cuda程序优化-3.通信简介
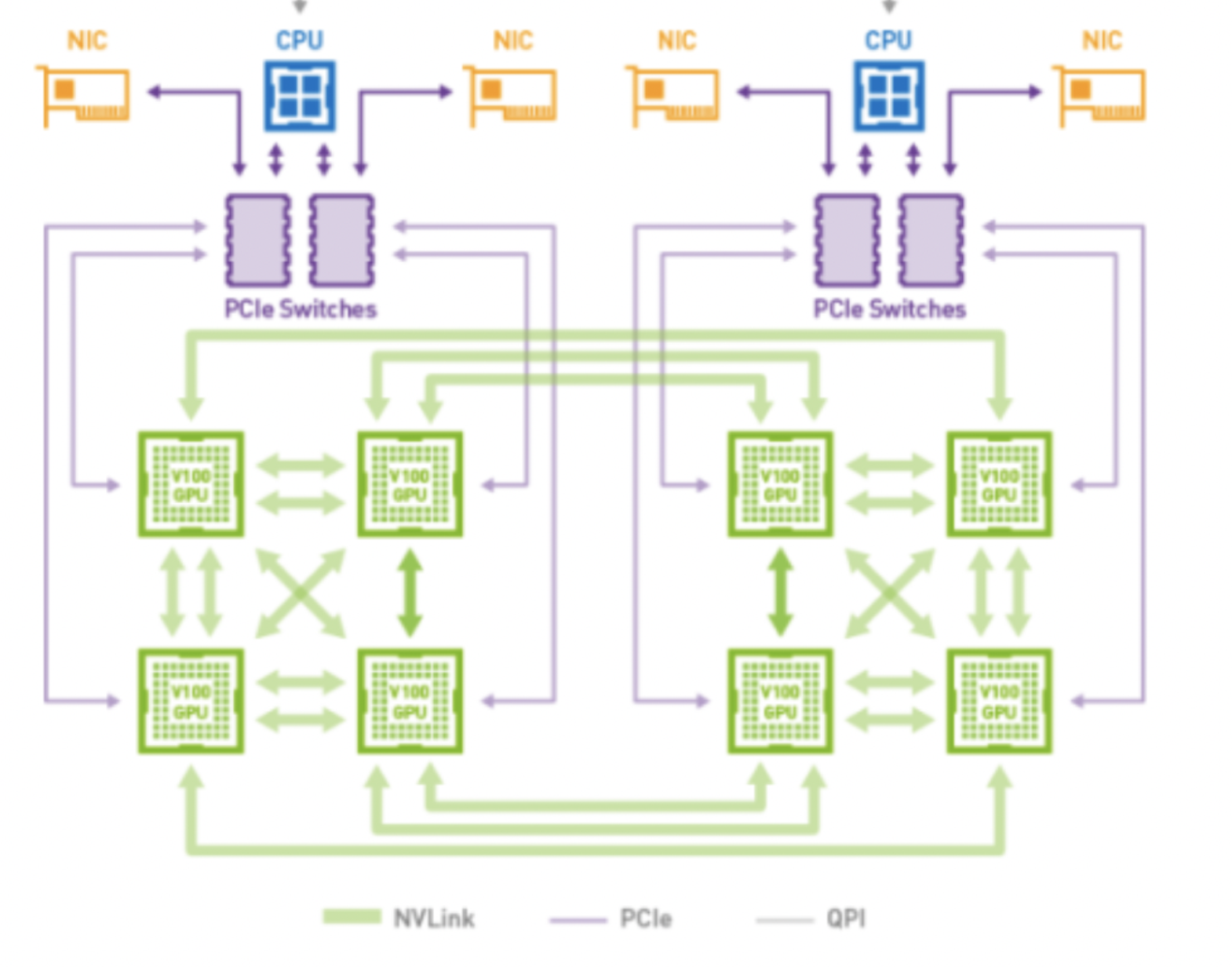
硬件结构
CPU<->GPU: 通过PCIe进行通信
GPU<->GPU: NVLink, 通过Switch桥接器辅助访问其他卡的HBM
多机通信: InfiniBand with GPU Direct RDMA(简称GDRDMA), 需要专用网卡
卡间通信-Ring AllReduce
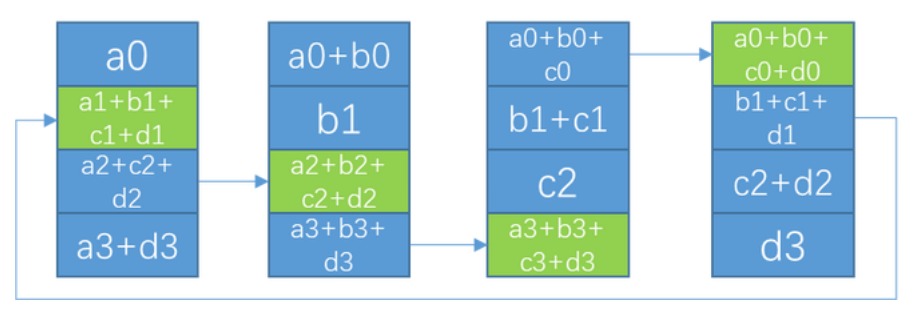
1. 初始状态
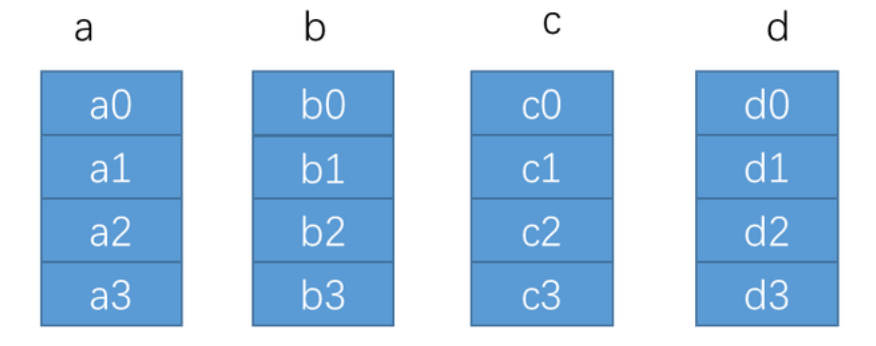
卡数: N(该图为4), 总数据量为K.
在RingAllreduce算法中, 会进行2*(N-1)次通信, 单节点通信总量为 N*K-N/K, 首先会把单卡上的数据平均分成N份
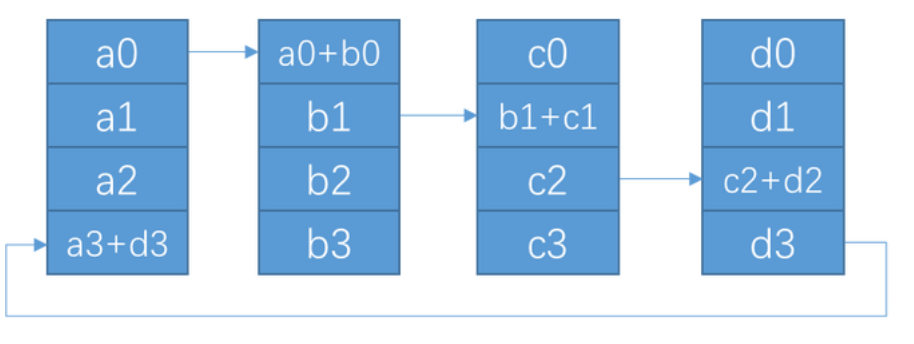
2. Scatter
在scatter阶段, 会进行(N-1)次通信, 每次通信量为 K/N, 单节点通信总量为 (K/N)*(N-1) = K-N/K
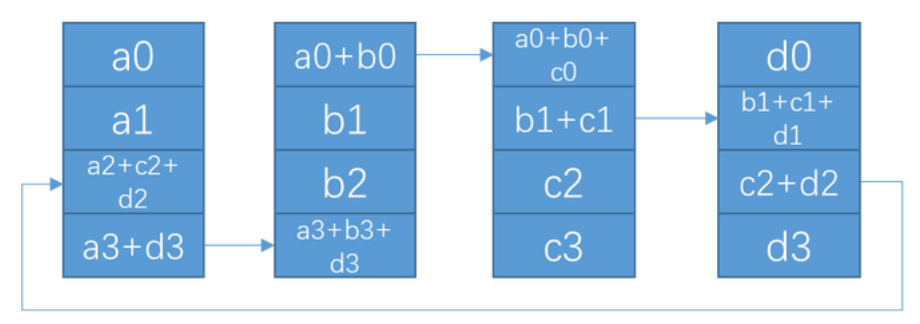
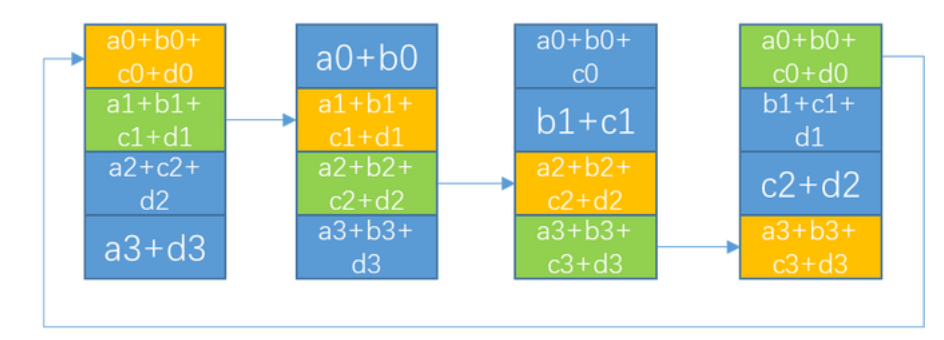
3.Allgather
在Allgather阶段, 会进行(N-1)次通信, 每次通信量为K, 单节点通信总量为K*(N-1)
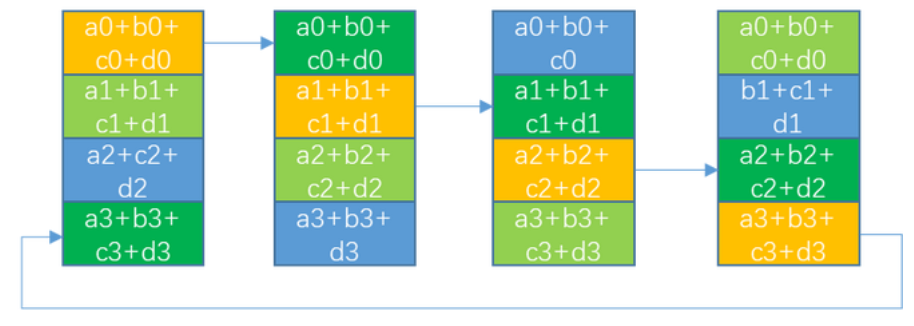
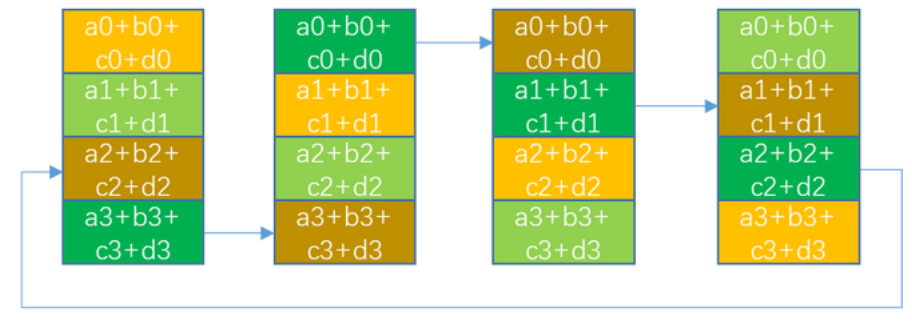
多机通信-Double Binary Tree(DBT)
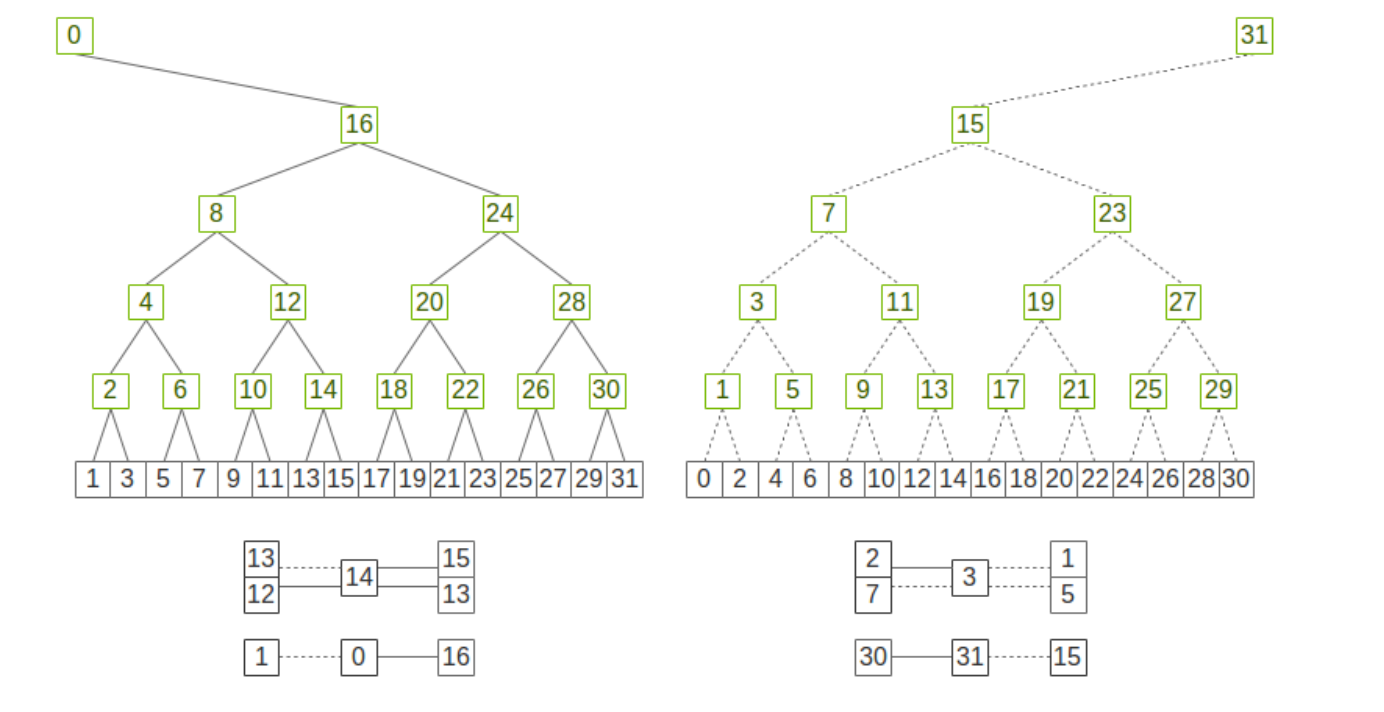
以上图为例, 整个集群有32个节点需要进行AllReduce, 这里每个节点代表一台server, 这个算法中每个节点最多成为一次叶节点和另一颗树的非叶节点. (比如节点3, 在右边子树里, 接受来自1,5的reduce数据, 再发给父节点7, 而在左子树里作为叶节点把单机RingAllreduce的结果发送给2) 这种结构保证了每个节点都能从2个子节点接收和发送数据,也都能向2个父节点发送和接收数据。
在并行通信方面, 因为2棵树的数据来源不同, 使得可以2棵树的通信可以完全流水线并行, 在单棵树内当叶节点完成节点内的RingAllReduce+send出去后, 他自身就变成了完全空闲的状态, 得等多层父节点类似于fp/bp的方式把reduce结果给广播回来, 而在这段等待的时间内, 节点3可以作为另一颗树的父节点来参与数据通信. 这样就能很好的平衡每个节点的通信量和负载, 从而达到流水线并行的目的
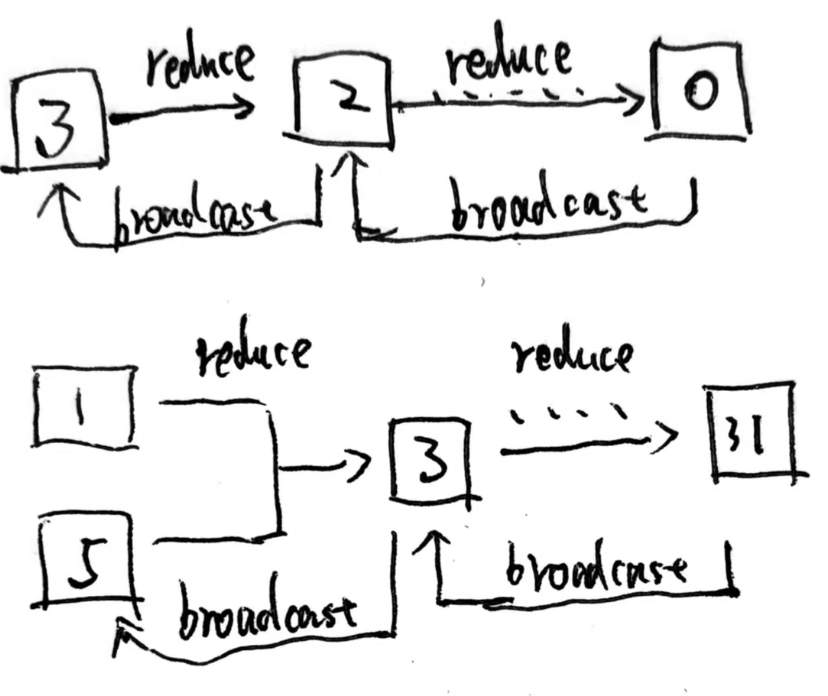
因为DBT的通信次数是O(logN)级别, 而Ring的通信次数是O(N)级别, 所以在大量节点的情况下会产生非常明显的性能收益, nvidia在博客里写到在2w+节点上, 用DBT的性能比Ring要好180+倍.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号