
ElasticSearch(ES)、ik分词器、倒排索引相关介绍
简介:
ES(ElasticSearch)是一款分布式全文检索框架,底层基于Lucene实现。Lucene只是一个框架;
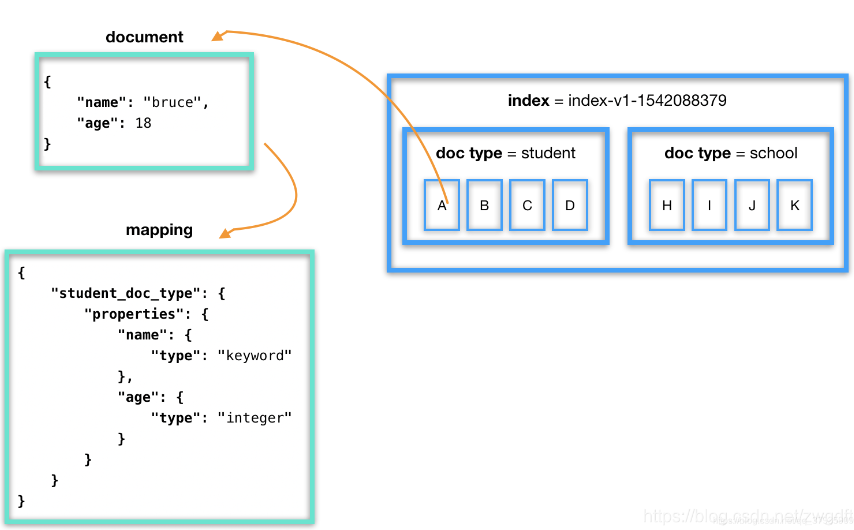
ES与传统数据的区别主要有: 1).结构名称不同 一个ES集群可以包含多个索引(数据库),每个索引又包含了很多类型(表),类型中包含了很多文档(行),每个文档使用 JSON 格式存储数据,包含了很多字段(列)。
基本概念:
ik分词器:
1)ik_max_word(常用模式)
将文本做最细粒度拆分
2)ik_smart
将文本做最粗粒度拆分
扩展词典使用
扩展词的使用场景:就是不想让哪些词分开,例如:南京市长江大桥 使用 ik_max_wrod 分出来的 江大桥 并没有意义
1).windows安装:官网下载对应es版本的ik分词器,然后将下好的ik分词器放到下载好的es的plugins文件夹下,进入到ik分词器的安装目录下的config目录下,如果想自定义词,那么就新增自定义扩展词典,如my.dic,并在里面写入自定义不想被分开的词;
2). 把自定义的扩展词文件添加到IKAnalyzer.cfg.xml中如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
停用词典使用
有些词在文本中出现的频率非常高,但对本文的语义产生不了多大的影响。例如英文的a、from、of等。或中文的”的、啊、呢等”。这样的词称为停用词。停用词经常被过滤掉,不会被进行索引。在检索的过程中,如果用户的查询词中含有停用词,系统会自动过滤掉。停用词可以加快索引的速度,减少索引库文件的大小;
同上在ik目录下新建一个xx.dic的文件,里面写好自定义需要停用的词(即不想被检索,可以直接过滤掉的词),然后将该文件添加到ik分词器配置文件中(IKAnalyzer.cfg.xml)中即可;
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">xx.dic</entry>
同义词典使用
有很多相同意思的词,我们称之为同义词,比如“土豆”和“马铃薯”,“馒头”和“馍”等。在搜索的时候,我们输入的可能是“马铃薯”,但是应该把含有“土豆”的数据一起查询出来,这种情况叫做同义词查询。
注意:扩展词和停用词是在索引的时候使用,而同义词是检索时候使用。
配置IK同义词
Elasticsearch 自带一个名为 synonym 的同义词 filter。为了能让 IK 和 synonym 同时工作,我们需要定义新的 analyzer,用 IK 做 tokenizer,synonym 做 filter。听上去很复杂,实际上要做的只是加一段配置。
1)创建同义词文件
首先要在ES中config文件夹下创建analysis文件,并在里面创建synonym.dic
2.编辑同义词
使用文本编辑器打开文件,输入你想要创建的同义词(分隔符是英文逗号),输入一些同义词并存为 utf-8 格式。例如
china,中国
倒排索引:
什么是倒排索引: 倒排索引也叫反向索引,通俗来讲正向索引是通过key找value,反向索引则是通过value找key(即通过字段找文档)。
Elasticsearch的核心:inverted index(倒排索引)。inverted index是一个二维结构,如下所示,包含一组排好序的term(字段),每个term都关联有一些信息,这些信息指出哪些document包含了这个term。如当需要查询包含关键词"分布式"的数据时,系统会先从inverted index中找出对应的term,获取到其对应的document id,然后就可以根据document id找出其信息了。
sample data(如下三条文档数据):
1. {"author": "Bruce", "title": "浅谈分布式存储系统"}
2. {"author": "Bruce", "title": "常见的分布式系统"}
3. {"author": "David", "title": "分布式存储原理"}
inverted index for field "author":关于字段‘author’建立的倒排索引;
-------------------------------
term | Posting List
-------------------------------
Bruce | 1, 2
David | 3
-------------------------------
inverted index for field "title":关于字段‘title’建立的倒排索引;
-------------------------------
term | Posting List
-------------------------------
常见 | 3
存储 | 1, 3
分布式 | 1, 2, 3
浅谈 | 1
系统 | 1, 2
原理 | 3
-------------------------------
Elasticsearch分别为每个field(字段)都建立了一个倒排索引,'24','Bruce' , '分布式' ,这些叫term,而[1,2]就是Posting List(倒排列表)。Posting list就是一个int的数组,倒排列表记录了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
如果这里有上千万的记录呢?如何通过term来查找呢?这就需要了解一下Term Dictionary和Term Index的概念
Term Dictionary
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似,为什么说比B-Tree的查询快呢?
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树
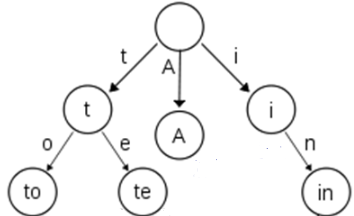
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找
所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?