序列化类常用字段类和字段参数 序列化类高级用法之source 定制序列化字段的两种方式 关系表外键字段的反序列化保存 序列化类继承ModelSerializer
昨日内容回顾
# 1 APIView--->drf 提供的,继承了原来的View,以后如果写视图类,都继承APIView及其子类
# 2 APIView执行流程
-1 去除csrf认证
-2 包装了新的Request对象--->视图类中使用的request都是drf的Request
-原来的在哪?
-用起来跟之前一样--->__getattr__--->学过的魔法方法
-request.data--->put,post..请求体携带的数据,无论什么编码,都是字典
-request.query_params--->老的request.GET
-request.FILES--->跟之前一样,重写了文件类
-3 执行了三大认证(认证,权限,频率)
-4 三大认证的代码,视图类方法的代码,如果出了异常,会有异常捕获--->后期会做统一处理
# 3 Request源码分析
# 4 序列化类--->APIView+序列化类+Respone--->5个接口
-序列化类的作用:做序列化,反序列化,反序列化校验
-序列化过程:
-写一个序列化类,继承Serializer,写一个个字段CharField,写的字段表示要序列化和反序列化的字段
-视图类中:导入,实例化得到对象,对查出来的queryset,单个对象序列化,传入instance参数,如果是queryset,一定要传many=True
-序列化对象 ser.data--->字典或列表--->Resonse--->json格式字符串给前端
-序列化单条和序列化多条,路由不一样,写成两个视图类,分别两个get方法
-反序列化过程:新增,修改
-新增:
-前端传入的无论什么编码格式,都在request.data中,是字典
-request.data:
-urlencoded,form-data--->QueryDict
-json--->dict
-拿到前端传入的数据,进行反序列化--->序列化类的反序列化,完成
-序列化类得到对象,传入参数, data=request.data
-校验数据
-保存:ser.save() --->序列化类中重写create方法
-修改:
-拿到前端传入的数据,进行反序列化,查出要修改的对象--->序列化类的反序列化,完成
-序列化类得到对象,传入参数,instance=要修改的对象,data=request.data
-校验数据
-保存:ser.save() --->序列化类中重写update方法
# 反序列化的校验
-只要在序列化类中写局部和全局钩子
-局部钩子
def validate_字段名(self,name):
校验通过,返回name
如果不通过,抛出异常
-全局钩子
# attr,前端传入的数据,走完局部钩子校验后的数据
def validate(self,attrs):
校验通过,返回attrs
如果不通过,抛出异常
作业
#原生的request 没有data 属性 实现一个原生的 request.data 拿出无论什么编码格式提交的数
FBV--->写个装饰条
import json
# 通过装饰器做,装饰器视图函数的,以后都会有request
def wrapper(func):
def inner(request, *args, **kwargs):
# 造个新的requeset
# 如果是 urlencoded,form-data ----》request.POST 就有值
# 如果request.POST 就有值没有值,就是json格式编码
try:
print(request.body)
request.data = json.loads(request.body) # 表示是json格式编码
except Exception as e:
request.data = request.POST
res = func(request, *args, **kwargs)
return res
return inner
@wrapper # test=wrapper(func)------>以后执行test()本质是---》wrapper(func)(request)---》本质是inner(request)
def test(request):
print(request.POST) # urlencoded,form-data----->QueryDict
print(request.data) # 报错了
return HttpResponse('ok')
# 总结:前端提交数据的编码格式
-urlencoded:
name=lqz&age=19&price=999 放在了请求体中
-formdata: 分数据部分和文件部分
'----------------------------585520151165741599946333\r\n
Content-Disposition: form-data;
name="name"\r\n\r\nlqz\r\n
----------------------------585520151165741599946333--\r\n'
-json格式:{"name":"lqz","age":19}
-
序列化类常用字段和字段参数(了解)
-
系列化高级用法之source(了解)
-
序列化高级用法之定制字段的两种方式
-
多表关联反序列化保存
-
反序列化字段校验其他
-
ModelSerializer使用
1 序列化类常用字段和字段参数(了解)
# 序列化类---》字段类 CharField,除此之外还有哪些其他的
# 序列化类---》字段类,字段类上,传属性的,序列化类上,也可以写属性
【models.CharField(max_length=32)】
1.1 常用字段类
#1 BooleanField BooleanField()
#2 NullBooleanField NullBooleanField()
#3 CharField CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True)
#4 EmailField EmailField(max_length=None, min_length=None, allow_blank=False)
#5 RegexField RegexField(regex, max_length=None, min_length=None, allow_blank=False)
#6 SlugField SlugField(max_length=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9-]+
#7 URLField URLField(max_length=200, min_length=None, allow_blank=False)
#8 UUIDField UUIDField(format=’hex_verbose’) format: 1) 'hex_verbose' 如"5ce0e9a5-5ffa-654b-cee0-1238041fb31a" 2) 'hex' 如 "5ce0e9a55ffa654bcee01238041fb31a" 3)'int' - 如: "123456789012312313134124512351145145114" 4)'urn' 如: "urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a"
#9 IPAddressField IPAddressField(protocol=’both’, unpack_ipv4=False, **options)
#10 IntegerField IntegerField(max_value=None, min_value=None)
#11 FloatField FloatField(max_value=None, min_value=None)
#12 DecimalField DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置
#13 DateTimeField DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None)
#14 DateField DateField(format=api_settings.DATE_FORMAT, input_formats=None)
#15 TimeField TimeField(format=api_settings.TIME_FORMAT, input_formats=None)
#16 DurationField DurationField()
#17 ChoiceField ChoiceField(choices) choices与Django的用法相同
#18 MultipleChoiceField MultipleChoiceField(choices)
#19 FileField FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL)
#20 ImageField ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL)
----------重要,后面讲-----------
ListField ListField(child=, min_length=None, max_length=None)
DictField DictField(child=)
#记住的:CharField IntegerField DecimalField DateTimeField BooleanField
ListField
DictField
1.2 常用字段参数
选项参数:
# CharField及其子类的(EmailField) ---》反序列化的校验,字段自己的规则
max_length 最大长度
min_lenght 最小长度
allow_blank 是否允许为空
trim_whitespace 是否截断空白字符
# IntegerField
max_value 最小值
min_value 最大值
# 所有字段类都有的
required 表明该字段在反序列化时必须输入,默认True
default 反序列化时使用的默认值
allow_null 表明该字段是否允许传入None,默认False
validators 该字段使用的验证器
----看一眼忘掉-----
error_messages 包含错误编号与错误信息的字典
label 用于HTML展示API页面时,显示的字段名称
help_text 用于HTML展示API页面时,显示的字段帮助提示信息
# 重点:
read_only 表明该字段仅用于序列化输出,默认False
write_only 表明该字段仅用于反序列化输入,默认False
## 反序列化校验执行流程
-1 先执行字段自己的校验规则----》最大长度,最小长度,是否为空,是否必填,最小数字。。。。
-2 validators=[方法,] ----》单独给这个字段加校验规则
name=serializers.CharField(validators=[方法,])
-3 局部钩子校验规则
-4 全局钩子校验规则
2 序列化高级用法之source(了解)
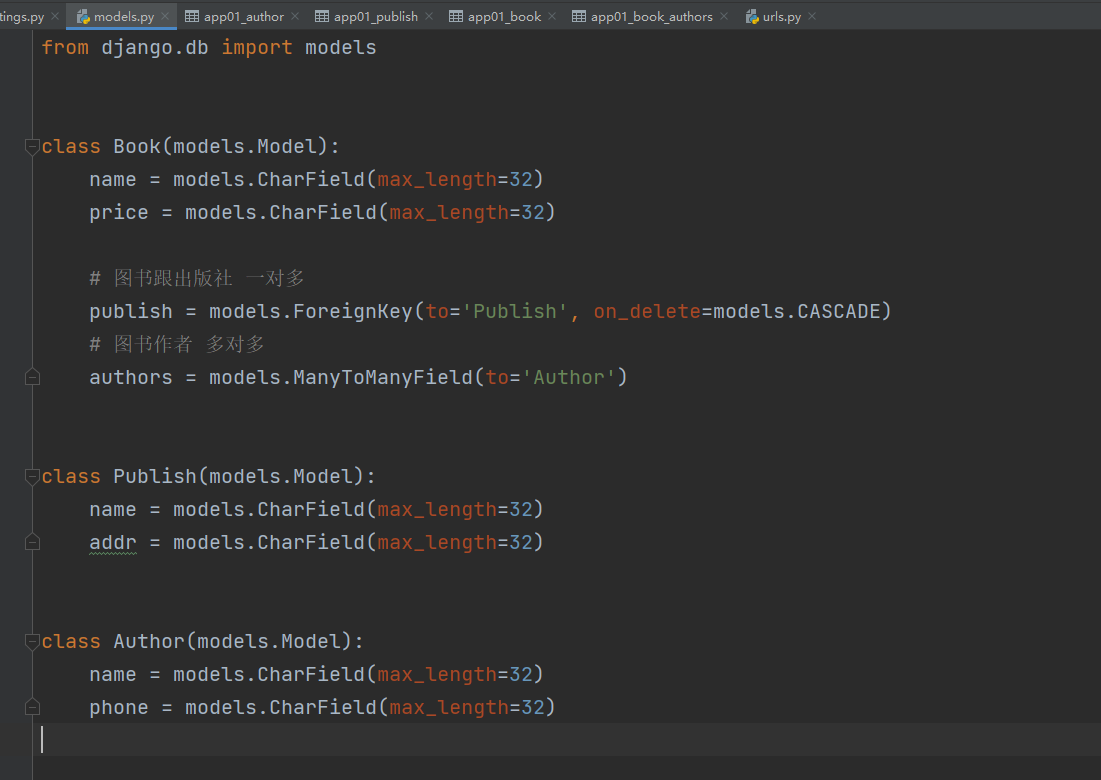
# 创建关联表
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.CharField(max_length=32)
# 图书跟出版社 一对多
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE)
# 图书作者 多对多
authors = models.ManyToManyField(to='Author')
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=32)
class Author(models.Model):
name = models.CharField(max_length=32)
phone = models.CharField(max_length=32)
# 迁移,录入数据
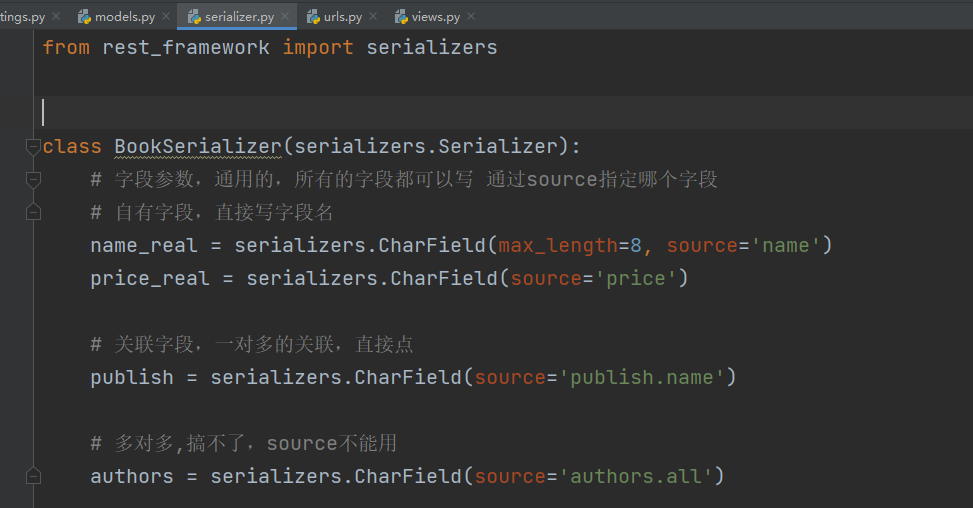
2.1 序列化定制字段名字
序列化类
class BookSerializer(serializers.Serializer):
# 字段参数,通用的,所有的字段都可以写 通过source指定哪个字段
# 自有字段,直接写字段名
name_real = serializers.CharField(max_length=8, source='name')
price_real = serializers.CharField(source='price')
# 关联字段,一对多的关联,直接点
publish = serializers.CharField(source='publish.name')
# 多对多,搞不了,source不能用
authors = serializers.CharField(source='authors.all')

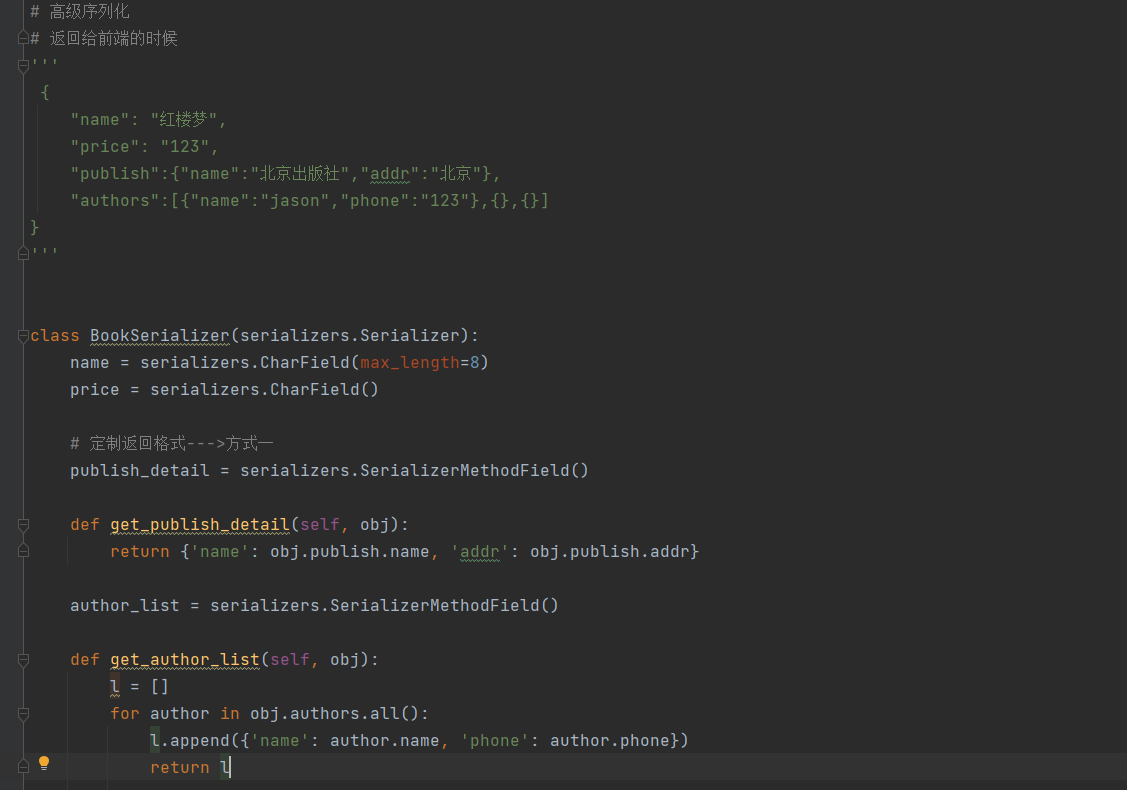
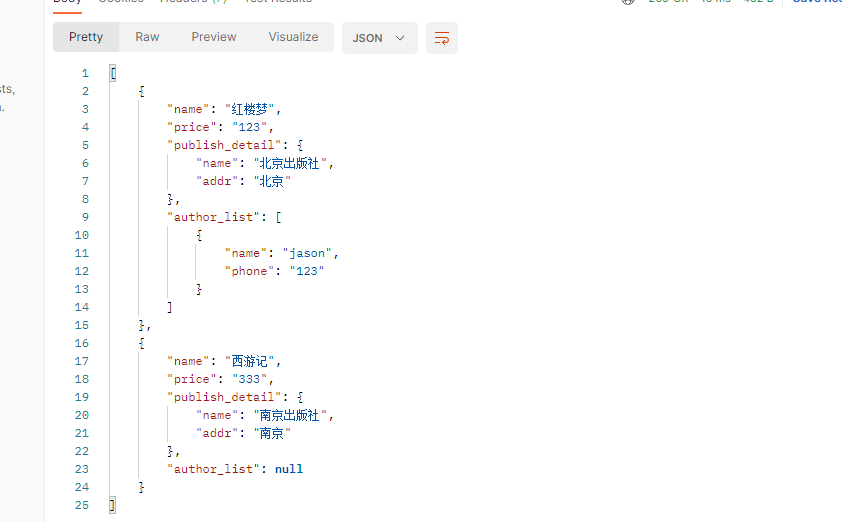
3 序列化高级用法之定制字段的两种方式
3.1 方式一:SerializerMethodField定制
# 定制关联字段的显示形式
-一对多的,显示字典
-多对多,显示列表套字典
序列化类
class BookSerializer(serializers.Serializer):
name = serializers.CharField(max_length=8)
price = serializers.CharField()
# 定制返回格式--->方式一
publish_detail = serializers.SerializerMethodField()
def get_publish_detail(self, obj):
return {'name': obj.publish.name, 'addr': obj.publish.addr}
author_list = serializers.SerializerMethodField()
def get_author_list(self, obj):
l = []
for author in obj.authors.all():
l.append({'name': author.name, 'phone': author.phone})
return l
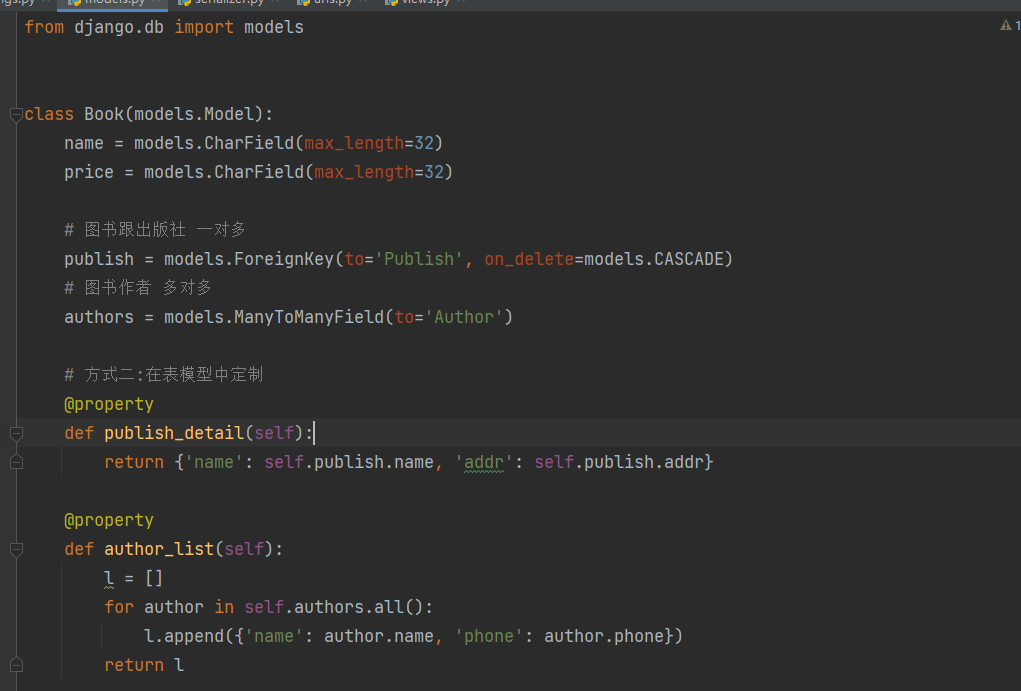
3.2 方式二:在表模型中定制
表模型
# 方式二:在表模型中定制
@property
def publish_detail(self):
return {'name': self.publish.name, 'addr': self.publish.addr}
@property
def author_list(self):
l = []
for author in self.authors.all():
l.append({'name': author.name, 'phone': author.phone})
return l
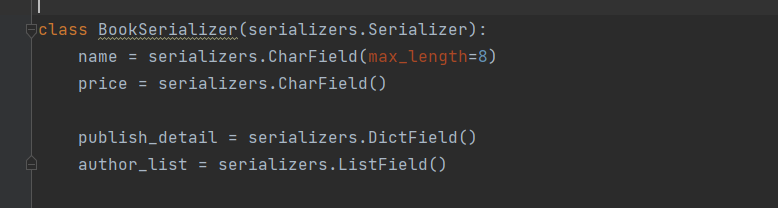
序列化类
class BookSerializer(serializers.Serializer):
name = serializers.CharField(max_length=8)
price = serializers.CharField()
# publish_detail = serializers.CharField()
publish_detail = serializers.DictField()
author_list = serializers.ListField()
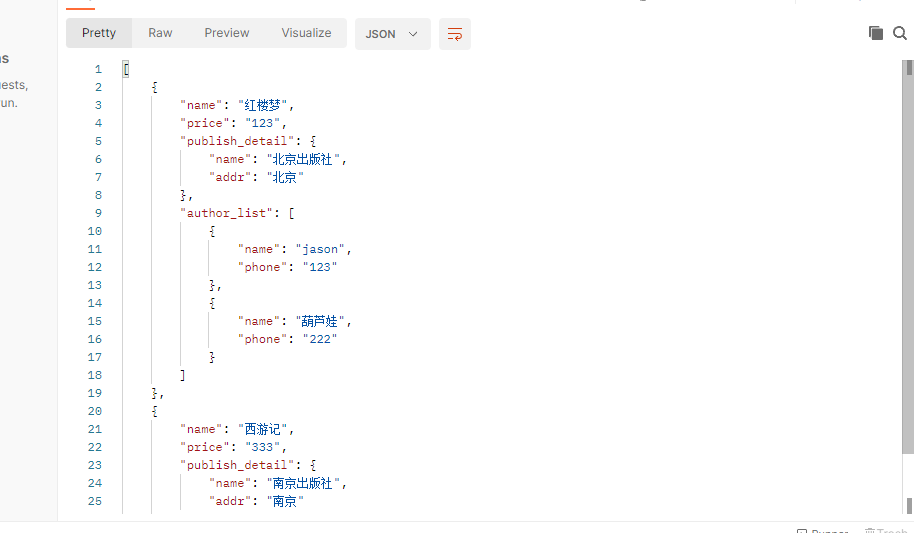
4 多表关联反序列化保存
4.1 新增图书接口
# 新增图书接口
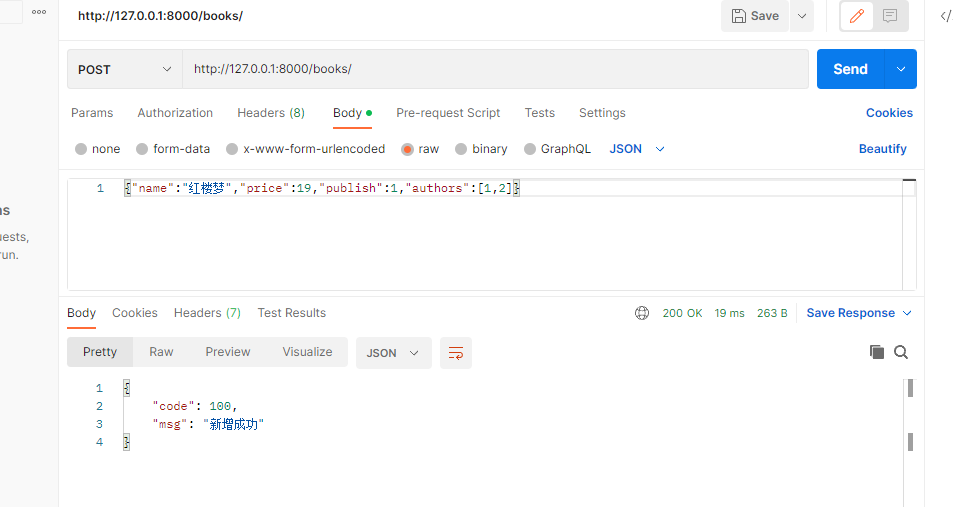
-前端传入的数据格式:{name:红楼梦,price:19,publish:1,authors:[1,2]}
视图类
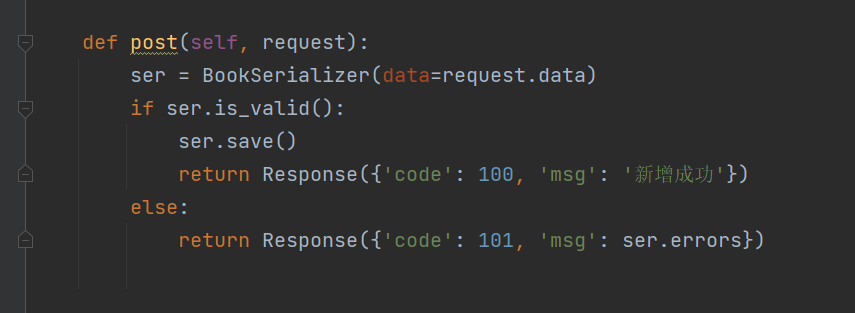
class BookView(APIView):
def post(self, request):
ser = BookSerializer(data=request.data)
if ser.is_valid():
ser.save()
return Response({'code': 100, 'msg': '新增成功'})
else:
return Response({'code': 101, 'msg': ser.errors})
序列化类
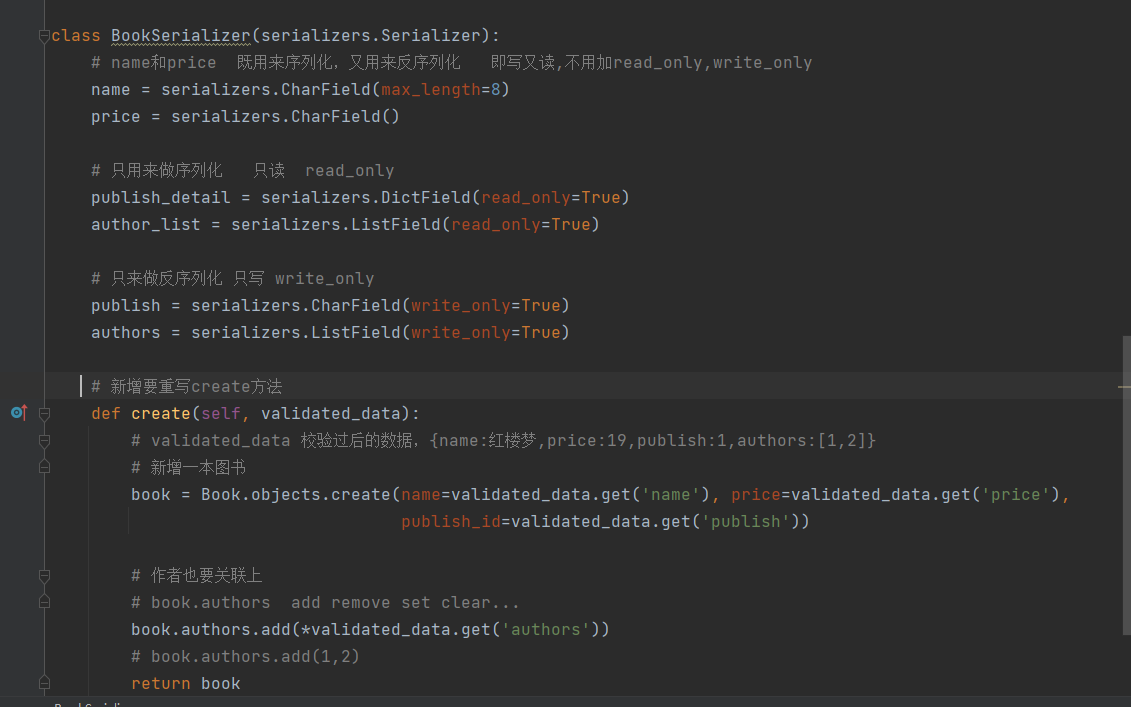
class BookSerializer(serializers.Serializer):
# name和price 既用来序列化,又用来反序列化 即写又读,不用加read_only,write_only
name = serializers.CharField(max_length=8)
price = serializers.CharField()
# 只用来做序列化 只读 read_only
publish_detail = serializers.DictField(read_only=True)
author_list = serializers.ListField(read_only=True)
# 只来做反序列化 只写 write_only
publish = serializers.CharField(write_only=True)
authors = serializers.ListField(write_only=True)
# 新增要重写create方法
def create(self, validated_data):
# validated_data 校验过后的数据,{name:红楼梦,price:19,publish:1,authors:[1,2]}
# 新增一本图书
book = Book.objects.create(name=validated_data.get('name'), price=validated_data.get('price'),
publish_id=validated_data.get('publish'))
# 作者也要关联上
# book.authors add remove set clear...
book.authors.add(*validated_data.get('authors'))
# book.authors.add(1,2)
return book
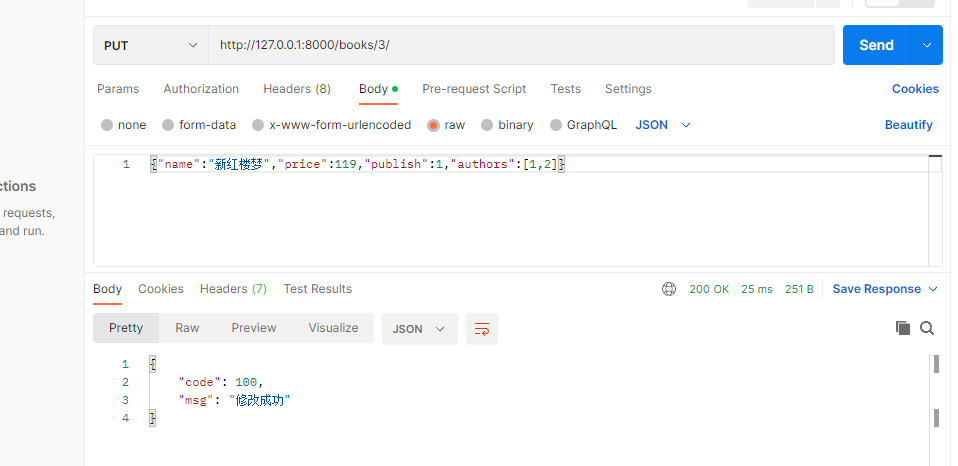
4.2 修改图书接口
# 新增图书接口
-前端传入的数据格式:{name:红楼梦,price:19,publish:1,authors:[1,2]}
路由层
path('books/<int:pk>/', views.BookDetailView.as_view()),
视图类
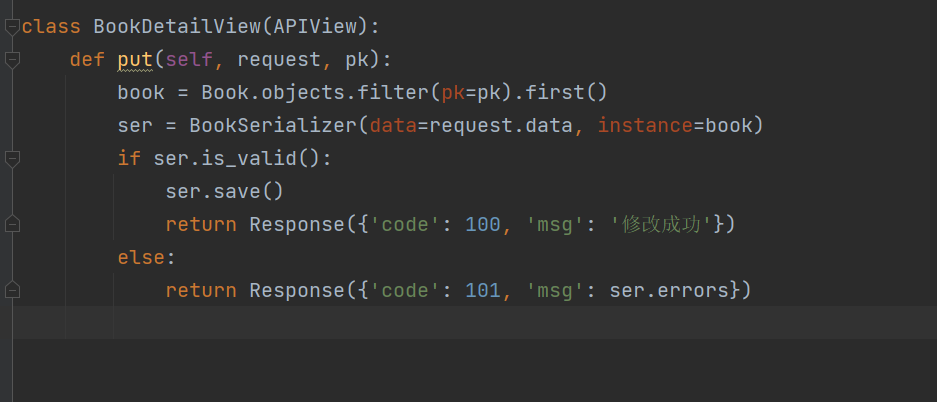
class BookDetailView(APIView):
def put(self, request, pk):
book = Book.objects.filter(pk=pk).first()
ser = BookSerializer(data=request.data, instance=book)
if ser.is_valid():
ser.save()
return Response({'code': 100, 'msg': '修改成功'})
else:
return Response({'code': 101, 'msg': ser.errors})
序列化类
#### 反序列化的多表关联的保存
class BookSerializer(serializers.Serializer):
# name和price 既用来序列化,又用来反序列化 即写又读 ,不用加read_only,write_only
name = serializers.CharField(max_length=8)
price = serializers.CharField()
# 只用来做反序列化 只写 write_only
publish = serializers.CharField(write_only=True)
authors = serializers.ListField(write_only=True)
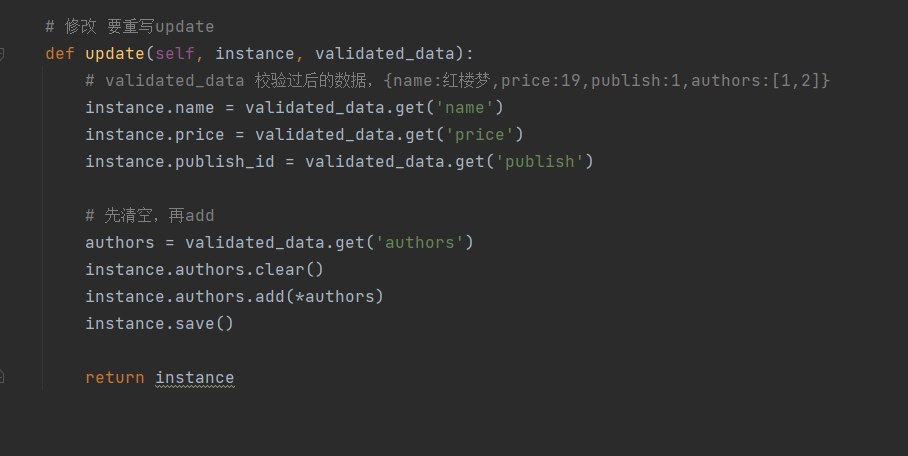
# 修改 要重写update
def update(self, instance, validated_data):
# validated_data 校验过后的数据,{name:红楼梦,price:19,publish:1,authors:[1,2]}
instance.name = validated_data.get('name')
instance.price = validated_data.get('price')
instance.publish_id = validated_data.get('publish')
# 先清空,再add
authors = validated_data.get('authors')
instance.authors.clear()
instance.authors.add(*authors)
instance.save()
return instance
5 反序列化字段校验其他
# 4层
-1 字段自己的:举例:name = serializers.CharField(max_length=8, error_messages={'max_length': '太长了'})
-2 validators=[方法,] 忽略掉
-3 局部钩子
-4 全局钩子
6 ModelSerializer使用
# ModelSerializer 继承自Serializer,帮咱们完成了很多操作
-跟表模型强关联
-大部分请求,不用写create和update了
# 如何使用
### ModelSerializer的使用
class BookSerializer(serializers.ModelSerializer):
# 跟表有关联
class Meta:
model = Book # 跟book表建立了关系 序列化类和表模型类
# fields = '__all__' # 序列化所有Book中的字段 id name price publish authors
fields = ['name', 'price', 'publish_detail', 'author_list', 'publish', 'authors'] # 序列化所有Book中的name和price字段字段
# 定制name反序列化时,最长不能超过8 给字段类加属性---方式一
extra_kwargs = {'name': {'max_length': 8},
'publish_detail': {'read_only': True},
'author_list': {'read_only': True},
'publish': {'write_only': True},
'authors': {'write_only': True},
}
# 如果Meta写了__all__ ,就相当于,复制了表模型中的所有字段,放在了这里,做了个映射
# name = serializers.CharField(max_length=32)
# price = serializers.CharField(max_length=32)
# 定制name反序列化时,最长不能超过8 给字段类加属性---方式二,重写name字段
# name = serializers.CharField(max_length=8)
# 同理,所有的read_only和wirte_only都可以通过重写或使用extra_kwargs传入
# 终极,把这个序列化类写成跟之前一模一样项目
# publish_detail = serializers.SerializerMethodField(read_only=True)
# def get_publish_detail(self, obj):
# return {'name': obj.publish.name, 'addr': obj.publish.addr}
# author_list = serializers.SerializerMethodField(read_only=True)
# def get_author_list(self, obj):
# l = []
# for author in obj.authors.all():
# l.append({'name': author.name, 'phone': author.phone})
# return l
# 局部钩子和全局钩子跟之前完全一样
def validate_name(self, name):
if name.startswith('sb'):
raise ValidationError('不能sb')
else:
return name


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律