cuda程序优化-2.访存优化
简介
在CUDA程序中, 访存优化个人认为是最重要的优化项. 往往kernel会卡在数据传输而不是计算上, 为了最大限度利用GPU的计算能力, 我们需要根据GPU硬件架构对kernel访存进行合理的编写.
这章主要以计算一个tensor的模为例, 来看具体如何优化访存从而提升并行效率. 以下代码都只列举了kernel部分, 省略了host提交kernel的部分. Block_size均为256, 代码均在A100上评估性能.
CPU代码
void cpu_tensor_norm(float* tensor, float* result, size_t len) {
double sum = 0.0;
for (auto i = 0; i < len; ++i) {
sum += tensor[i] * tensor[i];
}
*result = sqrt(sum);
}
是一个非常简单的函数, 当然这里针对CPU程序也有优化方法, 当前实现并不是最优解. 此处忽略不表
GPU实现1-基于CPU并行思想
在传统的多线程CPU任务中, 如果想处理一个超大数组的求和, 很自然的会想到起N个线程, 每个线程算1/N的和, 最后再把这N个和加到一块求sqrt. 根据这个思路实现了kernel1, 使用1个block, block中每个线程计算1/N连续存储的数据.
__global__ void norm_kernel1(float* tensor, float* result, size_t len) {
auto tid = threadIdx.x;
auto size = len / blockDim.x;
double sum = 0;
for (auto i = tid * size; i < (tid + 1) * size; i++) {
sum += tensor[i] * tensor[i];
}
result[tid] = float(sum);
}
//norm_kernel1<<<1, block_size>>>(d_tensor, d_result1, len);

接下来我们使用nsight-compute来分析下第一个kernel实现哪些地方不合理. 具体使用方法可以从官方文档获取, 这里举个命令例子: nv-nsight-cu-cli -f --target-processes all -o profile --set full --devices 0 ./output/norm_kernel_bench

ncu分析给出了2个主要问题:
grid太小
因为我们只使用了256个线程. 而A100光CUDA core就7000个. 在GPU中不像CPU中线程上下文切换具有很高的成本, 如果想充分利用算力, 就要用尽量多的线程来提升并发度. 同时线程数也不能无限制增加, 因为如果每个线程使用了32个寄存器, 而SM中最多16384的寄存器空间的话, 多于16384/32=512个线程后, 这些多出来的线程就需要把数据存到显存里, 反而会降低运行效率.
读显存瓶颈
下面打开detail后也给出了问题日志: Uncoalesced global access, expected 262144 transactions, got 2097152 (8.00x) at PC
coalesced指的是显存读取需要是连续的, 这里也许你会有疑问, 在kernel1里就是按照连续的显存读的呀. 这里涉及到GPU的实际执行方式, 当一个thread在等读显存数据完成的时候, GPU会切换到下一个thread, 也就是说是需要让thread1读显存的数据和thread2的数据是连续的才会提升显存的读取效率, 在kernel1中明显不连续. 同时参考ProgrammingGuide 中的描述, 每个warp对显存的访问是需要对齐 32/64/128 bytes(一次数据传输的数据量在默认情况下是32字节), 如果所有数据传输处理的数据都是该warp所需要的,那么合并度为100%,即合并访问
GPU实现2-优化coalesced
__global__ void norm_kernel2(float* tensor, float* result, size_t len) {
auto tid = threadIdx.x;
double sum = 0.0;
while (tid < len) {
sum += tensor[tid] * tensor[tid];
tid += blockDim.x;
}
result[threadIdx.x] = float(sum);
}
//norm_kernel2<<<1, block_size>>>(d_tensor, d_result1, len);
依然还是1个block256个线程, kernel2将每个thread读取方式改成了每隔256个float读一个, 这样uncoalesced的报错就不见了. 但是! 一跑bench却发现为啥反而还变慢了呢?

此时可以点开memory WorkLoad Analysis
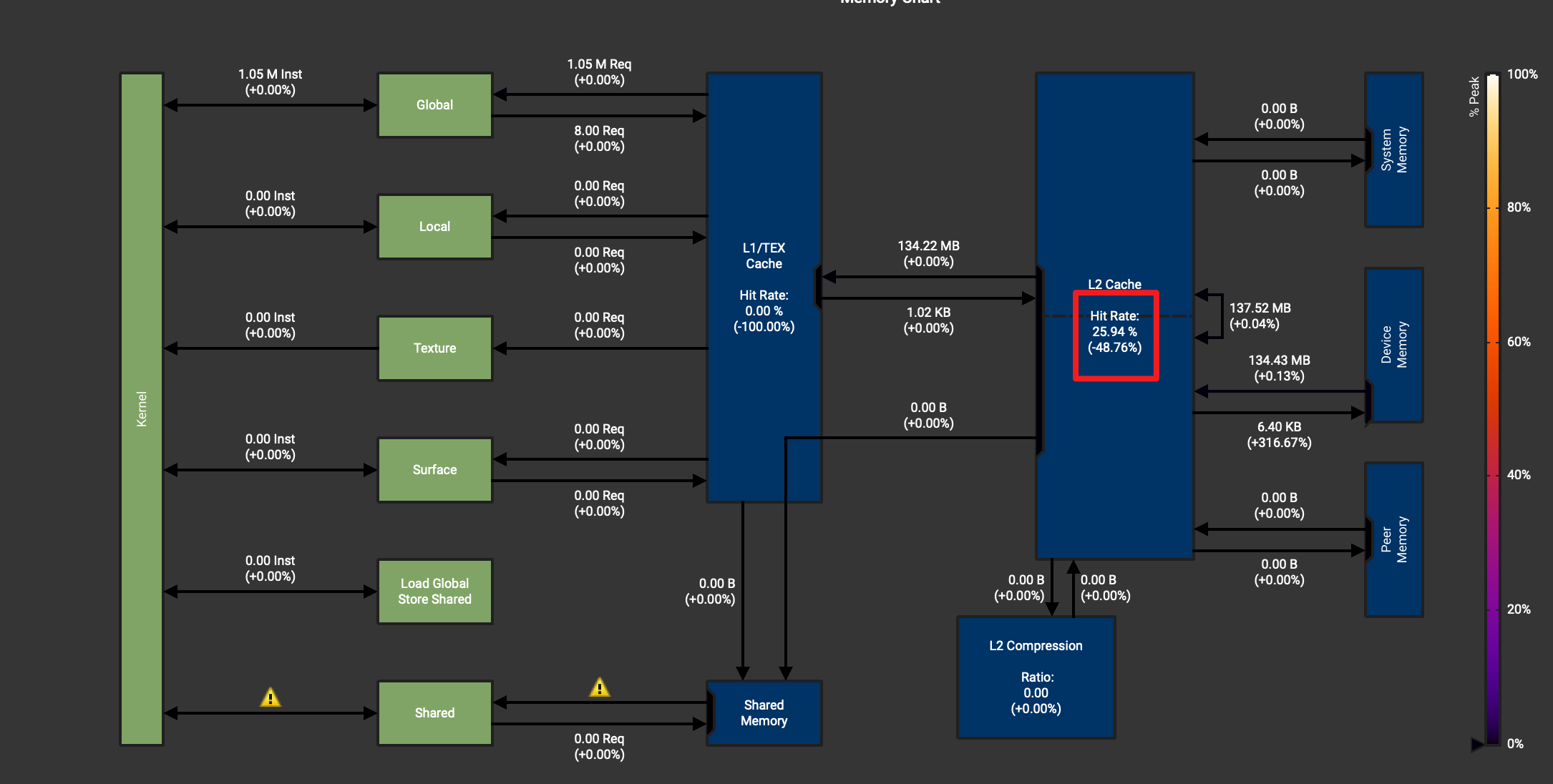
从这里可以看到L2 cache命中率降低了50%左右, 原因是因为按照kernel1的访问方式, 第一次访问了32bytes长度, 但是只用了一部分后, 剩下的会缓存在L2中, 而Kernel2虽然访问显存连续了, 但每次的cache命中率会随着读入数据利用效率的变高而降低, 根本原因是因为线程和block太少导致的. 另外这张图上还有个明显的叹号, 我们没有合理的用到shared_memory. 接下来的kernel3重点优化这两部分
GPU实现3-增大并发&利用shared_memory
__global__ void norm_kernel3(float* tensor, float* result, size_t len) {
auto tid = threadIdx.x + blockIdx.x * blockDim.x;
extern __shared__ double sum[];
auto loop_stride = gridDim.x * blockDim.x;
sum[threadIdx.x] = 0;
while (tid < len) {
sum[threadIdx.x] += tensor[tid] * tensor[tid];
tid += loop_stride;
}
__syncthreads();
if (threadIdx.x == 0) {
for (auto i = 1; i < blockDim.x; ++i) {
sum[0] += sum[i];
}
result[blockIdx.x] = float(sum[0]);
}
}
//grid_size3=64
//norm_kernel3<<<grid_size3, block_size, block_size * sizeof(double)>>>(d_tensor, d_result3, len);
//for (auto i = 1; i < grid_size3; ++i) {
// h_result3[0] += h_result3[i];
//}
//sqrt(h_result3[0])

短短几行改动, 让程序快了27倍, 这是什么魔法(黑人问号)? kernel3做了如下几个优化:
-
使用shared_memory用来存储临时加和, 最后在每个block的第一个thread里把这些加和再加到一块, 最后再写回HBM. shared_memory访问速度19T/s, HBM速度才1.5TB/s, 所以我们如果有需要临时存储的变量, 要尽可能的把shared_mem利用起来.
-
这次使用了64个block, GPU的其他SM终于不用看戏了. 但其实还是可以增加的, A100有108个SM呢, 让我们把他用满再看下性能
auto grid_size3 = (len + block_size - 1) / block_size;可以看到我们终于让计算吞吐打满了~

到这里还有2个问题需要解决: 1.我们只是在GPU里求了局部加和, 全局和还得挪到CPU算好挫. 2.每个block在syncthread之后只有第一个线程在计算, 能不能加快计算的同时减少一下计算量
GPU实现4-优化加和
template <int64_t BLOCK_SIZE>
__global__ void norm_kernel4(float* tensor, double* result, size_t len) {
using BlockReduce = cub::BlockReduce<double, BLOCK_SIZE>;
__shared__ typename BlockReduce::TempStorage temp_storage;
int tid = threadIdx.x + blockIdx.x * blockDim.x;
double sum = 0.0;
if (tid < len) {
sum += tensor[tid] * tensor[tid];
}
double block_sum = BlockReduce(temp_storage).Sum(sum);
if (threadIdx.x == 0) {
atomicAdd(result, block_sum);
}
}
//norm_kernel4<block_size><<<grid_size, block_size>>>(d_tensor, d_result4, len);
//sqrt(h_result4)

对与第一个线程连续加和的问题, 我偷懒使用了cub::BlockReduce方法, BlockReduce的原理是经典的树形规约算法. 利用分治的思想, 把原来的32轮加和可以简化为5轮加和, 这样就能极大减少长尾线程的计算量.
对于显存上的全局求和问题, 由于block之间是没有任何关联的, 我们必须使用原子操作来解决对全局显存的操作. 这里为了减少原子写冲突, 只在block的第一个线程上进行原子加. 另外我们可以不用cub的BlockReduce优化到和他差不多的性能吗?
GPU实现5-自己实现BlockReduce
template <int64_t BLOCK_SIZE>
__global__ void norm_kernel5(float* tensor, double* result, size_t len) {
using WarpReduce = cub::WarpReduce<double>;
const int64_t warp_size = BLOCK_SIZE / 32;
__shared__ typename WarpReduce::TempStorage temp_storage[warp_size];
__shared__ float reduce_sum[BLOCK_SIZE];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int warp_id = threadIdx.x / 32;
float sum = 0.0;
if (tid < len) {
sum += tensor[tid] * tensor[tid];
}
auto warp_sum = WarpReduce(temp_storage[warp_id]).Sum(sum);
reduce_sum[threadIdx.x] = warp_sum; //这里尽量避免wrap内的分支
__syncthreads();
//树形规约
int offset = warp_size >> 1;
if (threadIdx.x % 32 == 0) {
while (offset > 0) {
if (warp_id < offset) {
reduce_sum[warp_id * 32] += reduce_sum[(warp_id + offset) * 32];
}
offset >>= 1;
__syncthreads();
}
}
if (threadIdx.x == 0) {
atomicAdd(result, reduce_sum[0]);
}
}
//norm_kernel5<block_size><<<grid_size5, block_size>>>(d_tensor, d_result5, len);
//sqrt(h_result5)

kernel5主要分为两个部分, 第一步进行了warp内的规约, 第二步手动实现了树形规约的方法. 耗时基本与BlockReduce一致, 由于warp内的32个线程会共享寄存器和shared_mem读写, 在warp内先做一些规约可以适当减少后续的sync_threads轮数.
其实这个kernel还是有很大优化空间, 篇幅受限原因更深层次的优化技巧在后续说明
计算分析
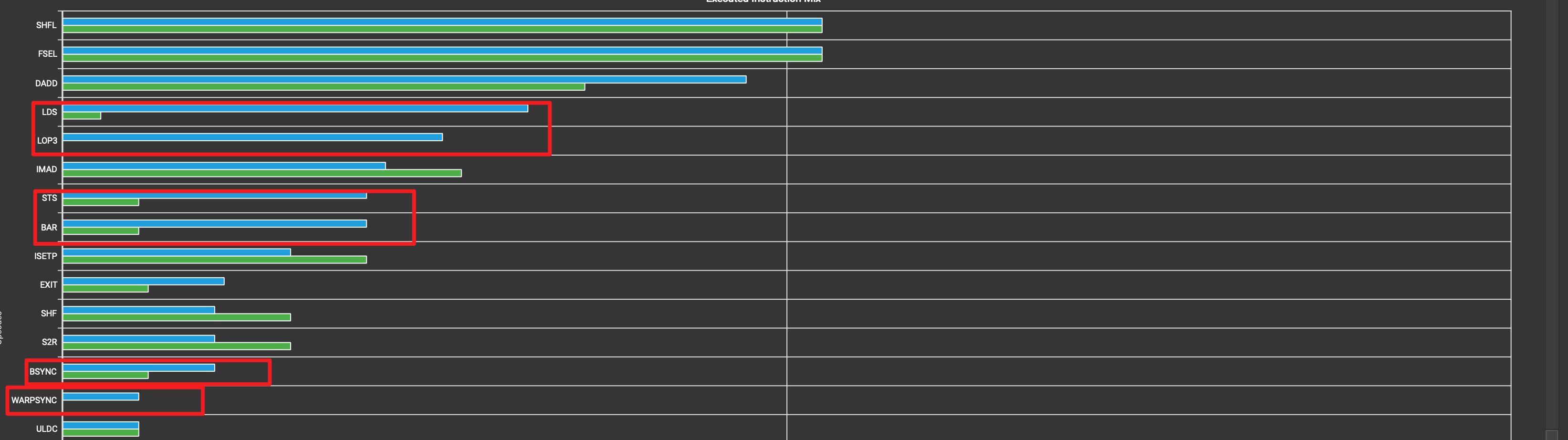
在汇编指令统计这块可以看到LDS(从shared_mem加载指令), LOP3(logic操作), STS(往mem中写入操作), BAR(barrier), BSYNC(线程同步时的barrier, 对应atomic操作), WARPSYNC(warp同步)这些相较于kernel4多了很多. WARPSYNC/LOP3/BAR这些变多是正常的, 是kernel5里新增的逻辑. LDS/STS增加应该是因为我们在warp_reduce时的频率比block_reduce对共享内存的访问频率更高导致.
访存注意要点-bank conflicts

内存分析里出现了一个新名词bank conflicts , 先根据官方文档 解释下这个名词.
SharedMemory结构: 放在shared memory中的数据是以4bytes作为1个word,依次放在32个banks中。第i个word存放在第(i % 32)个bank上。每个bank在每个cycle的 bandwidth为4bytes。所以shared memory在每个cycle的bandwidth为128bytes。这也意味着每次内存访问只会访问128bytes数据
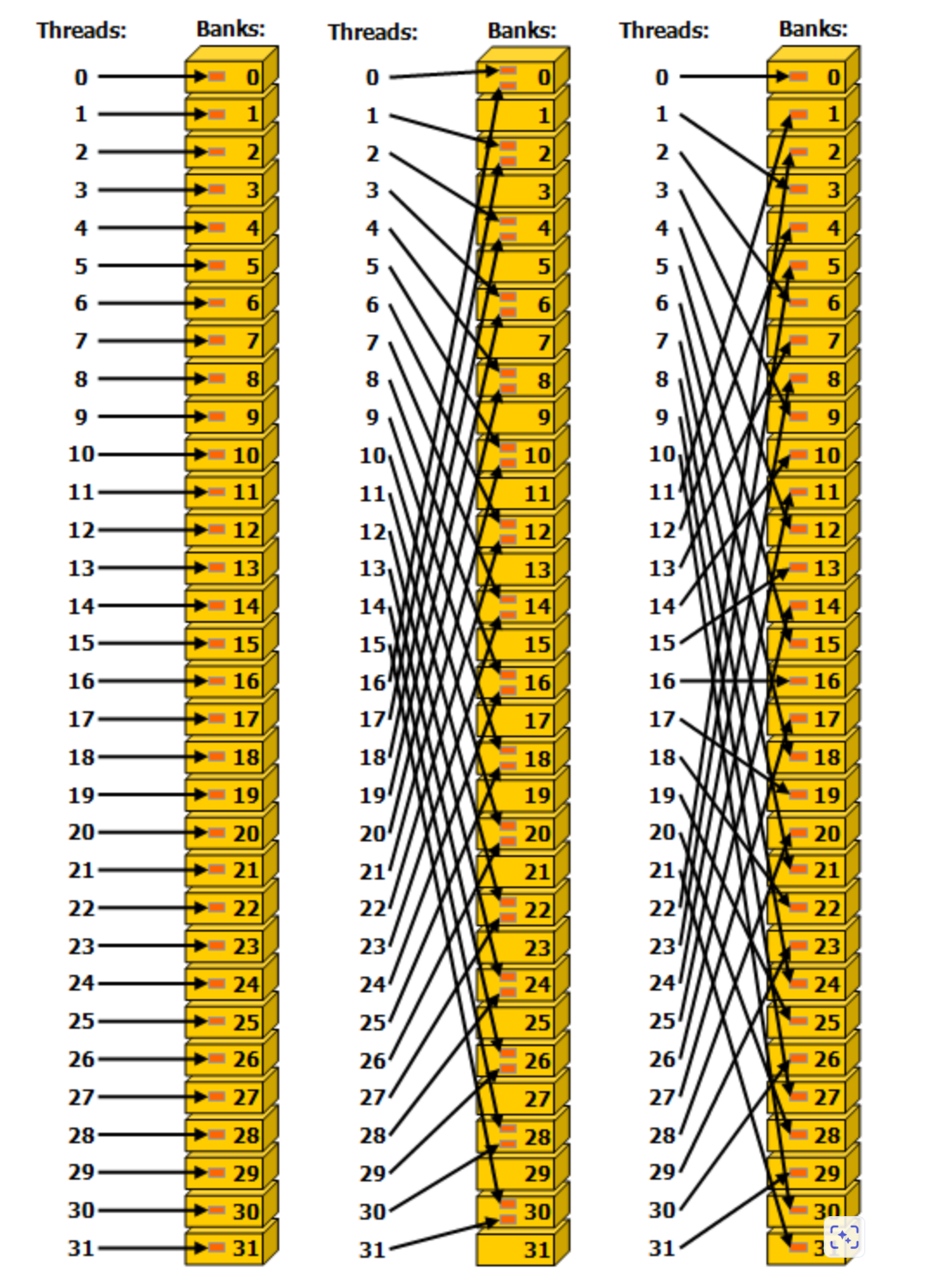
如果同一个warp内的多个threads同时访问同一个bank内的同一个word, 会触发broadcast机制, 会同时发给多个thread. 不会产生冲突
冲突主要产生在多个threads访问同一个bank内的不同word, 如上图的第二列. 这样就会导致本来的一次memory transaction被强制拆分成了2次, 而且需要串行访问memory
解决方法:
通过错位的方式访问数组, 避免访问步长和32产生交集, 每个线程根据线程编号tid与访问步长s的乘积来访问数组的32-bits字(word):
extern __shared__ float shared[];
float data = shared[baseIndex + s * tid];
如果按照上面的方式,那么当s*n是bank的数量(即32)的整数倍时或者说n是32/d的整数倍(d是32和s的最大公约数)时,线程tid和线程tid+n会访问相同的bank。我们不难知道如果tid与tid+n位于同一个warp时,就会发生bank冲突,相反则不会。
仔细思考你会发现,只有warp的大小(即32)小于等于32/d时,才不会有bank冲突,而只有当d等于1时才能满足这个条件。要想让32和s的最大公约数d为1,s必须为奇数。于是,这里有一个显而易见的结论:当访问步长s为奇数时,就不会发生bank冲突。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号