

SAS对数据变量的处理
SAS对数据变量的处理
在使用DATA步基于已经存在的数据集生成新数据集时,可以指定在新数据集中不需要包含的变量而仅读取其他变量,或者指定仅需要在 新数据集中包含的变量。该功能可以通过DATA步中的SET语句和数据集选项KEEP=和DROP=来实现,也可以通过KEEP和DROP语句来实现。
1.使用数据集选项KEEP=和DROP=
使用数据集选项KEEP=和DROP=的基本形式如下:
DATA 新数据集; SET 原数据集 (KEEP|DROP=变量列表); RUN;
读取数据集sashelp.shoes中与产品销售相关的变量Product、Stores和Sales,建立新数据集。代码如下:
data work.shoes_part1; set sashelp.shoes (keep=Product Stores Sales); run; proc print data=work.shoes_part1 (obs=5) noobs; run;
在上面的代码中,SET语句使用数据集选项KEEP=指定的Product、 Stores和Sales。PROC PRINT打印所生成的数据集work.shoes_part1的前5 条观测,如下图所示。可以看到,该数据集中包含了变量Product、 Stores和Sales。
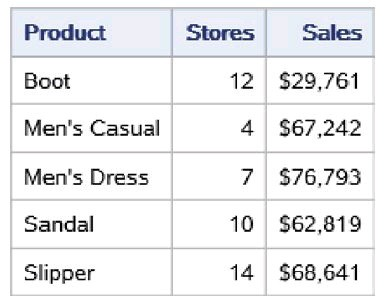
下面使用数据集选项DROP=来实现相同的功能,代码如下:
data work.shoes_part2; set sashelp.shoes (drop=Region Subsidiary Inventory Returns); run;
因为sashelp.shoes的变量包含Product、Stores、Sales、Region、Subsidiary、Inventory和Returns,所以当选项DROP=中指定了Region、 Subsidiary、Inventory和Returns时,剩下的变量Product、Stores和Sales都 会被读取并写入数据集work.shoes_part2。所生成的数据集 work.shoes_part2和前面示例中生成的work.shoes_part1相同。
简单来说,选择使用选项KEEP=还是DROP=依赖于哪种方法会需 要指定较少的变量。但相比较而言,使用选项KEEP=会明确指明需要读 取的变量,这样在比较大的作业中可以避免读取预期之外的变量。
2.使用KEEP和DROP语句
在DATA步中,KEEP和DROP语句同样可用于选取写入到新数据集 中的变量。使用DROP和KEEP语句的基本形式如下:
DATA 新数据集; SET 原数据集; KEEP|DROP变量列表; RUN;
在该过程中,DATA步会读取原数据集的所有变量,但在写入新数据集前只保留部分变量。新数据集中包含的变量由所使用的语句(KEEP语句或DROP语句)给出的变量列表确定。使用KEEP语句表示 只选取变量列表中变量,而使用DROP语句则表示选取除变量列表之外的其他所有变量。
读取数据集sashelp.shoes中跟产品销售相关的变量Product、Stores和Sales,建立新数据集。
下面两段代码分别使用KEEP语句和DROP语句来完成上述功能,生成数据集work.shoes_part3和work.shoes_part4。
代码1:
data work.shoes_part3; set sashelp.shoes; keep Product Stores Sales; run;
代码2:
data work.shoes_part4; set sashelp.shoes; drop Region Subsidiary Inventory Returns; run;
在代码1中,DATA步会读取数据集sashelp.shoes中的所有变量,并 选取KEEP语句指定的Product、Stores和Sales创建新数据集 work.shoes_part3。在代码2中,DATA步的DROP语句指定了Region、 Subsidiary、Inventory和Returns,那么剩下的变量Product、Stores、Sales 会被选取写入数据集work.shoes_part4。这里所生成的数据集 work.shoes_part3和work.shoes_part4也和work.shoes_part1相同。
使用KEEP语句还是DROP语句,与选择使用数据集选项KEEP=还是DROP=的标准一样。从上面的示例中可以看出,它们都可以实现相 同的功能。
开发程序时具体该怎样选择
(读取速度快、效率高、不能对未保留得字段进行处理): 1.使用数据集选项KEEP=和DROP=
(读取速度慢、效率差、可以多个数据集,可以对未保留得字段进行处理):2.使用KEEP和DROP语句
3.一个DATA步中创建多个数据集
数据集选项KEEP=和DROP=除了可以在SET语句中使用之外,还可以用于DATA语句中指定的数据集。这样就可以在一个DATA步中通过 给每个数据集使用选项KEEP=和DROP=来创建包含不同变量的多个数 据集。而KEEP和DROP语句却实现不了该功能,因为它们会影响所有的 输出数据集。
分别读取数据集sashelp.shoes中关于产品销售情况的变量
(Product、Stores及Sales)和产品库存情况的变量(Product、Inventory 及Returns),并将这两类变量写入两个数据集work.shoes_sales和 work.shoes_inventory。
代码如下:
data work.shoes_sales (keep=Product Stores Sales) work.shoes_inventory (keep=Product Inventory Returns); set sashelp.shoes; run; proc print data=work.shoes_sales (obs=5) noobs; title "Product Sales"; run; proc print data=work.shoes_inventory (obs=5) noobs; title "Product Inventory"; run;
两个PRINT过程打印的数据集work.shoes_sales和 work.shoes_inventory中的前5条数据分别如下图左和下图右所示。它们分别 包含变量Product、Stores、Sales和Product、Inventory、Returns。
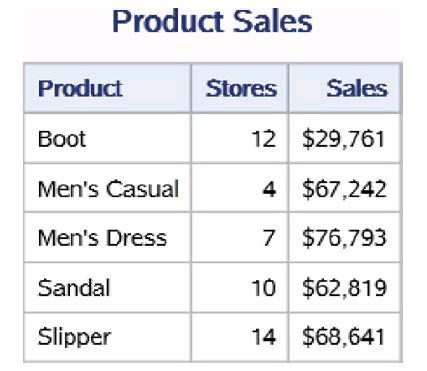
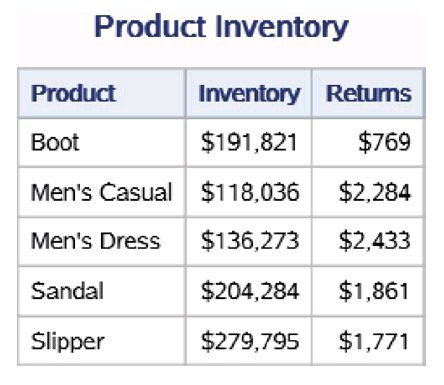
4.有效地使用数据集选项KEEP=和DROP=
在DATA步中,可在DATA语句和SET语句中使用数据集选项 KEEP=和DROP=。在DATA语句使用这些选项,PDV中会包括输入数据 集中的所有变量,不过,只有当变量从PDV中写入结果数据集时,这些 选项才会产生影响。然而,在SET语句中使用这些选项时,这些选项会 确定哪些变量要从输入数据集中读取到PDV中,也就是说,SAS不会将 未包括的变量读入PDV。在数据集很大时,这种方式会使程序执行更有效率。
在上面代码的基础上可在SET语句中增加选项DROP=来控制变量Region和Subsidiary不被读入PDV,以提高程序执行效率。如下:
data work.shoes_sales (keep=Product Stores Sales) work.shoes_inventory (keep=Product Inventory Returns); set sashelp.shoes (drop=Region Subsidiary); run;
有时候,部分变量虽然不需要输出到新数据集,但在进行运算处理 时却需要用到,这时候这些变量必须被读入PDV中,那么此时就不适合 在SET语句中使用数据集选项KEEP=和DROP=了。对于这种情况,可在 DATA语句中使用数据集选项KEEP=、DROP=,或使用KEEP、DROP 语句来实现。
小结:
重点掌握关键字:set、keep、drop
1、set 表示需要建立数据集的初始数据集
2、keep、drop表示需要保留以及删除的字段名;可以用于data 后面的数据集的命名,set初始化数据集;以及data步单独使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号