

1.简介
美国地质勘探局(United States Geological Survey,简称USGS),是美国内政部所属的科学研究机构。负责对自然灾害、地质、矿产资源、地理与环境、野生动植物信息等方面的科研、监测、收集、分析;对自然资源进行全国范围的长期监测和评估。USGS地球探测器遥感数据集非常丰富,包括航空影像、AVHRR、商业影像、数字高程模型、陆地卫星、激光雷达、MODIS、雷达等。
USGS Lidar Explorer Map的创建主要是为了识别启用了3D可视化的激光雷达项目(通过Entwine),它为用户提供了一种通过基于网络的可视化激光雷达的数据使用机制。同时,该网站还为用户提供了对项目元数据的集成访问,即可通过下载GeoPackage提供,而无需单独下载空间元数据。此外,Lidar Explorer还提供DEM产品和源产品的下载,以便根据用户定义的兴趣区域轻松比较覆盖范围和下载大小。最后,USGS Lidar Explorer Map提供了一种使用云处理功能从Lidar派生产品的机制,该功能利用了公共可用的EPT Lidar数据和点数据抽象库(PDAL)。
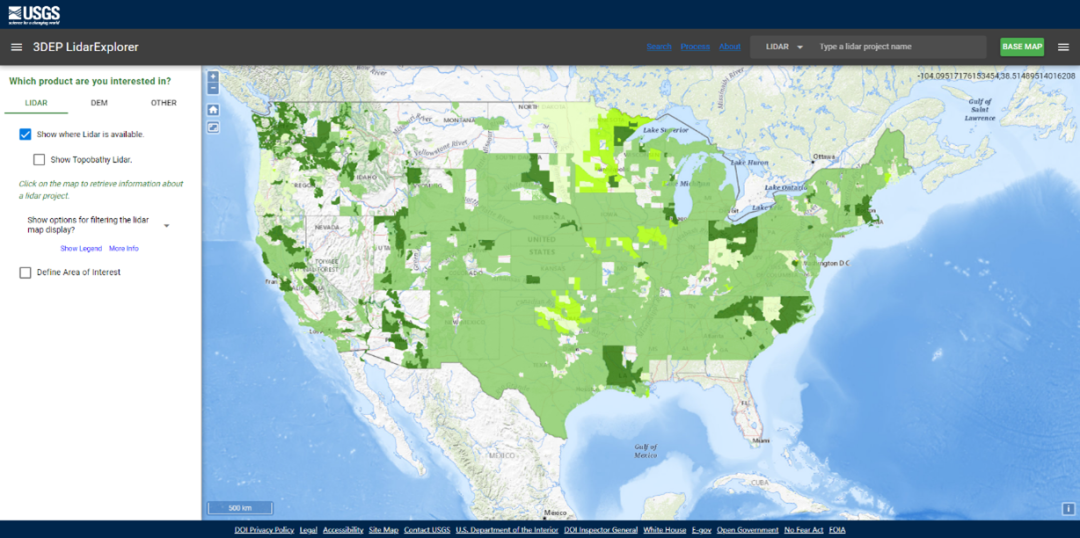
然而,由于搜索范围广和数据量大,Lidar数据难以快速批量下载,故以USGS Lidar Explorer Map点云数据为例,本次干货整理了利用Python和LIDAR360等软件,通过该网站批量下载和可视化数据的方法。
2.实验过程
1.选取数据
点击图层左上角的“Draw Area of Interest”按钮设置感兴趣的区域,可以双击浏览器来创建感兴趣的区域。感兴趣区域(AROI) 是限制搜索以获取数据的地理边界。接着,在“数据集”选项卡中选择要下载的数据,集合之间的差异基于数据质量和处理级别。USGS已根据质量和处理级别将图像分类为多个级别。

2.获取数据下载链接
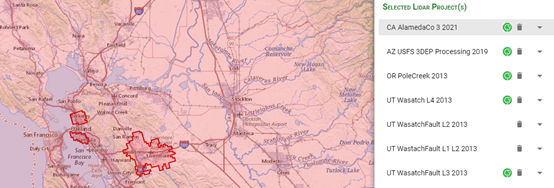
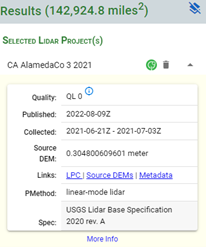
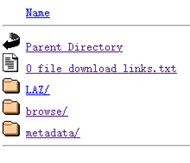
点击右侧数据详情页,如图所示红线范围内即为右边选中数据的可下载范围,选择Links中的LPC链接,点击0_file_download_links.txt,选择得到所有数据的url数据。由于本次实验为示范实验,故只选择部分数据,其中每个url对应选中数据范围内的一个地块(tile)。
3.批处理下载准备
根据所需地块名称找到对应的url,并将需要的数据下载链接复制到Excel表格中(注:表格是.xls格式),具体格式如下所示。

4.下载数据
以下是进行批量下载数据的代码,包括数据准备,初始化命名以及数据的单线程下载和多线程下载部分。

import xlrd import requests import logging import threading import time import random [yk1] a = xlrd.open_workbook('C:/Users/WINDOWS/Desktop/download.xls', 'r') # 打开.xlsx文件,在这之前要把所有的下载链接都填到excel表中 sht = a.sheets()[0] # 打开表格中第一个sheet # row1 = sht.row_values(0) # 设置要下载的数据的范围,对应于 Excel 中的行数 start = 1 # 获取excel表的所有行数 nrows = sht.nrows; def fetch(url, filename): r = requests.get(url) url2 = url[-3:] # 根据链接地址获取文件后缀 dir = r"E:\laz\\" + filename + "." + url2 # 构造完整文件名称 with open(dir, "wb") as code: code.write(r.content) # 保存文件 print(url) # 打印当前的 URL jindu = (i - start) / (nrows - start) * 100 # 计算下载进度 print("下载进度:", jindu, "%") # 显示下载进度 ######单进程下载######### # for i in range(start, nrows): # url = sht.cell(i, 3).value # 依次读取每行第3列的数据,也就是 URL # if url: # logging.info(url) # f = requests.get(url) # roadName=sht.cell(i,2).value # markNo=sht.cell(i, 1).value # ii = str(roadName)+"_"+markNo # 按照下载顺序(行号)构造文件名,filename # url2 = url[-3:] # 根据链接地址获取文件后缀 # dir = r"G:\Mississippi\ALS Region\ALS Data\\"+ii + "." + url2 # 构造完整文件名称 # with open(dir, "wb") as code: # code.write(f.content) # 保存文件 # print(url) # 打印当前的 URL # jindu = (i - start) / (nrows - start) * 100 # 计算下载进度 # print("下载进度:", jindu, "%") # 显示下载进度 #######多进程下载####### t1 = time.time() t_list = [] for i in range(start, nrows): user_agent_list = [ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; WOW64) Gecko/20100101 Firefox/61.0", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)", "Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15", ] headers = {'User-Agent': random.choice(user_agent_list)} # 分配随机user agent,避免认为是恶意攻击 url = sht.cell(i, 2).value # 依次读取每行第3列的数据,也就是 URL if url: logging.info(url) roadName = sht.cell(i, 1).value # markNo=sht.cell(i, 1).value # filename = str(roadName)+"_"+markNo # 按照下载顺序(行号)构造文件名 filename = sht.cell(i, 1).value # filename = url.split('.')[2].split('_')[-3] t = threading.Thread(target=fetch, args=(url, filename)) t_list.append(t) t.start() for t in t_list: t.join() print("多线程版爬虫耗时:", time.time() - t1)
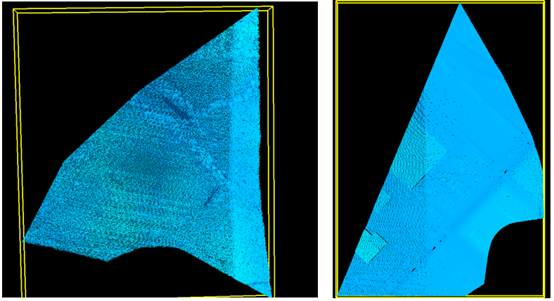
3.实验结果
利用LIDAR360软件显示最终下载的点云数据,如下图所示:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人