字符串(单/多)模式匹配/敏感词检测/查重问题(KMP、BM、BF、RK、Sunday、DFA)算法总览
原理说明:https://blog.csdn.net/locahuang/article/details/110186766
C/C++代码实现:https://zhuanlan.zhihu.com/p/625473716
Python代码实现:https://blog.csdn.net/weixin_45616285/article/details/128242976

背景:
字符串匹配问题是最典型的模式匹配问题,是许多文本编辑、数据检索和符号操作问题的重要组成部分,同时在信号处理领域,计算生物学中的序列分析和基因比对,以及OCR(Optical Character Recognition)纠错等领域也都有重要应用。
字符串匹配问题的求解算法总体上包括:动态规划、自动机方法、位并行运算、过滤算法。
字符串匹配(String Match)顾名思义,就是在主字符串中找到与目标字符串(模式串)匹配的操作。分为两类:
单模式串匹配算法,是在一个模式串和一个主串之间进行匹配,也就是说,在一个主串 中查找一个模式串。
如:BF 算法、RK 算法、BM 算法、KMP 算法、Sunday
多模式串匹配算法,就是在多个模式串和一个主串之间做匹配,也就是说, 在一个主串中查找多个模式串。
DFA、AC (Aho-Corasick algorithm)、ACBM (CW)[ A String Matching Algorithm Fast on the Average ]、
WM [Wu and Manber]、ACQS、DAWG (ACRF)、MultiBDM
单模式字符串匹配算法:(BF、RK、BM、KMP、Sunday)
单模式字符串匹配就是单个字符串a和另一个字符串b进行匹配,一般而言,a的长度远大于b,我们在a中查找是否包含b。我们将字符串a称为主串,字符串b称为模式串。
单模式匹配算法按搜索方式可以分为基于前缀搜索(KMP),基于后缀搜索(BM)和基于子串搜索(BDM)三种方式。
常见的算法(BF、RK、BM、KMP、Sunday)。
所谓单模式匹配问题,就是在一个大文本/主串(text)T=t1t2...tn 中找到某个特定的模式串(pattern)P=p1p2p3...pm出现的位置,文本长度为n,模式串长度为m,
其中T和P都是在有限字母表(alphabet)∑的字符序列,大小为δ。设x、y、z为模式串,则x为xy的前缀,x为yx的后缀,x为yxz的一个因子或子串。
如果存在两个字u和v使得w=uz=zv,则z是w的边界(border),是w的前缀也是它的后缀。注意在这种情况下|u|=|v|,并且它们是w的一个period。
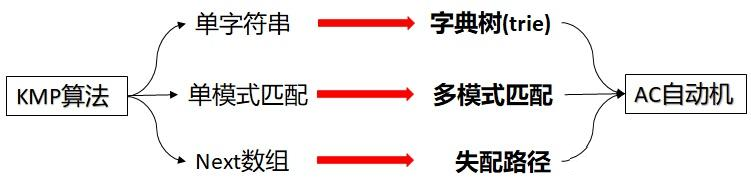
多模式字符串匹配算法:Aho-Corasick算法(AC自动机)(Trie树 + DFA)
多字符串匹配即指一次从整个文本串中同时找多个模式串,实际上多字符串匹配算法的指导思想都是从单字符匹配过度而来。
AC 自动机本名叫做 Aho-Corasick Automaton。AC 自动机就是 KMP算法 与 Trie 树的结合体,基于前缀搜索的非压缩字典树。
一、BF(Brute Force)算法
时间复杂度较高:O ( m ∗ n ), 与主串和模式串的长度都正相关,其中,m 是匹配字符串(模式串)s的长度,n 是被匹配文本(主串)t的长度
空间复杂度:O ( 1 )
又名(暴力匹配法)朴素字符串匹配算法。是最简单粗暴的字符串匹配算法之一,对主串和模式串进行逐个字符比较。
它的思想是将模式串 P 逐个字符与文本串 T 中的子串进行比较,如果匹配失败则将模式串向右移动一位,直到找到匹配的位置或者遍历整个文本串。
二、BM (Boyer-Moore)算法
时间复杂度: O ( n / m ),最坏 O ( m ∗ n )。
空间复杂度: O ( m )。
又名“精确字符集算法”,该算法的核心思想是借助“坏字符规则”和“好后缀规则”,在每一轮比较时,让模式串尽可能多挪动几位,利用模式串中的信息来跳过尽可能多的文本字符,减少了BF算法中很多无谓的比较,从而达到快速匹配的目的。
BM 算法的优点是在最坏情况下的时间复杂度为 O(m+n),其中 m 和 n 分别为模式串和文本串的长度,而且实际应用中通常比 KMP 算法更快。
BM 算法主要分为两个部分:预处理和匹配。预处理阶段的目的是计算模式串中每个字符在模式串中最右边出现的位置,以此来确定匹配时应该移动的距离。匹配阶段则是从文本串的末尾开始匹配,根据预处理阶段得到的跳跃表来决定下一步应该移动的距离。
三、RK(Rabin-Karp)算法
时间复杂度: O ( n )。其中文本串 S 的长度为 n ,模式串 P 的长度为 m 。
空间复杂度: O ( 1 ) 。
基于 哈希算法 的 BF算法优化方案。它使用哈希函数对文本串中的子串进行哈希计算,并与模式串的哈希值进行比较,以确定它们是否匹配。
它的基本思想是将模式串和文本串中长度相同的子串看作一个数,在模式串和文本串中分别计算这个数的哈希值,然后比较这两个哈希值是否相等,以此来判断是否匹配。
由于哈希值的计算速度比字符串的比较速度要快得多,所以 RK 算法的效率比 BF 算法高。
四、Sunday
时间复杂度: 最坏情况:O ( n ∗ m ) ,平均情况:O ( n )
空间复杂度: O ( s )。 为偏移表长度。
五、KMP (Kunth-Morris-Pratt )算法
时间复杂度: O ( n + m ),其中 n 是字符串 haystack的长度,m 是字符串 needle 的长度。我们至多需要遍历两字符串一次。
空间复杂度: O ( m ),其中 m 是字符串 needle 的长度。我们只需要保存字符串 needle 的前缀列表 next。
该算法的核心思想是在匹配过程中利用已经匹配过的信息来跳过尽可能多的文本字符,从而达到快速匹配的目的。相比于朴素的字符串匹配算法,KMP算法具有时间复杂度低、实现简单等优点,在实际应用中得到了广泛的应用。
KMP算法的核心是使用动态规划的方法,计算模式串的前缀函数。
六、DFA(Deterministic Finite Automaton)
即确定有穷/有限自动机。其特征为:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,DFA中不会有从同一状态出发的两条边标志有相同的符号。敏感词过滤很适合用DFA算法,用户每次输入都是状态的切换,如果出现敏感词,即是终态,就可以结束判断。我们把数组形式的敏感词整理为一个树状结构,准确的说是一个森林
KMP算法的本质,是在遍历字符串和模式串至不匹配字符之前,已经积累了一定的匹配信息。Knuth, Morris & Pratt发现,利用 确定有限状态自动机(Determinstic Finite Automata, DFA)
可以有效地复用这些信息,达到一个模式串 p 对应一个DFA、构建一次即可在任何文本中重复使用的效果。
e.g. https://www.cnblogs.com/black/p/5171702.html
七、AC自动机
AC自动机(Aho-Corasick automation),又称 trie图,是一种DFA, 该算法在1975年产生于贝尔实验室,是著名的多模匹配算法之一。解决的问题:一个常见的例子就是给出 n 个单词,再给出一段包含m个字符的文章,让你找出有多少个单词在文章里出现过。
要搞懂AC自动机,先得有字典树Trie和KMP模式匹配算法的基础知识。
AC自动机的构造:
1.建立一棵字典树Trie,作为ac自动机的搜索数据结构。
2.构造fail指针,给Trie 添加失败路径,使当前字符失配时跳转到具有最长公共前后缀的字符继续匹配。
3.根据AC自动机扫描主串进行匹配。
e.g. https://www.cnblogs.com/feiquan/p/11725982.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号