通过PRINT过程制作报表
通过PRINT过程制作报表
PRINT过程是SAS中用于输出数据集内容的最简单常用的过程,它可将选择的观测和字段以简单的矩形表格形式输出。
1.1 制作简单报表
使用PRINT过程最简单的语法形式如下:
PROC PRINT <DATA=数据集>;
RUN;
当选项DATA=被省略时,系统默认输出最新创建的数据集。为了保证代码的清晰易读,不建议省略。也可以使用数据文件地址和全称来代替数据集。
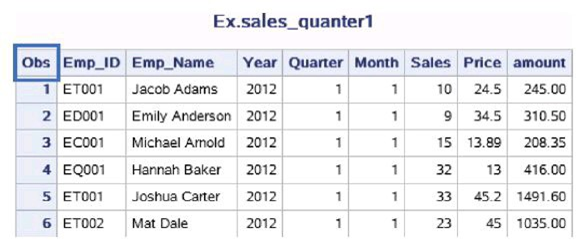
数据集ex.sales_quater1代表某公司2012年第一季度的销售数 据,Emp_ID代表员工ID,Emp_Name代表员工姓名,Year代表年份,Quarter代表季度,Sales代表销售数量,Price代表价格,Amount代表销 售额。现在要用PRINT过程输出它的内容。
示例代码如下:
proc print data=ex.sales_quarter1; title 'Ex.sales_quanter1'; run;
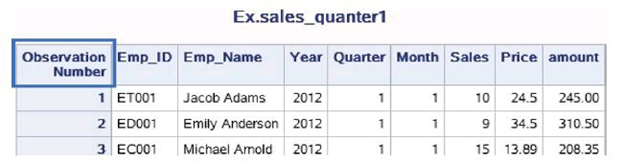
1.使用选项OBS=修改观测序号列标签在PRINT过程中可利用选项OBS=来修改最左侧观测序号一列的标 签。例如:
proc print data=ex.sales_quarter1 obs='Observation Number'; title 'Ex.sales_quanter1'; run;
2.使用NOOBS选项不显示观测序号列
如果不需要在输出结果中显示观测序号列,则可以使用NOOBS选项。
proc print data=ex.sales_quarter1 noobs; title 'Ex.sales_quanter1'; run;
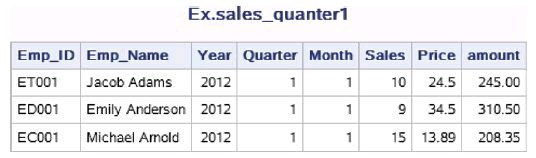
3. 使用ID语句在输出中取代观测序号列
在有些数据集中,每条观测都有自己的关键字段或标识,例如员工 ID、姓名。因此在输出中,常希望用这些标识观测的变量代替观测序号列置于输出的最左列。对于这种情况,可使用ID语句实现。ID语句的基 本语法如下:
ID 变量1 <变量2 变量3 …>;
ID语句中的变量可以有多个,当有多个变量时,这些变量将按照它们在ID语句中出现的顺序,依次置于输出的最左侧。在ex.sales_quarter1的输出中,用Emp_ID和Emp_Name代替 观测序号置于最左侧的列。
示例代码如下:
Proc print data=ex.sales_quarter1; Title 'Ex.sales_quanter1 with ID'; id emp_id emp_name; run;
4.使用VAR选择输出的变量
在默认情况下,PRINT过程会输出数据集中的所有变量。为了选择所要输出的变量以及输出变量的排列顺序,可以使用VAR语句。基本语 法如下:
VAR 变量1 <变量2 变量3 …>;
VAR语句中指明了需要输出的变量,以及在输出报表中这些变量从 左到右出现的顺序。
5.使用WHERE语句选择输出的观测
使用WHERE语句的基本语法如下:
WHERE 表达式;
WHERE语句的作用是只输出满足表达式条件的观测,表达式可以是算术表达式或逻辑表达式。如果表达式是变量和字符的比较,则字符 必须用单引号或双引号括起来,并且区分大小写。
从ex.sales_quarter1中输出Month=2的观测,并且在输出报表中依次仅包含Emp_ID、Emp_Name、Month、Sales和Amount 5个变量。
proc print data=ex.sales_quarter1 noobs; title 'Monthly Sales'; var emp_id emp_name month sales amount; where month=2; run;
6.使用数据集选项FIRSTOBS=和OBS=当指定输出特定观测序号的观测时,可以使用数据集选项 FIRSTOBS=和OBS=。这两个选项可以单独使用,也可以联合使用。语法如下:
数据集(FIRSTOBS= n1);
数据集(OBS= n2);
数据集(FIRSTOBS=n1 OBS=n2);
其中,选项FIRSTOBS=表示输出的第一条观测的序号为n1,选项OBS=表示输出的最后一条观测的序号为n2。
- ·单独使用选项FIRSTOBS=时,系统会输出序号从n1开始的所有观测。
- ·单独使用选项OBS=时,系统会输出前n2条观测。
- ·联合使用时,系统会输出序号从n1开始到n2为止(包含n2)的观 测,所以要求选项FIRSTOBS>选项OBS,否则系统会报错。
输出数据集ex.sales_quarter1中的第3~5条观测。 示例代码如下:
proc print data=ex.sales_quarter1(firstobs=3 obs=5); title 'Observation: 3 to 5'; var emp_id emp_name month sales amount; run;
1.2 制作增强型报表
在使用PRINT过程时,还可以使用SUM语句、BY语句和SUMBY语句来对变量进行分组和汇总,增加报表输出的信息。
1.使用SUM语句对变量进行求和在报表中除了可以显示数据集中的值,还可以使用SUM语句来进行 汇总和分组汇总。语法如下:
SUM 变量1 < 变量2 变量3 … >;
SUM语句中可以有多个变量,但是必须是数值型变量。
输出数据集ex.sales_quarter1中Month=2的观测,并计算2月的Sales总和及Amount总和。
proc print data=ex.sales_quarter1 noobs; title 'Monthly Sales for Total'; var emp_id emp_name month sales amount; where month=2; sum sales amount; run;
2.使用BY语句对变量进行分组汇总
输出数据集ex.sales_quarter1中属于部门TSG的员工的观测, 并按员工、按月计算Sales的和及Amount的和,最后给出所有Sales的总 和及Amount的总和(属于部门TSG的员工的Emp_ID中第二个字符是 T)。
这时就需要在使用SUM语句的同时使用BY语句了,使用BY语句 后,SUM语句的功能就是按照BY变量分组,然后计算每个BY组合中指 定变量的合计,以及所有观测的总和。和上一章中讲的一样,在使用 BY语句时,数据集必须已经按照BY变量排过序。这里,数据集 ex.sales_quarter1并没有按照Emp_ID和Month排序,需要使用SORT过程 进行排序,并将排序后的数据集写出到数据集work.sales_quarter1中。示 例代码如下:
proc sort data=ex.sales_quarter1 out=work.sales_quarter1; by Emp_ID Month; run; proc print data=work.sales_quarter1 noobs n='Sales Transactions' 'Total Sales Transactions'; title 'Emp Monthly Sales for Total'; var sales amount; where substr(emp_id,2,1)="T"; sum sales amount; by emp_id month; run;

在上面的代码中,有以下两点需要注意:
- ·在BY语句中用了Emp_ID和Month两个变量,并相应地在VAR语句 中将这两个变量去除掉了,避免报表中这两个变量重复输出。
- ·使用了选项N=来输出每个BY组合中的观测数以及整个数据集的观测数,每个BY组合中的观测数以第一段文本Sales Transactions为标签, 输出在每个BY组合的最后一行,整个数据集的观测数以第二段文本 Total Sales Transactions为标签,输出在报表的最后一行。
BY 变量1 变量2 … 变量n 变量n+1 … 变量n+k; SUMBY 变量n;
其中,SUMBY语句中的变量n必须出现在BY语句中,PRINT过程 将对每个BY组合进行汇总,这里BY组合指的是使得变量1、变量2到变 量n取值完全相同的观测的集合,而不是使得变量1、变量2、…、变量 n、…、变量n+k取值完全相同的观测的集合。以下代码只实现了汇总每个员工整个季度的Sales和Amount。
proc print data=work.sales_quarter1 noobs; title 'Emp Sales for Total'; var sales amount; where substr(emp_id,2,1)="T"; sum sales amount; by emp_id month; id emp_id month; sumby emp_id; run;
以上介绍了PRINT过程中的一些常用语句,这里总结如下:
PROC PRINT DATA=数据集 <选项>;
ID 变量1 < 变量2 …>; VAR 变量1 < 变量2 …>; WHERE 表达式; SUM 变量1 <变量2 …>; BY 变量1 <变量2 …>; SUMBY 变量1 <变量2 …>; RUN;
在PRINT过程中,各个语句的顺序可以任意改变。
1.3 改进报表显示
上面已经介绍了PRINT过程的基本用法,下面将进一步介绍如何使用其他的语句和选项使输出的报表更加具有特色。主要包括以下几个方面:
- ·添加标题和脚注
- ·规定变量格式
- ·规定变量标签
1.添加标题(TITLE)和脚注(FOOTNOTE)
在SAS所有的输出报表中,都可以添加标题和脚注。在前面章节中,已经使用TITLE语句定义了输出报表的标题。这里详细讲解TITLE语句和FOOTNOTE语句及其使用语法。它们的基本语法如下:
TITLEn ‘标题内容’;
FOOTNOTEn ‘脚注内容’;
其中:
- ·n的取值可以为1~10,TITLEn代表从上往下数第n级标题, FOOTNOTEn代表从上往下数第n级脚注,标题内容和脚注内容必须用 单引号或双引号括起来。
- ·当n默认时,表示默认定义第1级标题或脚注。当n>m时,TILLEn 为TITLEm的下级标题,脚注同理。
- ·当使用多个TITLE语句时,如果跳过某一级或某几级TITLEn没有指定,则报表中对应的这一级或几级标题显示为空行。例如,指定了 TITLE1和TITLE3,但是并没有指定TITLE2时,输出报表中第一级标题 和第三级标题中间会有一行空行。
- ·TITLE语句和FOOTNOTE语句是全局语句,可以出现在PRINT过 程前面或PRINT过程的程序中间,标题和脚注一经指定,在以后输出的 所有报表中都将被使用,直到被取消。
- ·TITLEn语句的作用为指定新的标题内容和取消下级标题,FOOTNOTEn语句的作用为指定新的脚注内容和取消下级脚注。
输出数据集ex.sales_quarter1的Month=2观测,在报表中汇总2月的Sales和Amount,并为报表添加标题和脚注。
示例代码如下:
proc print data=ex.sales_quarter1 noobs; title1 'Asia Pacific Acrea';
title3 'Monthly Sales Report';
footnote1 'February Sales Total';
footnote2 'COMPANY CONFIDENTIAL'; var emp_id emp_name month sales amount; where month=2; sum sales amount; run;
从输出结果中可以看出两行标题中间有一空行,并且在报表下方输出了两行脚注。 取消标题或脚注的语法如下:
TITLEn;
FOOTNOTEn;
其中:
- ·“TITLEn;”表示取消所有第m级标题,其中m>=n。“FOOTNOTEn;”表示取消所有第m级脚注,其中m>=n。
- ·“TITLE;”表示取消所有标题;“FOOTNOTE;”表示取消所有脚注。
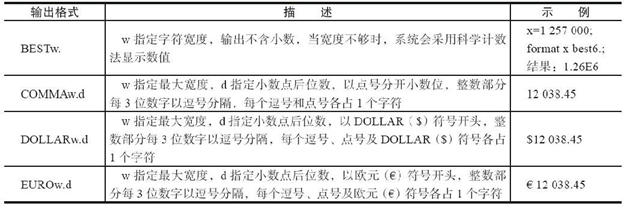
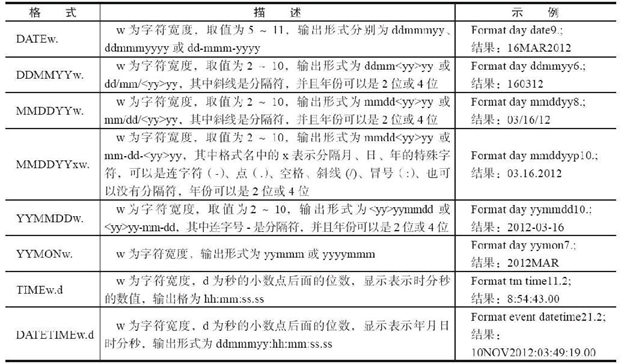
2.使用FORMAT语句规定输出格式
为了增加报表的可读性,可以在PRINT过程中加入FORMAT语句, 这可使变量在输出时采用指定的输出格式。其语法如下:
FORMAT<量1 变量2 变量3 …> 输出格式1 <变量4 <变量5 …>输出格式2 …> ;
其中,输出格式可以是SAS系统提供的输出格式,也可以是用户自定义的输出格式。需要注意的是,在PROC步中使用FORMAT语句并不会影响数据集中存储的数据,该输出格式仅对显示在报表中的变量起作用。
3.使用LABEL语句规定输出变量的标签
默认情况下,在PRINT过程的输出中,系统会使用数据集中的变量名作为报表的表头,有时为了使得报表更为用户化,可以使用变量的标签来代替变量名。变量的标签可以在创建数据集时定义。如果数据集的 变量已经设定了标签,那么只要在PROC步中加上选项LABEL,系统就 会自动采用变量的标签代替变量名。
如果数据集中的变量没有定义标签,或者在报表中需要使用不同于 数据集中已有标签的形式,则可以在PRINT过程中使用LABEL语句,定 义新的标签。这时再使用选项LABEL就可以在报表中显示新定义的标 签了。
LABEL语句的使用语法如下:
LABLE 变量1=’标签文本’ 变量2=’标签2’ …;
标签文本必须使用单引号或双引号括起来,长度不得超过256个字 符,包括空格在内。
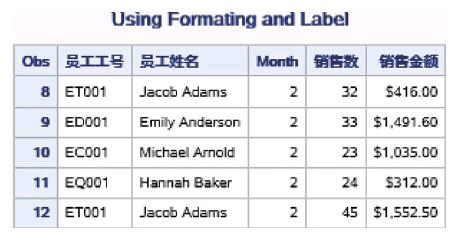
为Emp_ID、Emp_Name、Sales和Amount定义标签。 示例代码如下:
proc print data=ex.sales_quarter1 label; title 'Using Formating and Label'; var emp_id emp_name month sales amount; where month=2; format amount dollar14.2; label emp_id='员工工号' emp_name='员工姓名' Sales='销售数' Amount='销售金额'; run;
(1)分行显示标签 有时标签可能过长,系统会自动根据列宽将标签分成几行显示,但是系统分隔标签时不会考虑具体含义,为了控制标签的分行,可以使用 选项SPLIT=。使用选项SPLIT=时,需要进行以下两个操作。
·在PROC PRINT语句中使用选项SPLIT=指明分隔符,使用选项SPLIT=的基本语法如下:
SPLIT='分隔符'
·在LABEL语句中定义含有分隔符的标签。 分隔符可以是字母、数字或特殊符号中的任何一种,且只占一个字符,同时必须使用单引号或双引号括起来。在使用选项SPLIT=时,不需要使用选项LABLE,因为选项SPLIT=已经隐含了PRINT过程将使用 标签。
(2)在报表中添加空行
在PROC PRINT语句中还可以使用选项BLANKLINE=在报表中添加 空行。使用方法如下:BLANKLINE=n;
在输出报表中,每输出n行数据后输出一行空行。
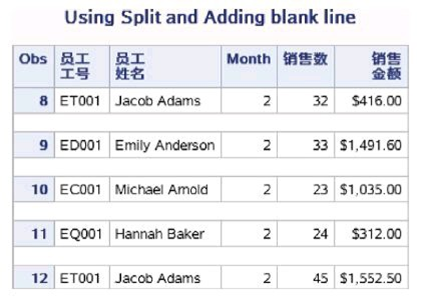
在PROC PRINT语句中定义斜杠(/)为分隔符,并在LABEL语句中将分隔符加入标签定义中,同时使得报表的每行数据后 有一个空行。
示例代码如下:
proc print data=ex.sales_quarter1 split='/' blankline=1; title 'Using Split and Adding blank line'; var emp_id emp_name month sales amount; where month=2; format amount dollar14.2; label emp_id='员工/工号' emp_name='员工/姓名' Sales='销售数' Amount='销售/金额'; run;