
Mahout 安装
Mahout是Hadoop的一种高级应用。运行Mahout需要提前安装好Hadoop。
1.下载二进制解压安装包。
到http://labs.renren.com/apache-mirror/mahout/0.9下载,我选择下载二进制包,直接解压即可。
| $:tar -zxvf mahout-distribution-0.9.tar.gz |
2.配置环境变量:在/etc/profile,/home/hadoop/.bashrc中添加如下红色信息
| #set java environment MAHOUT_HOME=/home/hadoop/mahout-distribution-0.9 HADOOP_HOME=/usr/hadoop-2.2.0 JAVA_HOME=/home/jdk1.7.0 PATH=$JAVA_HOME/bin:$MAHOUT_HOME/bin:$HADOOP_HOME/bin:$PATH CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$MAHOUT_HOME/lib:$JAVA_HOME/lib/tools.jar export MAHOUT_HOME export HADOOP_HOME export JAVA_HOME export PATH export CLASSPATH |
3.启动hadoop,也可以用伪分布式测试
4.mahout --help #检查Mahout是否安装完成好,看是否列出一些算法。
5.mahout使用准备
(1).下载一个文件synthetic_control.data,下载地址http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data,并把这个文件放在$MAHOUT_HOME目录下。
(2).启动hadoop:$HADOOP_HOME/bin/start-all.sh
(3).创建测试目录testdata,并把数据导入到这个testdata目录中(这里的目录的名字只能有testdata)
| $:hadoop fs -mkdir testdata $:hadoop fs -put /home/hadoop/mahout-distribution-0.7/synthetic_control.data testdata |
(4).使用kmeans算法(这会运行几分钟)
| $: hadoop jar /home/hadoop/mahout-distribution-0.7/mahout-examples-0.7-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job |
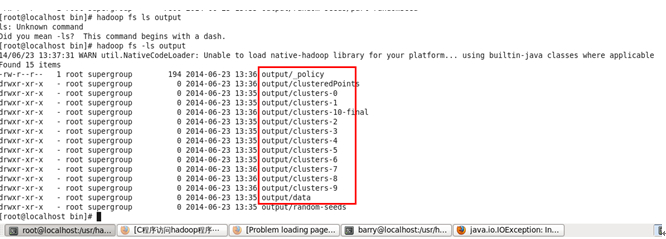
(5). 查看结果
| $:hadoop fs -lsr output |
如果看到以下结果那么算法运行成功,你的安装也就成功了。
| clusteredPoints clusters-0 clusters-1 clusters-10 clusters-2 clusters-3 clusters-4 clusters-5 clusters-6 clusters-7 clusters-8 clusters-9 data |
计算过程:

计算结果下图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号