b0105 大数据集群-2021分布式A(手动3节点)-环境搭建
环境
win7 安装vmware12,虚拟机装 centos7.9
3 台机器. 每台机器4G内存,20G硬盘
集群名字: 2021分布式A
集群规划
| 描述 | hc2109 | hc2110 | hc2111 | hc2107(客户端) |
| ip | 192.168.25.109 | 192.168.25.110 | 192.168.25.111 | |
| HDFS |
NameNode DataNode |
Second NameNode DataNode |
DataNode | |
|
Yarn |
ResourceManager NodeManager |
NodeManager | NodeManager | |
|
Hive |
Hive服务器 | Hive客户端(Beeline) | ||
|
zookeeper |
✔ | ✔ | ✔ | |
|
hbase |
✔ | ✔ | ✔ | |
|
kafka |
✔ | ✔ | ✔ | |
|
spark(standlone) |
worker | worker |
master worker |
|
|
storm |
Supervisor |
Nimbus HA Supervisor |
Nimbus Supervisor |
|
|
flink(standalone) |
taskmanager |
taskmanager |
jobmanasger
|
|
|
flume |
✔ |
✔ |
✔ |
|
|
sqoop |
✔ |
已有
- 已经创建hadoop账号,添加了sudo 权限
- 已经安装jdk1.8
- 配置了 主机名 和静态ip地址
- 关闭防火墙
- 集群机器上的时间直接设置为北京时间,没有使用其他工具
计划
计划把这台机器当作分布式机器,安装大数据开源生态常见组件,具体如下
- hadoop 3.3.1 (最新版本)
- spark
- hive
- zookeeper
- hbase
说明
- 默认操作都用hadoop账户进行, 需要特别权限的地方,会在前面加sudo,在文中会补充描述。 需要root账户单独操作的,也会特别说明
- 所有的组件都安装在 /opt 目录下
- 环境搭建下组件的配置, 只满足能够跑起来来就行,并不考虑其他。后续修改体现在 "b0108 大数据集群-2021分布式A-运维“, 根据具体使用情况调整配置参数
- 分布式集群组件的安装一般紧跟在伪分布式后, 可以参考 b0104 大数据集群-2021伪分布式-环境搭建
- 分布式集群组件的安装思路,先在一台机器上弄好,再scp复制到其他机器上, 最后个性化修改
- 很多组件的文档前都加上 前置 , 表示之前做了什么工作
10. Sqoop 1.4.7 20210808
计划
由于sqoop 本质上是一个编译转换器, 将生成的mapreduce程序提交到hadoop集群, 是一个客户端。 只需装在客户机上。
单节点就行了。 这里是hc2107
前置
- jdk 1.8 (必需)
- hadoop 服务器已经安装 (必须)
- 客户机上 hadoop 解压包,并配置指定hadoop服务器参数 (sqoop客户机上安装 必须)
- 客户机上hive 安装好, 通过服务器元数据9083端口服务可以获取元数据正常使用, 如果sqoop客户机上安装,并使用数据库<-->hive,是必须的。
- 一个关系型数据库,比如mariadb (必须)
安装配置
参考 b0104/sqoop
将 hc2108 安装的包,并且配置好了的参数,全部复制到hc2107上,
其他都一样
启动和检验
执行b0104/sqoop 中的测试例子
首先启动hadoop集群。
执行例子。
这里报了一个异常, 参考 b0108/HIVE/Q2, 简单的说,是之前客户机上的hive没有安装测试完全,没有配置 元数据服务器地址和端口
解决这个问题一切都正常。
总结
- sqoop可以不用安装在hadoop集群上
- 它本质就是一个编译器,并且将编译输出的代码以客户程序的形式提交到集群运行
- sqoop本身没必要存在分布式的概念
- 猜测,也不存在 客户机/服务器模式
9. Flume 1.9.0 20210808
计划
在集群所有3台机器上安装。
注意一点, Flume与大多数分布式集群组件不一样, 各个节点其实是独立的,只不过有数据上的上下游依赖关系。
前置
- 安装jdk1.8 (必须)
安装配置
flume 基本解压到集群上,配置环境变量。 实际参数在使用中配置
参考 b0104/flume, 先在hc2109一台机器上, 最终分发到其他机器。
# hc2109, flume 集群分发 scp -r /opt/apache-flume-1.9.0-bin hadoop@hc2110:/opt scp -r /opt/apache-flume-1.9.0-bin hadoop@hc2111:/opt
启动和检验
单机的参考 b0104/flume, 集群待做todo
参考
- disk 20210807_大数据_伪分布式_flume安装.txt
- b0104/flume 单机,里面有使用案例
后续
- 测试 多个Flume的agent 配合实现一个任务
- 测试 不同类型的源和目标
资料
soure

Sink
Sink:支持的数据类型:HDFS Sink,Logger Sink, Kafka Sink,Avro Sink, Thrift, IPC, File Roll 等。
Sink在设置存储数据时,可以向文件系统、数据库、hadoop存数据
channel
channel: 有MemoryChannel, JDBC Channel, File Channel, Kafka Channel.
Flume用到的技术(个人提炼)
网络通信: socket, RPC,AVRO,Thrift
存储: 内存队列,各种类型的外部存储
并发: 集群不同进程之间、 多线程
8. Flink 1.13.2 20210807
计划
flink 的集群模式类似spark, 支持standlone独立模式,yarn,meos 等模式。
这里选择standlone模式, 尽量支持yarn模式。
主节点借助 zookeeer支持HA, 这里没有选择这个 ,把主节点选定为 hc2111
从节点 选定为 hc2109,hc2110.
前置
- 安装jdk (必须)
- 已经在单机hc2108 安装过flink, 记录在文档 b0104中
安装配置
参考 b0104/flink 中的相关。
先选定hc2109, 解压到安装目录
flink-conf.yaml
设置以下参数
# jobmanager节点的机器, 和HA(+zookeeper)的单独文件masters 二选一。 jobmanager.rpc.address: hc2111 # 设置主节点 进程的内存 jobmanager.memory.process.size: 800m # 从节点进程内存 taskmanager.memory.flink.size: 800m # 并发数量,依照CPU设置 taskmanager.numberOfTaskSlots: 2 parallelism.default: 2
该文件的参数还支持以下类型
- 支持主节点HA, 指定zookeeper服务器,和 存储地址, 用来恢复
- Fault tolerance and checkpointing , 对程序执行 中间状态存储,指定存储位置,和恢复类型
- 对外rest 接口
- 集群安全方面的配置
- 历史服务,存储历史任务信息的 机器和进程
workers
hc2109
hc2110
注意, masters用不到,除非结合zookeeper配置主节点的HA
安装包集群分发
scp -r /opt/flink-1.13.2 hadoop@hc2110:/opt scp -r /opt/flink-1.13.2 hadoop@hc2111:/opt
/etc/profile
### flink export FLINK_HOME=/opt/flink-1.13.2 export PATH=$PATH:${FLINK_HOME}/bin
执行source生效
启动和检验
1 启动flink
在主节点hc2111 上执行
start-cluster.sh
整个集群进程都启动了
http://hc2111:8081
web 页面如下
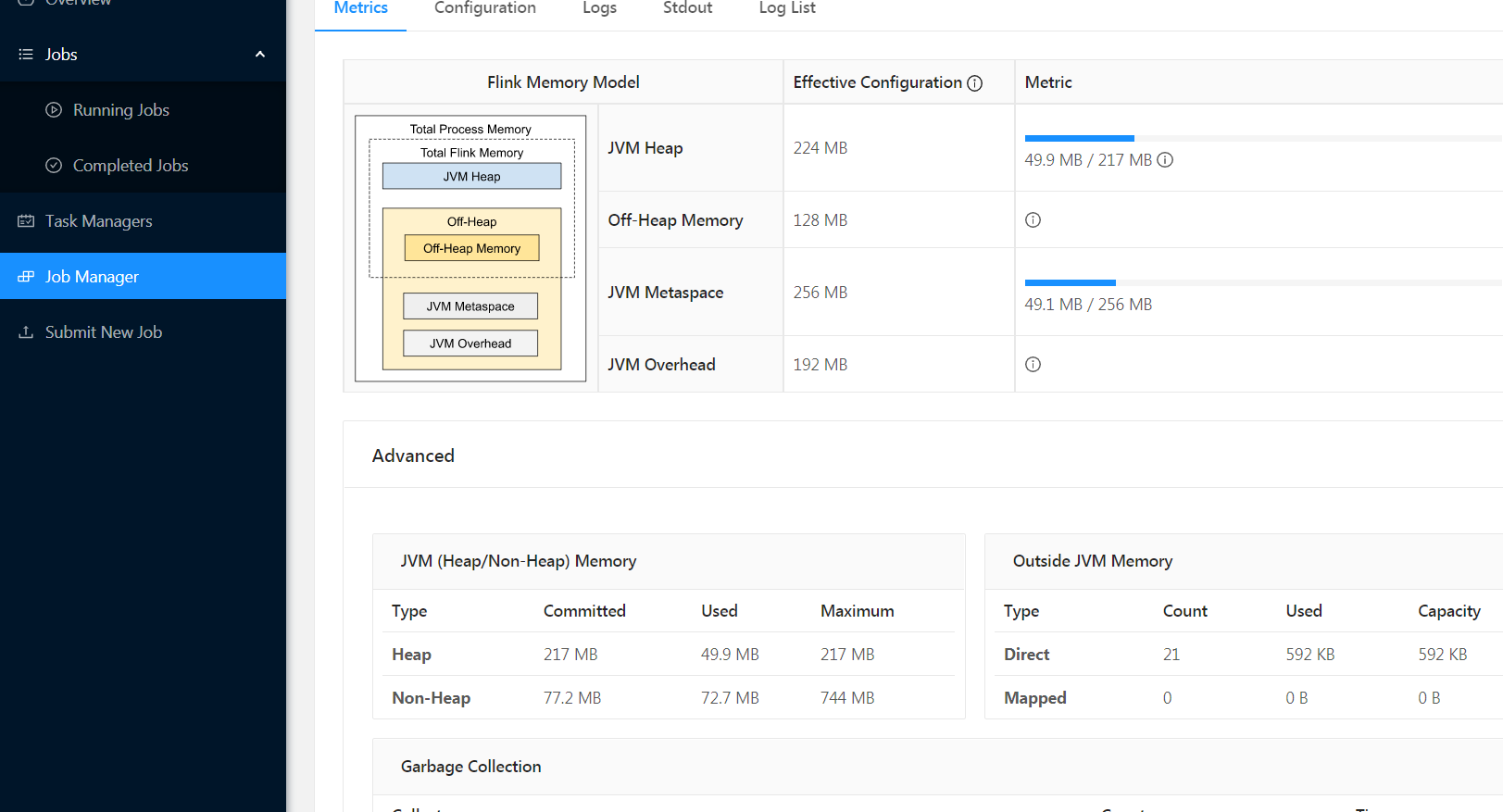

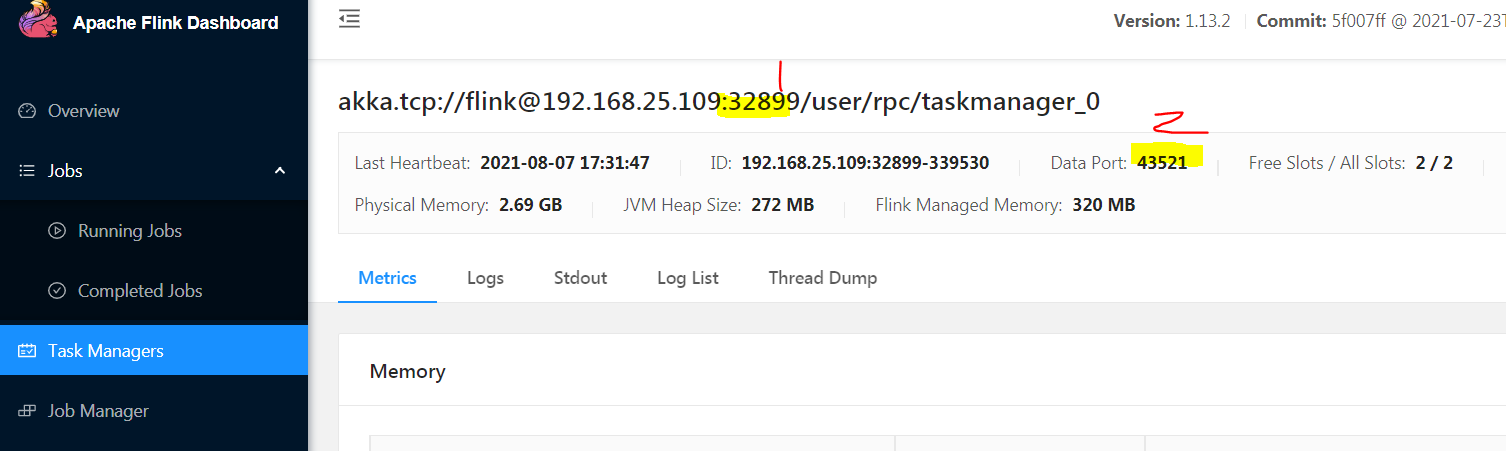

从上可以看出, 一个从节点上的TaskManager会使用多个 端口,与外界通信和数据传输。
2 批处理wordcount
执行批处理 wordcount 的例子,如下命令
flink run $FLINK_HOME/examples/batch/WordCount.jar
对比 b0104中记录的,
此时程序有2个并发, 集群上2个机器,每个机器2个slot
注意一下并发, task,subtasks等概念的实际体现

3 流wordcount
思路
- 在某台机器 运行一个本文输入命令行程序,作为服务器端,监听端口,等待客户机连接
- 运行一个flink 统计单词的流程序,作为客户端连接刚才的服务器程序。
- 然后在服务器端 命令行下输入字句, 就会被flink接收,并在集群上运算,统计单词数量,最终输出到某台机器上的本地默认输出文件中
# hc2110 上执行,启动服务器程序,监听端口9000 nc -l 9000 # hc2111 执行,启动流程序,作为客户端连接 刚才的服务器程序 flink run $FLINK_HOME/examples/streaming/SocketWindowWordCount.jar --hostname hc2110 --port 9000 # 从 flink web页面获取 流程序最后的输出在机器 hc2110上, 打开一个查看程序可以实时看到结果 tail -f flink-hadoop-taskexecutor-0-hc2110.out
在一端输入消息数据,在另外一端实时输出来了
相关截图如下
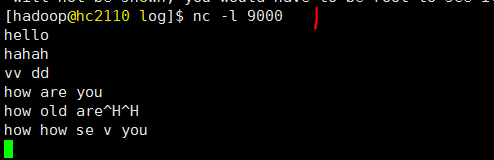


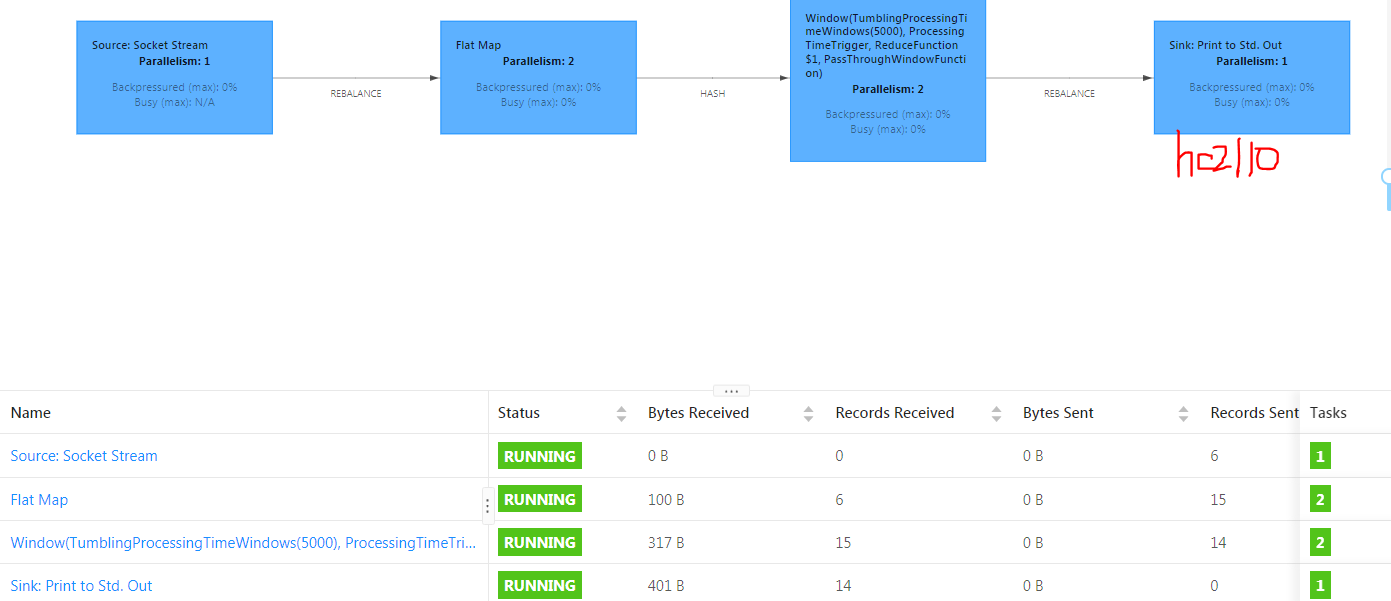
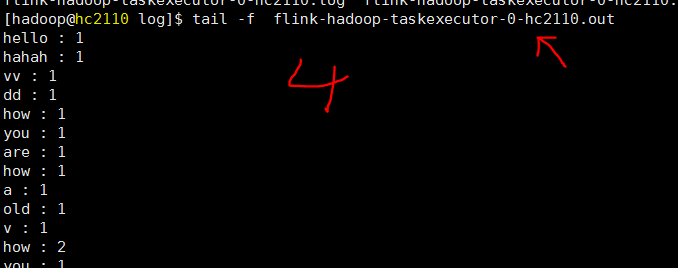
参考
- disk 20210807_大数据_分布式_flink安装.txt
- disk 20210807_大数据_伪分布式_flink安装.txt
- b0104/flink
- ref1 "Flink完全分布式集群安装,Snail,2020/04/16"
后续
- 测试程序 flink on yarn, 和从hdfs 读取数据
7.Storm 2.2 20210805
计划
机群上3台机器, hc2111作为主节点nimbus程序,hc2110作为备选节点,实现HA
3台机器都 运行干活监控进程 Supervisor
前置
- 安装zookeeper (必须)
- 安装jdk (必须)
- 伪分布式hc2108已经安装了,记录在文档b0104中。 本文将以此为基准 增加变化部分
安装配置
参考 b0104中storm部分,大部分都一样。
集群操作,先在一台机器hc2109上操作。
storm.yaml
文件内容如下
#所使用的zookeeper集群主机 storm.zookeeper.servers: - "hc2109" - "hc2110" - "hc2111" #nimbus所在的主机候选列表,实际会从中选一个 nimbus.seeds: ["hc2110","hc2111"] # 指定ui端口,以免8080被其他程序占用 ui.port: 8081
安装包集群分发
scp -r /opt/apache-storm-2.2.0 hadoop@hc2110:/opt scp -r /opt/apache-storm-2.2.0 hadoop@hc2111:/opt
启动和检验
1. 先启动 zookeepr
3台机器都执行, zkServer.sh start
2. 启动nimbus和ui
在hc2111中执行程序
nohup storm nimbus & 开启nimbus
nohup storm ui & 开启ui界面,通过web服务
3 启动supervisor
在3台机器上都启动
nohup storm supervisor &
http://hc2111:8081

参考
- disk 20210806_大数据_分布式_storm安装.txt
- disk 20210805_大数据_伪分布式_storm安装.txt
- b0104 storm
注意点
- storm 集群配置文件 并没有指定哪些机器是从节点, hadoop,spark就指定了,storm的从节点 在所在机器启动进程就是了
- storm nimbus, supervisor 进程 kill 掉没关系, 因为关键信息都存储在zookeeper了,不会影响
6. Spark 3.1.2 20210805
计划
在集群3台机器上安装spark standlone模式, 同时把支持yarn 模式配置加进去。
hc2111 安装master, 所有机器都装worker
前置
- 已经安装jdk, 这里是1.8 (必须)
- 安装hadoop
- 伪分布式hc2108已经安装了,记录在文档b0104中。 本文将以此为基准 增加变化部分
安装配置
集群3台机器, 先选定hc2109操作, 按照 b0104 文档中 ,伪分布式hc2108安装spark过程执行前面大部分操作.。
下面只记录不一样的地方
spark-env.sh
export SPARK_MASTER_HOST=hc2111
workers
hc2109
hc2110
hc2111
安装包集群分发
# spark hc2109 -> hc2110 scp -r /opt/spark-3.1.2-bin-hadoop3.2 hadoop@hc2110:/opt scp -r /opt/spark-3.1.2-bin-hadoop3.2 hadoop@hc2111:/opt
/etc/profile
3台机器上的spark环境变量都添加,并执行source 生效
启动和检验
服务器启动
参考 hc2108 伪分布式 spark 启动。
注意点,
- start-master.sh 只能在master节点hc2111上启动, 其他机器启动会不成功
- start-workers.sh 可以选取任意一台机器启动
- 这里没有用hadoop,只是单独启动spark测试
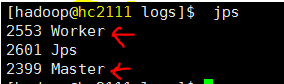
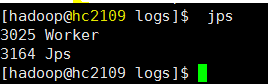

客户端连接
把hc2108当作客户端 连接 spark 集群 master节点 hc2111,如下。 注意 4040端口是在客户机 hc2108
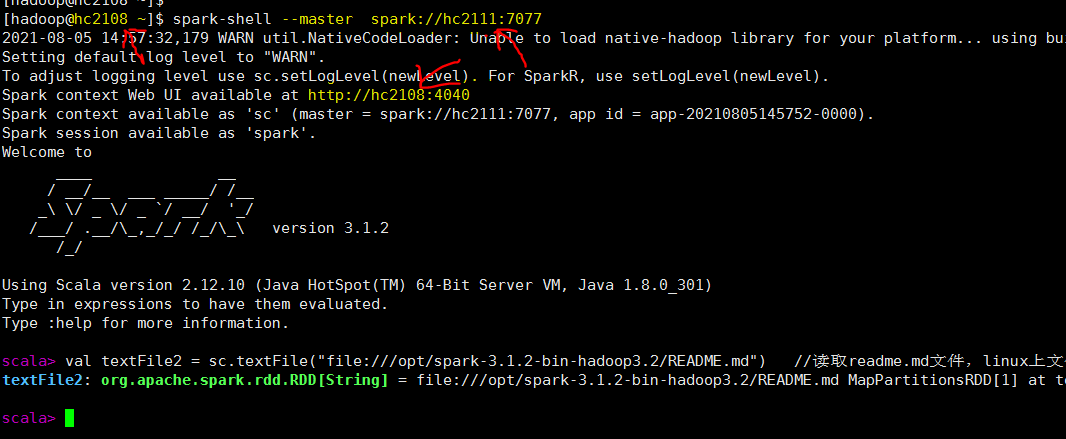
注意: 如果集群内存不够, 可能会出现情况 b0108/spark/Q1 无法分配足够资源给应用程序,导致程序一直等待
可以 spark-env.sh 调整 driver,execuer 占用的资源比如内存数量, 也可以在应用程序提交时指定,如下
# driver 默认1G,executor 默认1G, 2个参数至少 500m左右
spark-shell --master spark://hc2111:7077 --driver-memory 500m --executor-memory 500m
web页面监控情况


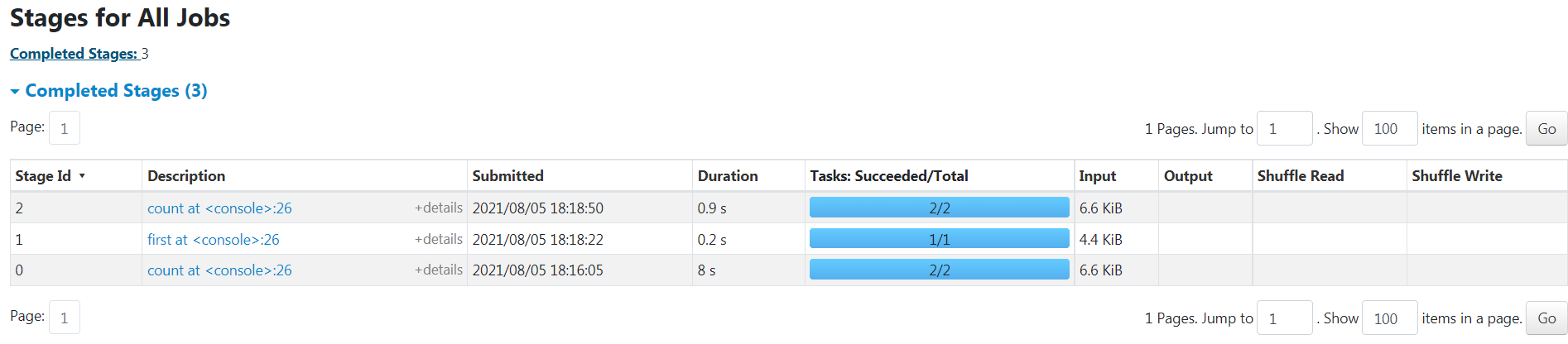
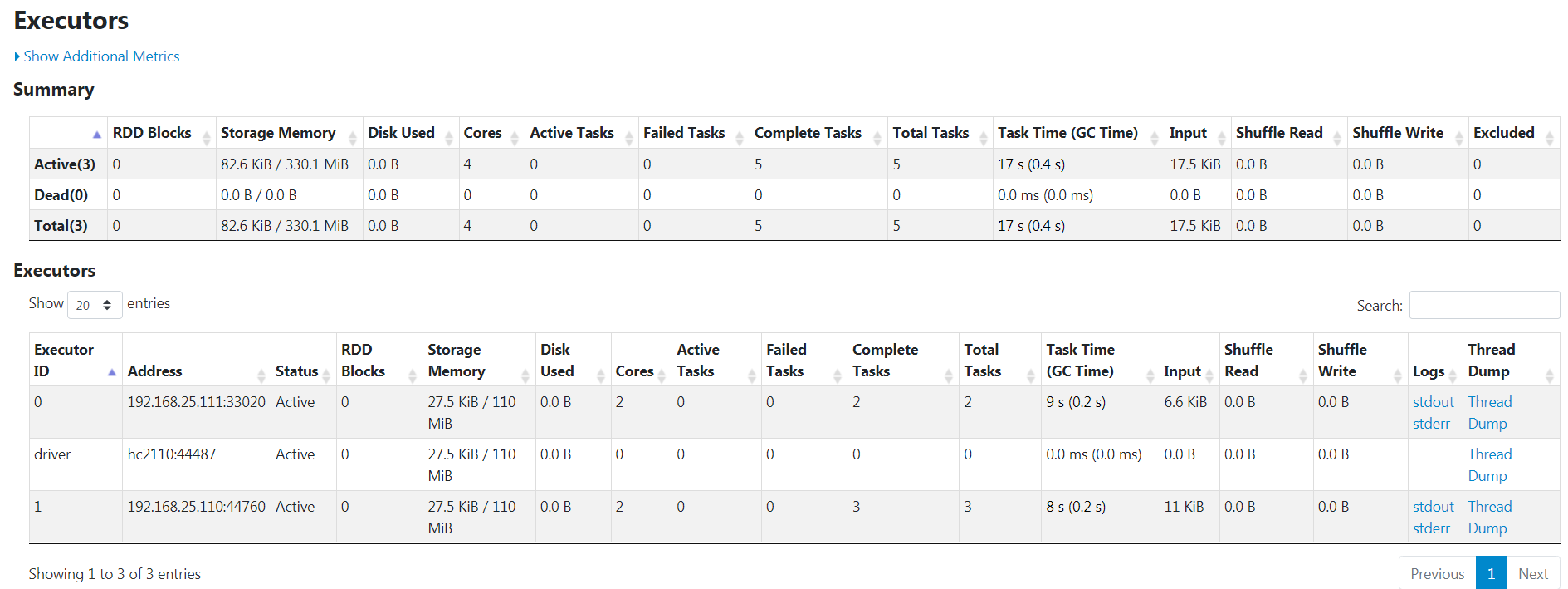
参考
- disk 20210805_大数据_分布式_spark安装.txt
- disk 20210805_大数据_伪分布式_spark安装.txt
- b0104/spark 在单机上standlone安装
- ref1 "我的 Spark 3.1.1 之旅, 黄赟, 2021/04/19"
其他
后续可做
- 测试 spark on yarn的程序,熟悉
注意点
- 4040 web 应用程序查看页面在 提交程序的客户机上,而不是master节点上
5. kafka 2.8 20210803
计划
kafka 集群所有节点都是平等的。 在集群3台机器上都安装
前置
- 已经安装jdk, 这里是1.8 (必须)
- 已经安装zookeeper (必须)
- 伪分布式hc2108已经安装了,记录在文档b0104中。 本文将以此为基准 增加变化部分
安装配置
集群3台机器, 先选定hc2109, 按照 b0104 文档中 ,伪分布式hc2108安装kafka过程执行前面大部分操作.。
下面只记录不一样的地方
server.properties
修改或添加这些参数值
# broker(集群中每个机器的叫法)的id或者编号,在集群中该编号必须唯一 broker.id=1 # 服务器监听端口 listeners=PLAINTEXT://hc2109:9092 # 消息的副本数量,这是kafka高可用、数据不丢失的关键 default.replication.factor=2 # topic创建时默认分区的数量 num.partitions=2 # 消息的存放目录,这里看配置是日志的意思,因为kafka把消息使用日志的形式存储,所以这里不要和kafka的运行日志相混淆 log.dirs=/opt/kafka_2.13-2.8.0/data # zookeeper服务器集群地址 zookeeper.connect=hc2109:2181,hc2110:2181,hc2111:2181
集群分发
# 复制解压包到其他机器上,hc2109上执行 scp -r /opt/kafka_2.13-2.8.0 hadoop@hc2110:/opt scp -r /opt/kafka_2.13-2.8.0 hadoop@hc2111:/opt
在对应机器上修改文件 server.properties
hc2110机器上改以下参数
broker.id=2
listeners=PLAINTEXT://hc2110:9092
hc2111机器上改以下参数
broker.id=3
listeners=PLAINTEXT://hc2111:9092
/etc/profile
3台机器上都添加环境变量,并使之生效
启动和检验
参考 b0104中启动过程。 下面列出不一样或注意的地方。
- zookeeper要在3台机器上单独启动。
- kafka也要在3台机器上分布单独启动.
- 以下是常见命令。 连接3台机器任意一台 9092端口,都可以。 好像可以直接指定zookeeper。
# 创建topic,使用默认参数 kafka-topics.sh --bootstrap-server hc2109:9092 --create --topic testKafka1 kafka-topics.sh --bootstrap-server hc2109:9092 --list # 生产者和消费者 命令行程序 kafka-console-producer.sh --bootstrap-server hc2109:9092 --topic testKafka1 kafka-console-consumer.sh --bootstrap-server hc2109:9092 --topic testKafka1 # 指定服务器,也可以成功 kafka-topics.sh --bootstrap-server hc2110:9092 --create --topic testKafka2 kafka-topics.sh --bootstrap-server hc2109:9092 --list # 创建3个分区,2个副本的topic kafka-topics.sh --bootstrap-server hc2110:9092 --create --topic test1 --partitions 3 --replication-factor 2
topic test1 磁盘结构
如上命令,创建topic后,去查看磁盘目录
hc2109

hc2110

hc2111
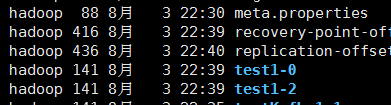
| hc2109 | hc2110 | hc2111 | |
| leader | test1-0 | test1-1 | test1-2 |
| follower | test1-1 | test1-2 | test1-0 |
正常情况3个kafka节点都启动, 这个topic 3个leader节点均分在集群上,最大程度利用并发资源。 一旦某个机器挂掉, 有一台机器会运行2个leader分区,相对负担比正常下大一些。
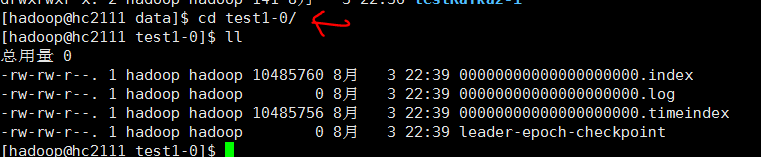
每个 分区副本里面的文件对象如下。
参考
- disk 20210803_大数据_伪分布式_kafka安装.txt
- disk 20210803_大数据_分布式_kafka安装.txt
- b0104 伪分布式/kafka
4. hbase 2.3.6 20210803
计划
在集群3台机器上都安装hbase
前置
- 已经安装hadoop
- 已经安装zookeeper (其实hbase 默认自带一个,但是不用它的)
- 之前在伪分布式上安装过了,并写了详细过程, 本文基于此在上面改动,参考b0104
安装配置
集群3台机器, 先选定hc2109, 安装 b0104 文档中 ,伪分布式hc2108安装hbase过程执行前面大部分操作.。
下面只记录不一样的地方
hbase-site.xml
这两个参数的值需要调整为本集群的
<!-- zk地址 --> <property> <name>hbase.zookeeper.quorum</name> <value>hc2109:2181,hc2110:2181,hc2111:2181</value> </property> <!-- 配置hbase存储位置,根据自己的hadoop集群配置端口 --> <property> <name>hbase.rootdir</name> <value>hdfs://hc2109:9000/hbase</value> </property>
regionservers
将内容设置为本集群安装hbase的所有机器主机名,这里是
hc2109
hc2110
hc2111
集群分发
# 复制解压包到其他机器上,hc2109上执行 scp -r /opt/hbase-2.3.6 hadoop@hc2110:/opt scp -r /opt/hbase-2.3.6 hadoop@hc2111:/opt
/etc/profile
在hc2110,hc2111上 将hbase的路径变量加进去,并执行source 生效
启动和测试
按照 b0104 伪分布式 hc2108上的 过程进行, 一路都正常
注意点:
- hadoop,hbase 只需要在一台机器上执行启动命令就可以启动整个集群程序, 而zookeeper需要登录到每台机器上各启动一次程序
- 集群中 hbase的3台机器是平等的, 启动过程中,哪台机器最开始启动, HMaster 就在上面,后续的web 端口也是, http://hc2109:16010/
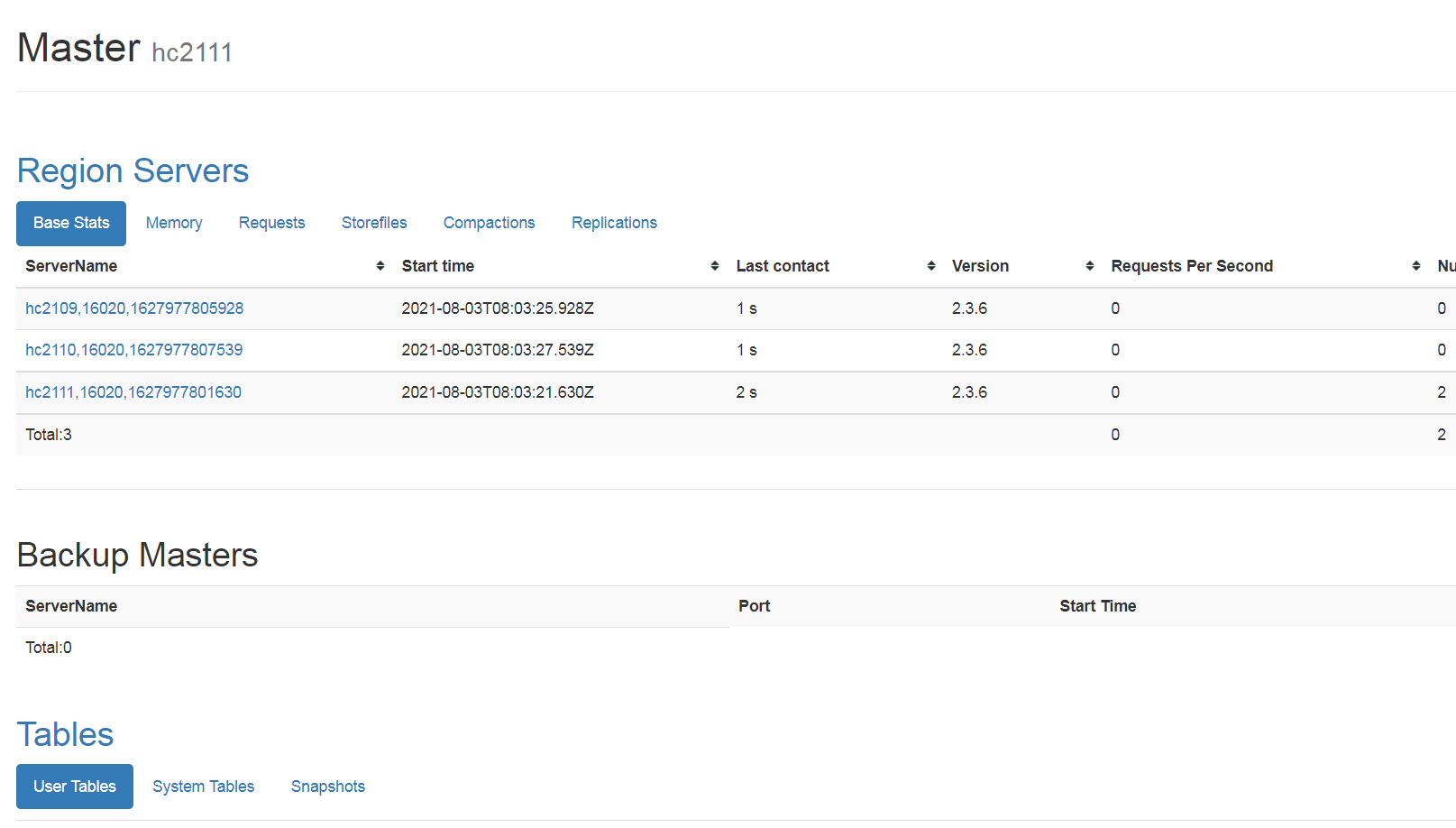
参考
- disk 20210803_大数据_分布式_hbase相关记录.txt
- b0104 伪分布式/hbase安装
3. zookeeper 3.6.3 20210802
计划
在集群3台机器上都安装zookeeper
前置
- 已经安装jdk
安装
单机上配置好
先在一台机器上操作, 选定 hc2109
按照 "b0104 大数据集群-2021伪分布式-环境搭建"/3.zookeeper 3.6.3 的步骤配置参数
相对hc2108上单机zookeeper,不一样的地方是
1. zoo.cfg 中添加以下信息
dataDir=/opt/apache-zookeeper-3.6.3-bin/data dataLogDir=/opt/apache-zookeeper-3.6.3-bin/log # 主机ip, 心跳端口、数据端口 server.1=hc2109:2888:3888 server.2=hc2110:2888:3888 server.3=hc2111:2888:3888
2. 在 apache-zookeeper-3.6.3-bin/data , 添加文件 vi myid, 输入1 保存
复制到其他机器
在hc2109上将配置好的安装包 和配置文件复制到集群其他机器
# 复制解压包到其他机器上,hc2109上执行 scp -r /opt/apache-zookeeper-3.6.3-bin hadoop@hc2110:/opt scp -r /opt/apache-zookeeper-3.6.3-bin hadoop@hc2111:/opt # 传输配置文件 scp /etc/profile root@hc2110:/etc/profile scp /etc/profile root@hc2111:/etc/profile
还需要登录其他机器
- 执行 source /etc/profile 使得变量生效
- data/myid, hc2110上机器上的值修改为2, hc2111机器上的修改为3, 这样与前面的配置参数都对应起来
启动和测试
分布在3台机器上 执行启动命令和状态查看 zkServer.sh start , zkServer.sh status



在其他机器安装过zookeeper的hc2108上 ,执行客户端程序, 连接集群中任意一台机器,这里是hc2109, 如下
# hc2108上执行
zkCli.sh -server hc2109:2181
测试
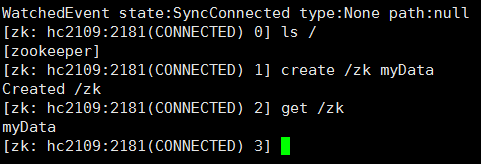
也可以指定整个集群连接参数, 也是从中选择一台机器作为连接服务器
zkCli.sh -server hc2109:2181,hc2110:2181,hc2111:2181
参考
- 20210803_大数据_分布式_zookeeer安装.txt
- ref1 "ZooKeeper的安装、配置和启动, liaosilzu2007, 2018/04/27"
- ref2 "zookeeper安装以及使用,燕少༒江湖,2018/07/05"
- ref3 "ZooKeeper安装及简单操作, H_D, 2019/01/15"
- ref4 "ZooKeeper的安装与部署,jimcsharp,2019/08/27"
注意
- zoo.cfg 配置文件中 参数右边 添加 "# 中文描述" 可能会引发zookeeper启动时不能正确读取参数, 参考 b0108/zookeeper/Q1
- myid 文件是放在 创建的数据目录 data下, 而不是 conf下。
2. HIVE 2.3.9 20210802
计划
由于已经在 伪分布式hc2108上安装过hive了。 在分布式上集群上,只在hc2110机器上安装服务器组件, 可以照做,修改数据库连接用户和数据库就可以了。
同时计划 安装hive 客户端程序,选定机器为hc2107作为客户机,不在集群中。 hive客户端用来执行Beeline.
前置
- 已经安装了hadoop, 这里是3.3.1, 参考本文相关章节
- 已经 安装了 数据库 MariaDB 5.5, 对应Mysql 开源版本,随着centos7.9 安装时装好的。数据库服务器在hc2102, 创建了数据库用户 hive2和数据库hivedb2,测试过可以远程命令行访问
Hive 安装(服务器端)
参考 “b0104 大数据集群-2021伪分布式-环境搭建" / 2. HIVE 2.3.9 , 将Hive 安装在 hc2110上。
这里直接从hc2108上拷贝配置好的安装包
scp -r /opt/apache-hive-2.3.9-bin hadoop@hc2110:/opt
在/etc/profile中添加环境变量并使生效。
整个配置过程中不一样的地方是:
hive-site.xml
hive-site.xml 相对 hc2108伪分布式上变化 <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hc2102:3306/hivedb2?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive2</value> </property> <property>
Hive客户端(Beeline)
hive安装后, 可以执行hive CLI,这是本地模式,运行在Hive服务器端。
还有一个Beeline程序, 使用了Thrift、JDBC 技术并且支持SQL的命令行客户端程序, 可以不和服务器程序在同一台机器上。
这里选定客户机为hc2107
启动相关服务
<!-- 客户端远程连接的端口 --> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>0.0.0.0</value> </property> <property>
服务器端上的Hive里的 hive-site.xml 配置文件的这两个参数,决定了服务器程序的端口
执行以下命令启动这个服务并验证
nohup hiveserver2 & # 验证,看端口10000是否开启 netstat -nltp | grep 10000
服务器端hc2110的Beeline功能验证
命令行执行 Beeline, 登录到它的shell, 执行以下连接命令
!connect jdbc:hive2://hc2110:10000
输入 连接账号和密码, 结果报错了,原因就是hadoop服务器不允许任意客户端连接
还需要添加额外配置,详细参考 “b0108 大数据集群-2021分布式A(手动3节点)-运维"/Hive/Q1 问题
解决这个问题,就可以正常使用了,如同 Hive Cli 一样
客户端 hc2107 配置
- 安装jdk
- 将 分布式集群上配置好的hadoop安装文件夹 复制到 hc2107 /opt下
- 将 hc2110 上的hive 安装包 复制到 hc2107 /opt下 , 将 hive-site.xml 文件下的所有属性清空 (参考本文 返回补充/hive.metastore.uris)
- 将hc2110是的 /etc/profile 上的 jdk,hadoop, hive的配置信息复制到 hc2107对应文件中,前提是它们的存放路径都一样
客户端hc2107 的Beeline功能验证
命令行执行 Beeline, 登录到它的shell, 执行以下连接命令
!connect jdbc:hive2://hc2110:10000
输入 连接账号和密码 。 正常可以了
可以登录hive web 查看结果 http://hc2110:10002/
注意: hc2107上 并不需要启动hadoop 任何进程,和hive服务端进程
相关
- disk 20210802_大数据_hadoop分布式_hive安装.txt
- “b0104 大数据集群-2021伪分布式-环境搭建”/HIVE
其他
遗留以下问题值得深入探索:
- 分布式集群 hive 服务器端 有没有必要装成分布式的, 本文是单点的。
- 服务器端Hive的 MetaStore 可以单独服务形式存在,指定参数 hive.metastore.uris 为 thrift://服务器ip:9083 , 说明客户端程序 通过连接它获取元数据信息,但是本文中客户端程序并没有用到这参数,直接连接服务器的Thrift端口,也能正常使用,看到数据库的表。 不很清楚这个MetaStore单独存在的情况。 已经解决,参考本文 返回补充/hive.metastore.uris
返回补充
hive.metastore.uris (20210808)
1. 启动hive服务器的这个服务

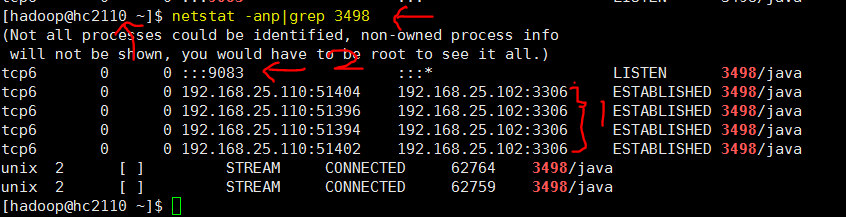
hive 服务器hc2110 并没有配置 hive.metastore.uris , 在服务器启动在这个服务, 发现监听 9083端口,并且和mysql 3306
说明hive 服务器hc2110 通过这个服务 起一个中转站的作用, 帮助 hive客户端 获得mysql数据库里的hive元数据信息,这种情况在客户机使用hive时有用。
2 在客户端的hive中添加 hive.metastore.uris 信息
在hc2107上的hive的配置文件添加以下
<!-- 本机作为客户端,连接这个hive服务器,通过它中转获取hive元数据。这是远程服务器的地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://hc2110:9083</value> </property>
接下来在客户机hc2107 执行hive, 就可以连上hc2110。
在hive shell可以获取hive数据,这样在hive客户端上不存储数据库帐号、密码,同时又能正常使用
1. HADOOP3.3.1 20210728
前置
所有的机器都已经完成了这些操作
- 已经创建hadoop账号,添加了sudo 权限
- 已经安装jdk1.8
- 配置了 主机名 和静态ip地址
- 关闭防火墙
- 集群机器上的时间直接设置为北京时间,没有使用其他工具
设置ssh无密登录
集群机器通信需要配置这里, 以下在集群所有机器上都操作
ssh-keygen -t rsa # 生成密钥, 分别在3台机器上执行,每台机器按3次回车 # 分布在3台机器上执行以下命令, 将指定机器上的公钥拷贝到本机上 # 每个执行过程中, 选择 yes,输入对方机器密码 ssh-copy-id hc2109 ssh-copy-id hc2110 ssh-copy-id hc2111
执行上述操作后,任何2台机器都能够彼此无密码 ssh 登录对方
注: N台机器的操作次数 N*N, N很小时可以一台台机器操作, N很大需要寻找更高效的处理方法
下载、解压
win下 通过地址 https://hadoop.apache.org/releases.html下载二进制安装包 hadoop-3.3.1.tar.gz 通过winscp工具上传到 hadoop某个目录下 tar -zxvf hadoop-3.3.1.tar.gz # 解压 mv hadoop-3.3.1 /opt/ # 移动到安装目录下
以上linux 操作只需在 一台机器上 hc2109进行
参数配置
以下改动先在hc2109机器上进行
- /etc/hosts 配置集群机器主机名
在hc2109机器 的这个配置文件中添加以下 集群机器信息,后续可以通过主机名指定机器
192.168.25.109 hc2109 192.168.25.110 hc2110 192.168.25.111 hc2111
1 添加环境变量
sudo vi /etc/profile
添加文件内容:
### 配置hadoop export HADOOP_HOME=/opt/hadoop-3.3.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行 source /etc/profile 生效
可以进行一个简单验证,如下,看看环境参数有没有成功
[hadoop@hc2109 ~]$ hadoop version Hadoop 3.3.1
2 在linux创建hadoop运行时目录
在 /opt/hadoop-3.3.1 下创建以下目录
- tmp 存放运行过程临时文件
- dfs/name 存放namenode的输出
- dfs/data 存放datanode的输出
3 添加jdk路径到 hadoop xxxx.sh 脚本文件中
在以下文件中添加环境变量
- hadoop-env.sh
- yarn-env.sh
- mapred-env.sh
export JAVA_HOME=/opt/jdk1.8.0_301
如果这里不添加,虽然在/etc/profile 有该环境变量,启动时还是会提示找不到它
4 core-site.xml
在目录下hadoop-3.31/etc/hadoop , 添加以下内容, 默认是空文件
<configuration> <!-- 指定hdfs的nameservice的地址为hc2109:9000 --> <property> <name>fs.defaultFS</name> <value>hdfs://hc2109:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-3.3.1/tmp</value> </property> </configuration>
5 hdfs-site.xml
路径同上,添加以下内容,文件默认为空的


<configuration> <!-- HDFS的副本为2, 大规模集群>=3 --> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/hadoop-3.3.1/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/hadoop-3.3.1/dfs/data</value> </property> <!-- 指定Hadoop secondary namenode,避免与namenode同一台主机 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hc2110:9868</value> <description> The secondary namenode http server address and port. </description> </property> <property> <name>dfs.namenode.secondary.https-address</name> <value>hc2110:9869</value> <description> The secondary namenode HTTPS server address and port. </description> </property> </configuration>
6 yarn-site.xml
路径同上,添加以下内容,文件默认为空的
<configuration> <!-- 指定YARN ResourceManager的地址。另外可以在yarn.resourcemanager.ha.xxx 配置高可用--> <property> <name>yarn.resourcemanager.hostname</name> <value>hc2109</value> </property> <!-- 指定reducer获取数据的方式, 可以设置多个比如mapreduce_shuffle,spark_shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- value值为 命令行执行 hadoop classpath的输出--> <property> <name>yarn.application.classpath</name> <value>/opt/hadoop-3.3.1/etc/hadoop:/opt/hadoop-3.3.1/share/hadoop/common/lib/*:/opt/hadoop-3.3.1/share/hadoop/common/*:/opt/hadoop-3.3.1/share/hadoop/hdfs:/opt/hadoop-3.3.1/share/hadoop/hdfs/lib/*:/opt/hadoop-3.3.1/share/hadoop/hdfs/*:/opt/hadoop-3.3.1/share/hadoop/mapreduce/*:/opt/hadoop-3.3.1/share/hadoop/yarn:/opt/hadoop-3.3.1/share/hadoop/yarn/lib/*:/opt/hadoop-3.3.1/share/hadoop/yarn/*</value> </property> <!-- 忽略虚拟内存的检查,虚拟机上设置不容易出问题 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>
7 mapred-site.xml
路径同上,添加以下内容,文件默认为空的
<configuration> <!--指定mr运行在yarn上--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- historyserver 是否运行不影响hadoop集群正常工作 只是为了更好查看历史运行信息的 --> <!-- 指定mapreduce jobhistory地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hc2109:10020</value> </property> <description>MapReduce JobHistoryServer IPC host:port</description> <!-- 任务历史服务器的web地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hc2109:19888</value> <description>MapReduce JobHistoryServer Web UI host:port</description> </property> </configuration>
8 workers
路径同上, 文件内容改成本主机名, 表示hadoop集群工作节点. 在文件中添加
hc2109
hc2110
hc2111
集群分发
设置安装目录scp权限
# 分别在3台机器上执行赋权,接下来会执行scp,否则权限不够
# 如果不安装在/opt下,可以不用这样 sudo chmod 777 /opt
替代方案: ssh root@hc2110 "chmod 777 /opt" , 需要对方机器root密码
将配置好的hadoop安装包分发到集群其他机器上
# 复制解压包到其他机器上,hc2109上执行
scp -r /opt/hadoop-3.3.1 hadoop@hc2110:/opt
scp -r /opt/hadoop-3.3.1 hadoop@hc2111:/opt
分发配置文件 /etc/profile, /etc/hosts
前提: 这3台机器的操作是同步的, 对应的配置文件时一样的,可以直接覆盖。
以下操作在hc2109机器上进行
su # 切换到 root 用户
# 传输配置文件
scp /etc/profile root@hc2110:/etc/profile
scp /etc/profile root@hc2111:/etc/profile
# 使得配置文件生效
ssh root@hc2110 "source /etc/profile" # 需要对方机器root密码,连接对方机器的shell需要重新打开才能看到
ssh root@hc2111 "source /etc/profile"
备注: 上述操作 每一步都需要root密码。 可以和其他方案放在一起权衡选择
/etc/hosts 可以按照上面一样。
启动hadoop和检验
格式化
hdfs namenode -format
如果报错, 需要检查前面的配置漏了什么或者是否错误
启动
start-dfs.sh # 启动hdfs, 在namenode 所在机器 core-site.xml/fs.defaultFS, 这里是hc2109
start-yarn.sh # 启动yarn, 在resoucemanager 所在机器 yarn-site.xml/yarn.resourcemanager.hostname , 这里是hc2109
Web页面
打开检验一下安装是否成功
http://hc2109:9870/ # hdfs
http://hc2109:8088/ # yarn
检验
执行下面的计算pi程序,如果能够成功 , 说明一切正常
# 执行检验程序
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 1
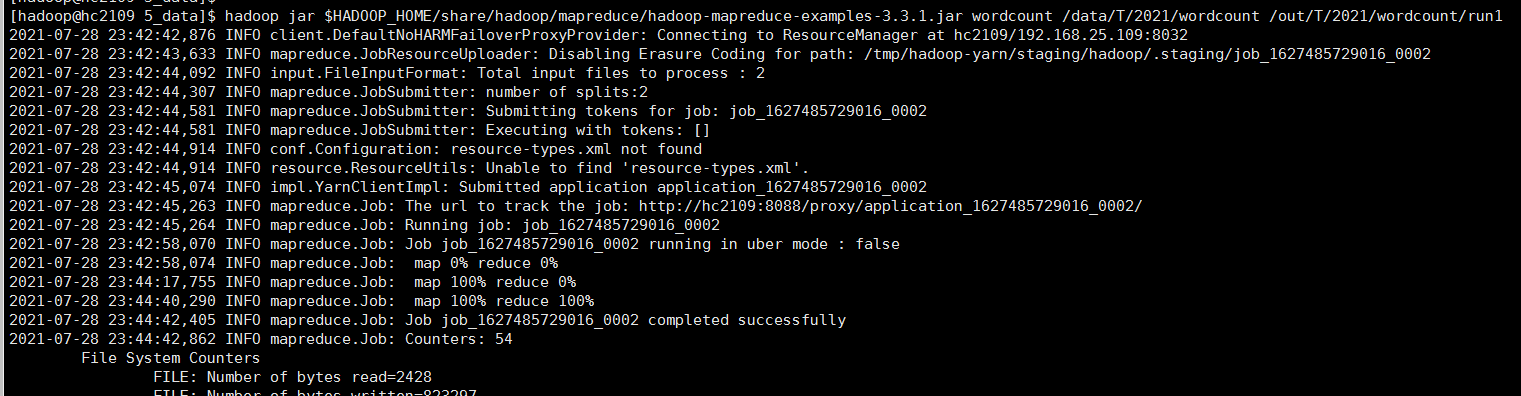
wordcount 需要准备好 输入目录下的文件、输出目录, 其中 run1 由程序运行后自动创建
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /data/T/2021/wordcount /out/T/2021/wordcount/run1
其他
需要添加 数据节点
添加 DataNode
- 不能 scp 原来机器上的 hadoop 安装包, 因为已经在下面创建运行数据存储目录了
- 新机器配置基础环境,包括ssh, 确保所有设置和前面的机器保持一样。
- 重新解压 hadoop 安装包 hadoop-3.3.1.tar.gz, 放入到 /opt目录下, 并创建运行时目录 tmp, dfs/name,dfs/data
- 在hc2109机器上的 workers文件中添加新节点, 然后将hadoop 配置文件重新分发到集群所有节点 scp /opt/hadoop-3.3.1/etc/hadoop/* hadoop@hc2112:/opt/hadoop-3.3.1/etc/hadoop/
- 新机器 /etc/profile, /etc/hosts 文件的改动和生效
- 重启 hdfs和yarn
参考
- “b0104 大数据集群-2021伪分布式-环境搭建"
- disk 20210727_hadoop分布式集群之间操作命令.txt
- linux $HADOOP_HOME/share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/xxx-default.xml 这个下面有很多配置 参数样例可以参考学习
- http://hadoop.apache.org/docs/r3.3.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
- "Hadoop3.3.0集群安装" 渊云
- "hadoop3.2.0完全分布式集群搭建" 日日v

 浙公网安备 33010602011771号
浙公网安备 33010602011771号