LLM并行训练6-激活优化
前置知识
Activation
激活指的是一些在fp时计算得到的临时tensor, 会用于bp时的计算. 如果能在fp计算后把临时tensor缓存下来就可以加速bp, 缺点在于激活会占用大量显存. 以一层transformer结构为例分析下各层存在的激活.

简单部分的分析这里忽略. 主要分析下几个不好理解的计算:
- \(QK^T\): 需要缓存Q输出和K输出 \(2sbh+2sbh\)
- \(softmax\): a个head, 每个head进行s次softmax概率分类, 一共有b*s个token, 输出为fp16, 所以是\(2 * a * s * (s * b) = 2as^2b\)
- \(dropout\): 需要缓存一个mask数组标记哪些位置的token需要被反向更新. 所以每个位置只需要bool, 所以是\(a * s * (s * b) = as^2b\)
如果激活的临时显存全部不释放, 每个transformerLayer需要占用的量级为\(sbh(34+5\frac{as}{h})\) (不包含任何并行加速的情况)

选择性激活重计算
重计算部分: 以GPT-3为例: a = 96, s = 2048, and h = 12288, 5as/h = 80. 占了总激活显存的70%左右的主要是attention里的部分比如: softmax的输出, dropout的mask, dropout的输出. 这些部分的激活都跟矩阵乘法没关系, 所需要的计算量很小. 把这些在前向计算完之后直接释放显存, 在bp用的时候再重计算的话就能以很小的计算代价换取70%的显存存储.
拆分存储部分: 而比如像线性层的中间输出, Q,K,V这些中间tensor. 因为前面有一个和W的矩阵乘法, 重计算代价巨大更适合临时缓存起来用于bp计算复用. 这些激活通过张量并行和序列并行把他们拆分存储, 在bp使用的时候通过集合通信的方式再拉取, 来减少显存消耗.
张量并行共计24sbh: 并行后拆分为t份的包括:
- attention部分: QKV的输入2sbh, \(QK^T\)结果4sbh, 和V相乘结果里的2sbh. 共计8sbh
- MLP部分: 两个8sbh, 因为TP的先列在行的计算方法全部平分成了t份, 共计16sbh

序列并行共计10sbh, 拆分成t份的包括:
- attention部分: layerNorm的输入输出4sbh, dropout的mask sbh
- MLP部分: layerNorm的输入输出4sbh, dropout的mask sbh
序列并行
序列并行指的是在 Transformer 层的非张量并行切分部分,计算在序列维度(s)是独立的. 所以在这个维度上以切分数量和张量并行数相同的方式进行切分.
为什么切分数要和TP相等呢? 回忆下TP后如何汇聚计算结果, 在行并行后allReduce, 把每张卡各自计算的结果纵向拼起来还原成完整的输入. 如果我们想把这部分完整的输入进行切分存储, 如果切分数量和TP不一致意味着在$\bar{g} $ 这个地方在allReduce之后还要再进行一次reduceScatter进行分割, 在\(g\)地方再allGather..
而如果切分数和TP相等, 在\(\bar{g}\)这里可以把allReduce直接省掉, 相当于把allReduce拆分的两个操作. 在通信量保持不变的情况下分离了layerNorm的激活

Ring-attention
原理
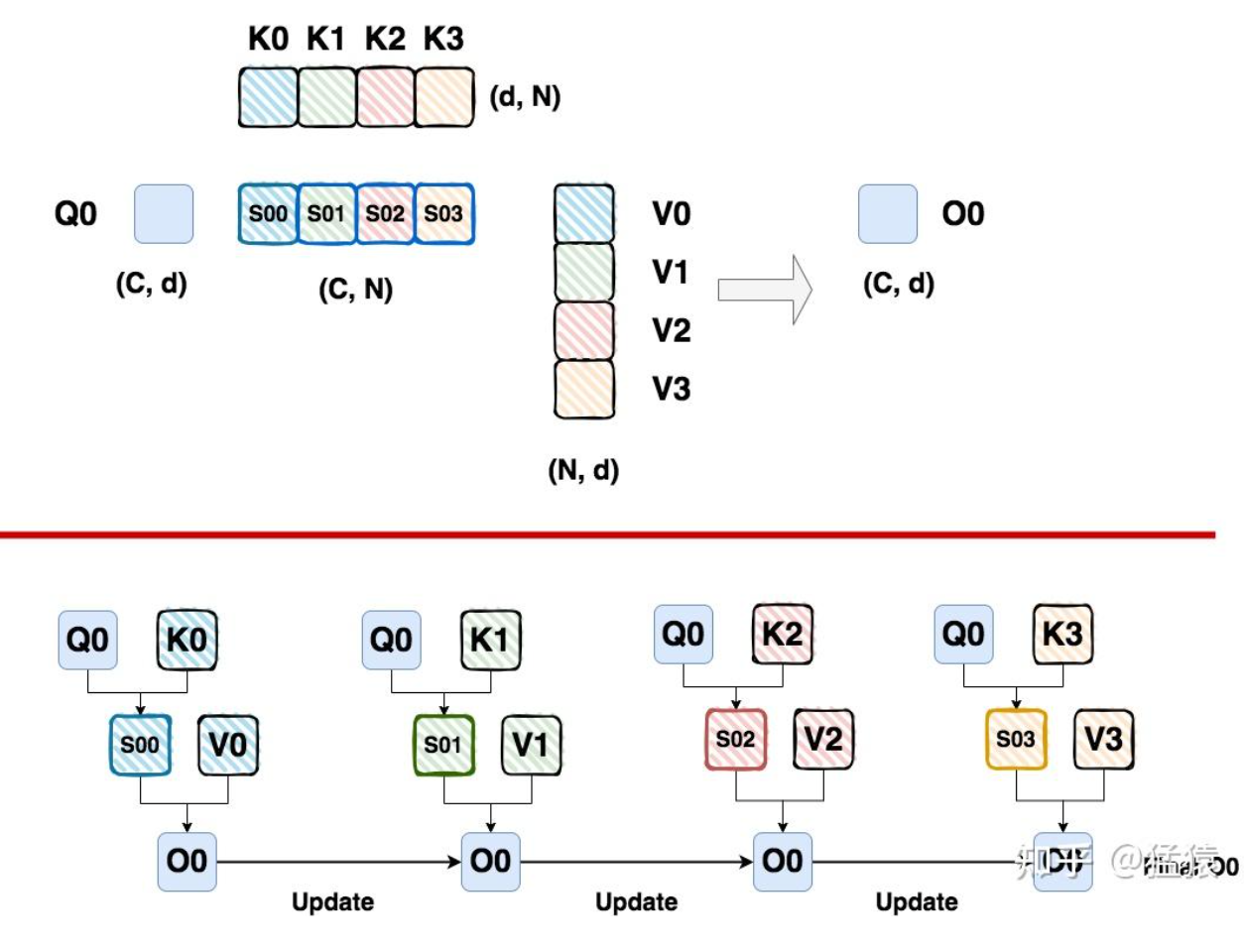
类似于分布式版本的FlashAttention
计算步骤:
- 切分Q为若干个块, 作为外循环
- 内循环K/V, 依次与Q0相乘后, 通过safe_softmax的方式更新O0, 当遍历完所有的K/V切分块后, 就拿到了最后的输出
- K/V的切分顺序不重要, 因为只和当前的max和sum有关系. 而当计算上图的S00与V0这部分的时候, 其实显存里存储K1-3/V1-3是没有必要的. 这也是ring-attention要优化的部分
实现
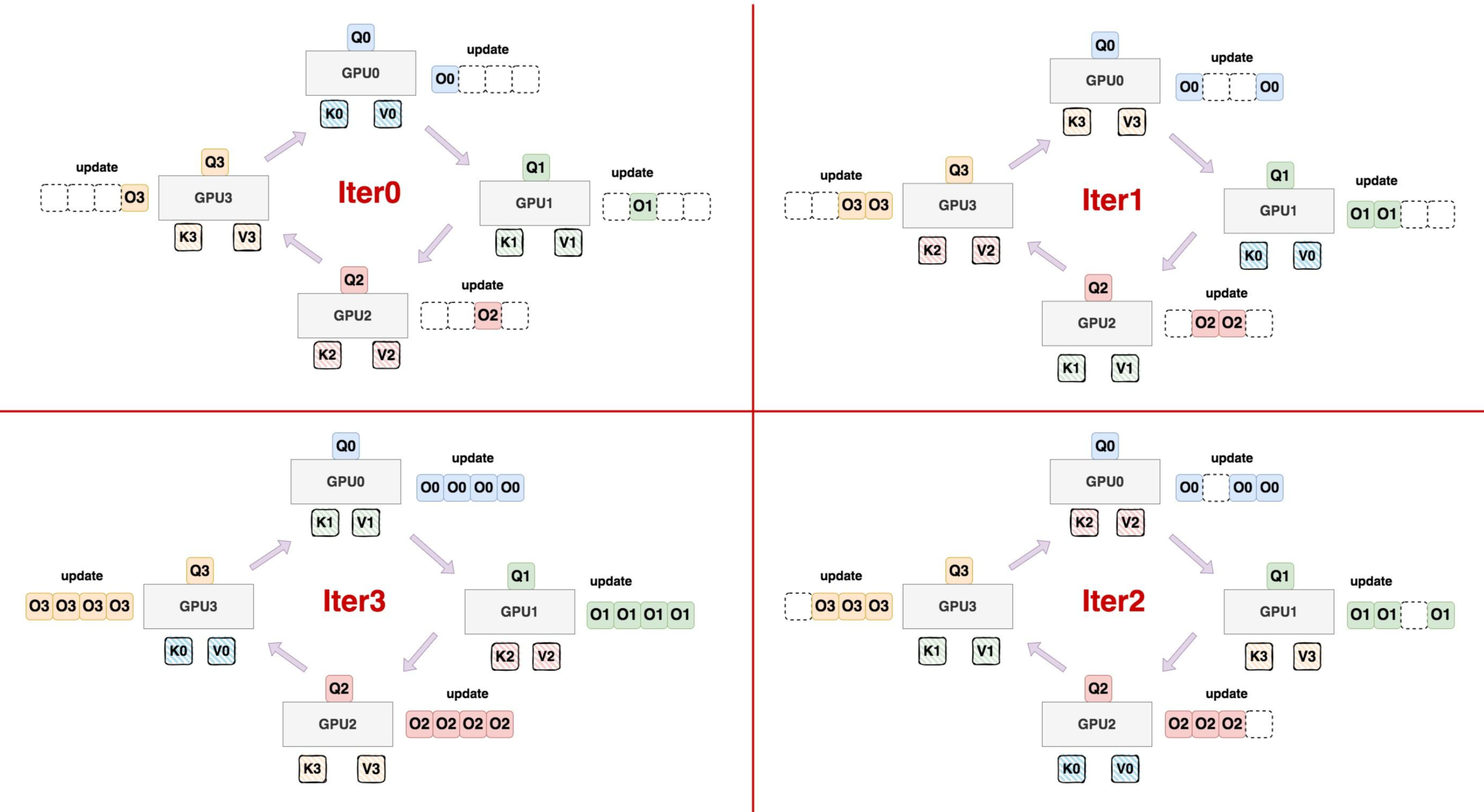
以上图为例, 为了把计算Q0/K0/V0时, 其他冗余的K/V驱逐出显存用于节省显存, 在4块GPU的系统里每张卡上只保存1/4的Q/K/V. 计算步骤:
- 第一次迭代时, 每张卡计算对应的 \(Q_i, K_i, V_i\)乘积, 显存里维护一个\(O_i\)结果
- 把已经算完的K/V块发送给环中的下一个节点, 同时接收上一个节点传过来的K/V块, 计算更新\(O_i\)
- 当每个K/V块都完成环中的循环后, 整个计算完成. 而且计算和通信可以异步进行从而实现overlap隐藏通信.
Megatron Context Parallelism
这个设计思路主要是为了解决ring-attention中的负载不均衡问题, 当训练采用casual mask时, 每个token实际只需要计算他和他之前的token的attention, 他之后的计算属于无效计算量. 而ring-attention 无法解决冗余计算的问题, 也就是从GPU0->GPU3的算力浪费是从多到少分布的.
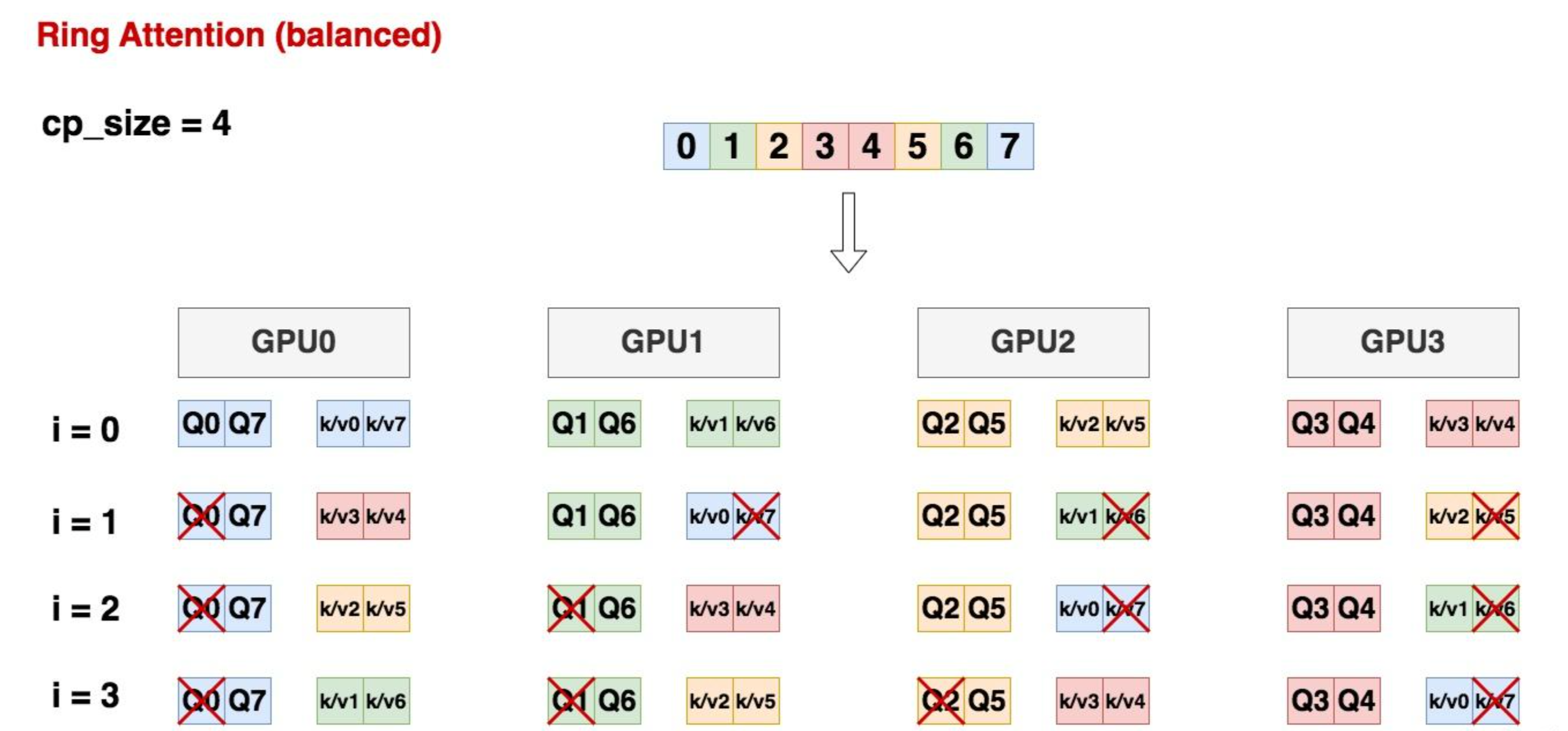
如上图把Q/K/V均分成8份, 由4个GPU组成ring, 计算步骤和ring-attention一致, 但计算量一致, i = 0时,每张卡上都是4个块在做attn计算, i = 1/2/3时,每张卡上都是3个块在做attn计算, 各卡计算量保持一致
Zero-R
激活分区 & checkpointing
这里提到在模型并行的时候activation会存在冗余副本. 这里应该就是指的是TP输入的冗余副本. 论文里是说到会把激活给partition多份..其实我感觉实现方法和megatron里的序列并行就是一样的, 标记一下等细看deepspeed代码的时候再确认下.
另外还提到个新方法利用内存来存激活checkpoint, 想了下应该是类似下图的步骤
- 在最初始的几层fp和bp的时间间隔比较远, 适合在做完fp后memcpyAsync到内存.
- 靠近loss的后面几层激活还存在显存里, 在bp的时候直接用完就释放了. 快到cpu激活的部分通过memcpyAsync回来.
- 如果训练和copy激活能使用同一个stream, 那么这块就不需要同步, 按流的顺序实行即可

恒定大小显存缓冲区
像all-reduce这些集合通信操作, 在一次通信一批很大的数据效率很高. 但缺点是会分配大量的临时显存, 这样会导致显存出现较大波动, 在大模型场景会出现问题.
所以zero在这块设定了一个固定的buffer_size, 超过buffer_size的时候分批次通信. cpu激活checkpointing的copy应该也需要相应的方式.
其实在写flux-gpu的sparse拷贝的时候也用了类似的方法..分批次拷贝来避免单次的超大通信和小数据的碎片通信.
显存碎片解决方法
显存碎片产生的原因: 在fp的时候只有一部分激活储存下来用于bp, 另外一些需要在bp重算的激活被释放了.就会导致一部分显存的使用周期很长, 另一部分很短, 从而产生显存碎片. 会导致两个问题: 1. 显存allocator查找满足大小的显存块效率很低 2. 可能会出现大块连续显存分配不出来.
论文里说会给activation和grad预分配好连续显存块..emm, 这个做法看着和llm.c里的实现是一样的, 其实在大模型里大部分的w/grad/activation在运行的时候都是定长的, 我们完全可以在第一次运行的时候全部分配好. 在网络计算的时候避免显存分配. 如果不使用allocator就不会有碎片问题.
Zero-Offload
主要用来解决模型规模远大于显存规模的问题, 看着灰常似曾相识, 和部署在本地内存的参数服务器很像. 感觉区别在于2点: 1. 训练是同步的, gpu在cpu更新optimizer_state的时候只能处于等待状态 2.内存里保存全量的参数, 不进行多机通信(多机通信应该会让本来就慢的cpu更加雪上加霜吧haha).
计算策略
- 保证 CPU 的计算负担远远小于 GPU,从而防止 CPU 成为计算瓶颈;保证 GPU 的内存节省最大;(optimizer_state是最占显存的同时, 也是不需要反复计算的, 一个batch里只需要存取一次, 不像fp16的w一样还会参与反向的梯度计算)
- 保证 CPU 和 GPU 之间的通信量最小;(在通信的时候进行量化和反量化)

调度策略
offload采用的是zero2方案, 也就是fp16 w是分卡存储的. 考虑使用zero2的很重要的一个原因我猜测是在于多卡可以同时copy w, 而且没有冗余数据通信. 避免pciE带宽拖后腿.
下图是单卡的数据流, swap的部分论文里画错了应该是CPU->GPU, 通信和计算异步的地方主要有2处:
- g offload, 是在gpu bp的时候每计算完一层的g就async copy到内存
- p swap, cpu更新完一批w, 就分块进行量化和async copy到显存.

Fp16 w到了显存里后就和不同的zero2计算流程完全一样了.
后面还有一个和推荐模型cpu异步训练类似的cpu操作全隐藏训练模式, 只不过区别是把异步训练的n个batch对齐dense改成了固定1个batch.

Zero-Offload++
在第一版offload的时候, 所有的参数都是在cpu计算的, 上面也说到了. 在cpu计算的时候gpu只能空等, 如何在空等的时间窗口把gpu利用起来是一个很大的问题. offload++给了一个很棒的思路. 设置了一个os_w的存储比例, 以图示为例, 有40%的os_w存在内存里由cpu更新, 剩下的60%由gpu更新. 步骤如下:
- 在bp完靠上层40%的网络后, 把g往内存copy
- CPU开始逐步计算已经拉下来的g, 更新os_w. 把属于自己更新的那部分算完
- 到达属于GPU更新的部分后, GPU Scatter 剩下的60% grad到os_w存储的对应卡上, 更新显存里的os_w
- 等cpu算完后量化的fp16_w copy回显存和显存里的fp16_w合并, 进行下一轮计算

这里的比值是人工设置的, 设置原理就是在尽量把显存用满的前提下尽可能的往GPU塞os_w, 塞不下的再放内存里. 这个思路感觉超棒, 待细看代码
参考
Megatron-LM论文: https://arxiv.org/pdf/2205.05198
zero-R论文: https://arxiv.org/abs/1910.02054
zero-offload: https://www.usenix.org/system/files/atc21-ren-jie.pdf
zero-offload++博客: https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-offloadpp
ring-attention: https://zhuanlan.zhihu.com/p/4963530231

 浙公网安备 33010602011771号
浙公网安备 33010602011771号