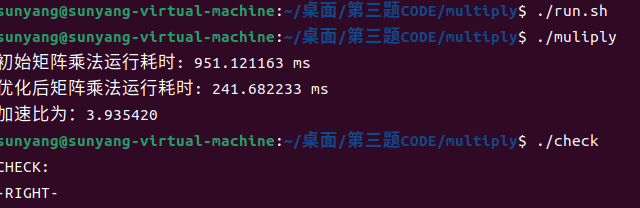
矩阵乘法优化
step1:更改循环顺序
//--------------- c = a * b -------------------------//
for(int i=1;i<N;i++)
for(int k=1;k<N;k++)
for(int j=1;j<N;j++)
c[i][j] += a[i][k]*b[k][j];
//--------------------------------------------------//
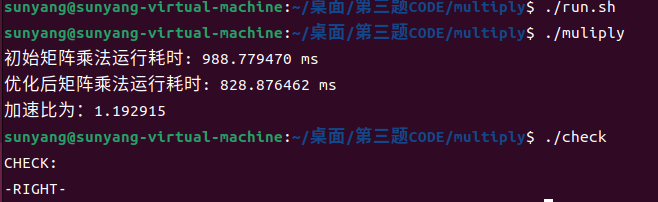
step2:矩阵分块
//--------------- c = a * b -------------------------//
int blocksize=10;
double sum=0;
for (int kk = 0; kk < N; kk += blocksize) {
for (int jj = 0; jj < N; jj += blocksize) {
for (int i = 0; i < N; i++) {
for (int j = jj; j < jj + blocksize; j++) {
sum = c[i][j];
for (int k = kk; k < kk + blocksize; k++) {
sum += a[i][k]*b[k][j];
}
c[i][j] = sum;
}
}
}
}
//--------------------------------------------------//
(blocksize取值经反复试验后取值为10 速度达到最快(仅适用于本机及当前500*500矩阵,各有差异))
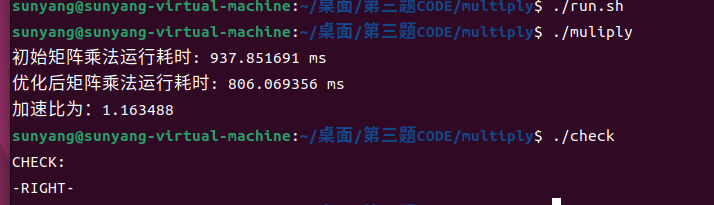
step3:分块后效果太不明显
上并行)
#include<stdio.h>
#include<omp.h>
#include<stdlib.h>
#include<math.h>
const int N = 500;
double a[500][500];
double b[500][500];
double c_0[500][500];
double c[500][500];
int main(){
//------------------------------------------//
FILE* f1;
FILE* f2;
FILE* out;
f1 = fopen("data_a.txt", "r");
f2 = fopen("data_b.txt", "r");
out = fopen("data_c.txt", "w");
for(int i=1;i<N;i++){
for(int j=1;j<N;j++){
fscanf(f1,"%lf",&a[i][j]);
fscanf(f2,"%lf",&b[i][j]);
}}
//--------------------------------------------------//
double t0,t1;
double T0,T1;
//----------------------------------//
t0 = omp_get_wtime();
//mul
for(int i=1;i<N;i++)
for(int j=1;j<N;j++)
for(int k=1;k<N;k++)
c_0[i][j] += a[i][k]*b[k][j];
t1 = omp_get_wtime();
T0 = (t1-t0)*1000;
printf("优化前矩阵乘法耗时: %f ms\n", T0);
//---------------------------------------------------//
t0 = omp_get_wtime();
//---------------------//
//--------------- c = a * b -------------------------//
#pragma omp parallel for schedule(dynamic)
for(int i=1;i<N;i++)
for(int k=1;k<N;k++)
for(int j=1;j<N;j++)
c[i][j] += a[i][k]*b[k][j];
//--------------------------------------------------//
t1 = omp_get_wtime();
T1 = (t1-t0)*1000;
printf("优化后矩阵乘法运行耗时: %f ms\n", T1);
printf("加速比为%f\n",T0/T1);
//-------------------------------------------//
for(int i=1;i<N;i++)
for(int j=1;j<N;j++)
fprintf(out,"%lf\n",c[i][j]);
//---------------------------------------------------//
fclose(f1);
fclose(f2);
fclose(out);
}