等待界面元素出现
在进行网页操作的时候,有的元素内容不是可以理解出现的,可能会等待一段时间,比如
百度搜索一个词语,点击搜索后,浏览器需要把这个搜索请求发送给百度服务器,百度服务
器处理后,再把搜索结果返回
所以,从点击搜索到得到结果,需要一定的时间
只是通常百度服务器的处理比较快,感觉是立即出现了搜索结果。
百度搜索的每个结果对应界面元素其ID分别是数字1,2,3,4.....
如下:
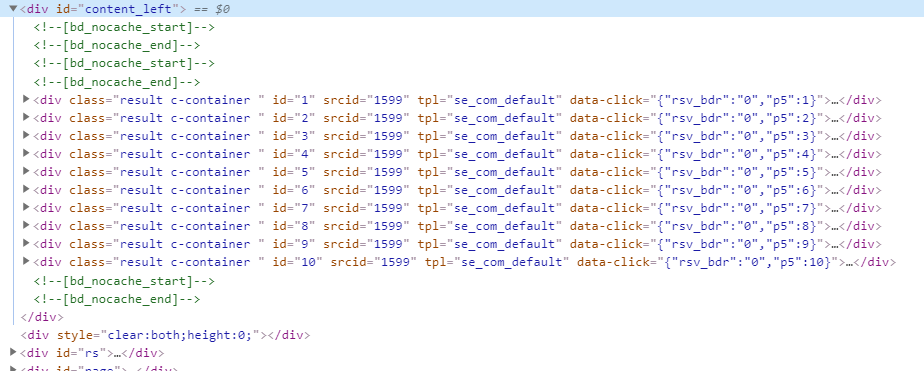
过快请求实例:
from selenium import webdriver # 导包
import time
# 实例化浏览器 如果为空就是是用的项目根目录的Chrome驱动
borwser = webdriver.Chrome()
# 请求网址
borwser.get('https://www.baidu.com')
ele = borwser.find_element_by_id('kw')
ele.send_keys('老祝头博客园')
cl = borwser.find_element_by_id('su').click()
eles = borwser.find_element_by_id('1')
print(eles.text)
运行会抛出如下异常:

在短暂的瞬间,网页上是没有id为1的元素的(因为还没搜索到结果)自然会报错id为1的元素不存在
如果用 sleep等待几秒钟,等百度服务返回结果后再去选择元素,那样会浪费大量时间
Selenium提供了一个更合理的解决方案:
当发现元素没有找到的时候,并不立即返回找不到元素的错误。
而是周期性(每隔半秒)重新查找该元素,直到找到该元素
或者超出指定最大等待时间,才抛出异常,(若是find_elements 方法,则返回空列表)
Selenium 的 Webdrive 对象有一个方法: implictly_wait(隐式等待)
该方法接收一个参数用来指定最大等待时间。
实例代码:
borwser.implicitly_wait(10)
后续的 find_element 等方法的调用都会采用上面的策略;
此方法会偷偷的设置等待时间 每隔半秒再找元素 最大上限为10秒
实例代码:
from selenium import webdriver # 导包
# 实例化浏览器 如果为空就是是用的项目根目录的Chrome驱动
borwser = webdriver.Chrome()
# 请求网址
borwser.get('https://www.baidu.com')
# 隐式等待 每隔半秒请求
borwser.implicitly_wait(10)
ele = borwser.find_element_by_id('kw')
ele.send_keys('老祝头博客园')
cl = borwser.find_element_by_id('su').click()
eles = borwser.find_element_by_id('1')
print(eles.text)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号