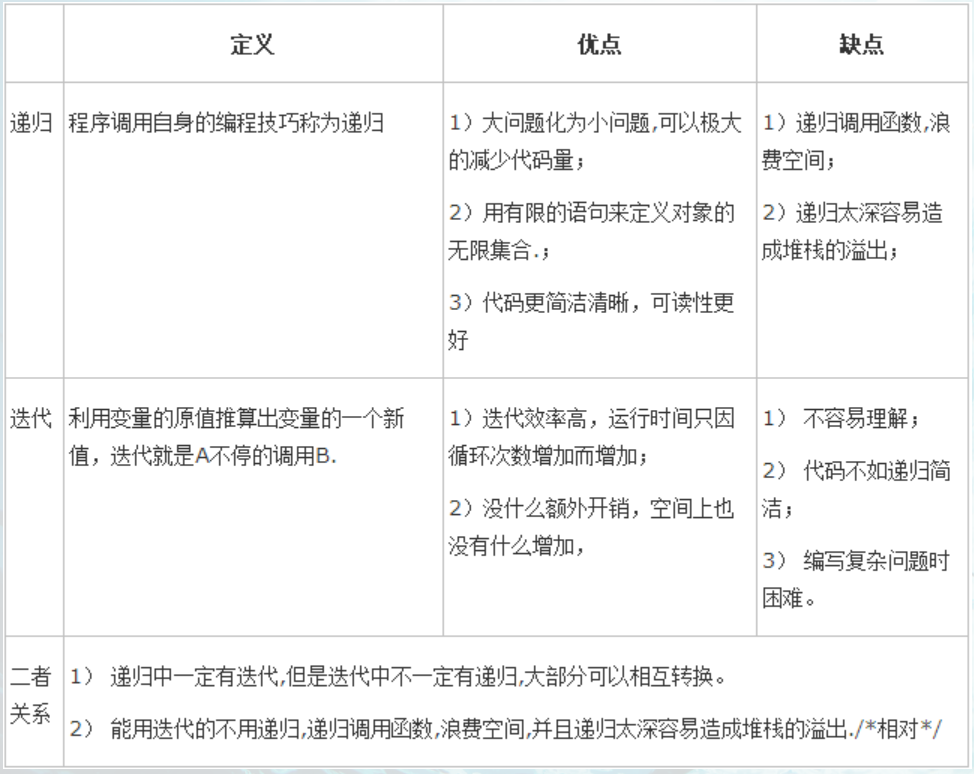

-
【问题4】可检测异常和不可检测异常的区别?
-
解答 :参考检查异常和未检查异常不同之处和java检查异常与非检查异常
-
【问题5】字节流和字符流的区别和用法?
-
解答 :参考理解Java中字符流与字节流的区别和字节流与字符流的区别&&用字节流好还是用字符流好?
在java.io包中操作文件内容的主要有两大类:字节流、字符流,两类都分为输入和输出操作。在字节流中输出数据主要是使用OutputStream完成,输入使的是InputStream,在字符流中输出主要是使用Writer类完成,输入流主要使用Reader类完成。(这四个都是抽象类)在所有的硬盘上保存文件或进行传输的时候都是以字节的方法进行的,包括图片也是按字节完成,而字符是只有在内存中才会形成的,所以使用字节的操作是最多的。两种写入文件的方式,但字节流的使用更重要。
-
【问题6】为什么可以对异常根本不进行处理?不进行处理不会导致程序出错吗?
-
解答 :对于不可检测的异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。
运行时异常:都是RuntimeException类及其子类异常,如NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。运行时异常的特点是Java编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。
非运行时异常 (编译异常):是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
-
【问题7】finally子句的作用?finally子句一定会被执行?
-
【问题8】关于语句
System.err和System.out的区别及具体用法? -
解答 :1、out:“标准”输出流。此流已打开并准备接受输出数据。通常,此流对应于显示器输出或者由主机环境或用户指定的另一个输出目标。
2、err:“标准”错误输出流。此流已打开并准备接受输出数据。通常,此流对应于显示器输出或者由主机环境或用户指定的另一个输出目标。按照惯例,此输出流用于显示错误消息,或者显示那些即使用户输出流(变量 out 的值)已经重定向到通常不被连续监视的某一文件或其他目标,也应该立刻引起用户注意的其他信息。
out和err的一个区别是,out往往是带缓存的,而err没有缓存(默认设置,可以改)。所以如果你用标准出错打印出来的东西可以马上显示在屏幕,而标准输出打印出来的东西可能要再积累几个字符才能一起打印出来。如果你在应用中混用标准输出和标准出错就可能看到这个问题。
测试代码:
public class Test2 {
static{
System.out.println("1");
}
public static void main(String[] args) {
System.err.println("2");
new Test2();
}
public Test2() {
System.out.println("3");
}
}
实验结果:
1,3的位置相对不变,2的位置随机出现
-
【问题9】IO流写入和读取文件的几种方式?
-
解答 :参考java中的IO操作总结(一)或者王老师讲的课堂实例:
import java.io.*;
public class FileTest {
public static void main(String[] args) throws IOException {
//(1)文件创建(文件类实例化)
File file = new File("C:\\Users\\besti\\Desktop\\FileTest","HelloWorld.txt");
if (!file.exists()){
file.createNewFile();
}
//(2)文件读写
//第一种:字节流读写,先写后读
OutputStream outputStream1 = new FileOutputStream(file);
byte[] hello = {'H','e','l','l','o',',','W','o','r','l','d','!'};
outputStream1.write(hello);
InputStream inputStream1 = new FileInputStream(file);
while (inputStream1.available()> 0){
System.out.print((char) inputStream1.read()+" ");
}
inputStream1.close();
//============================BufferedInputStream====================================
byte[] buffer = new byte[1024];
String content = "";
int flag = 0;
InputStream inputStream2 = new FileInputStream(file);
BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream2);
while ((flag =bufferedInputStream.read(buffer))!=-1){
content += new String(buffer,0,flag);
}
System.out.println(content);
bufferedInputStream.close();
//====================================BufferedOutputstream================================================
OutputStream outputStream2 = new FileOutputStream(file);
BufferedOutputStream bufferedOutputStream2 = new BufferedOutputStream(outputStream2);
String content2 = "写入文件的缓冲区内容";
bufferedOutputStream2.write(content2.getBytes(),0,content2.getBytes().length);
bufferedOutputStream2.flush();
bufferedOutputStream2.close();
//第二种:字符流读写,先写后读(两种读)
Writer writer2 = new FileWriter(file);
writer2.write("Hello, I/O Operataion!");
writer2.flush();
writer2.append("Hello,World");
writer2.flush();
BufferedWriter bufferedWriter = new BufferedWriter(writer2);
String content3 = "使用bufferedWriter写入";
bufferedWriter.write(content3,0,content3.length());
bufferedWriter.flush();
bufferedWriter.close();
Reader reader2 = new FileReader(file);
System.out.println();
while(reader2.ready()){
System.out.print((char) reader2.read()+ " ");
}
BufferedReader bufferedReader = new BufferedReader(reader2);
while ((content =bufferedReader.readLine())!= null){
System.out.println(content);
}
}
}
-
【问题10】关于杨辉三角的实现及输出排版?
-
解答 :参考java编程实现杨辉三角两种输出结果实例代码
- 其他问题详见答疑论坛或云班课:https://group.cnblogs.com/pdds/
第 10 周 - 作业问题与解答
-
【问题1】数据库的简单操作?
-
解答 :参考Intellj IDEA 简易教程-数据库或者蓝墨云班课上第十二周的资源。
-
【问题2】关于xampp中端口占用问题如何解决?
-
解答 :参考Apache服务无法启动的解决办法
-
【问题3】persistence (持续化)和 serialization(序列化)区别?
-
解答 :参考序列化和持久化的区别与联系及郭恺同学的博客
序列化和持久化很相似,有些人甚至混为一谈,其实还是有区别的,序列化是为了解决对象的传输问题,传输可以在线程之间、进程之间、内存外存之间、主机之间进行。我之所以在这里提到序列化,是因为我们可以利用序列化来辅助持久化,可以说凡是可以持久化的对象都可以序列化,因为序列化相对容易一些(也不是很容易),所以主流的软件基础设施,比如.net和java,已经把序列化的框架完成了。
所以,序列化只是辅助持久化而已,是有一定区别的,换句话说,实现持久化就可以实现序列化。
-
【问题4】ArrayList和Linked和Vector的区别
-
解答 :参考Vector,ArrayList, LinkedList的区别
1.Vector、ArrayList都是以类似数组的形式存储在内存中,LinkedList则以链表的形式进行存储。
2.List中的元素有序、允许有重复的元素,Set中的元素无序、不允许有重复元素。
3.Vector线程同步,ArrayList、LinkedList线程不同步。
4.LinkedList适合指定位置插入、删除操作,不适合查找;ArrayList、Vector适合查找,不适合指定位置的插入、删除操作。
5.ArrayList在元素填满容器时会自动扩充容器大小的50%,而Vector则是100%,因此ArrayList更节省空间。
-
【问题5】关于队列、图等数据结构如何用代码来实现?
-
解答 :在这里仅做适当了解就可以了,可参考java队列实现(顺序队列、链式队列、循环队列)、数据结构--图 的JAVA实现(下)、java中图的两种存储方式和【算法导论-37】Graph的Java实现及范雯琪同学的博客
-
【问题6】关于Java集合类API和泛型的理解?
-
解答 :参考黑马程序员——Java基础:集合类、泛型或者蓝墨云上的资源。

-
【问题7】“数组与链表为同级”,那他们可以互换吗,或者彼此替代吗?
-
解答 :参考数组和链表的区别
数组的特点:
1、在内存中,数组是一块连续的区域。
2、数组需要预留空间,在使用前要先申请占内存的大小,可能会浪费内存空间。 比如看电影时,为了保证10个人能坐在一起,必须提前订好10个连续的位置。这样的好处就是能保证10个人可以在一起。但是这样的缺点是,如果来的人不够10个,那么剩下的位置就浪费了。如果临时有多来了个人,那么10个就不够用了,这时可能需要将第11个位置上的人挪走,或者是他们11个人重新去找一个11连坐的位置,效率都很低。如果没有找到符合要求的作为,那么就没法坐了。
3、插入数据和删除数据效率低,插入数据时,这个位置后面的数据在内存中都要向后移。删除数据时,这个数据后面的数据都要往前移动。 比如原来去了5个人,然后后来又去了一个人要坐在第三个位置上,那么第三个到第五个都要往后移动一个位子,将第三个位置留给新来的人。 当这个人走了的时候,因为他们要连在一起的,所以他后面几个人要往前移动一个位置,把这个空位补上。
4、随机读取效率很高。因为数组是连续的,知道每一个数据的内存地址,可以直接找到给地址的数据。
5、并且不利于扩展,数组定义的空间不够时要重新定义数组。链表的特点:
1、在内存中可以存在任何地方,不要求连续。
2、每一个数据都保存了下一个数据的内存地址,通过这个地址找到下一个数据。 第一个人知道第二个人的座位号,第二个人知道第三个人的座位号……
3、增加数据和删除数据很容易。 再来个人可以随便坐,比如来了个人要做到第三个位置,那他只需要把自己的位置告诉第二个人,然后问第二个人拿到原来第三个人的位置就行了。其他人都不用动。
4、查找数据时效率低,因为不具有随机访问性,所以访问某个位置的数据都要从第一个数据开始访问,然后根据第一个数据保存的下一个数据的地址找到第二个数据,以此类推。 要找到第三个人,必须从第一个人开始问起。
5、不指定大小,扩展方便。链表大小不用定义,数据随意增删。综上所述:
同级只是它们的共同点之一,不同仅仅以这样一个标准就去认为可以互换,实际上讲,各个都有彼此的优点,互换的也仅仅是方法,各自有实现目标的办法,只是有些方法复杂,有些比较简单而已,所以讲,从实际问题上讲,是可以互换的,但是不能直接讲位置互换就可以,需要进行方法内部的修改,然后发现问题,及时修改。
-
【问题8】数据结构和抽象数据类型的区别和联系?
-
解答 :参考赵晓海同学的博客
数据结构:总是为了完成一个功能或者目的写程序,但不管什么程序、代码实际上都是一些指令的集合,说白了就是在描述“怎么做”,而光知道怎么做还只是问题的一半,还要知道“做什么”,也就是刚才那些指令的对象是谁,自然肯定是相关的数据,比如说学生信息管理中,指令是增加学生,那他的对象就是学生信息这种数据,指令是成绩统计,那对象就是学生的成绩数据,而在我们的程序中,数据也必须要有一种很明确的组织表示方式,只要这样我们才能在这种具体明确的实体上编写指令,比如说学生数据可以定义为一个多维的数组,只有这样我们再写增加学生时,才能知道具体增加就是增加一个数组元素并为其赋值。所以数据结构就是相互之间有联系的具有某种组织方式的数据集合。
抽象数据类型相比较数据结构要具体一些,我们光有了数据结构还不够,因为数据是各种各样的,对于不同数据,我们能采取的方法也不一样,比如说学生数据可以增减,成绩数据可以进行算数运算,但是为什么说抽象呢,也就说他并不是具体整型还是字符型这种基本类型,而是我们根据我们要解决的实际问题,对应现实世界所描述的一种和现实世界中的实体对应的数据类型,而且这种抽象的数据类型还包括能够对于他实行的操作,比如说我们定义一种数据类型叫“学生”,具体的数据我可以定义一中类似表的结构存储,而且还要定义一些操作,比如说添加学生,删除学生,这两部分就共同组成了“学生”这个抽象的数据类型。
-
【问题9】动态链表节点增加、插入和删除步骤的原理?
-
解答 :参考java中单项链表实现方法:增加、删除、插入数据
-
【问题10】在学习堆栈过程中,不理解“与Stack类不同的是,在JavaAPI中没有实现队列的类。”是什么意思?
-
解答 :参考李馨雨同学的博客
先去了解javaAPI到底是什么:
API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件的以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。
运行Java程序时,虚拟机装载程序的class文件所使用的Java API class文件。所有被装载的class文件(包括从应用程序中和从Java API中提取的)和所有已经装载的动态库(包含本地方法)共同组成了在Java虚拟机上运行的整个程序。
再去了解一下队列的使用:
在java5中新增加了java.util.Queue接口,用以支持队列的常见操作。Queue接口与List、Set同一级别,都是继承了Collection接口。

javaAPI中没有实现队列的类,所以只能通过Queue接口来实现队列。
- 其他问题详见答疑论坛或云班课:https://group.cnblogs.com/pdds/
第 11 周 - 作业问题与解答
-
【问题1】什么是生命活动周期方法?
-
解答 :生命周期很好理解,但是在后面加上方法就显得有些抽象。书上也很详细的将其中每个具体方法进行讲解。但是,具体到一个app中是怎样的呢?先用一个图进行理解(图)onCreate和onDestroy方法在每个生命周期中只执行一次,而其他均可循环。这里着重探究onPause、onStop、onDestroy方法。
1.当活动开始进入运行阶段后,假如用户执行其他活动时,就需要执行onPause操作,使得减少资源的浪费。而此时的内存依旧占用。此时,activity仍然处于部分可见的状态。
2.当活动调用onStop方法时,首先,活动将处于不可见状态。但是它依然保持所有状态和成员信息,但是它不再可见,所以它的窗口被隐藏,当系统内存需要被用在其他地方的时候,Stopped的Activity将被杀掉。
3.当Activity(用户调用finish()或系统由于内存不足)被系统销毁杀掉时系统调用,(整个生命周期只调用1次)用来释放onCreate()方法中创建的资源,如结束线程等。
参考android 活动的生命周期,还可以把整个活动周期分成三个部分:
- 完整生存期:onCreate()方法和onDestroy()之间,总共调用了6个方法。
- 可见生存期:活动在onStart()方法和onStop()之间,总共4个方法,再加上重新运行的onRestart()方法,总共5个。
- 前台生存期:活动在onResume()方法和onPause()方法,总共2个方法。
活动生命周期图解:
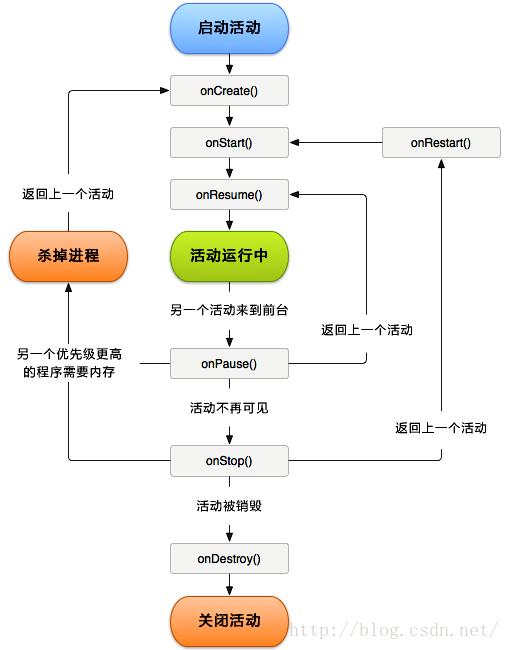
-
【问题2】对于Android事件和监听器不是很理解。
-
解答 :参考Android事件和监听器详细的介绍
监听器是一个存在于View类下的接口,一般以On**Llistener命名,实现该接口需要复写相应的on(View v)方法(如onClick(View v))。
监听器的三种实现方法:
方法一:在Activity中定义一个内部类继承监听器接口(这里是OnClickListener)。常见的继承方法如下:
class MyListener implements View.OnClickListener{
@Override
public void onClick(View v) {
Toast.makeText(MainActivity.this,"you have clicked Button2",Toast.LENGTH_SHORT).show();
}
}
方法二:实现匿名内部类。这种方法适合只希望对监听器进行一次性使用的情况,在该代码块运行完毕之后,该监听器也就不复存在了。
bt1.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
Toast.makeText(MainActivity.this,"you have clicked Button1",Toast.LENGTH_SHORT).show();
}
});
方法三:利用布局文件中的onClick属性,并在实现文件中实现该方法。注意的是这里的方法名应该和布局文件中onClick属性的方法名相同,该方法必须是public方法。
// 方法三,注意需要public方法
public void onButtonClick (View view){
Toast.makeText(MainActivity.this,"you have clicked Button3",Toast.LENGTH_SHORT).show();
}
}
-
【问题3】Android Studio 里加载的R类究竟是什么?
-
解答 :R类是AS中看不到的一个通用类,可以在
app/build/generated/source目录下找到它。每当添加、修改或者删除资源时,都会重新生成R。R的作用是让你可以在代码中引用一个资源。

R类的作用是让你能够引用代码中的一个资源:
1)layout下中的andoid:id、android:text等资源信息等
2)string对应的字段是res/values/strings.xml中的配置项信息(自动生成的,不需要认为的修改R类,包含id也一样)。
3)@color查找颜色:color对应的字段是res/values/colors.xml中的配置项信息(自动生成的,不需要认为的修改R类,包含id也一样)。
4)@drawable查找图片:只需要把png/jpeg/gif文件拷贝到新建的/res/drawable目录下,或者拷贝到工程新建的默认drawable-xx目录下
5)@dimen某个组件尺寸定义:需要在res/values/目录下新建一个dimen.xml文件.
-
【问题4】对活动程序的文件目录结构要怎么理解?
-
解答 :文件目录如下图所示:
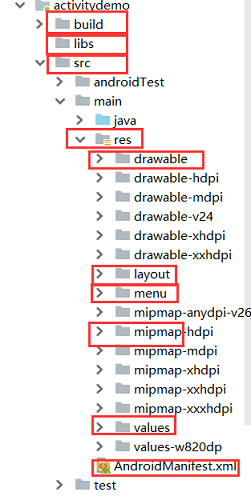
-
build:该目录包含了自动生成的文件,这些文件包括了编译设置项、R类等
-
libs:该目录包含了开发Android应用所需要的库文件
-
src:该目录存放了应用的源代码.java文件。默认情况下,它包含了MainActivity.java文件,这个源代码j有一部分是执行了你点击应用图标时启动应用所需要功能
- res:该目录存放了所有的资源文件
- drawable:该目录存放了项目的drawable对象和一些图片资源
- layout:该目录存放了各个界面的布局文件
- menu:该目录存放了应用中设计的菜单对象
- mipmap:该目录存放了应用的主要图片资源
- values:该目录存放了字符串、颜色等定义的资源集合
- AndroidManifest.xml:该文件是描述应用基础特性的文件,定义了每个组件。
-
-
【问题5】apk文件的签名是什么意思?
-
解答 :计算机中所说的签名和生活中所说的签名在本质上是一样的,Android系统要求每一个Android应用程序必须要经过数字签名才能够安装到系统中,也就是说如果一个Android应用程序没有经过数字签名,是没有办法安装到系统中的!Android通过数字签名来标识应用程序的作者和在应用程序之间建立信任关系,不是用来决定最终用户可以安装哪些应用程序。这个数字签名由应用程序的作者完成,并不需要权威的数字证书签名机构认证,它只是用来让应用程序包自我认证的。
-
【问题6】Android Studio 里加载的Gradle到底是指什么?
-
解答 :参考Android Studio中的Gradle是干什么的
专业解释:
Gradle是一个基于Apache Ant和Apache Maven概念的项目自动化建构工具。它使用一种基于Groovy的特定领域语言来声明项目设置,而不是传统的XML。当前其支持的语言限于Java、Groovy和Scala,计划未来将支持更多的语言。
较好地解释:
软件开发讲究代码复用,通过复用可以使工程更易维护,代码量更少..... 开发者可以通过继承,组合,函数模块等实现不同程度上的代码复用.但不知你有没有想过,软件开发也是一种工程作业,绝不仅仅是写代码,还涉及到工程的各种管理(依赖,打包,部署,发布,各种渠道的差异管理.....),你每天都在build,clean,签名,打包,发布,有没有想过这种过程,也可以像代码一样被描述出来, 也可以被复用。
总结地说:
1、Gradle是一种构建工具,它可以帮你管理项目中的差异,依赖,编译,打包,部署......,你可以定义满足自己需要的构建逻辑,写入到build.gradle中供日后复用;
2、Gradle不是一种编程语言,它不能帮你实现软件中的任何实际功能。
-
【问题7】在运行书上相关代码时,R文件变红,如何处理?
-
解答 :以前用studio是R文件是不报错的。当你从其他程序拷过一些代码是会发现R文件会变红并且应用程序不能运行。除了R文件其他地方没有报错,只有app运行时会报错 。
这是因为当你从其他程序拷过一些代码。你的r文件中没有自动加载,这时你需要把那些报错的代码删除并重新在Android studio中输入,这样你的应用程序就可以运行了。也可以试着用rebuild project.
-
【问题8】在运行书上相关代码时,menu文件报红,如何处理?
-
解答 :menu文件主要是因为没有导入,但是如果想自己新建的话要注意menu布局文件要在menu文件夹地下创建才行,应该先在res文件夹右键,然后选择
New>Android resource directory,出现界面后在Resource type下拉栏选择menu。接着在menu文件夹下右键,New>Menu resource file之后输入文件名就可以了.
-
【问题9】Android Studio 里加载的Manifest.xml是什么?
-
【问题10】显式意图和隐式意图代表什么?区别?
-
解答 :参考Intent的显式意图和隐士意图
对意图的理解:
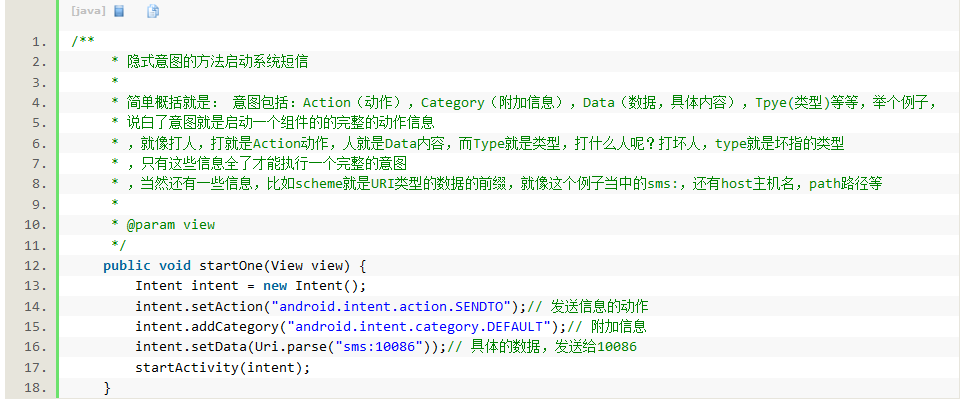
显式意图:调用Intent.setComponent()或Intent.setClass()方法明确指定了组件名的Intent为显式意图,显式意图明确指定了Intent应该传递给哪个组件。
隐式意图:没有明确指定组件名的Intent为隐式意图。 Android系统会根据隐式意图中设置的动作(action)、类别(category)、数据(URI和数据类型)找到最合适的组件来处理这个意图。简单概括就是: 意图包括:Action(动作),Category(附加信息),Data(数据,具体内容),Tpye(类型)等等,举个例子,说白了意图就是启动一个组件的的完整的动作信息,就像打人,打就是Action动作,人就是Data内容,而Type就是类型,打什么人呢?打坏人,type就是坏指的类型,只有这些信息全了才能执行一个完整的意图,当然还有一些信息,比如scheme就是URI类型的数据的前缀,就像这个例子当中的sms:,还有host主机名,path路径等。
-
【问题11】如何将Android studio项目上传至码云?
-
解答 :参考Android studio项目上传至oschina(码云)教程(感谢张昊然同学的分享)
- 其他问题详见答疑论坛或云班课:https://group.cnblogs.com/pdds/
第 12 周 - 作业问题与解答
-
【问题1】关于计算MD5使用的类、生成MD5摘要的示例?
-
解答 :参考使用javaAPI生成MD5摘要
-
【问题2】实验五-密码学相关算法参考资料及示例。
-
解答 :参考Java 密码学算法
关于DH算法,亦可参考下图,计算出的共享秘钥是g^(ab):
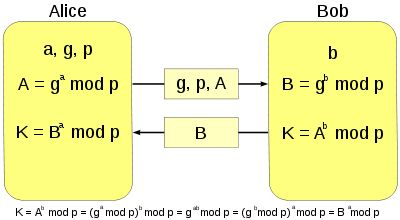
-
【问题3】什么是协商密钥?
-
解答 :协商密钥的意思就是客户端给服务器发送个数据,然后服务器再给客户端发送数据。客户端根据接收到服务器的数据,然后根据自己再加上自己的私钥计算出一个密钥。然后服务器,是根据客户端发送数据,再加上自己的私钥在计算出一个秘钥。这样就能协商出来,他计算出来的秘钥两个是一模一样的。这就是迪福哈尔曼那个协议的妙处。
-
【问题4】关于实验五-第三个实验:如何传给服务器密钥?

-
解答 :第一种方法,通过传递原文的方式将其传递过去,但是这里就会有问题,因为,我们不清楚到底是如何去传递两个东西,我们并没有被要求去用双线程,况且我们也没有那么厉害,因此通过和余坤澎同学的讨论,我们可以用这个方法进行将两个东西传递过去,举个例子:假如我们现在要传递字符串A和字符串B,但是我们怎么把两个东西一起传递过去呢,首先我们想到,就字符串有一个
split的方法,我们可以利用这个方法把这两个字符串用一个字符进行切分,然后分别保存,比如String aa =A;B,我们用String []bb =aa.split";";就可以将其分成bb[0]和bb[1]这样就把两个东西都传递过去了。(参考王文彬同学的博客)第二种方式,用文件直接拷贝过去就可以。
-
【问题5】关于实验五-第三个实验:即将字节型数组的密文转换成String类型时,传输过来时,总是会出现乱码,结果导致没有办法解密。
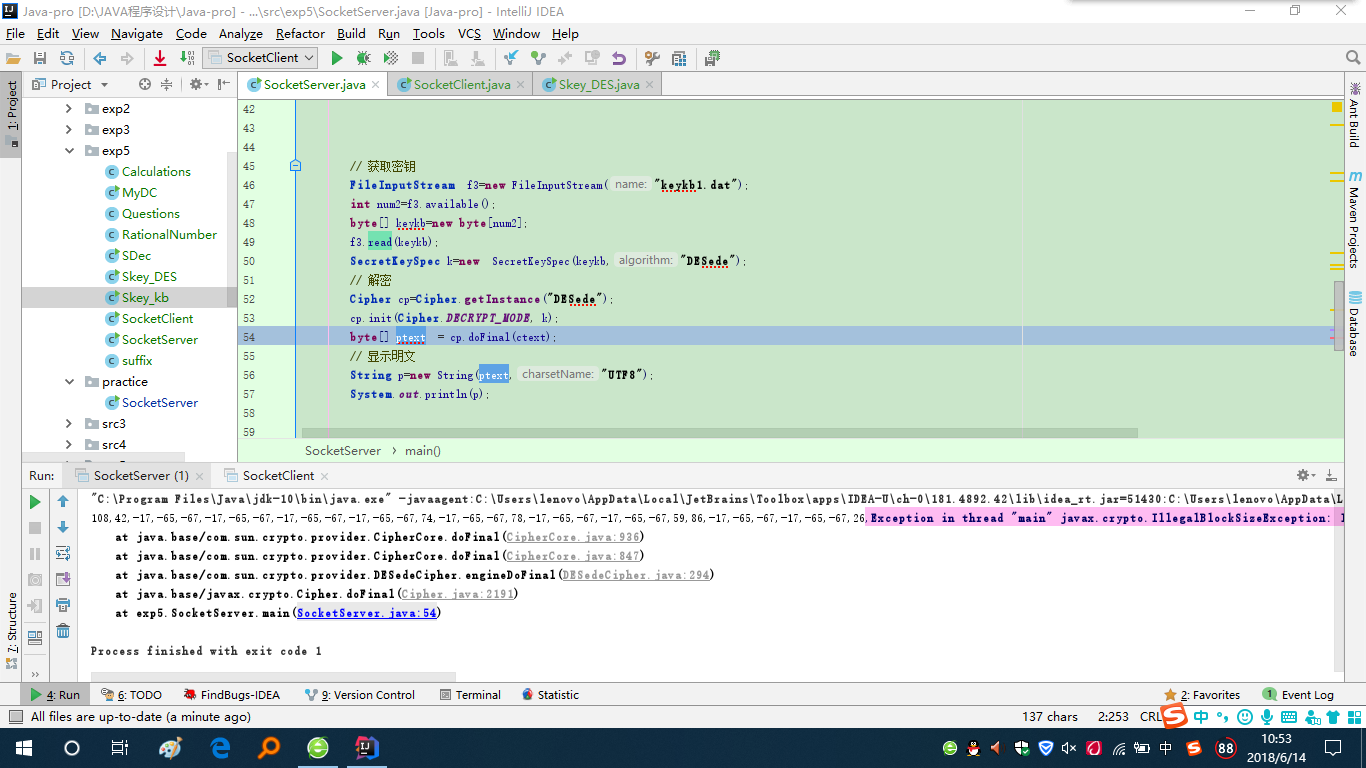
-
解答 :这里显示的密文是不合法的,我们在这里卡了很久,最后采用的是不再进行转换成String类型的转换,我们直接将密文的byte数组使用字节流传输,接收时使用一个byte的数组进行接收,这里就没有问题了,具体代码是客户端是
outputStream.write(ctext);outputStream.flush();,服务器是byte[] ctext = inputStream.readAllBytes();,最后就是这样,将密文传输过来,并完成后续步骤。(参考侯泽洋同学的博客)
-
其他问题详见答疑论坛或云班课:https://group.cnblogs.com/pdds/
(一共十三次问题收集与解答整理完毕,大部分从同学们的博客中摘录,少部分来源于云班课和QQ群)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号