正则表达式
导图
1.正则表达式概述
正则表达式(REGEXP: Regular Expressions):由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能,类似于增强版的通配符功能,
但与通配符不同,通配符功能是用来处理文件名,而正则表达式是处理文本内容中字符
通常用于判断语句中,用来检查某一字符串是否满足某一格式
• 正则表达式是由普通字符与元字符组成
• 普通字符包括大小写字母、数字、标点符号及一些其他符号
• 元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
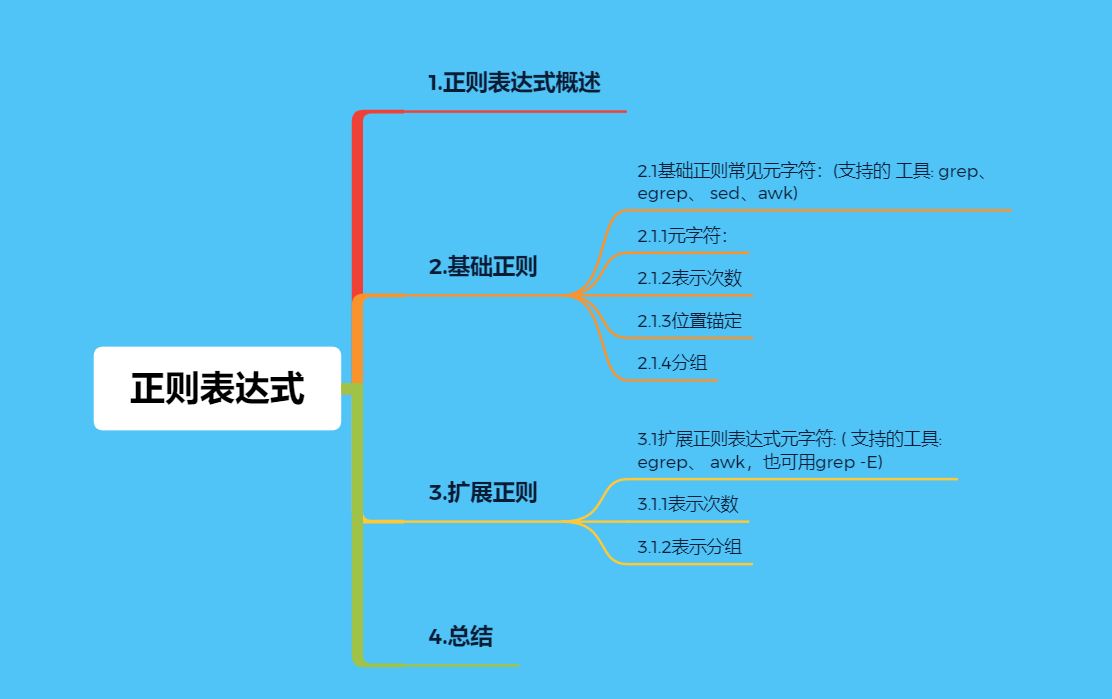
2.基础正则
2.1基础正则常见元字符:(支持的 工具: grep、 egrep、 sed、awk)
2.1.1元字符:
. //匹配任意单个字符,可以是一个汉字 [] //匹配指定范围内的任意单个字符,示例:[zhou] [0-9] [] [a-zA-Z] [^] //匹配指定范围外的任意单个字符,示例:[^zhou] [^a.z] a.z [:alnum:] //字母和数字 [:alpha:] //代表任何英文大小写字符,亦即 A-Z, a-z [:lower:] //小写字母,示例:[[:lower:]],相当于[a-z] [:upper:] //大写字母 [:blank:] //空白字符(空格和制表符) [:space:] //包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广 \w //匹配单词构成部分,等价于[_[:alnum:]] \W //匹配非单词构成部分,等价于[^_[:alnum:]] \S //匹配任何非空白字符。等价于 [^ \f\n\r\t\v] \s //匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]
2.1.2表示次数
* //匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配 .* //任意长度的任意字符 \? //匹配其前面的字符出现0次或1次,即:可有可无 \+ //匹配其前面的字符出现最少1次,即:肯定有且 >=1 次 \{n\} //匹配前面的字符n次 \{m,n\} //匹配前面的字符至少m次,至多n次 \{,n\} //匹配前面的字符至多n次,<=n \{n,\} //匹配前面的字符至少n次
2.1.3位置锚定
^ //行首锚定, 用于模式的最左侧 $ //行尾锚定,用于模式的最右侧 ^PATTERN$ //用于模式匹配整行 (单独一行 只有root) ^$ //空行
^[[:space:]]*$ //空白行 \< 或 \b //词首锚定,用于单词模式的左侧(连续的数字,字母,下划线都算单词内部) \> 或 \b //词尾锚定,用于单词模式的右侧 \<PATTERN\> //匹配整个单词
2.1.4分组
分组:() //将多个字符捆绑在一起,当作一个整体处理,如:\(root\)+
实例1:^ 表示匹配字符串开始的位置,匹配行首
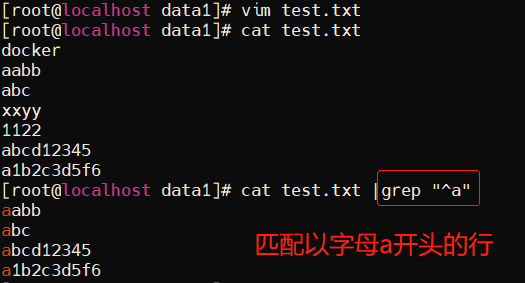
实例2: $表示匹配字符串末尾的位置,匹配行尾

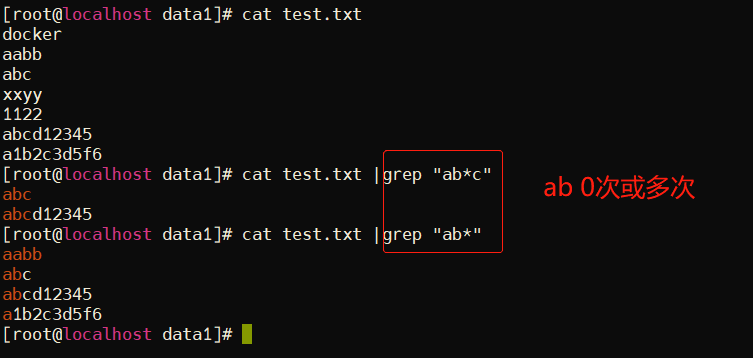
实例3:* 匹配前面子表达式0次或者多次
3.扩展正则
注: egrep(grep-E)、awk使用{n }、{n, }、{n,m}匹配时"{}”前不用加"\"
3.1扩展正则表达式元字符: ( 支持的工具: egrep、 awk,也可用grep -E)
3.1.1表示次数
* //匹配前面字符任意次 ? //0或1次 + //1次或多次 {n} //匹配n次 {m,n} //至少m,至多n次 {,n} //匹配前面的字符至多n次,<=n,n可以为0 {n,} //匹配前面的字符至少n次,<=n,n可以为0
3.1.2表示分组
() 分组 分组:() 将多个字符捆绑在一起,当作一个整体处理,如:\(root\)+ 后向引用:\1, \2, ... | 或者 a|b #a或b C|cat #C或cat (C|c)at #Cat或cat
4.总结
- 正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的文字模式。
- 模式描述在搜索文本时要匹配的一个或多个字符串。
- 正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号