java 数据集合类
Collection
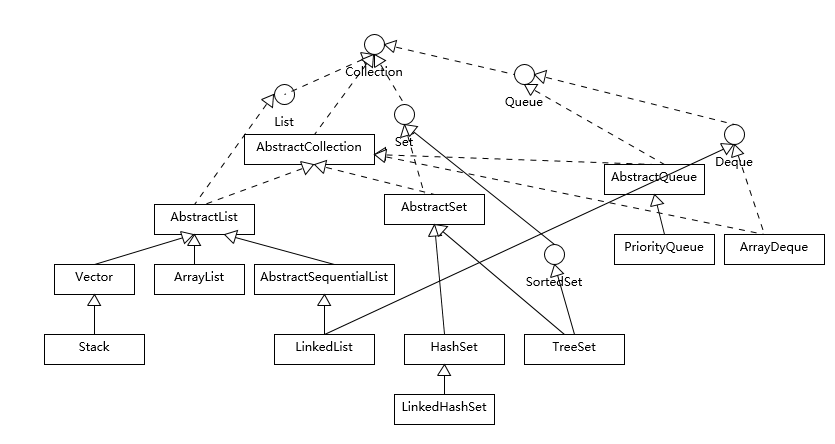
其中Tree和Linked前置代表该集合是有序的,Linked可以按照插入的顺序进行访问,Tree则是可以根据键值或者元素值的大小关系,因为其本地是红黑树,就是根据插入数值进行排序的。
而Hash前缀则代表存储的位置顺序是经过hash计算过的,就不能保证元素的插入顺序,但是元素的访问速度很快,因为本质上是存储在数组上的。
而LinkedHash则是数组和链表的复合结构,实际元素是存储在链表中的,这个保证了顺序,同时又有一个保存链表元素对象的引用数组,做到可以快速访问到指定的元素。
Collections
各种集合的工具类。提供的方法主要分为以下几个功能
添加元素
public static <T> boolean addAll(Collection<? super T> c, T... elements)
查找元素
int binarySearch(List<? extends Comparable<? super T>> list, T key)
创建类型检查的集合
public static <E> List<E> checkedList(List<E> list, Class<E> type)
创建空集合,单元素集合,不可变集合,线程安全集合等等
sort集合,翻转,交换集合元素等等
sort
底层采取的排序算法,根据元素个数的不同选取不同的排序算法
- 当元素个数小于47时,采用插入排序
- 当元素个数大于47,小于286时,采用快速排序
- 当元素个数大于286时,采用归并排序
https://www.cnblogs.com/baichunyu/p/11935995.html
Arrays
Arrays是一个单独的类,并没有继承Collection接口,相当于列表的一个工具类
Map

map相关类和其他集合类(List,Set等)的接口并不一致。map类继承自Map接口,而其他集合类继承自Collection接口,Collection接口继承自Iterable接口。凡是被Iterable接口修饰的类都是可以得到对应Iterator接口实现迭代遍历的。
遍历map
在java8之前,map类(比如hashmap)并不能实现自己的遍历,只能通过转化为Set<Entry>,Set<key>,Set<value>进行遍历。java新增了foreach的迭代方法,可以不用再转为set对象进行迭代了
HashMap<String, String> hashMap = new HashMap<>(); //方法一 hashMap.forEach((key, value) -> {}); //方法二 for (Entry<String, String> entry : hashMap.entrySet()) { } //方法三,遍历key,再通过key得到对应键值 for(String key : hashMap.keySet()) { } //方法四,直接遍历value for(String value : hashMap.values()) { }
遍历时修改集合
Collection接口的集合类在遍历的时候并不能进行删除和添加操作,否则就会报ConcurrentModificationException的异常,例如进行下面的遍历操作都会报错
ArrayList<String> list = new ArrayList<>(); list.add("ele1"); list.add("ele2"); list.add("ele3"); list.add("ele4"); list.add("ele5"); list.add("ele6"); //遍历一报错 list.forEach(ele -> list.remove(ele)); //遍历二报错 for (String entry : list) { list.remove(entry); } //遍历三报错 Iterator<String> ite = list.iterator(); while (ite.hasNext()) { String value = ite.next(); list.remove(value); } //遍历四不会报错,调用迭代器的删除方法 Iterator<String> iter = list.iterator(); while (iter.hasNext()) { String value = iter.next(); iter.remove(); }
因此要修改还必须依赖迭代器的删除方法。
关于产生ConcurrentModificationException报错的原因,请查看下面的文章分析:
https://www.cnblogs.com/zhuyeshen/p/10956822.html
https://blog.csdn.net/tttzzztttzzz/article/details/87556048
HashMap实现
初始化
hashmap时lazy-load方式,执行构造函数时只会设置初始容量和负载系数。
负载系统默认是0.75,这是查找和插入操作的最佳平衡点,如果过高,则容易发生hash冲突,造成同一hash值对应的链表长度过长,影响查找效率;如果过低,则会造成hash过于稀疏,浪费空间。
插入操作
hashmap是在插入第一个元素时确定容量和分配空间的,初始容量并不是真实的容量,容量都是略大于初始容量的二的幂次方。这是为了减少hash冲突,这里就要说一下hashmap的hash算法。先得到key值对应的hash值,然后将hash值左移16位,然后再与容量-1进行位的异或操作.
将hash值左移16位是因为hash的低16位更容易发生hash冲突,所以要利用高16位,而容量-1对应的每个二进制位都是1。这样在计算hash值时,能够最大限度的减少hash冲突。
数据结构
主体是数组类型,元素类型是key-value的Node类型链表。hash冲突的元素都会被放置到同一个链表中,但是如果链表长度过长就会影响查找效率,因此在Java1.8中,如果链表长度大于8,就自动将链表转化为红黑树。转化为红黑树后,插入操作会有影响,涉及到树的平衡操作。
resize操作
hashmap内部有一个门限值,其值为容量乘以负载系数。当hashmap的长度超过门限值时就会执行resize。resize的长度是将当前数组的长度扩大两倍,然后每个元素重新计算hash值确定新的位置,但因为是位操作,所以新的索引位置是由原来key的有效hash值左移一位决定的。如果该位值是0,则在新数组中的索引位置不变;如果是1,则新的索引位置是原索引加上原数组长度。
resize问题
https://mp.weixin.qq.com/s/VtIpj-uuxFj5Bf6TmTJMTw
Java1.7
多线程下对线程进行扩容的时候会造成链表的循环引用和数据丢失,这是因为在链表中添加新元素的时候,总是把它加在链表头部。
Java1.8
在1.8中就改成了链表尾部,既避免了循环应用,也因为要检查链表的长度,当长度超过8时,会将链表转化为一个红黑树。
但是可能会发生数据覆盖的问题
还可能会在红黑树平衡转换过程中
ConcurrentHashMap实现
Java1.7
put加锁
通过分段加锁segment,一个hashmap里有若干个segment,每个segment里有若干个桶,桶里存放K-V形式的链表,put数据时通过key哈希得到该元素要添加到的segment,然后对segment进行加锁,然后在哈希,计算得到给元素要添加到的桶,然后遍历桶中的链表,替换或新增节点到桶中
size
分段计算两次,两次结果相同则返回,否则对所以段加锁重新计算
Java1.8
put
CAS 加锁
1.8中不依赖与segment加锁,segment数量与桶数量一致;
首先判断容器是否为空,为空则进行初始化利用volatile的sizeCtl作为互斥手段,如果发现竞争性的初始化,就暂停在那里,等待条件恢复,否则利用CAS设置排他标志(U.compareAndSwapInt(this,
SIZECTL, sc, -1));否则重试
对key hash计算得到该key存放的桶位置,判断该桶是否为空,为空则利用CAS设置新节点
否则使用synchronize加锁,遍历桶中数据,替换或新增加点到桶中
最后判断是否需要转为红黑树,转换之前判断是否需要扩容
get
https://mp.weixin.qq.com/s/5I6a2ab7dkO4XOnJ5Q3x4w
不加锁读取,保证高性能
通过volatile关键字来保证扩容时的实时可见性
size
利用LongAdd累加计算
上面的集合对象都不支持在直接遍历元素时,进行添加和删除操作,但是ConcurrentHashMap可以在遍历时进行更新操作。但并不能保证实时更新,本次遍历添加的元素可能不会在本次遍历出来,只能在下次才能遍历出来。详细说明如下:
https://www.cnblogs.com/williamjie/p/9099861.html
https://www.jianshu.com/p/d10256f0ebea
https://www.cnblogs.com/zhuawang/p/4779649.html
https://www.cnblogs.com/heqiyoujing/p/10928423.html
https://blog.csdn.net/killalllsd/article/details/83607945
死循环
https://mp.weixin.qq.com/s/xGOTupzskUmzhTaiG4tJmw
嵌套使用computeIfAbsent会造成死循环,jdk1.9已经修复


 浙公网安备 33010602011771号
浙公网安备 33010602011771号