流行病学中的偏差包括两种 : 随机误差 和 系统误差。
随机误差影响研究的精确性(precision),但是难以避免。可以通过研究设计和统计学方法给予减少或评价。
着重介绍系统误差,即偏倚(bias)。偏倚造成的误差不能通过增加样本量和重复试验来减少
偏倚的类型有三种: 选择偏倚、信息偏倚、混杂偏倚
选择偏倚(主要发生在实验设计阶段)的种类:
1,入院率偏倚(admission rate bias): 当以医院病人作为研究对象时,由于不同患者入院率不同导致的偏倚,即使他们的暴露率相同。
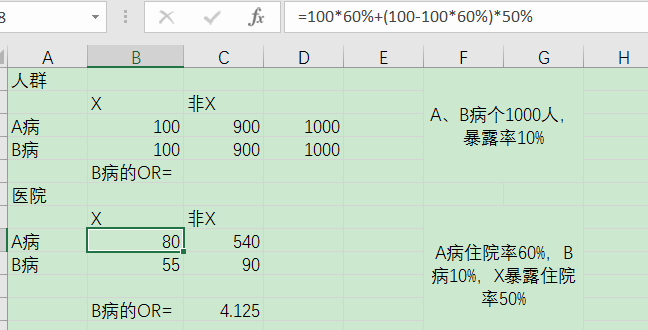
2,现患病例-新发病例偏倚(prevalence-incidence bias)又奈曼偏倚(Neyman bias)
以现患病例或新发病例为研究对象时,因这;两类对象的特征差异所导致的系统误差。
比如队列研究中,研究慢性血清胆固醇与冠心病的关系,第一次分析使用第一次测量的基线资料,第二次分析使用的是第六次测量的基线资料
第一次冠心病的OR值要大于第二次的OR值,是因为冠心病人诊断以后,生活习惯大多发生改变,所以胆固醇降低,导致低估了暴露与疾病的联系
再比如,常年的高血压患者,他的血压值并不太高,因为一直在吃药。
3,检出症候偏倚(detection signal bias)
因素A在病因学上与某病B无关,但是由于A的存在导致了所研究疾病相关一些症状的出现,使其及早就医,那么该人群(暴露A因素的)的检出率就高。主要针对慢病如癌症、动脉硬化、结石
比如:子宫内膜癌与雌激素暴露。雌激素的暴露易导致子宫出血,频繁就医,子宫内膜癌检出率增加;而未服用雌激素的病例,就医次数少,无形中导致了病例组里暴露的比例大大增加,得到虚假联系。
4,无应答偏倚(non-response bias)
失访就是无应答的一种表现形式。
5,易感性偏倚(susceptibility bias)
研究对象是否暴露于某危险因素,与许多主观、客观因素有关,这会直接或间接的影响研究对象对研究疾病的易感性。
比如健康人群效应。研究暴露于某危险因素的作业工人,研究结果发现,该人群中某研究疾病的发病率或死亡率并不比一般人群高。
这有可能是因为这类工人由于工作性质的需要,其健康水平本身就比一般人群高,对暴露因素的耐受性强,对研究疾病的易感性低
选择偏倚的控制:
1,掌握发生环节
在研究对象的选择和资料收集的过程中,考虑易感性偏倚和检出症候偏倚,无应答比例?,失访原因的提前考虑etc。
2,严格选择标准
严格明确的纳排标准,例如病例对照研究,病例的入选原则为新发,确诊的病例(防止奈曼偏倚);
对照入选原则:①不患研究疾病且有暴露研究因素的可能②不患与研究因素有关的其他疾病③与病例组的可比性
3,研究对象的合作
提高研究对象的合作,降低无应答率和实验性研究的不依从、或队列研究中的失访等。
4,采用多种对照
如不同病种对照,最好有来自一般人群的对照
5,随机化
信息偏倚(主要发生在实施阶段)的种类:
信息偏倚的表现是使研究对象的某种或某些特征被错误的分类。可分为无差异错误分类和有差异错误分类。
1,回忆偏倚(recall bias)
顾名词义
2,报告偏倚(reporting bias)
研究对象有意夸大或缩小某些信息而导致的系统误差。
比如:研究对象为了继续工作而有意的掩盖某些患病信息。
3,暴露怀疑偏移(exposure suspicion bias)
研究者若事前对研究对象的患病情况或结局有了解,可能会采取与对照组不可比的方法。
比如:多次认真的询问病例组某因素的暴露史,而不认真询问对照组,导致错误结论。
4,诊断怀疑偏移(diagnostic suspicion bias)
研究者若事前对研究对象的暴露情况有了解,在主观上倾向于应该或不应该出现某种结局。
5,测量偏倚(detection bias)
研究者对研究所需要数据进行测量时所产生的系统误差。
比如仪器的校正、测量人员的技术水平等。
信息偏倚的测量
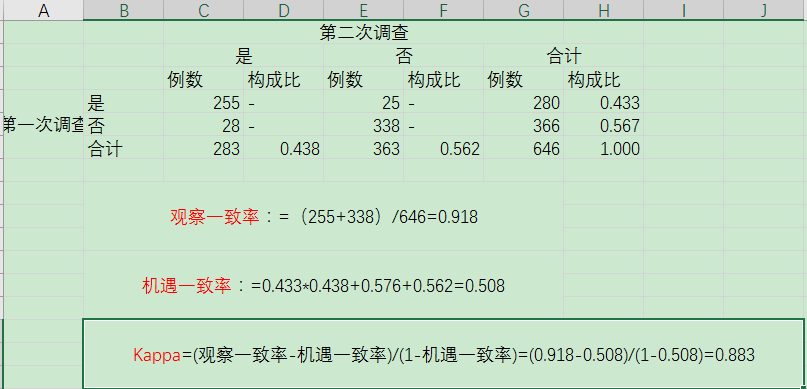
Kappa值:
信息偏倚的控制
1,严格信息标准
2,盲法收集信息>>诊断怀疑偏移和暴露怀疑偏移
3,采用客观指标
4,调查技术应用--随机应答技术
5,统计学处理
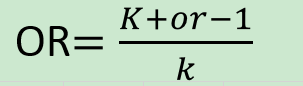 其中or是实测值,k是kappa系数
其中or是实测值,k是kappa系数
混杂偏倚:
三基本条件:①是所研究疾病的危险因素 ②与所研究因素有关 ③不是研究因素与研究疾病因果链上的中间变量。
当具备这三点以后,且在比较的人群组中分布不均,即可导致混杂产生。
比如吸烟和肺癌的关系,年龄即具备上述三条件,如果在病例组与对照组中分布不均,则导致错误估计。
混杂偏移的控制:
1,限制(restriction)
比如口服避孕药与心肌梗死的关系,考虑年龄是混杂,只选择某一年龄组。
2,随机化(randomization)
简单随机、分层随机
分层随机适用于 对主要混杂因素有充分了解,根据混杂因素事先将研究对象分层,然后再讲每层的研究对象随机分配
3,匹配(matching)
4,统计学处理
标准化法、分层分析、对因素分析、倾向性评分(propensity score matching)、工具变量等
交互作用和效应修饰
交互作用指的是两个或两个以上因子共同作用于某一件事情,其效应明显不等于该两个因子单独作用时的和或者积,称这些因子间存在交互作用,有时也称效应修饰
效应修饰指在基础人群中一种暴露因素的效应在另一种暴露因素不同水平上不同,存在不一致性或者异质性。因此,无修饰效应是指效应的一致性或同质性。
交互作用的类型
协同作用:两个或两个以上因子共同作用于某一件事情,其效应明显不等于该两个因子单独作用时的和或者积。
拮抗作用:相加模型、相乘模型
在报告有无交互时,一定要说明分析时用的哪种模型
当两种模型的结果相矛盾时,一般应选择相加模型
交互与混杂的区别


 浙公网安备 33010602011771号
浙公网安备 33010602011771号