
【CVPR2017,action recognition,动作识别】Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
本文只主要有两个贡献。
-
ImageNet表明在足够大的数据集上训练网络之后,在其他的数据集甚至其它类型的任务上直接使用pre-trained参数初始化能够取得很好的效果。本文探究了在足够大的视频数据集Kinetics上训练了之后在UCF101和HMDB51上能够得到非常好的效果,可以达到在目前最好的效果。
-
总结了经典的动作分类方法,提出了一个新的结构组合方式,即把3Dconv应用到two-tream的两个分支中,而且输入的是整个视频。中并做了对比实验。
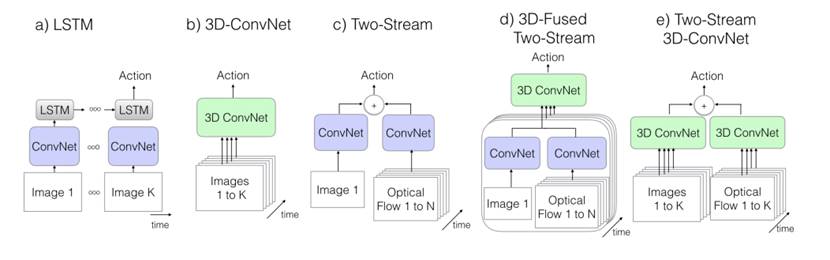
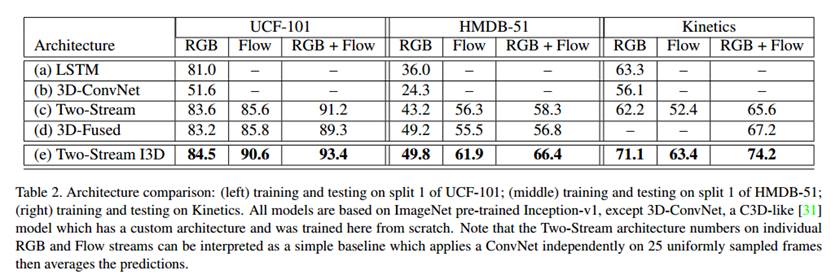
在各个数据集上都得到了最好的正确率。但是作者的新结构输入的数据更多,这样直接对比我觉得有点不公平。TSN+Two-tream只在4块Titan上训练了9个小时,文中的网络用了64块GPU,这不能充分说明作者提出的网络结构更好。在two-tream上也加大输入的数据量对比更有说服力一点。
另外作者提出时间域卷积和空间域卷积和池化不一定要相同的步长,时间域卷积太快可能会导致在空间域上还没有获得特征就被来自不同帧的图像重叠破坏掉了,时间域卷积太慢又可能抓不住运动特征。作者在第前两次池化时在时间域上的长度为1,说这样得到的效果比较好,其中的原因没有搞太清楚,我猜想可能这样有助于捕捉细粒度的运动信息。
另外从上图的数据来看,I3D在Kinetics首次实现了RGB的正确率超过Flow,说明I3D确实是能够直接中原始视频中捕获时序信息的。
