(2)RCNN成长之路
上次我们说到要进行目标检测需要:1.获得相应的感受域,或者我们该用图像处理中的ROI(Region Of Interest,感兴趣的区域)表述;2.将这个ROI对应的特征进行分类,判断目标类别。这就是RCNN(Regions with CNN features)要做的。
RCNN
直接上图:
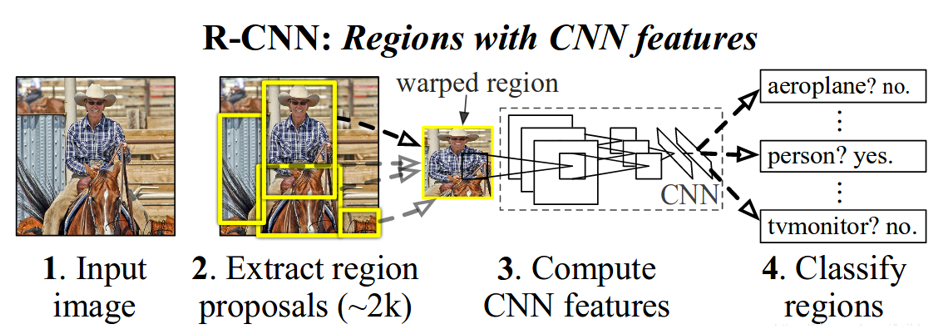
一直以来CNN都是对于全图的,但目标检测需要将全图的一部分区域输入CNN,那么很重要问题就有:1.如何选择区域或者说如何提取ROI;2.如何提取特征进行分类
RCNN是怎么做的呢?针对候选区域选择,提出了诸多办法大都是一般的图像处理手段:selective search、objectness、constrained parametric min-cuts(CPMC)等,RCNN采用了selective search的方法,这种方法(em好复杂的)大概就是先把一张图采用图像分割的方法分割好,然后计算相似的区域进行合并,最后输出这个过程产生的所有区域,这样就会得到所有的候选区域;
针对分类,首先使用CNN提取特征,然后使用针对各个类别的SVM进行2分类(ps.为什么进行不直接用CNN分类是因为在确定正负样本的原则上,用CNN训练的目的是为了提取特征,所以对正样本要求较低如果要求太高很容易过拟合,因为你要提取的是20类的特征,而SVM往往就用于进行数据量较少的分类,可以针对每一类进行精确分类,适当提高正样本的条件,这里所说的正样本是以IOU作为阈值选择的,比如在CNN训练阶段把IOU>0.5当做正样本,而在训练svm阶段把IOU>0.7当做正样本)
按照上图RCNN做了四项工作:
1.输入整张图像;
2.提取候选区域,每张图大概~2k;
3.将候选区域的图像数据进行wrap操作,这个操作后讲不通的区域数据都resize成CNN输入数据维度,进行特征提取;
4.将各个候选框提取的特征送入训练好的20个SVM进行分类
RCNN的训练包括两部分,一部分是训练提取特征的CNN网络,另一部分是训练各个SVM。利用CNN对候选框进行分21类(20类+1背景类)完成训练,最后把softmax层去掉,将前面的FC层作为特征向量输出。SVM就是不同的正负样本二分类训练,针对每个类别训练20个。两者的训练数据均由标注产生的候选区proposal产生,比如针对原图产生了一个候选区proposal,这个候选区如果与真实目标框ground truth进行重合面积计算:

在利用CNN分20类时可以使proposal与ground truth的IOU>0.5就标记为对应的1~20类别,其他为背景类0;而在训练某一类SVM时把IOU>0.7标记为1,其他标记为0。
RCNN算是目标检测思想的简单实现,他主要存在的问题是:
1.使用selective search选出的候选区域太多,每张都有~2k,也就是说每张图就要进行~2k次特征提取,计算量庞大;
2.候选框往往存在着重叠部分,意思是说一张图上的一块区域的特征被不同候选框重复计算,浪费资源;
3.进行的wrap和resize操作回事图像发生形变,可能会影响特征判断
针对这些问题有了Faste RCNN
Fast RCNN
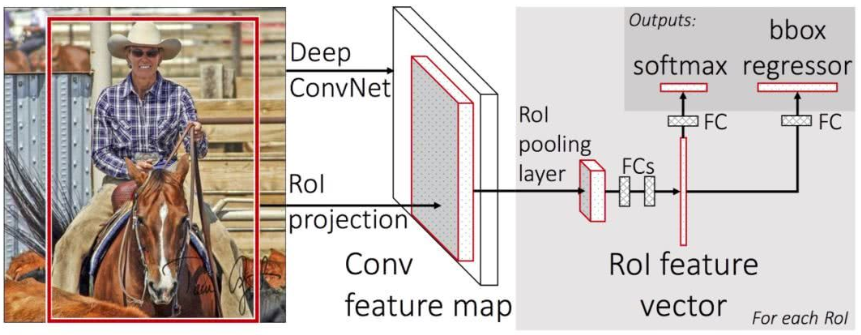
针对问题2,Faster RCNN将整张图进行特征提取,我们假设能够在卷积层最后一层学习到原图对应的特征,也就是说原图与最终的特征图存在位置映射关系,那么我们就可以将原图selective search产生的候选框region proposal映射到特征图中也就是上图的ROI projection。这样一张图我们只计算一次;
针对问题3:,Faster RCNN采用了SPP(空间金字塔池化Spatial Pyramid Pooling)结构,通过这个结构就可以不限制CNN输入的图像尺寸大小。其实对于具有卷积层和全连接层的CNN而言。卷积操作并不限制输入的shape,而是全连接层要求的,比如全连接层有4096个神经元,那么输入必须是4096维的,所以真正要做的是在上面卷积层提取网特征图后,加一个ROI poling layer,这样无论输入多大的proposal对应的特征图,都会有固定的输出,就可以连接到后面的全连接层了,SPP如何做到呢,一张图解释: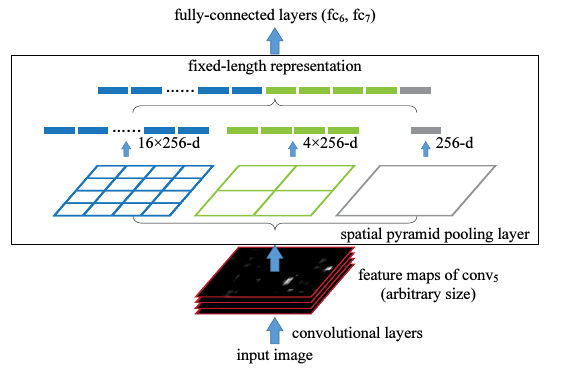
从左往右代表的就是空间金子它的自上而下,这个空间金字塔有三层,第一层把一个图分成4*4总共16个单元,每个单元比如采用max poling这种输出一个数,那么这样不管输入是多大的size,最终得到都是16维,同理往高层分成2*2共4个单元,输出4维,最后是图像本身输出1维,这样对于一张特征图就是16+4+1这样没无论输入有多大。ROI Poling就是SPP的精简版本,对于每个proposal输入的feature map,都下采样到7*7的维度,只进行这一步,不用2*2和1*1,这样对于随便一个特征图输入w*h*512,最后都会成为7*7*512。
同时Faster RCNN还去掉了svm,重新使用softmax(这个真的好迷,上面刚介绍完为什么不用softmax而是用svm,这里就换了),同时使用神经网络左回归,即调整proposal的位置(这个可以理解,因为分类和定位这两个任务应该是相互促进的,想要分好类就要定好位),这样完全变成端到端的训练,不用像RCNN那样CNN和SVM分开训练。最后我们发现Faster RCNN并没有解决问题1,使用了selective search产生了那么多框,有没有更快的方法,Faster RCNN就解决了这个问题。
Faster RCNN
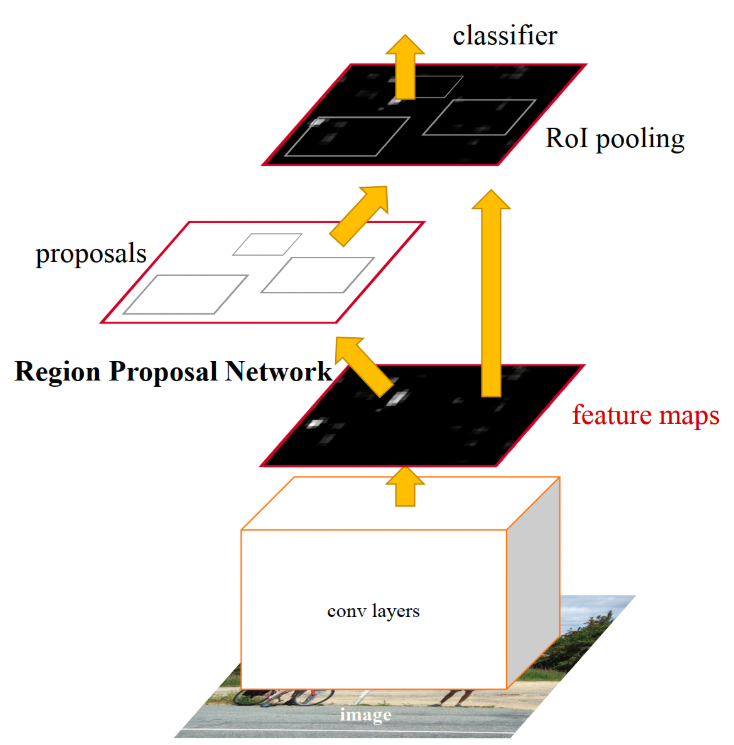
Faster RCNN针对问题1比着Fast RCNN只是多了一个RPN(候选区域生成网络,region proposal network),通过他来生成很多个proposal,而不是像之前那样采用selective search的方法,具体怎么做我们后面会学习。
Faster RCNN同样先提取一个图像的特征图,将这个特征图送入RPN网络生成proposal(上面讲过,我们假定特征图和原图存在位置映射关系,所以这里生成的proposal既可以表示在特征图上,也可以映射回原图上),再将proposal对应的特征图进行ROI poling和分类回归操作,整体和之前一样,只是多了RPN。网络的训练又要分为两部分(em..这个原因很简单,RPN算是一个新的网络结构,必须得训练),一部分是RPN的训练,输入是初始化的一些anchor(下次在解释,反正就是一个初始化区域)label(0,1),输出是这些anchor调整后形成的proposal以及proposal对应的标签(0,1分别表示背景和前景,我们当然是想要获得前景的),训练数据怎么来?以后再说吧。另一个训练就是分类和回归的训练,输入是proposal对应的特征图,输出是这个proposal对应的类别,以及微调后的真正输出的目标位置,这个训练数据怎么来,下次再说吧。
西工大陈飞宇还在成长,如有错误还请批评指教。

