
练习第一篇 Python Requests使用
前面用到的python库urllib
上篇讲的是urlib 抓网页的点击事件
这篇用的库是Requests抓取网页点击事件
import requests import re str = { '__VIEWSTATE': 'i8VVE3gtBLKgjBpYFwMCruW86sOjv2lTpmzZF3mD3L/QIkX0Ode3Xc9MaMXFQnjiAK80xxkQ9rjTyjGrBWvbLwcxug4r9Akhmcxs/plCdYM=', '__VIEWSTATEGENERATOR':'B6E7D48B', '__EVENTVALIDATION':'2X6ageL+LlYeiTSgyQPd/FPAhPtg350MNiiKvURoS4xMsysX+0HyGjGN93yx7K27/NubbDHt2oTpWbFCv1dampTLrZkWvsf32lHlqJUliAsudoGhZ3kwM/XCxXSlvhNr', 'Button1':'Button' } url = "http://192.168.21.195:8044/WebForm1" response = requests.post(url,data=str) resstr=response.text new_st = re.sub(r'<[^>]*>','',resstr) print(new_st.split())
运行结果
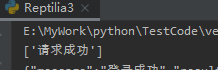
自己抓自己发布的网页程序感觉没什么挑战的。
换点别的操作,模拟某网站人工登录。
1,先用浏览器抓个包

code:
import json
import requests
headers={
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'
}
str = {'trafree_username':'帐号','trafree_password':'密码','isRemember':False}
data = json.dumps(str)
data = bytes('json=' +data, 'utf-8')
# str = {'json': {'trafree_username':'帐号','trafree_password':'密码','isRemember':False}}
#
# data = json.dumps(str)
# data = bytes(data, 'utf-8')
url = "http://www.trafree.com/platform/agentuser/login"
# 写法1
# response = requests.post(url, data=data,headers=headers)
# 写法2
response = requests.request('POST', url=url ,data=data,headers=headers)
# response = requests.post(url, data=data)
# print(response)
print(response.text)
# print(response.content)
运行结果:

为什么不带头文件不行
response = requests.post(url, data=data)
debug调试发现 request的请求头是
{'User-Agent': 'python-requests/2.23.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'Content-Length': '94'}
response = requests.post(url, data=data,headers=headers)
这段代码执行的 request的请求头是
{'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
比对浏览器抓的包分析就知道怎么设置请求了。


