mongoDb CPU利用率100%的分析和解决
在公司的项目中,突然出现过一个情况,mongodb 的CPU利用率到达100%,导致服务器这边卡死了,请求了半天无响应,提示请求超时。
因为,当时APP用户可能会在某一个时间段集中的使用,所以,请求量一下子就飙上去了,刚好APP打开请求的时候,有一个mongodb的请求。
当时因为Mongodb的服务器不在我们这边,所以一下子没反应过来,不过最后还是给排除出,并解决了。这里就来记录下排查和解决的全过程。
问题分析:
1.根据代码,定位到了是Mongodb的报错。
2.进入Mongodb 服务器的监控后台,这里是在阿里云购买的云缓存。
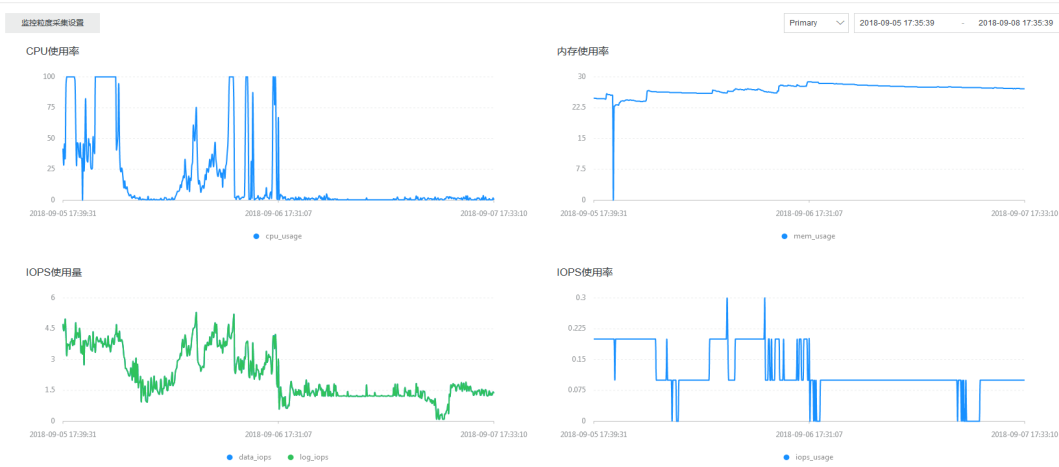
3.知道是Mongodb出问题,就好办了,阿里云里面有个索引推荐,很好用的,会给出查询时间,执行次数,和推荐策略

OK,这里准备工作就基本做完了。
解决策略:
1.根据这些给出的执行次数,和执行时间慢的,去看了下库。从设计上,有问题,一个库有900W的数据,然后集合逻辑看了下,这库只往里面存数据,从不清理
2.没有建立过索引,包括单一索引和连接索引,这也是会导致慢的一个原因。优化后是这样的,
db.getCollection('course_study_history').createIndex({'studentId':1,'contentStudyID':1,'courseWareID':1,'courseStudyId':1})
3.一个查询总数的方法有问题,下面是修改后的JAVA方法:
MongoCollection<Document> collection = database.getCollection(pushMessageCollection);
long cNt = collection.count(Filters.and(Filters.eq("userId", userId),
Filters.eq("sendType", sendType),
Filters.eq("message_read", "0")));
最开始的写法,大概就类型,Mysql 里,查询某个list,然后list.size(),得出总数,
修改后的方法:大概就相当于 count(id) 得出总数,
这样的话,修改后的方法,肯定就会比修改前的快。
方案基本决定下来了,实施后开始压力测试。
没修改时的2000并发:

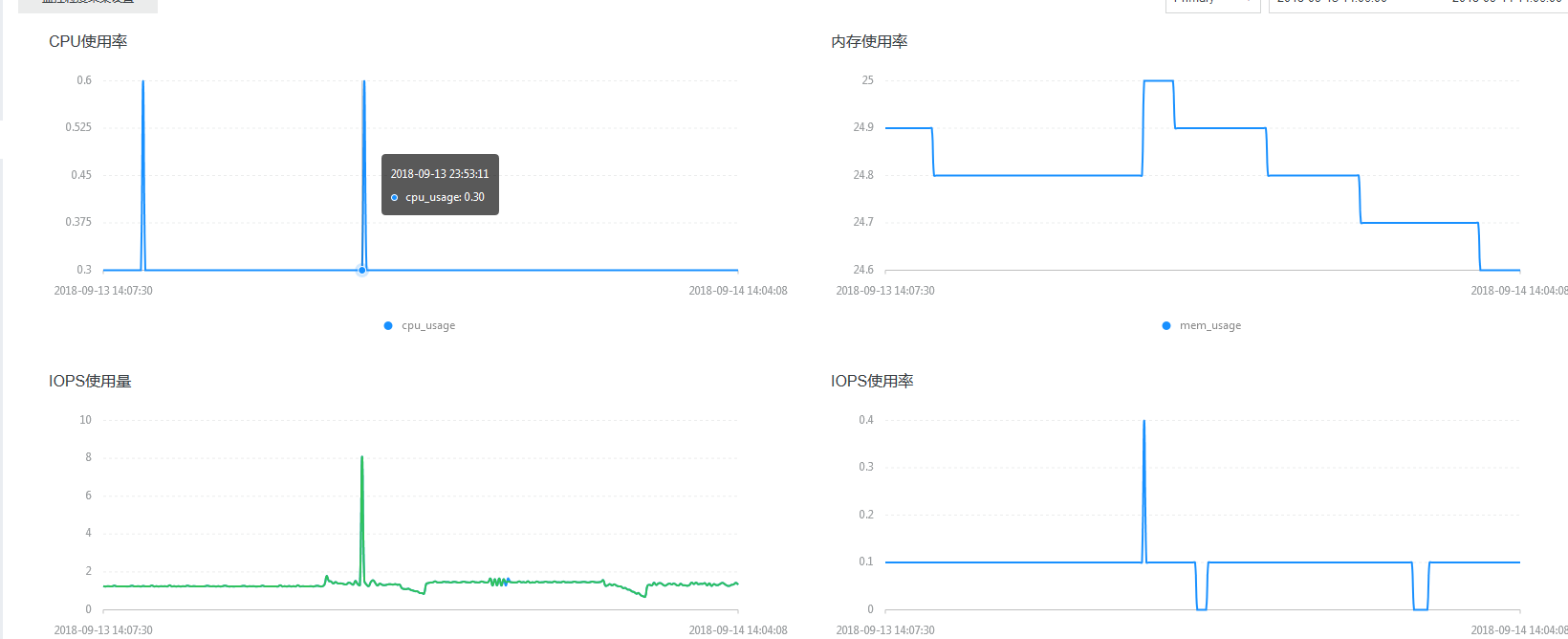
修改后的2000并发:

可以看到时间,也明显的提高了。
并且测试4000 并发,虽然慢了,不过没崩掉。

再查看CPU信息,没有出现100%的情况了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号