(6)YOLOv4
嗯,这个v4我觉得吧创新谈不上,就是会有一些tricks,作者整理了大量的tricks并做了对比,最终为yolov4选择了一套方案,所以想借这个机会刚好介绍在目标检测中的一些tricks:
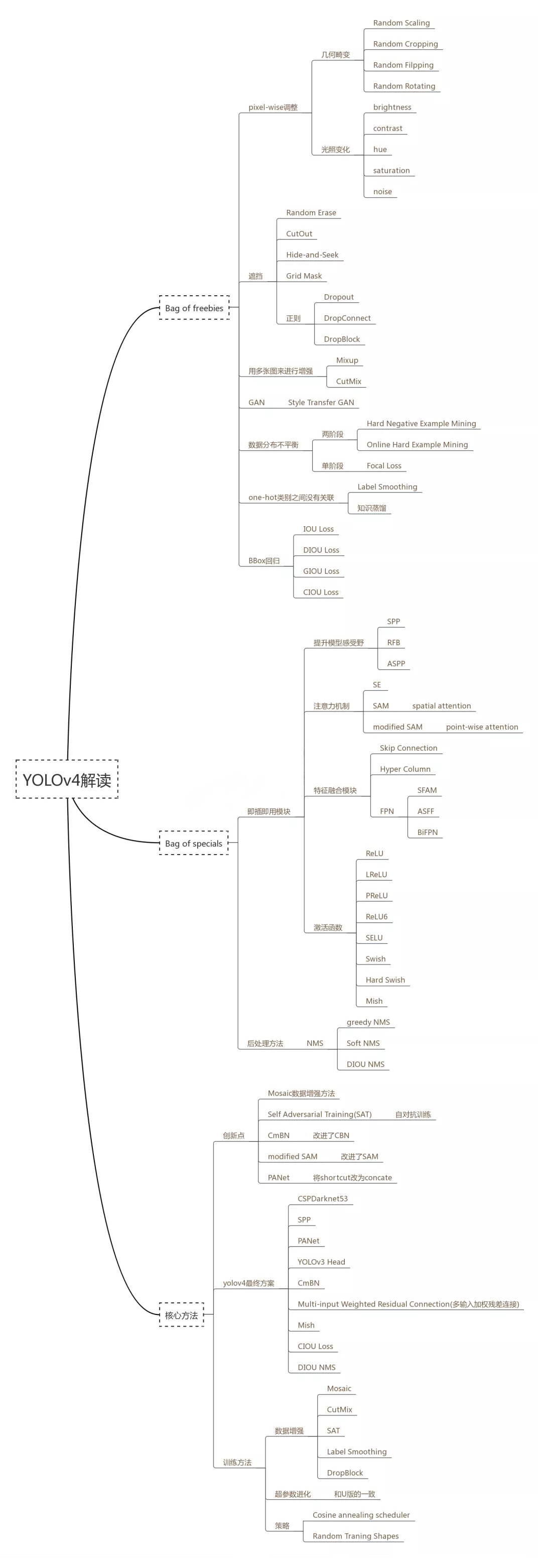
首先我们要理解在目标检测中主要是由三部分组成的:Object Detection = Backbone + Neck + Head
Backbone:骨干。提取图像特征的部分,这部分可以很好的借鉴一些设计好并且已经训练好的网络,例如(VGG16,19,ResNet-50, ResNeXt-101, Darknet53), 同时还有一些轻量级的backbone(MobilenetV1,2,3 ShuffleNet1,2)。
Neck:将backbone提取的特征进行进一步处理的过程,方便检测,这部分典型的有(SPP,ASPP in deeplabV3+,RFB,SAM),还有一些(FPN, PAN, NAS-FPN, BiFPN, ASFF, SFAM)。
Head:检测头。输出你想要的结果,例如想得到一个heatmap,(如在centernet中),那就增加一些反卷积层来一层一层反卷积回去。如果想直接得到bbox,那就可以接conv来输出结果,例如Yolo,ssd这些。亦或是想输出多任务(mask-RCNN)那就输出三个head:classification,regression,segmentation(就是mask那部分)。
目标检测的tricks也大都针对这三个方面的,我主要按照上面的图来介绍下:
1.bag of freebies
和意思一样就是赠品,不用消耗额外的资源,也就是不会影响速度,就可以提高精度,这里面主要是包括了一些在训练的时候使用的数据增强技术:
pixel-wise 调整
几何畸变和光照变化
这个参考之前v3写的随笔,里面都有。
遮挡
这个看这里.
drop out
看这里
归一化
看这里
BBOX回归损失
看这里
2.Bag of specials
就是会稍微增加模型复杂度和速度的技巧
提升模型感受野
SPP
这个之前就已经分享过了,在介绍faster rcnn的时候提到过,但是faster rcnn的源码却没有使用,而是用的resize。具体的结构还是这张图:
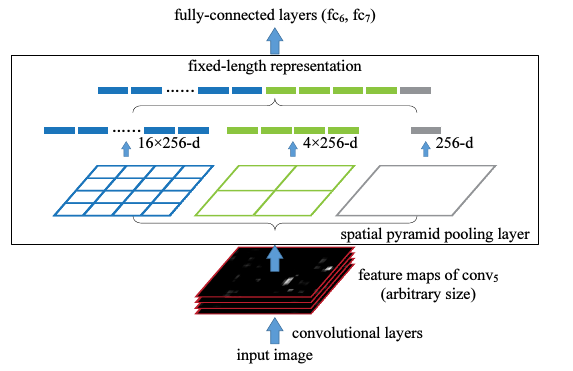
具体的细节可以回去看。
ASPP
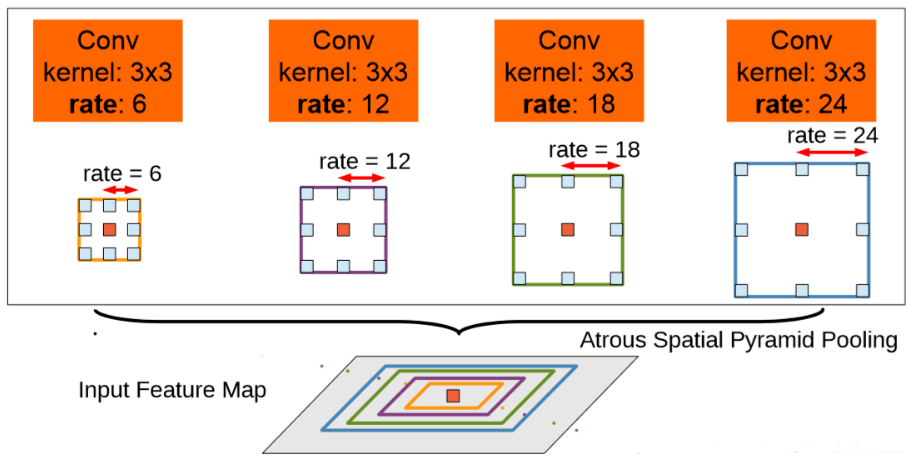
ASPP和SPP的差别是,并不是采用max pool得到不同感受野的特征图,而是采用卷积实现,且其kernel size全部是3,但是引入了不同的空洞率来变相扩大感受野。其余操作和SPP一致,ASPP来自DeepLab论文。空洞卷积的概念:
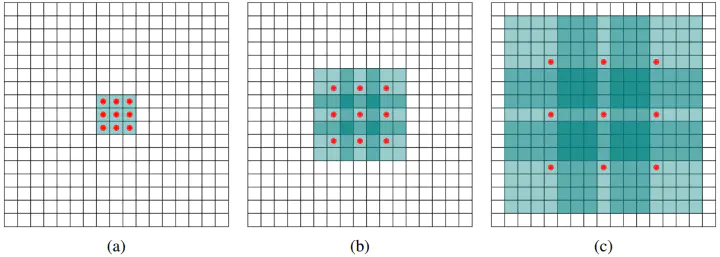
(a)图对应3x3的1-dilated conv,和普通的卷积操作一样,(b)图对应3x3的2-dilated conv,实际的卷积kernel size还是3x3,但是空洞为1,也就是对于一个7x7的图像patch,只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。 可以看到虽然kernel size只有3x3,但是这个卷积的感受野已经增大到了7x7(如果考虑到这个2-dilated conv的前一层是一个1-dilated conv的话,那么每个红点就是1-dilated的卷积输出,所以感受野为3x3,所以1-dilated和2-dilated合起来就能达到7x7的conv),(c)图是4-dilated conv操作,同理跟在两个1-dilated和2-dilated conv的后面,能达到15x15的感受野。对比传统的conv操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野,也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。
论文链接:https://arxiv.org/abs/1711.07767
代码链接:https://github.com/ruinmessi/RFBNet
论文思想:
- 人类的视觉系统是由多个具有不同感受野的部分复合而成的。而一般的CNN每层的感受野都是固定的,这会损失一些信息,失去对不同视野的分辨能力,比如靠近中心部分的更重要、需要被强化等。
- 看到1,可能有些人自然而然地会想起Inception。确实,Inception模块的并行结构采用的就是不同大小的卷积核,确实是将不同的感受野综合起来了。但是作者说,Inception中所有的kernels采样中心是相同的。根据之前提到的发现,不同的感受野应该具备不同的离心率,套用到CNN网络,kernels越大,采样点应该离中心点越远,应该尽可能地分布地比较散而不是像Inception那样kernel大小变化了仍然聚在一起。 因此,作者给出的最后设计草稿是这样的:
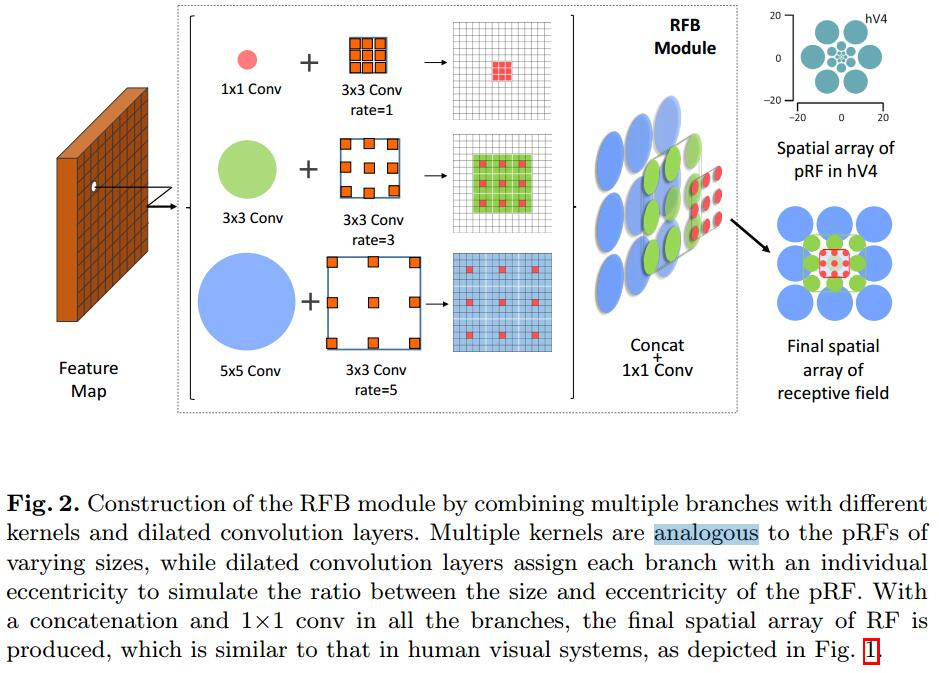
大致思想就是通过调节空洞卷积的rate来调节不同大小的卷积核的离心率,比如5x5分支的采样点和中心的距离就比3x3和1x1的更远。
注意力机制
SE
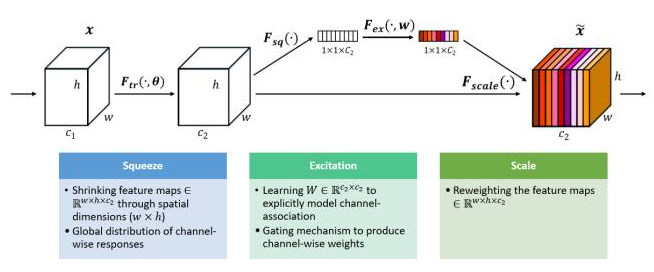
给定一个输入x,其特征通道数为c_1,通过一系列卷积等一般变换后得到一个特征通道数为c_2的特征。接下来通过三个操作来重标定前面得到的特征。
首先是Squeeze操作,顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
其次是Excitation操作,它是一个类似于循环神经网络中门的机制。通过参数 来为每个特征通道生成权重,其中参数 被学习用来显式地建模特征通道间的相关性。
最后是一个Reweight的操作,我们将Excitation的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
SAM
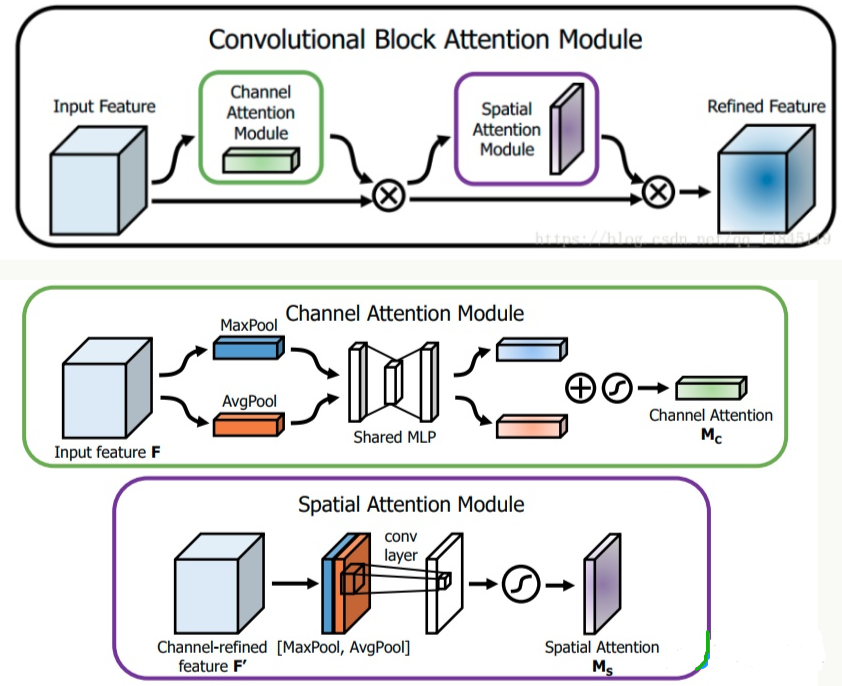
SAM是CBAM论文中的空间注意力模块。其流程是:将Channel attention模块输出特征图作为本模块的输入特征图。首先做一个基于channel的global max pooling 和global average pooling,然后将这2个结果基于channel 做concat操作。然后经过一个卷积操作,降维为1个channel。再经过sigmoid生成spatial attention feature。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
SE模块可以提升大概1%的ImageNet top-1精度,增加2%计算量,但推理时有10%的速度损失,对GPU不太友好,而SAM模块仅仅增加0.1%计算量,提升0.5%的top-1准确率,故本文选择的其实是SAM模块。
yolov4对SAM进行简单修改,如下所示:
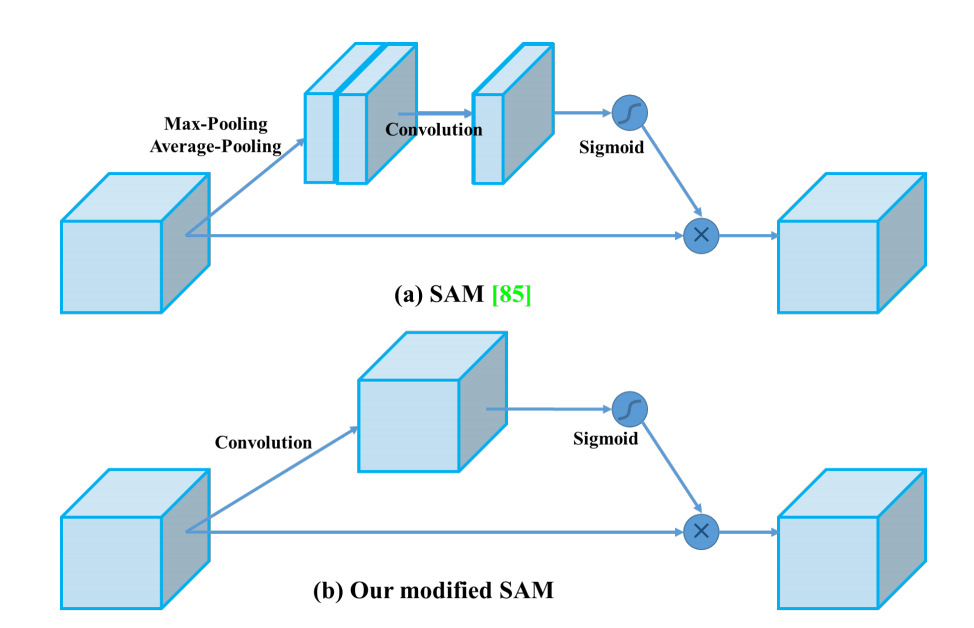
修改spatial-wise attention 为 pointwise attention,简化了流程,目的应该也是为了提高训练速度。
特征融合
FPN
这个和v3介绍的部分一样
PAN
PAN来自论文:Path Aggregation Network for Instance Segmentation。其结构如下所示:
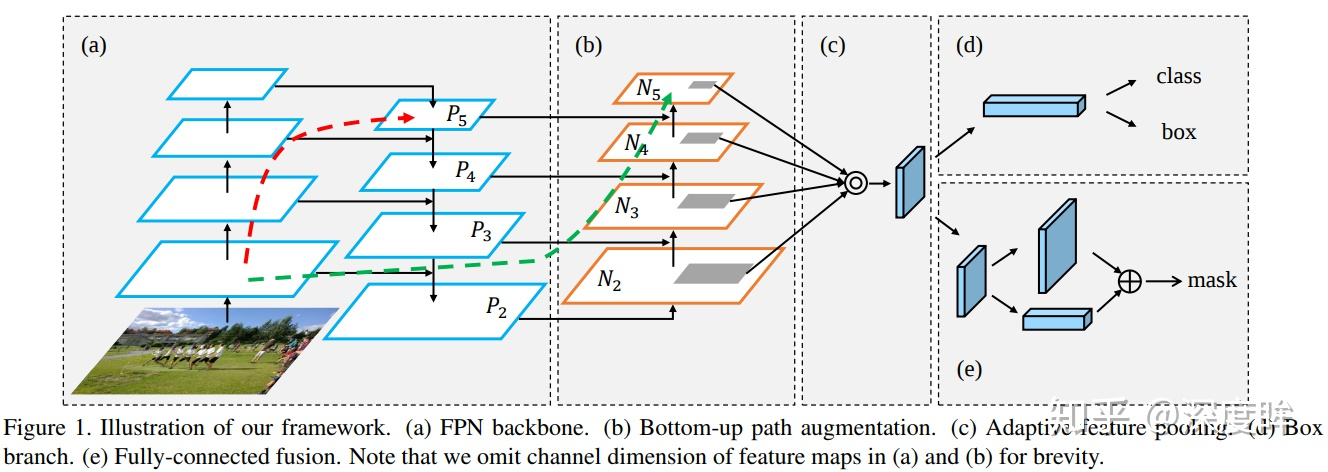
PAN增加了b的down-top的路径,这是因为PAN论文作者觉得low-level的feature很有利于定位,虽然FPN中P5也间接融合了low-level的特征,但是信息流动路线太长了如红色虚线所示,其中会经过超多conv操作,本文在FPN的P2-P5又加了low-level的特征,最底层的特征流动到N2-N5只需要经过很少的层如绿色需要所示,主要目的是加速信息融合,缩短底层特征和高层特征之间的信息路径。
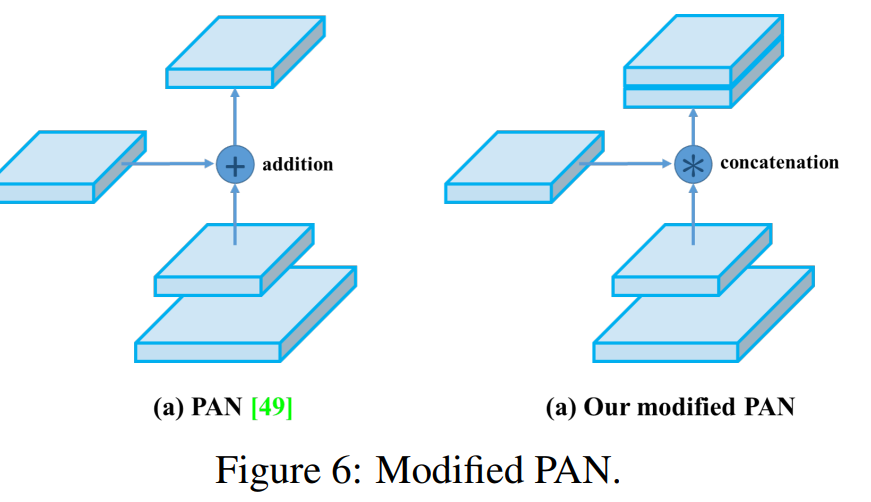
yolov4对它进行了改进,主要是特征融合操作由addition变成了concatenation:
SFAM
SFAM来自M2det: A single-shot object detector based on multi-level feature pyramid network。
-
paper地址:https://arxiv.org/abs/1811.04533
-
GitHub地址:https://github.com/qijiezhao/M2Det
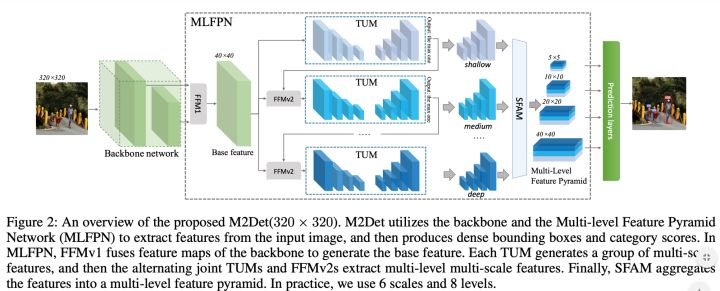
这篇论文提出多级特征金字塔网络MLFPN,M2det中的SFAM,比较复杂,它是先把C3与C5两个stage的特征融合成一个与C3分辨率相同的特征图(下图中的FFM1模块),然后再在此特征图上叠加多个UNet(下图中的TUM模块),最后将每个UNet生成的多个分辨率中相同分辨率特征一起融合(下图中的SFAM模块),从而生成最终的P3、P4、P5、P6特征,以供检测头使用。具体如下图。
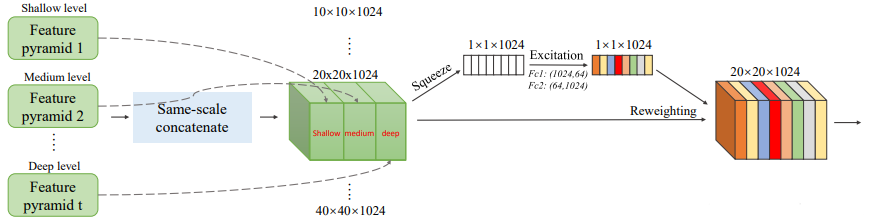
SFAM全称是Scale-wise Feature Aggregation Module,不同尺度的特征进行重组和融合,基本原理是对不同TUM的输出(每个TUM有6个不同尺度的输出),将其中相同尺度的特征进行concat,然后经过一个SE模块(对通道进行reweighting)输出,然后进行检测。其实就是把相同尺度的各层金字塔特征提取出来,然后concat,经过se模块,进行通道加权,再进行后续的预测,实现对不同通道进行不同加权功能。看起来开销有点大呀,因为要多个stage。和FPN及其改进版本的不同是SFAM的融合是尺度感知的,只融合相同尺度的特征,而不是像FPN那样,强制上下采样然后进行融合。
ASFF(自适应空间特征融合)
ASFF在YOLOV3的FPN的基础上,采用了注意力机制。FPN操作是一个非常常用的用于对付大小尺寸物体检测的办法,作者指出FPN的缺点是不同尺度之间存在语义gap,举例来说基于iou准则,某个gt bbox只会分配到某一个特定层,而其余层级对应区域会认为是背景(但是其余层学习出来的语义特征其实也是连续相似的,并不是完全不能用的),如果图像中包含大小对象,则不同级别的特征之间的冲突往往会占据要素金字塔的主要部分,这种不一致会干扰训练期间的梯度计算,并降低特征金字塔的有效性。一句话就是:目前这种concat或者add的融合方式不够科学。本文觉得应该自适应融合,自动找出最合适的融合特征, 简要思想就是:原来的FPN add方式现在变成了add基础上多了一个可学习系数,该参数是自动学习的,可以实现自适应融合效果,类似于全连接参数。 ASFF具体操作包括 identically rescaling和adaptively fusing。
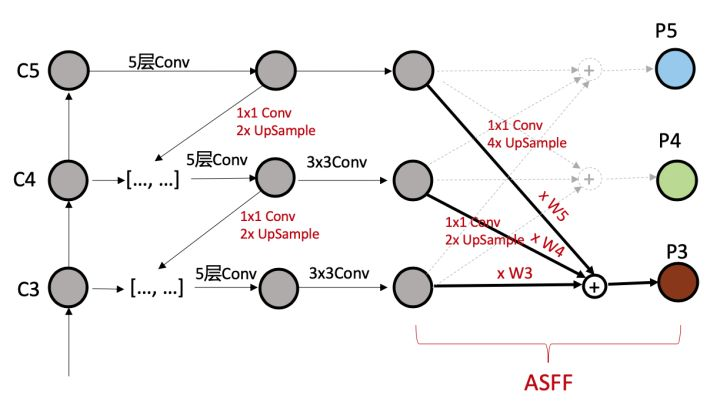
具体操作为:
(1) 首先对于第l级特征图输出cxhxw,对其余特征图进行上下采样操作,得到同样大小和channel的特征图,方便后续融合
(2) 对处理后的3个层级特征图输出,输入到1x1xn的卷积中(n是预先设定的),得到3个空间权重向量,每个大小是nxhxw
(3) 然后通道方向拼接得到3nxhxw的权重融合图
(4) 为了得到通道为3的权重图,对上述特征图采用1x1x3的卷积,得到3xhxw的权重向量
(5) 在通道方向softmax操作,进行归一化,将3个向量乘加到3个特征图上面,得到融合后的cxhxw特征图
(6) 采用3x3卷积得到输出通道为256的预测输出层
BiFPN
BiFPN来自论文:EfficientDet: Scalable and efficient object detection 。ASFF思想和BiFPN非常类似,也是可学习参数的自适应加权融合,但是比ASFF更加复杂。来看一下文中对这些FPNs的总结:
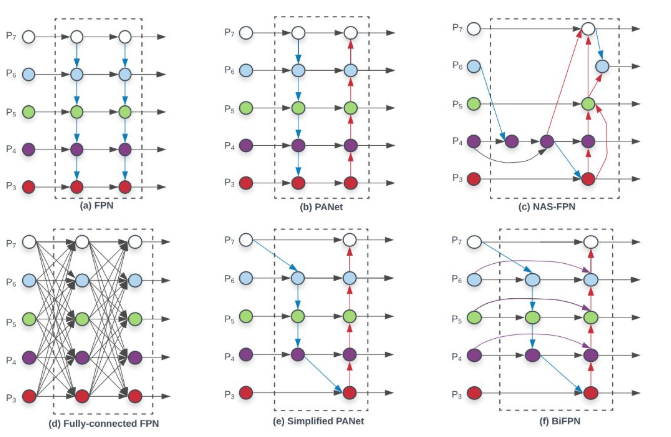
思想都差不多,多尺度融合不仅仅是从下到上,也要从上到下,并且融合的参数都是学习出来的,不是简单的add或者concat就Ok的。
本文在PANet的基础上提出三步优化:1)去掉没有进行融合的单一特征图参数学习;2)同一层中增加从原始节点到输出节点的短接;3)堆叠FPN结构。
激活函数
看这里
NMS
看这里
YOLO v4最终在上面的组合中选择了最优的组合。
西工大陈飞宇还在成长,如有错误还请批评指教。

