
2003031130-孙月梅Python数据分析五一假期作业
| 项目 | 内容 |
| 课程班级博客链接 | 20级数据班(本) |
| 这个作业要求链接 | python数据分析五一假期作业 |
| *博客名称: | 2003031130-孙月梅Python数据分析五一假期作业 |
| 要求 |
每道题要有题目,代码(使用插入代码,不会插入代码的自己查资料解决,不要直接截图代码!!),截图(只截运行结果)。
|
作业:
1.把期中考试代码看懂、运行并调通,要求每一行 或 每个重要功能写上注释。
题目:一、分析1996~2015年人口数据特征间的关系(1题50分,共50分)
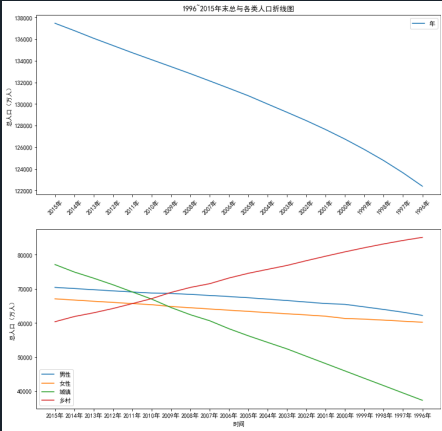
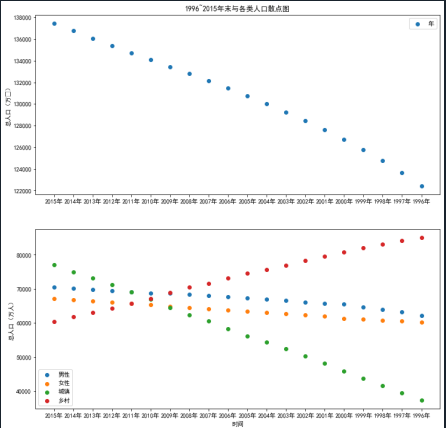
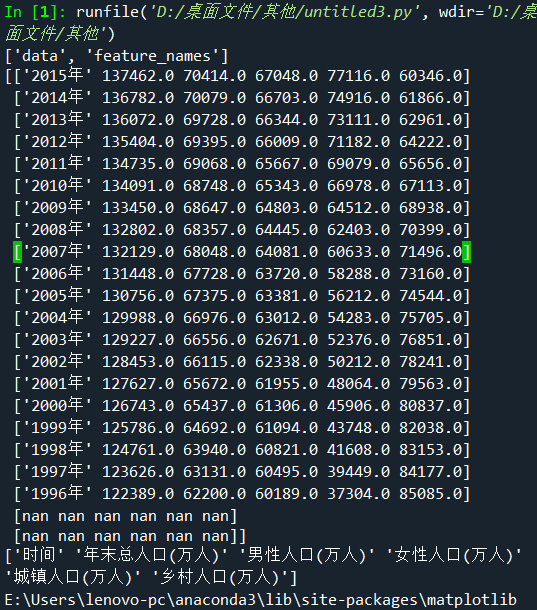
import numpy as np import matplotlib.pyplot as plt #使⽤numpy库读取⼈⼝数据 data=np.load('D:/桌面文件/pycharm 文件/populations.npz',allow_pickle=True) print(data.files)#查看⽂件中的数组 print(data['data']) print(data['feature_names']) plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示 plt.rcParams['axes.unicode_minus'] = False# 防止字符无法显示 name=data['feature_names']#提取其中的feature_names数组,视为数据的标签 values=data['data']#提取其中的data数组,视为数据的存在位置 p1=plt.figure(figsize=(12,12))#确定画布⼤⼩ pip1=p1.add_subplot(2,1,1)#创建⼀个两⾏⼀列的⼦图并开始绘制 #在⼦图上绘制散点图 plt.scatter(values[0:20,0],values[0:20,1])#,marker='8',color='red' plt.ylabel('总人口(万⼈)') plt.legend('年末') plt.title('1996~2015年末与各类人口散点图') pip2=p1.add_subplot(2,1,2)#绘制⼦图2 plt.scatter(values[0:20,0],values[0:20,2])#,marker='o',color='yellow' plt.scatter(values[0:20,0],values[0:20,3])#,marker='D',color='green' plt.scatter(values[0:20,0],values[0:20,4])#,marker='p',color='blue' plt.scatter(values[0:20,0],values[0:20,5])#,marker='s',color='purple' plt.xlabel('时间') plt.ylabel('总人口(万人)') plt.xticks(values[0:20,0]) plt.legend(['男性','女性','城镇','乡村']) #在⼦图上绘制折线图 p2=plt.figure(figsize=(12,12)) p1=p2.add_subplot(2,1,1) plt.plot(values[0:20,0],values[0:20,1])#,linestyle = '-',color='r',marker='8' plt.ylabel('总人口(万人)') plt.xticks(range(0,20,1),values[range(0,20,1),0],rotation=45)#rotation设置倾斜度 plt.legend('年末') plt.title('1996~2015年末总与各类人口折线图') p2=p2.add_subplot(2,1,2) plt.plot(values[0:20,0],values[0:20,2])#,'y-' plt.plot(values[0:20,0],values[0:20,3])#,'g-.' plt.plot(values[0:20,0],values[0:20,4])#,'b-' plt.plot(values[0:20,0],values[0:20,5])#,'p-' plt.xlabel('时间') plt.ylabel('总人口(万人)') plt.xticks(values[0:20,0]) plt.legend(['男性','女性','城镇','乡村']) #显⽰图⽚ plt.show()
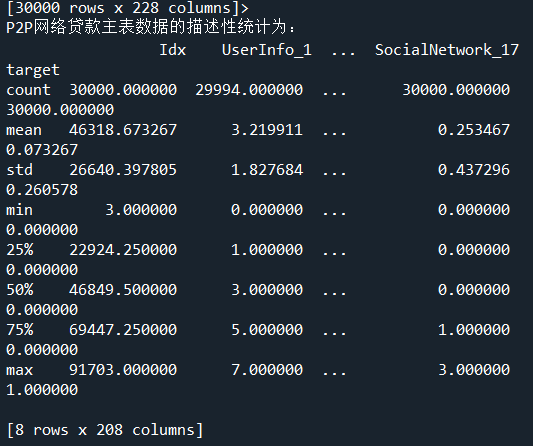
二、读取并查看P2P网络贷款数据主表的基本信息(1题10分,共10分)
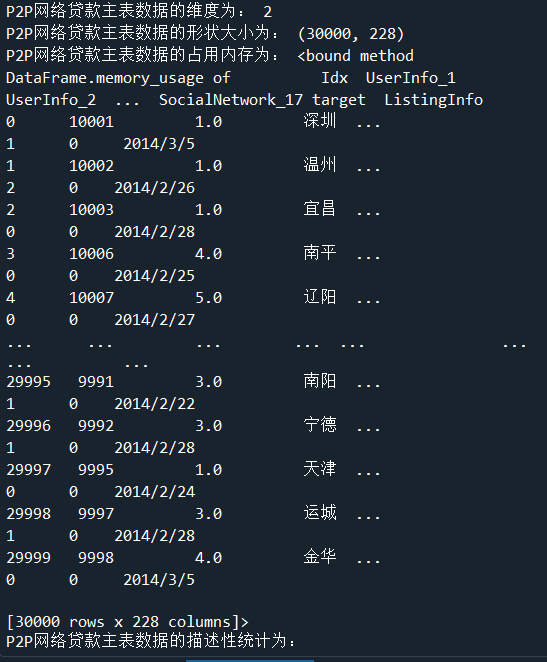
#代码16-1 import os import pandas as pd master = pd.read_csv('D:/桌面文件/pycharm 文件/Training_Master.csv',encoding='gbk') print('P2P网络贷款主表数据的维度为:',master.ndim) print('P2P网络贷款主表数据的形状大小为:',master.shape) print('P2P网络贷款主表数据的占用内存为:',master.memory_usage) #代码16-2 print('P2P网络贷款主表数据的描述性统计为:\n',master.describe())
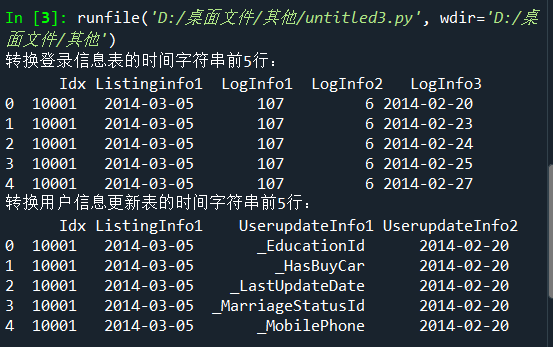
三、提取用户信息更新表和登录信息表的时间信息(1题10分,共10分)
import pandas as pd LogInfo = pd.read_csv('D:/桌面文件/pycharm 文件/Training_LogInfo.csv',encoding='gbk') Userupdate = pd.read_csv('D:/桌面文件/pycharm 文件/Training_Userupdate.csv',encoding='gbk') # 转换时间字符串 LogInfo['Listinginfo1']=pd.to_datetime(LogInfo['Listinginfo1']) LogInfo['LogInfo3']=pd.to_datetime(LogInfo['LogInfo3']) print('转换登录信息表的时间字符串前5行:\n',LogInfo.head()) Userupdate['ListingInfo1']=pd.to_datetime(Userupdate['ListingInfo1']) Userupdate['UserupdateInfo2']=pd.to_datetime(Userupdate['UserupdateInfo2']) print('转换用户信息更新表的时间字符串前5行:\n',Userupdate.head())
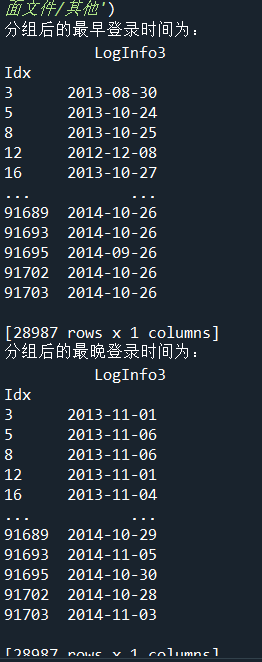
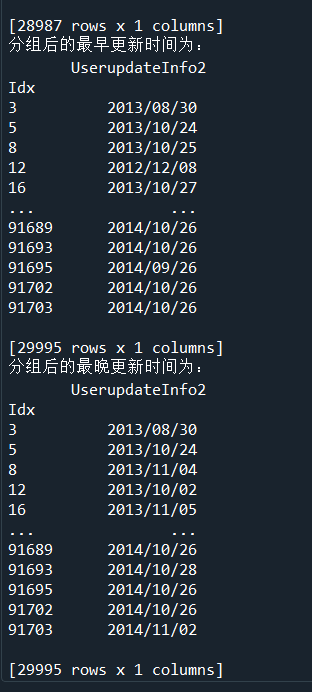
四、使用分组聚合方法进一步分析用户信息更新表和登录信息表(1题30分,共30分)
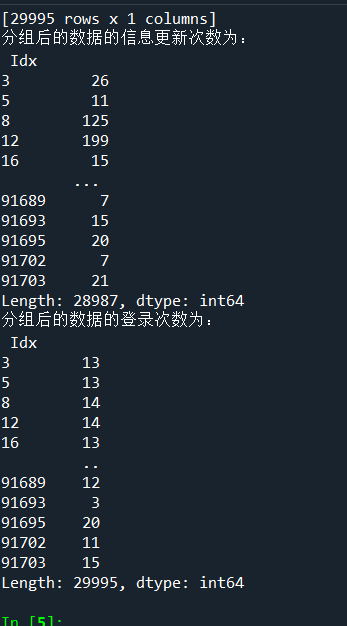
#代码18-1 import pandas as pd import numpy as np LogInfo = pd.read_csv('D:/桌面文件/pycharm 文件/Training_LogInfo.csv',encoding='gbk') Userupdate = pd.read_csv('D:/桌面文件/pycharm 文件/Training_Userupdate.csv',encoding='gbk') # 使用groupby方法对用户信息更新表和登录信息表进行分组 LogGroup = LogInfo[['Idx','LogInfo3']].groupby(by = 'Idx') UserGroup = Userupdate[['Idx','UserupdateInfo2']].groupby(by = 'Idx') #代码18-2 # 使用agg方法求取分组后的最早,最晚,更新登录时间 print('分组后的最早登录时间为:\n',LogGroup.agg(np.min)) print('分组后的最晚登录时间为:\n',LogGroup.agg(np.max)) print('分组后的最早更新时间为:\n',UserGroup.agg(np.min)) print('分组后的最晚更新时间为:\n',UserGroup.agg(np.max)) #代码18-3 # 使用size方法求取分组后的数据的信息更新次数与登录次数 print('分组后的数据的信息更新次数为:\n',LogGroup.size()) print('分组后的数据的登录次数为:\n',UserGroup.size())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号