(2)YOLOv1源码
YOLOv1的网络结构还是比较简单的,因为他的关键部分在于他的逻辑,就是他的输入输出的映射和损失函数设计,先看一下yolov1的整体结构:
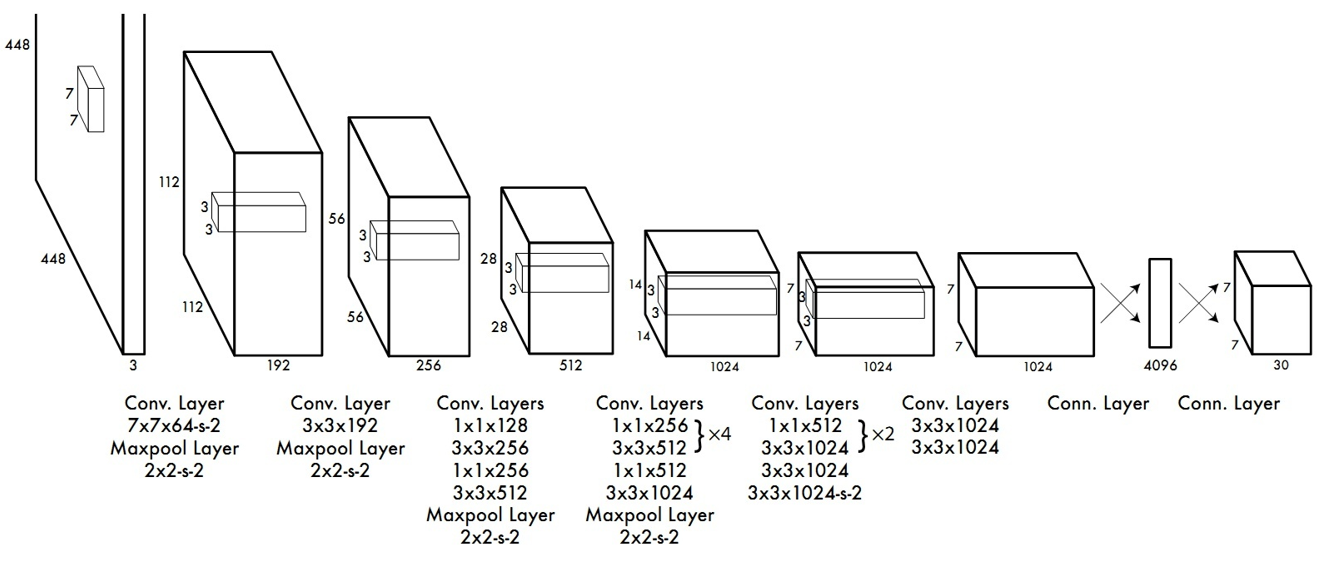
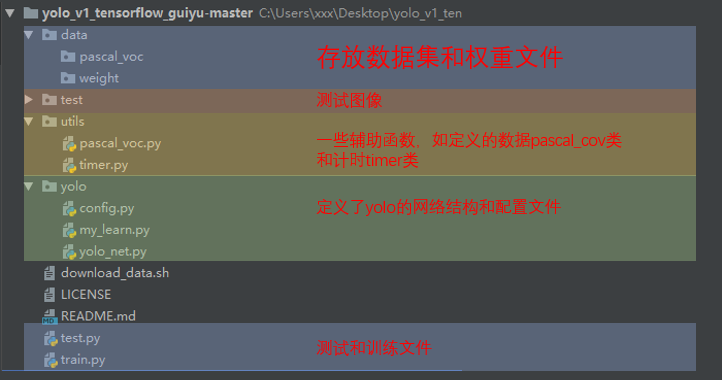
就是简单的卷积网络的结构。源码来自https://github.com/TowardsNorth/yolo_v1_tensorflow_guiyu,首先看一下文件结构:
那么看一下训练文件train.py里面定义了训练的main函数:
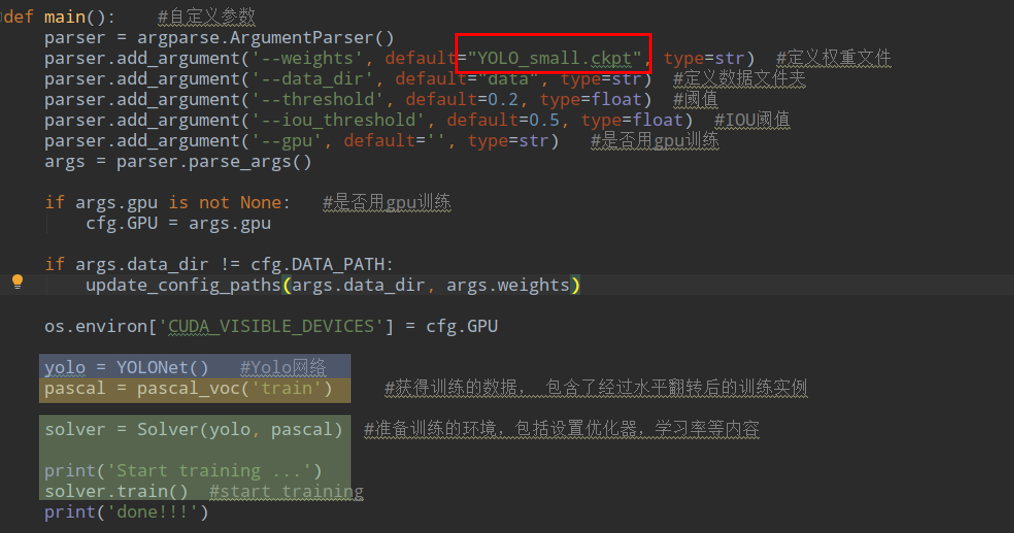
可以看到里面有个默认的权重Yolo_small.ckpt,这个并不是哪里来的,其实也是自己训练的,就是先使用这个网络在imagenet训练一个分类模型作为预训练模型,然后在用目标检测的数据微调。
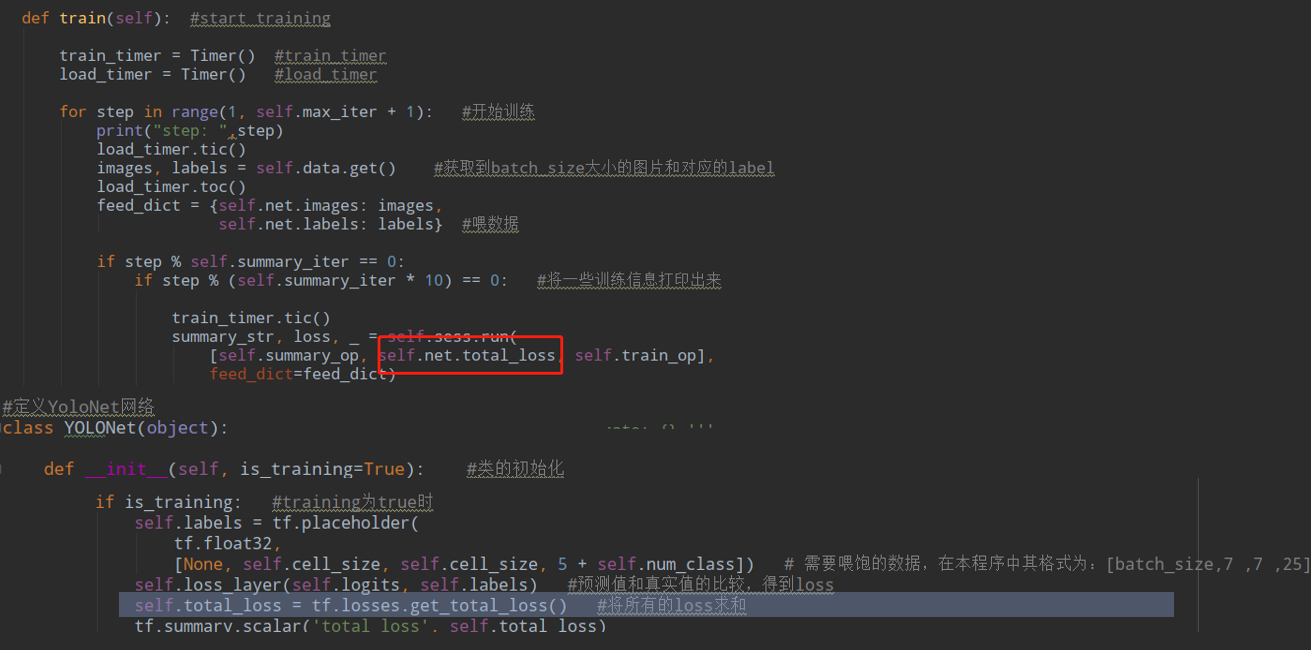
直接看Sovlver类里的train方法: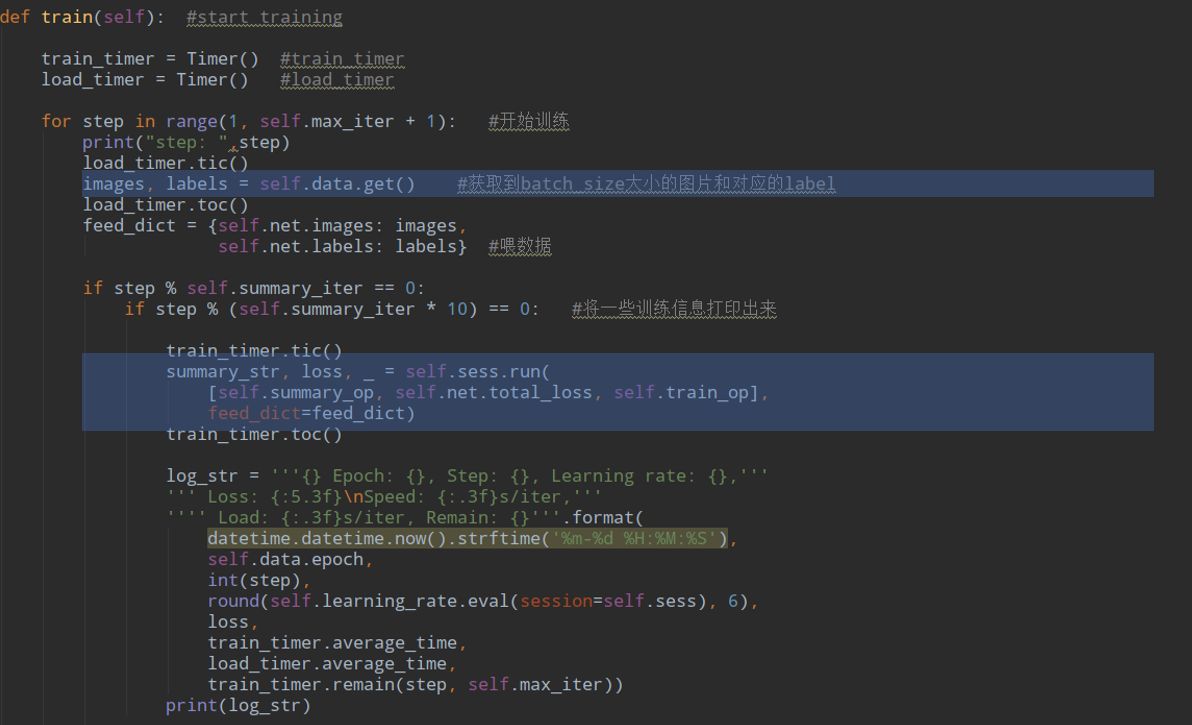
很简单,就是一个获得数据,然后训练计算loss的过程,data是一个pascal_voc类,看一下他的get方法:
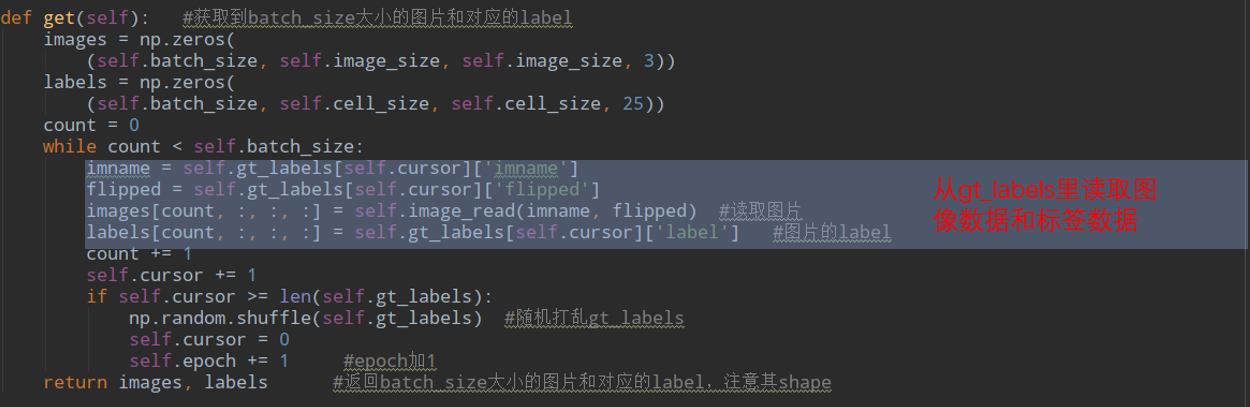
看来这个gt_labels很重要,他是在初始化的时候通过prepare赋值的:
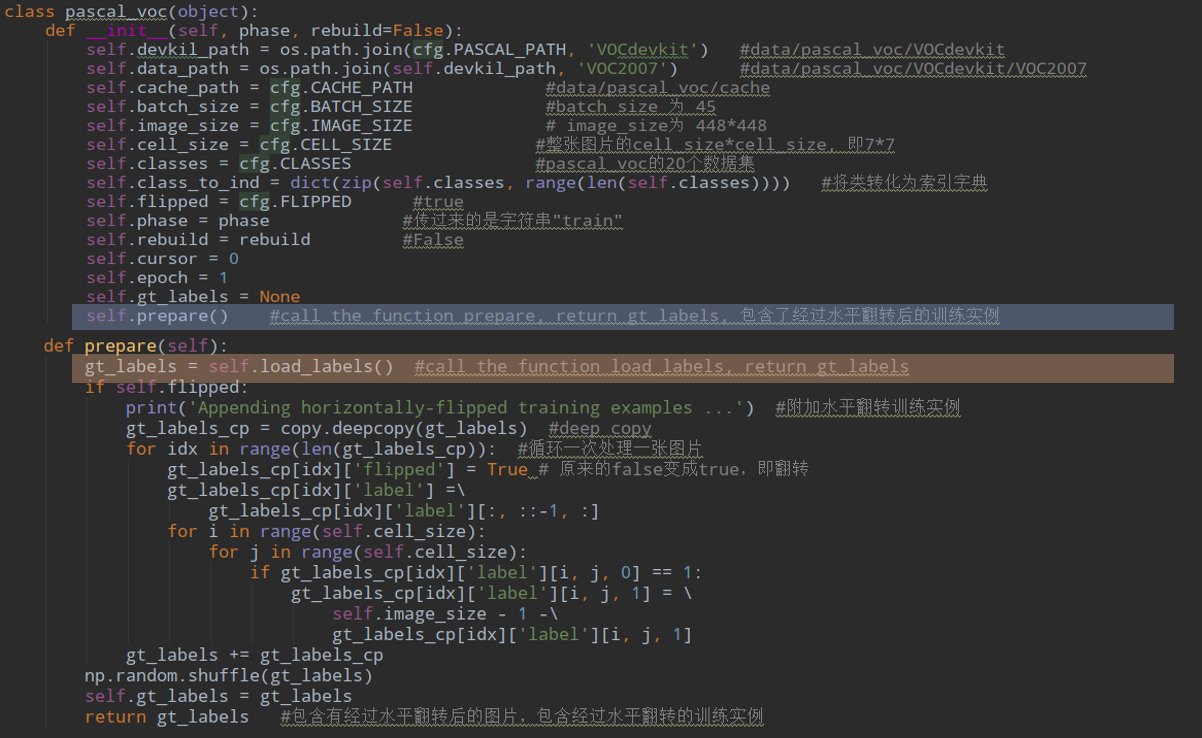
真的是一环套一环,还是要看load_labels:
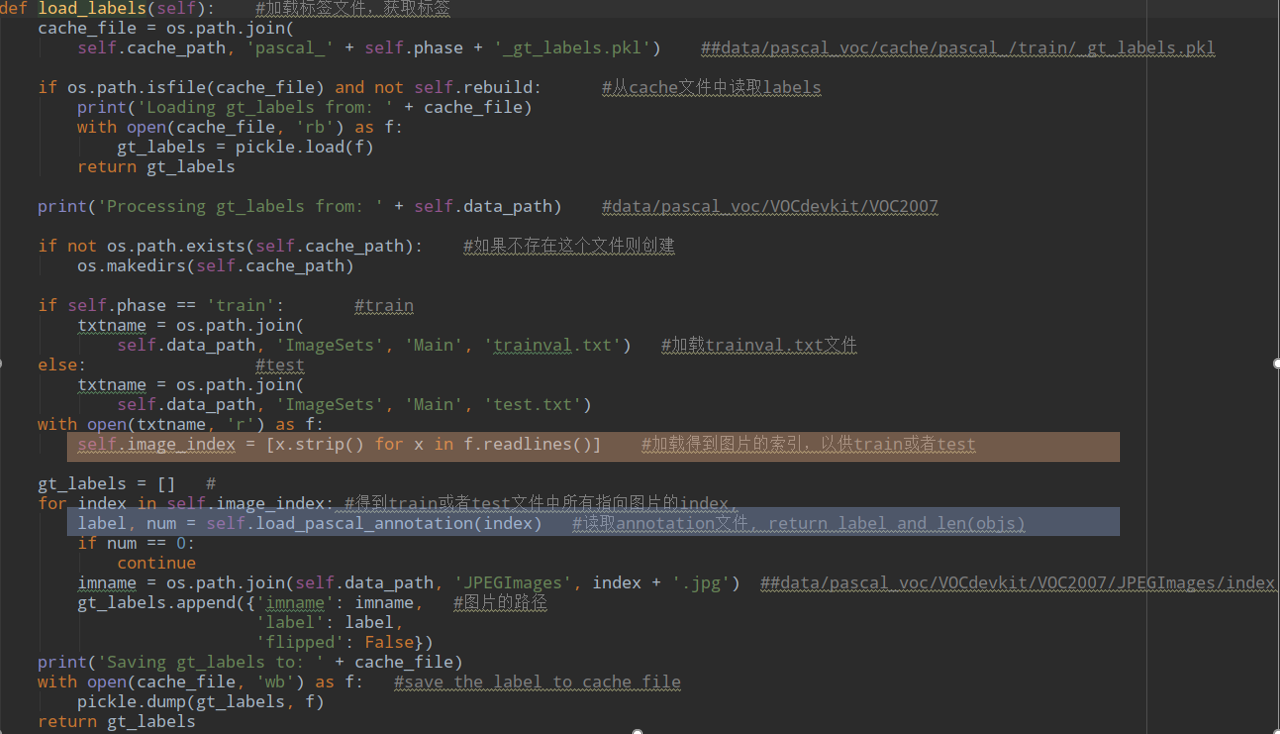
好吧继续看load_opascal_annotation:

返回的label是这样的cell_size*cell_size*25的张量: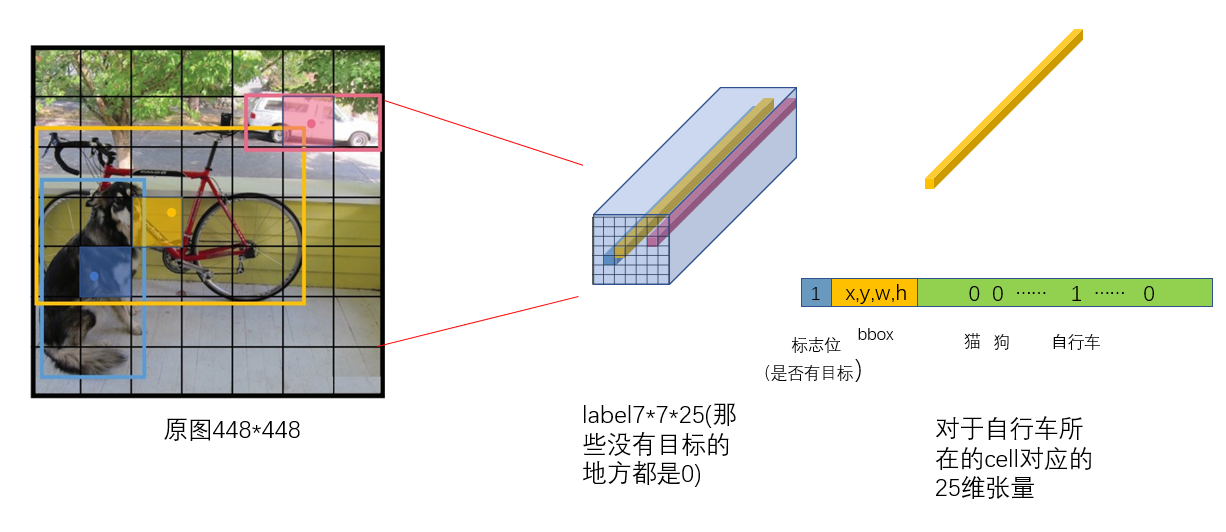
这个label的shape是7*7*25,与输出的维度7*7*30不对应,这个会在计算loss的时候处理。训练数据获取完毕,看一下计算loss部分,这个net是个YOLO类,他里面定义了total_loss:
所以只要看tf.losses里面都add了哪些loss就好: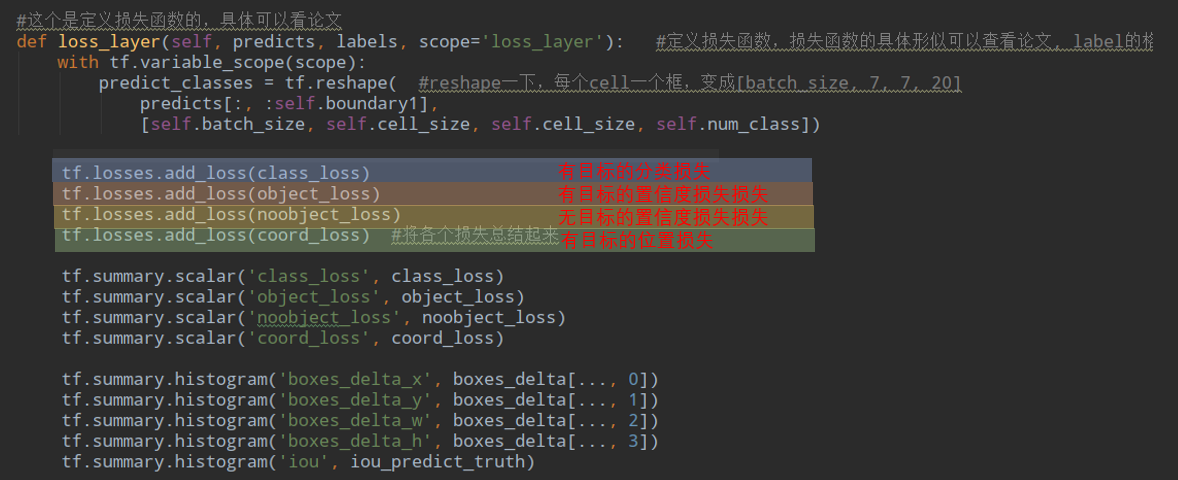
我们也分这几部分看,先看处理网络输出和label的部分:
因为网络输出的是全连接层的输出,所以要对predict进行reshape成我们需要的7*7*30的形式, 他没有把他们组合在一起,因为待会计算loss是分开计算的,所以是从predict中提取了各部分的信息,加起来20+2+2*4=30:

然后是从label提取信息:

同样得到了置信度response、boxes、和类别classes,注意他对boxes进行了归一化,除以了图像的尺寸。而且为了和predict每个cell预测的两个predict_box对应,把label里的box都进行复制操作。
接下来对预测的predict_boxes进行处理:

这表示输出的predict_boxes里面的(center_x,center_y,w,h)里面的center_x,center_y是相对于那个cell进行归一化的,现在要把他和label里的boxes对应起来,相对于全图进行归一化。一张图表明:
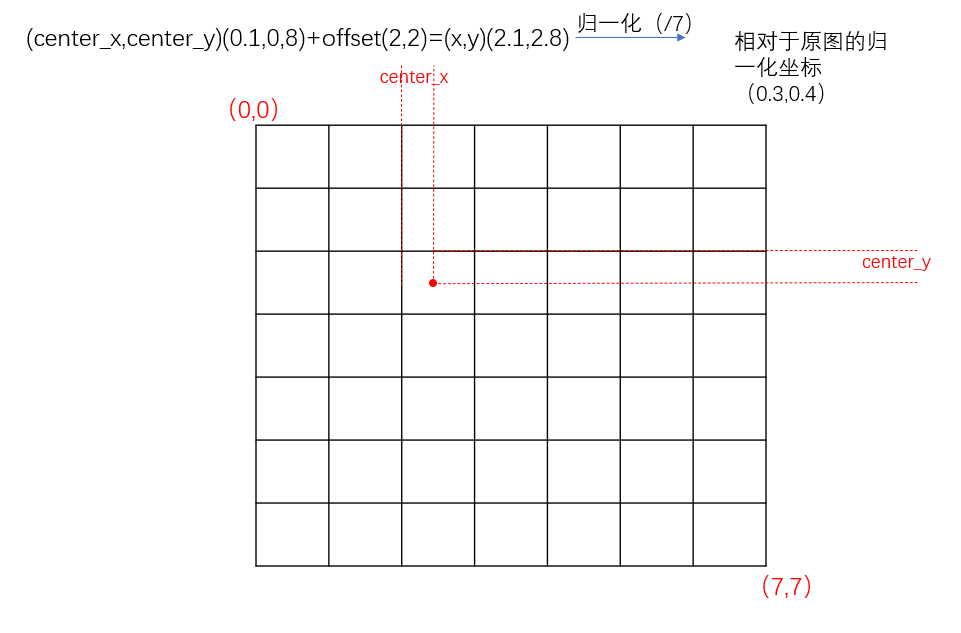
先计算每个cell对应的2个box和label里的iou,然后选取有目标的cell里的iou最大的作为目标object_mask存储这些信息,而其他的作为没有目标的noobject_mask:

最后还要处理label中目标框的center_x,center_y,宽度w和高度h,这也定义了输出的含义,他输出的是w和h的平方根,要和计算loss公式里的保持一致,loss里进行了开方操作:

这就是最后得到的用于计算位置损失的boxes_tran.
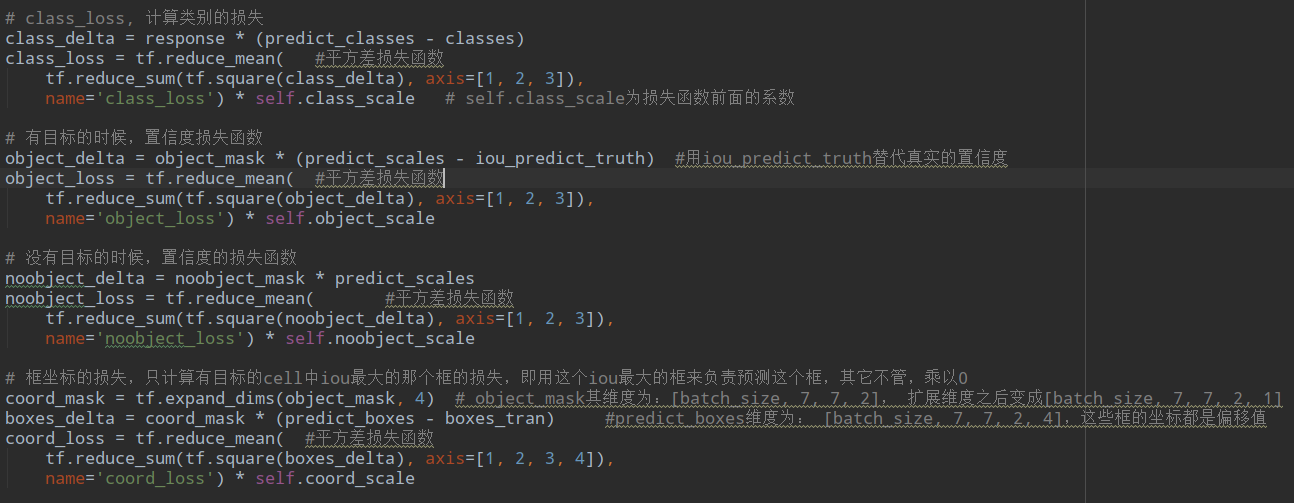
这里有个tips,就是计算置信度的时候使用了公式:
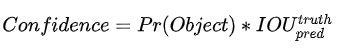
对于label计算这个公式,Pr(Object)=1,最终使用的是iou_predict_truth来作为置信度目标,这样有更深层的含义,就是希望学习到的是如何计算当前预测的box与ground_truth的iou来作为置信度,这个真的好厉害啊,但是也好复杂,他想要学习到这个信息,是不是最起码得对目标位置有个准确的认识,然后还要学习到iou计算公式,最终才会计算到这个iou。
最终loss就都计算完了。
定义的模型训练的train_op在Solver里的初始化部分:

在测试部分就不用了计算loss,而是要对输出进行筛选的操作,在test文件里的interpret_output函数:
首先把预测的boxes计算成为相对于原图的尺寸,就是上面那个图里面的计算,最后在*image_size就好:
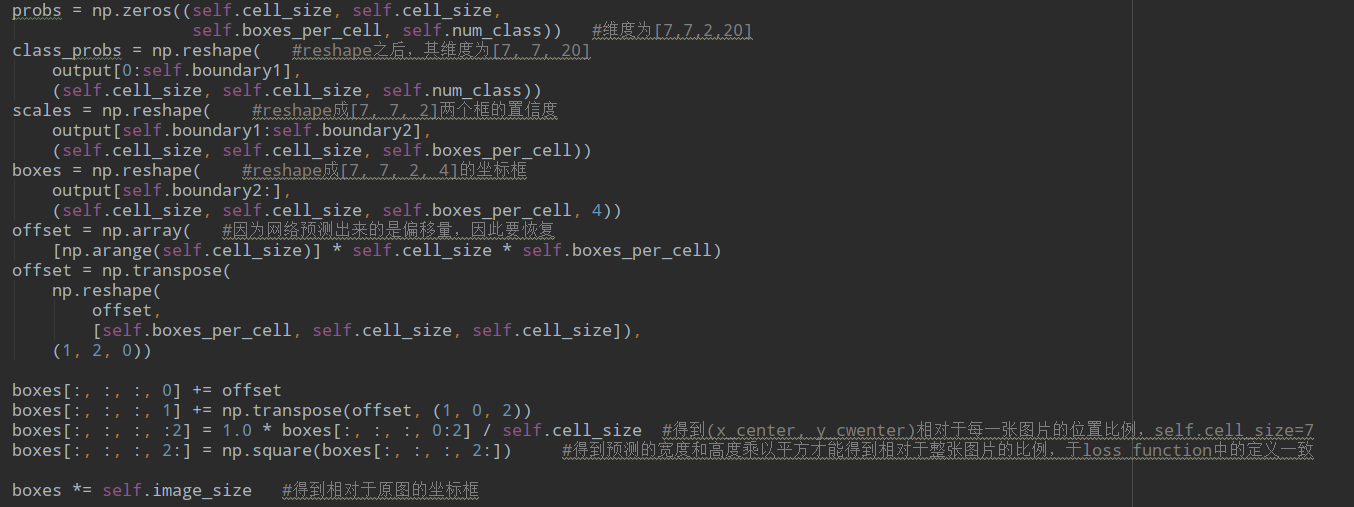
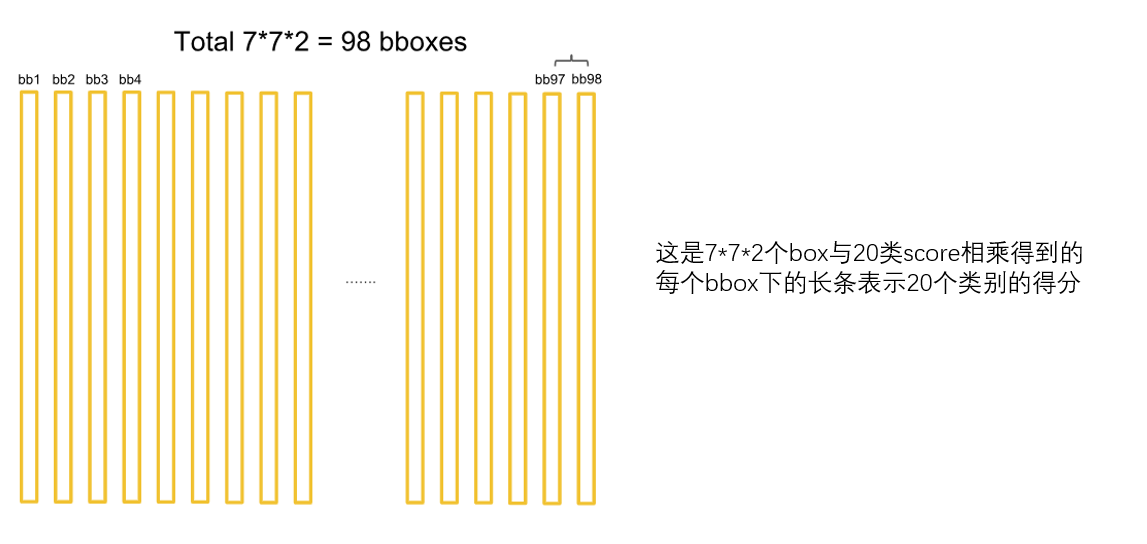
总共得到7*7*2个bbox。然后计算相对于类别的score:
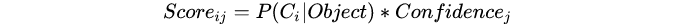
这样会得到7*7*2*20个分数对应着7*7*2个框在20个类别上的表现:

首先对所有的7*7*2*20个score进行筛选,选出满足要求的score对应的box得到boxes_filtered ,注意这里可能一个box有好多个类别的score都满足,但是一个box应该对应一个类别,这个类别就记录在class_num_filtered,。最后排序得到score从大到小的排序box表示为boxes_filtered,并且选取对应的置信度pros_filtered,这里一个cell可能两个box都留下来(我也不知道为什么不一个cell留一个,不是说好一个cell预测一个类别吗):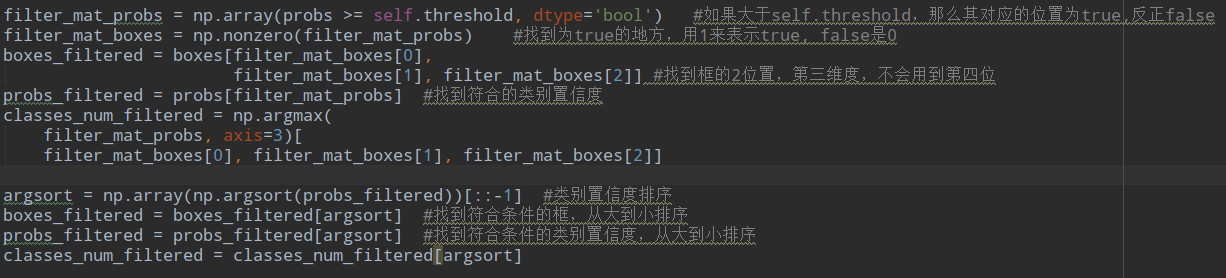
进行nms并保存结果:
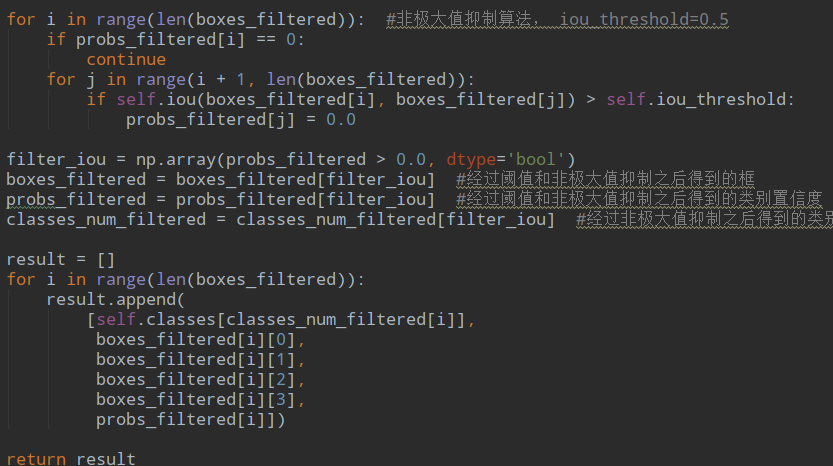
看看论文中最后筛选的方法:
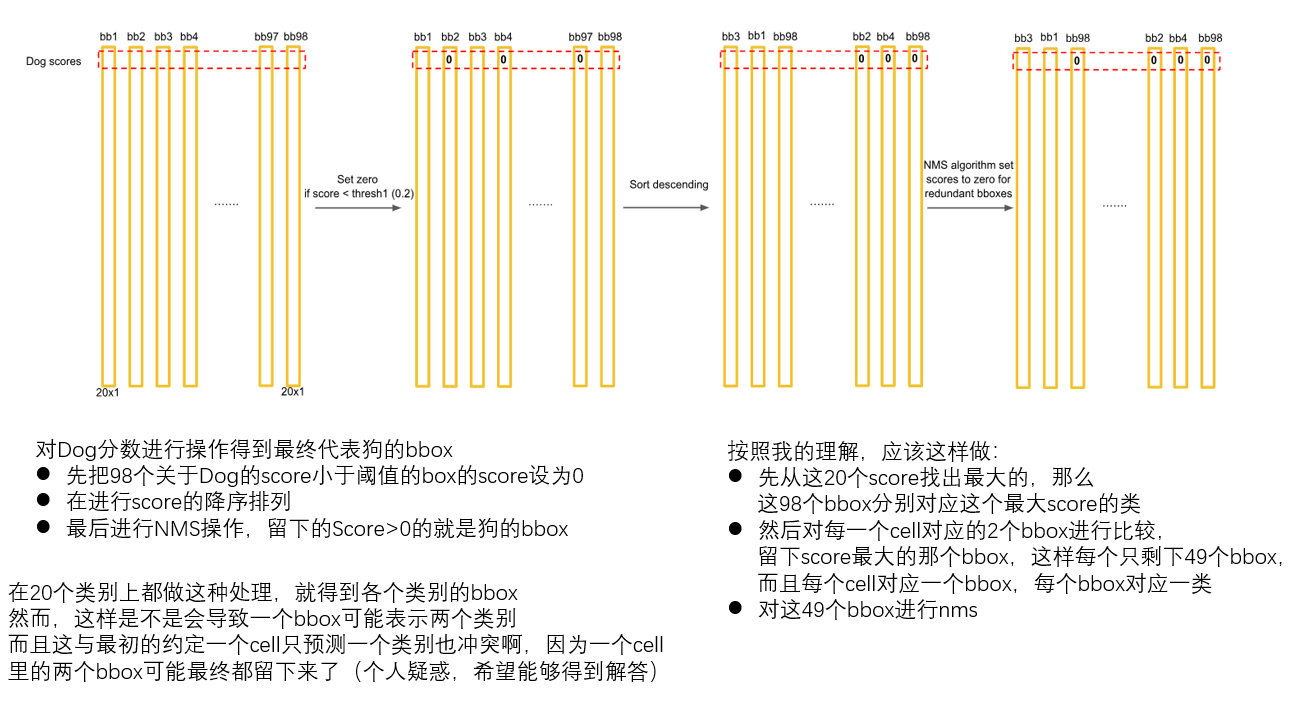
看了好多版本代码,都没有按照论文中把各个类别分开对待,而且无论是论文还是代码,也都没有对一个cell对应的两个bbox进行筛选,不知道为什么,代码中只是保证一个bbox对应一个类,可是并没有保证一个cell一类,后面在看看吧。
最后看看YOLONET的定义吧:
来看看他的结构吧:
1 def build_network(self, #用slim构建网络,简单高效
2 images,
3 num_outputs,
4 alpha,
5 keep_prob=0.5,
6 is_training=True,
7 scope='yolo'):
8 with tf.variable_scope(scope):
9 with slim.arg_scope(
10 [slim.conv2d, slim.fully_connected], #卷积层加上全连接层
11 activation_fn=leaky_relu(alpha), #用的是leaky_relu激活函数
12 weights_regularizer=slim.l2_regularizer(0.0005), #L2正则化,防止过拟合
13 weights_initializer=tf.truncated_normal_initializer(0.0, 0.01) #权重初始化
14 ):
15 net = tf.pad(
16 images, np.array([[0, 0], [3, 3], [3, 3], [0, 0]]),
17 name='pad_1')
18 net = slim.conv2d(
19 net, 64, 7, 2, padding='VALID', scope='conv_2') #这里的64是指卷积核个数,7是指卷积核的高度和宽度,2是指步长,valid表示没有填充
20 net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_3') #max_pool, 大小2*2, stride:2
21 net = slim.conv2d(net, 192, 3, scope='conv_4') #这里的192是指卷积核的个数,3是指卷积核的高度和宽度,默认的步长为1
22 net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_5') #max_pool,大小为2*2,strides:2
23 net = slim.conv2d(net, 128, 1, scope='conv_6') #128个卷积核,大小为1*1,默认步长为1
24 net = slim.conv2d(net, 256, 3, scope='conv_7') #256个卷积核,大小为3*3,默认步长为1
25 net = slim.conv2d(net, 256, 1, scope='conv_8') #256个卷积核,大小为1*1,默认步长为1
26 net = slim.conv2d(net, 512, 3, scope='conv_9') #512个卷积核,大小为3*3,默认步长为3
27 net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_10') #max_pool, 大小为2*2,stride:2
28 net = slim.conv2d(net, 256, 1, scope='conv_11') #256个卷积核,大小为1*1, 默认步长为1
29 net = slim.conv2d(net, 512, 3, scope='conv_12') #512个卷积核,大小为3*3,默认步长为1
30 net = slim.conv2d(net, 256, 1, scope='conv_13') #256个卷积核,大小为1*1, 默认步长为1
31 net = slim.conv2d(net, 512, 3, scope='conv_14') #512个卷积核,大小为3*3, 默认步长为1
32 net = slim.conv2d(net, 256, 1, scope='conv_15') #256个卷积核,大小为1*1, 默认步长为1
33 net = slim.conv2d(net, 512, 3, scope='conv_16') #512个卷积核,大小为3*3, 默认步长为1
34 net = slim.conv2d(net, 256, 1, scope='conv_17') #256个卷积核,大小为1*1, 默认步长为1
35 net = slim.conv2d(net, 512, 3, scope='conv_18') #512个卷积核,大小为3*3, 默认步长为1
36 net = slim.conv2d(net, 512, 1, scope='conv_19') #256个卷积核,大小为1*1, 默认步长为1
37 net = slim.conv2d(net, 1024, 3, scope='conv_20') #1024个卷积核,大小为3*3,默认步长为1
38 net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_21') # max_pool, 大小为2*2,strides: 2
39 net = slim.conv2d(net, 512, 1, scope='conv_22') #512卷积核,大小为1*1,默认步长为1
40 net = slim.conv2d(net, 1024, 3, scope='conv_23') #1024卷积核,大小为3*3,默认步长1
41 net = slim.conv2d(net, 512, 1, scope='conv_24') #512卷积核,大小为1*1,默认步长1
42 net = slim.conv2d(net, 1024, 3, scope='conv_25') #1024卷积核,大小为3*3, 默认步长为1
43 net = slim.conv2d(net, 1024, 3, scope='conv_26') #1024卷积核,大小为3*3,默认步长为1
44 net = tf.pad(
45 net, np.array([[0, 0], [1, 1], [1, 1], [0, 0]]),
46 name='pad_27') #padding, 第一个维度batch和第四个维度channels不用管,只padding卷积核的高度和宽度
47 net = slim.conv2d(
48 net, 1024, 3, 2, padding='VALID', scope='conv_28') #1024卷积核,大小3*3,步长为2
49 net = slim.conv2d(net, 1024, 3, scope='conv_29') #1024卷积核,大小为3*3,默认步长为1
50 net = slim.conv2d(net, 1024, 3, scope='conv_30') #1024卷积核,大小为3*3,默认步长为1
51 net = tf.transpose(net, [0, 3, 1, 2], name='trans_31') #转置,由[batch, image_height,image_width,channels]变成[bacth, channels, image_height,image_width]
52 net = slim.flatten(net, scope='flat_32') #将输入扁平化,但保留batch_size, 假设第一位是batch,实际上第一维也是batch
53 net = slim.fully_connected(net, 512, scope='fc_33') #全连接层,神经元个数
54 net = slim.fully_connected(net, 4096, scope='fc_34') #全连接层,神经元个数
55 net = slim.dropout( #dropout,防止过拟合
56 net, keep_prob=keep_prob, is_training=is_training,
57 scope='dropout_35')
58 net = slim.fully_connected( #全连接层
59 net, num_outputs, activation_fn=None, scope='fc_36')
60 return net
很平淡,就和我们上面展示的网络结构一样,其实主要部分是最开始介绍的的计算loss和制作label部分。
西工大陈飞宇还在成长,如有错误还请批评指教。


