b0124 数据领域知识点复习(一)
hdfs原理
namenode
datanode
secondnamenode 日志与元数据整合,故障恢复。
Fe 联邦, namenode 并发提供服务。
fsimage
edits
Checkpoint
HDFS工作原理,Hub-Link,2021-10-29 | 2022-09-22 ,比较详细
HDFS的原理详解,爱若手握流沙,2018-10-24 | 2022-09-12 ,简洁通俗
大数据入门:Hadoop HDFS存储原理, 2020-11-24 17:28 | r 2022-09-12
yarn原理
resourcemansger
nodemanager
container
application master
client
YARN架构设计和原理,水墨之白, 2019-05-27
Yarn工作原理,小五家的二哈, 2020-09-15
mapreduce原理
数据block(input), split, recordreader, mapper, combiner(可选) , partiioner , sorter , split, merge, shuffle, reucer , output
MapReduce原理剖析,简单随风, 2021-07-16
MapReduce基本原理(详解!),<一蓑烟雨任平生>,2020-06-21
MapReduce原理,小传风,2020-02-11
spark原理
b0104 大数据集群-2021伪分布式-环境搭建 - sunzebo - 博客园 (cnblogs.com)
Spark 学习: spark 原理简述,凯菜 2018-03-28
flink原理
hive优化
• 底层执行引擎选择 mapreduce、tez、spark
• 选择表存储格式 orcfile、parquet 等列存储
• 用好压缩, mapreduce过程中,减少IO负荷, 对CPU影响不大
• 列裁剪和分区裁剪, 只选择需要的列和需要的分区
• 谓词下推, 尽早执行where数据过滤操作
map join,让小表一次全部读入内存
大表放在最右边,前面的表关联处理完后,streamin 读取大表
将复杂的数据处理任务拆分
建表分区、分桶,选择合适的列优化
• group by 代替count distinct
• group by 配置调整, map预聚合,执行一个combiner 减少数据量; 倾斜均衡 skevindata 设为true
• join优化, 小表前置会读入内存、 多表join是key相同只有一个MR、 大小表map端join无reduce
• 不需要空值、无意义值提前过滤、单独处理倾斜key、确保join数据类型一致
• 调整mapper数,少量大文件,减少mapper数;大量非小文件,增大mapper数; 大量小文件,先合并小文件
• 调整合适reducers数
• java 虚拟机重用,默认一个task启动关闭一次, 设置重用参数,比如改成5,5个task重复使用一个jvm
• 用好并行执行和本地模式, 多个union all 打开 设置并行执行参数true, 数据量小的本地模型不提交到集群
• 用好 严格模式,避免有风险的查询,分区表查询没有指定分区列、笛卡尔积join、order by 无limit
• 处理好小文件
• left semi join 代替 in/exists
• 使用推测执行
hbase原理
Hmaster, HRegionServer, zookeeper
HMaster 1:N1 HRegionServer 1:N2 HRegion 1:N3 Store 1:N4 StoreFile
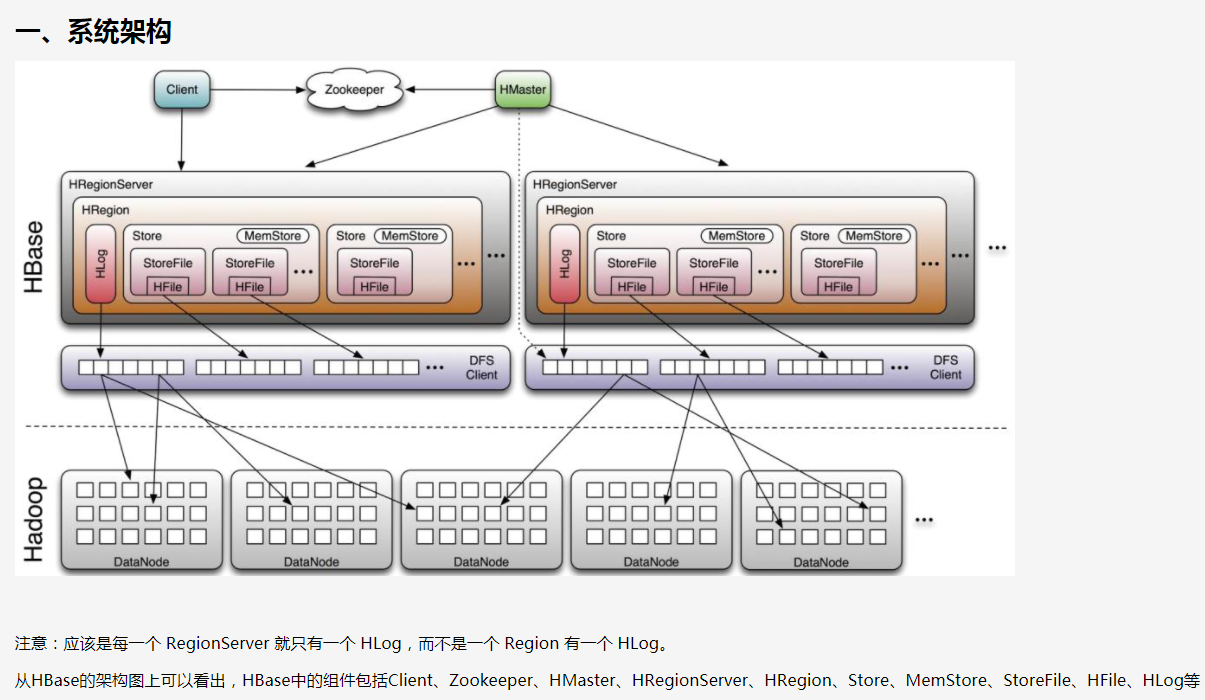
一个HRegion只属于一个表,当表增大时,从行切分多个HRegion
一个列簇一个Store

 浙公网安备 33010602011771号
浙公网安备 33010602011771号