Mysql 优化,慢查询
最近项目上遇到点问题,服务器出现连接超时。上次也是超时,问题定位到mongodb上,那次我修改好了,这次发现应该不是这个的问题了。
初步怀疑是mysql这边出问题了,写的sql没经过压力测试,导致用户量多的时候,出现拥堵。
好,那就来看看mysql方便的慢查询吧,来看看具体的哪些sql查询慢,从这里开始来优化下。
一:开启慢查询
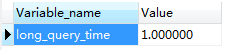
先来看看慢查询日志设置的时间长度:
show VARIABLES LIKE 'long%'
返回,long_query_time 指定了慢查询的阈值,即如果执行语句的时间超过该阈值则为慢查询语句,默认值为10秒。这里设置的为1s
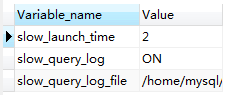
慢查询日志开启情况:
SHOW VARIABLES LIKE 'slow%'
返回:slow_query_log的值为ON为开启慢查询日志,OFF则为关闭慢查询日志。
slow_query_log_file 的值是记录的慢查询日志到文件中(注意:默认名为主机名.log,慢查询日志是否写入指定文件中,需要指定慢查询的输出日志格式为文件,相关命令为:show variables like ‘%log_output%’;去查看输出的格式)
通过以上命令,确定慢查询已经打开了。然后去看慢查询日志就行。
由于这里用的是阿里云的数据库,所以提供了后台可以很方便的查询到日志和下载日志。

这里点击下载即可将慢查询的日志下载下来。
二:分析慢查询日志
1. 截取一段慢查询日志:
# Time: 180918 19:06:21 # User@Host: proxy[proxy] @ [192.168.0.16] Id: 6707197 # Query_time: 1.015429 Lock_time: 0.000116 Rows_sent: 1 Rows_examined: 44438 SET timestamp=1537268781; select id, user_id, device_uuid, bd_client_id, bd_user_id, bd_tag, nodisturb_mode, nodisturb_start_time, nodisturb_end_time, binding_time, device_os_type, app_type, state from app_mobile_device where user_id = '78436' and app_type = 'YGY' order by binding_time desc; # User@Host: proxy[proxy] @ [192.168.0.16] Id: 6707236 # Query_time: 1.021662 Lock_time: 0.000083 Rows_sent: 1 Rows_examined: 44438 SET timestamp=1537268781; select id, user_id, device_uuid, bd_client_id, bd_user_id, bd_tag, nodisturb_mode, nodisturb_start_time, nodisturb_end_time, binding_time, device_os_type, app_type, state from app_mobile_device where user_id = '14433' and app_type = 'YGY' order by binding_time desc;
这里可以看到:
Query_time (慢查询语句的查询时间) 都超过了设置的 1s,
Rows_sent (慢查询返回记录) 这里只返回了 1 条
Rows_examined (慢查询扫描过的行数) 44438 -> 通过这里大概可以看出问题很大
2.现在将这个SQL语句放到数据库去执行,并使用EXPLAIN分析 看下执行计划。
EXPLAIN select id, user_id, device_uuid, bd_client_id, bd_user_id, bd_tag, nodisturb_mode, nodisturb_start_time, nodisturb_end_time, binding_time, device_os_type, app_type, state from app_mobile_device where user_id = '78436' and app_type = 'YGY' order by binding_time desc;
查询结果是:

解释下参数:
| SELECT识别符。这是SELECT的查询序列号 | |
| select_type |
SELECT类型,可以为以下任何一种:
|
| table |
输出的行所引用的表 |
| type |
联接类型。下面给出各种联接类型,按照从最佳类型到最坏类型进行排序:
|
| possible_keys |
指出MySQL能使用哪个索引在该表中找到行 |
| key | 显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。 |
| key_len | 显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。 |
| ref | 显示使用哪个列或常数与key一起从表中选择行。 |
| rows | 显示MySQL认为它执行查询时必须检查的行数。多行之间的数据相乘可以估算要处理的行数。 |
| filtered | 显示了通过条件过滤出的行数的百分比估计值。 |
| Extra |
该列包含MySQL解决查询的详细信息
|
这里可以发现:rows 为查询的行数,查询了4w多行,那慢是肯定的了。
因为这里是好几个条件,并且没有使用一个索引,那就只能给添加索引了,
这里给选择添加普通多列索引,因为这个表在最开始设计出问题了,导致有重复的数据,不能设置唯一索引了。
ALTER TABLE app_mobile_device ADD INDEX user_app_type_only ( `user_id` ,`app_type` )
索引设置了,再看下刚的SQL的执行计划。

可以发现rows 的检查行数,很明显的下降了。
到此,慢查询的使用和优化就基本完成了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号