
孙晓宇-20180912-3 词频统计
此作业的要求参见[https://edu.cnblogs.com/campus/nenu/2019fall/homework/6583]
代码:https://e.coding.net/sxy504/cipin.git
以下均是我总结出的对我而言的重难点:(1).py文件转化为.exe文件(2)python打开文件;(3)将文件中的标点等特殊符号去掉;(4)统计每个单词的频率并存放在字典;(5)文件数量的查找及文件路径的判断等。
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键盘在控制台下输入命令。
代码:
def rd_file(xgc): try: f = open(xgc, 'r') except IOError as s: print(s) return None bf = f.read() f.close() stat(bf) def stat(bf): if bf: wd_fd = {0} bf = bf.lower() for i in '!"#$%^&*()_+-=~`:;{}[]\|<>,.?/': bf = bf.lower().replace(i, " ") wds = bf.strip().split() a = 0 a += len(wds) print("a:"+str(a)) for wd in wds: wd_fd[wd] = 1 + wd_fd.get(wd, 0) ep(wd_fd)
运行结果:

功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
def reg(rec): i = '.txt' if i in rec: w = rec else: w = rec + '.txt' f = open(w, 'r') bf = f.read() f.close() stat(bf) def ep(wd_fd): if wd_fd: sorted_word_freq = sorted(wd_fd.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: #print(item[0], item[1]) print('%-8s%5d' % (item[0], item[1]))
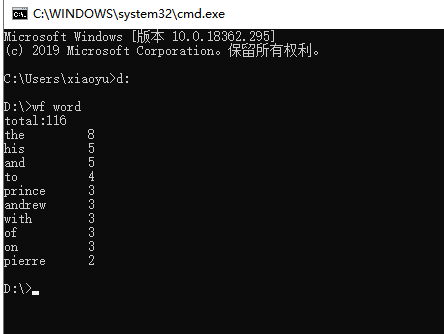
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
代码:
def flnub(x): print(x) a = open(x, 'r') b = a.read() a.close() stat(b)def felt(p): fs = os.listdir(p) for f in fs: if os.path.isfile(f): flnub(f)
执行结果:

功能4还未实现,随着之后的学习争取可以完成
PSP:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号