正则表达式
一 . 正则表达式
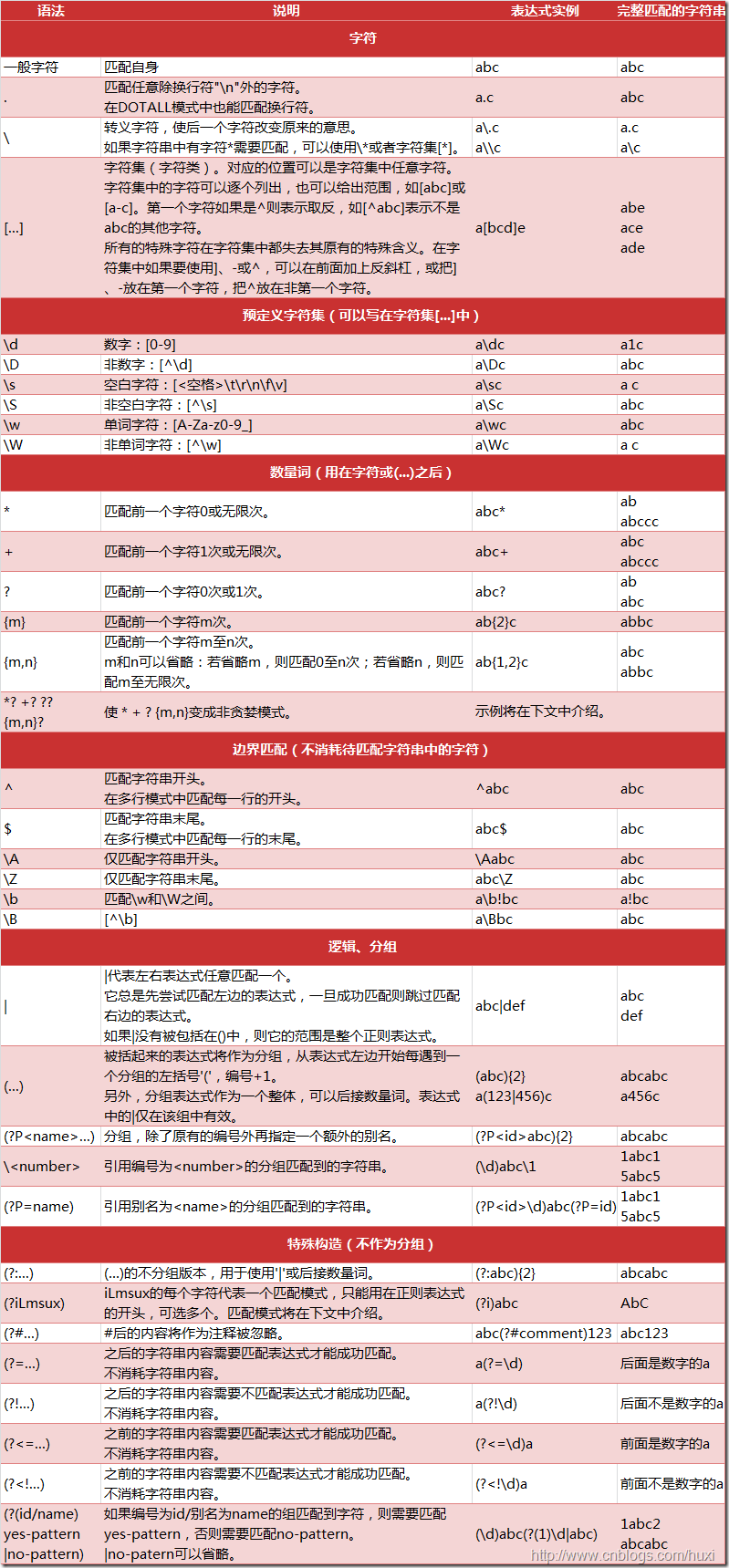

1. 给段字符串判断是否是手机号码
def aa(str): if len(str)!=11: return False elif str[0]!="1": return False elif str[1:3]!="39" and str[1:3]!="31": return False for i in range(3,11): if str[i]<"0" or str[i]>"9": return False return True age=input("请输入你的电话号码:") n=aa(age) print(n)
2. 正则概述
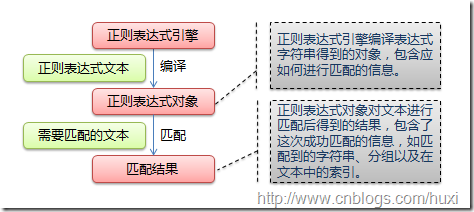
1. 正则表达式基础 1.1. 简单介绍 正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,
在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式 ,只需要简单看一看就可以上手了。 2. re模块 2.1. 开始使用re Python通过re模块提供对正则表达式的支持。 使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例, 然后使用Pattern实例处理文本并获得匹配结果(一个Match实例), 最后使用Match实例获得信息,进行其他的操作。 import re re.match函数 原型: match(pattern,string,flags=0) pattern :匹配的正则表达式(匹配格式) string :要匹配的字符串 flages : 标志位 用于控制正则表达式的匹配方式 re.I 忽略大小写 re.L 做本地户识别 re.M 多行匹配 影响 ^和$ re.S 是.匹配任意包括换行符在内的所有字符 re.U 根据 Unicode 字符集解析字符 影响 \w \W \b \B re.X 使我们以更灵活的格式理解正则表达式 参数: 功能:尝试从字符串的起始位置匹配一个模式如果不是起始位置 成功的话,返回 None re.match() "***********************华丽的分割线***********************************" re.search()函数 原型: reach(pattern,string,flags=0) pattern :匹配的正则表达式(匹配格式) string :要匹配的字符串 flages : 标志位 用于控制正则表达式的匹配方式 功能: 扫描整个字符串 并且返回第一个成功的匹配 str="my name is love and to bing love" a=re.search("love",str) print(a) "***********************华丽的分割线***********************************" re.findall()函数 原型: findall(pattern,string,flags=0) pattern :匹配的正则表达式(匹配格式) string :要匹配的字符串 flages : 标志位 用于控制正则表达式的匹配方式 功能: 扫描整个字符串 并返回结果列表 str="my name is love and to bing love" a=re.findall("love",str) print(a) #['love', 'love']
3. 使用简单的正则match
# re.match函数 # 原型: match(pattern,string,flags=0) # pattern :匹配的正则表达式(匹配格式) # string :要匹配的字符串 # flages : 标志位 用于控制正则表达式的匹配方式 # re.I 忽略大小写 # re.L 做本地户识别 # re.M 多行匹配 影响 ^和$ # re.S 是.匹配任意包括换行符在内的所有字符 # re.U 根据 Unicode 字符集解析字符 影响 \w \W \b \B # re.X 使我们以更灵活的格式理解正则表达式 # 参数: # 功能:尝试从字符串的起始位置匹配一个模式如果不是起始位置 # 成功的话,返回 None # re.match() import re # 例如:百度网址 a=re.match("www","www.baidu.com") # <_sre.SRE_Match object; span=(0, 3), match='www'> print(a) print("***********************华丽的分割线***********************************") b=re.match("wwW","www.baidu.com") print(b) # None 表示没有匹配上 print("***********************华丽的分割线***********************************") c=re.match("wwW","www.baidu.com", flags=re.I) print(c) # 不区分大小写 # <_sre.SRE_Match object; span=(0, 3), match='www'> print("***********************华丽的分割线***********************************") d=re.match("www","www.baidu.com").span() print(d) (0, 3) #可以得到匹配的位置
4. 使用简单正则search
# re.search()函数 # 原型: reach(pattern,string,flags=0) # pattern :匹配的正则表达式(匹配格式) # string :要匹配的字符串 # flages : 标志位 用于控制正则表达式的匹配方式 # 功能: 扫描整个字符串 并且返回第一个成功的匹配 import re str="my name is love and to bing love" a=re.search("love",str) print(a) # <_sre.SRE_Match object; span=(11, 15), match='love'>
5. 使用简单正则findall
# re.findall()函数 # 原型: findall(pattern,string,flags=0) # pattern :匹配的正则表达式(匹配格式) # string :要匹配的字符串 # flages : 标志位 用于控制正则表达式的匹配方式 # 功能: 扫描整个字符串 并返回结果列表 import re str="my name is love and to bing love" a=re.findall("love",str) print(a) #['love', 'love'] 返回匹配的个数
6. 正则表式元字符
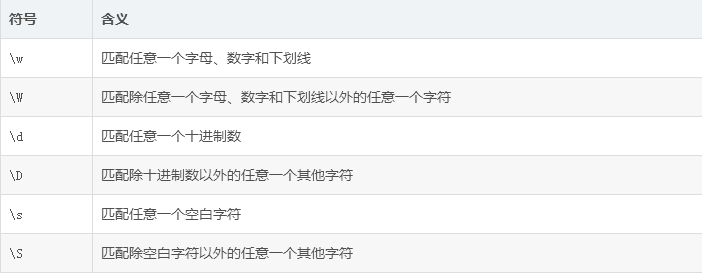
import re # . 匹配除换行符以外的任意字符 # [0123456789] []是字符集合 表示匹配方括号中所包含的任意一个字符 # [love] [] 匹配 'l','o','v','e' 中任意字符 # [a-z] 匹配任意小写字母 # [A-Z] 匹配任意大写字母 # [0-9] 匹配任意数字 类似: [0123456789] # [0-9a-zA-Z] 匹配任意的数字 字母包括大小写 # [0-9a-zA-Z_] 匹配任意的数字 字母包括大小写 和下划线 # [^love] 匹配除了love 这几个字母以外的所有字符 # 中括号里的^称为托字符 表示不匹配集合中的字符 # [^0-9] 匹配所有的非数字字符 #\d 匹配所有数字 效果如同[0-9] # \D 匹配非数字字符 效果如同[^0-9] # \w 匹配数字 字母 下划线 效果如同[0-9a-zA-Z] # \W 匹配非数字 字母 和下划线 效果如同[^0-9a-zA-Z # \s 匹配任意的空白符 (换行 空格 回车 换页 制表) # 效果同 [\f \n \r \t] # \S 匹配任意的非空白符 效果同 [^\f \n \r \t] str="my name is love and to bing love" a=re.search(".",str) print(a) # <_sre.SRE_Match object; span=(0, 1), match='m'> print("***********************华丽的分割线***********************************") # [0123456789] []是字符集合 表示匹配方括号中所包含的任意一个字符 str="my name is love an6d to bin5g love" b=re.search("[0123456789]",str) print(b) # <_sre.SRE_Match object; span=(19, 20), match='6'> print("***********************华丽的分割线***********************************") # [love] [] 匹配 'l','o','v','e' 中任意字符 str="my name is love and to bing love" c=re.search("[love]",str) print(c) # <_sre.SRE_Match object; span=(6, 7), match='e'>
7. 正则表式元字符
import re # . 匹配除换行符以外的任意字符 # [0123456789] []是字符集合 表示匹配方括号中所包含的任意一个字符 # [love] [] 匹配 'l','o','v','e' 中任意字符 # [a-z] 匹配任意小写字母 # [A-Z] 匹配任意大写字母 # [0-9] 匹配任意数字 类似: [0123456789] # [0-9a-zA-Z] 匹配任意的数字 字母包括大小写 # [0-9a-zA-Z_] 匹配任意的数字 字母包括大小写 和下划线 # [^love] 匹配除了love 这几个字母以外的所有字符 # 中括号里的^称为托字符 表示不匹配集合中的字符 # [^0-9] 匹配所有的非数字字符 #\d 匹配所有数字 效果如同[0-9] # \D 匹配非数字字符 效果如同[^0-9] # \w 匹配数字 字母 下划线 效果如同[0-9a-zA-Z] # \W 匹配非数字 字母 和下划线 效果如同[^0-9a-zA-Z # \s 匹配任意的空白符 (换行 空格 回车 换页 制表) # 效果同 [\f \n \r \t] # \S 匹配任意的非空白符 效果同 [^\f \n \r \t] str="my name is love and to bing love" a=re.search(".",str) print(a) # <_sre.SRE_Match object; span=(0, 1), match='m'> print("***********************华丽的分割线***************************") # [0123456789] []是字符集合 表示匹配方括号中所包含的任意一个字符 str="my name is love an6d to bin5g love" b=re.search("[0123456789]",str) print(b) # <_sre.SRE_Match object; span=(19, 20), match='6'> print("***********************华丽的分割线***********************************") # [love] [] 匹配 'l','o','v','e' 中任意字符 str="my name is love and to bing love" c=re.search("[love]",str) print(c) # <_sre.SRE_Match object; span=(6, 7), match='e'> print("***********************华丽的分割线***********************************") print("***********************华丽的分割线***********************************") str="my nam9e is lo6ve and 5to bing love" d=re.findall("\d",str) print(d) #['9', '6', '5']
8. re模块深入 分组-
# 分组: # 除了简单判断是否匹配之外 正则表达式还提取子串的功能 用()表示就是提取分组 print("***********************华丽的分割线***********************************") import re str1="010-12345678" m=re.match(r"(\d{3})-(\d{8})",str1) print(m.group(0)) # 010-12345678 print(m.group(1)) # 010 print(m.group(2)) # 12345678 str2="010-12345678" v=re.match(r"(\d{3})-(\d{8})",str2) # 使用序号获取对应组的信息 group (0) 一只代表的原始字符串 print(v.group(0)) # 010-12345678 print(v.group(1)) # 010 print(v.group(2)) # 12345678 print(v.groups()) #('010', '12345678') 查看匹配的各组的情况 print("**RRRR*********************华丽的分割线***********************************") # 编译: 当我们使用正则表达式时 re 模块会干两件事 # 1 . 编译正则表达式 如果正则表达式 本身不合法 会报错 # 2. 用编译后的正则表达式去匹配对象 # compile(pattern,flages=0) # pattern :匹配的正则表达式(匹配格式) # a=r"^1(([3578]\d)|(47))\d{8}$" print(re.match(a,"13600000000")) # 编译正则表对象 re_telephon=re.compile(a) re_telephon.match("13600000000") 正则函数 re.match(pattern,string,flags=0) re模块 调用 re_telephon.match(string) re 对象调用 re.search(pattern,string,flags=0) re_telephon.search(string) re.findall(pattern,string,flags=0) re_telephon.findall(string) re.finditer(pattern,string,flags=0) re_telephon.finditer(string) re.sub() re_telephon.sub(string) re.subn() re_telephon.subn(string) re.split(pattern,string,maxsplit=0,flags=0) re_telephon.split(string,maxsplit=0)
9. re模块深入
import re # 正则字符串切割 str1="my name is lover to 哈哈哈" print(str1.split(" ")) # ['my', 'name', 'is', 'lover', 'to', '哈哈哈'] print(re.split(r" +",str1)) # ['my', 'name', 'is', 'lover', 'to', '哈哈哈'] # # # re.finditer函数 # 原型: .finditer(pattern,string,flags=0) # pattern :匹配的正则表达式(匹配格式) # string :要匹配的字符串 # flages : 标志位 用于控制正则表达式的匹配方式 # # 功能:与fandall 类似扫描整个字符串 返回的是一个迭代器 # str3="my is zhangsan man!my a nice lisi man! my is av ery man" d=re.finditer(r"(my)",str3) while True: try: l=next(d) print(d) except StopIteration as e: break # <callable_iterator object at 0x004F57B0> # <callable_iterator object at 0x004F57B0> # <callable_iterator object at 0x004F57B0> # # re模块 字符串替换和修改 # sub() 函数 # subn() # 参数:sub(pattern,repl,string,count=0) # subn(pattern,repl,string,count=0) # pattern : 匹配的正则表达式(匹配格式) # repl : 指定的用来替换的字符串 # string : 目标字符串 # count=0 : 最多替换次数 # flages=0 : 标志位 用于控制正则表达式的匹配方式 # 功能: 在目标字符串中以正则表达式的规则匹配字符串,在把他们替换成指定的字符串 可以指定替换的次数 如果不指定 就替换所有的匹配字符串 # 区别: # sub() 返回一个被指定替换的字符串 # subn()返回一个元组 第一是替换的字符串 ,第二个元素表被替换的次数 str5="my is a good good man good " print(re.sub(r"(good)","nice",str5)) # my is a nice nice man str6="my is a good good man good and good hao to good" print(re.sub(r"(good)","nice",str6,count=3)) # my is a nice nice man nice and good hao to good print("***********************华丽的分割线***********************************") str6="my is a good good man good " print(re.subn(r"(good)","nice",str6)) print(type(re.subn(r"(good)","nice",str6))) # ('my is a nice nice man nice ', 3) # <class 'tuple'>
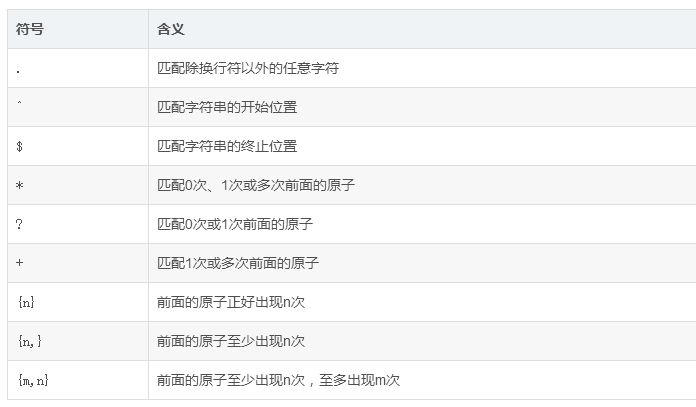
10 . 锚字符(边界字符)
import re # 锚点字符(边界字符) # ^ :表示行首匹配 和[^]意思不一样 # $ : 行尾匹配 # # \A 匹配字符串开始 它和^的区别 是 \A只匹配正个字符串的 # \Z 匹配字符串的结束 它和$的区别是 \Z 只能匹配整个字符串的结束 即使在re.M模式下也不会匹配它的行尾 #开头,即使在 re.M模式下也不会匹配它行的行首 # \b 匹配一个单词的边间 也就是指单词和空格的位置 # \B 匹配非单词边界 str="my name is love and to bing love" a=re.search("love$",str) print(a) # <_sre.SRE_Match object; span=(29, 33), match='love'> str="my name is love and to bing love" b=re.search("^my",str) print(b) # <_sre.SRE_Match object; span=(0, 2), match='my'> print("***********************华丽的分割线***************************") str="my name is love and to bing love\n my 哈哈哈 loer" e=re.findall("^my",str,re.M) print(e) # ['my'] print("***********************华丽的分割线***************************") str="my name is love and to bing love\n my 哈哈哈 love" g=re.findall("love$",str,re.M) print(g) # ['love'] ['love'] str="my name is love and to bing love\n my 哈哈哈 love" f=re.findall("love\Z",str,re.M) print(f) #['love'] print("***********************华丽的分割线***************************") str="my name is love and to bing love my 哈哈哈 love" h=re.search("lo\b",str,re.M) print(h) # None str="my name is love and to bing love my 哈哈哈 love" j=re.search("lo\B",str,re.M) print(j) #<_sre.SRE_Match object; span=(11, 13), match='lo'>
11. 字符匹配多个
import re # zyx n m是假设的 # (xyz) 匹配小括号的xyz (作为一个整体去匹配) # x? 匹配零个或者多个X # x* 匹配0个或者任意多个x 贪婪匹配 尽可能多匹配 # x+ 匹配至少一个x # x{n} 去匹配确定n个x (n是一个非负数) # x{n,} 匹配至少n个x # x{n,m} 匹配至少n个最多m个x 注意:n<=m # x|Y 匹配的是x或者y print("***********************华丽的分割线***************************") print(re.findall(r"(lover)","my name lover to boy lover")) #['lover'] # ['lover', 'lover'] print("***********************华丽的分割线***************************") print(re.findall(r"o?","my name lover to boy lover")) # [ 'o', '', '', '', '', '', 'o', '', '', 'o', '', '', '', '', 'o', '', '', '', ''] print("***********************华丽的分割线***************************") print(re.findall(r"a*","aaaabbbba")) # ['aaaa', '', '', '', '', 'a', ''] print("***********************华丽的分割线***************************") print(re.findall(r"a+","aaaabbbbaAA")) #['aaaa', 'a'] print("***********************华丽的分割线***************************") print(re.findall(r"a{3}","aaaabbbbaAA"))#['aaa'] print("***********************华丽的分割线***************************") print(re.findall(r"a{3,}","aaaabbbbaAAAAaaaaaaaAA")) #['aaaa', 'aaaaaaa'] print("***********************华丽的分割线***************************") print(re.findall(r"a{3,6}","aaaabbbbaAAAAaaaaaavaaaaaaaaAA")) #['aaaa', 'aaaaaa', 'aaaaaa'] print("***********************华丽的分割线***************************") print(re.findall(r"((l|L)over)","lover=====Lover")) # [('lover', 'l'), ('Lover', 'L')]
12. 练习正则
import re # 需求: srt="my is a good man!my is a niace man! my is a very handsome man" print(re.findall(r"^my(.*?)man$",srt)) print("***********************华丽的分割线***************************") # *? +? x? 最小匹配 通常都是尽可能多的匹配 可以使用这种可以解决贪婪模式 (?:x) 类似(xyz) 但是不表示 一个组
13. 练习正则
import re # 给段字符串判断是否是手机号码 def aa(str): if len(str)!=11: return False elif str[0]!="1": return False elif str[1:3]!="39" and str[1:3]!="31": return False for i in range(3,11): if str[i]<"0" or str[i]>"9": return False return True age=input("请输入你的电话号码:") n=aa(age) print(n) def cc(str): # "13912345678" a=r"^1(([3578]\d)|(47))\d{8}$" res=re.match(a,str) return res print(cc("13912345678"))
14. 练习正则
QQ : 1837855846 mail : loveraa@163.com phone : 010-55348765 user : ip : url : # QQ正则 re_QQ=re.compile(r"^[1-9]\d{5,9}$") print(re_QQ.search("1234567890")) re.compile() 函数 编译正则表达式模式,返回一个对象。可 以把常用的正则表达式编译成正则表达式对象,方便后续调用及提高效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号