CUDA程序优化-1.基础介绍
简介
本合集主要介绍我在开发分布式异构训练框架时的CUDA编程实践和性能优化的相关内容。主要包含以下几个部分:
- 介绍CUDA的基本概念和架构,帮助读者建立对CUDA的初步认识,包括硬件架构/CUDA基础等内容
- 介绍一些性能优化技巧和工具,帮助读者优化CUDA程序的执行效率
- 结合具体的代码示例来说明一个cuda程序的优化思路和结果, 帮助读者更好地理解和掌握CUDA编程和性能优化的实践方法
希望通过本文档,能够帮助大家写出更高效的CUDA程序。下面我们就开始吧~
1. 硬件架构
要说清楚为什么GPU比CPU更适合大规模并行计算, 要从硬件层面开始说起
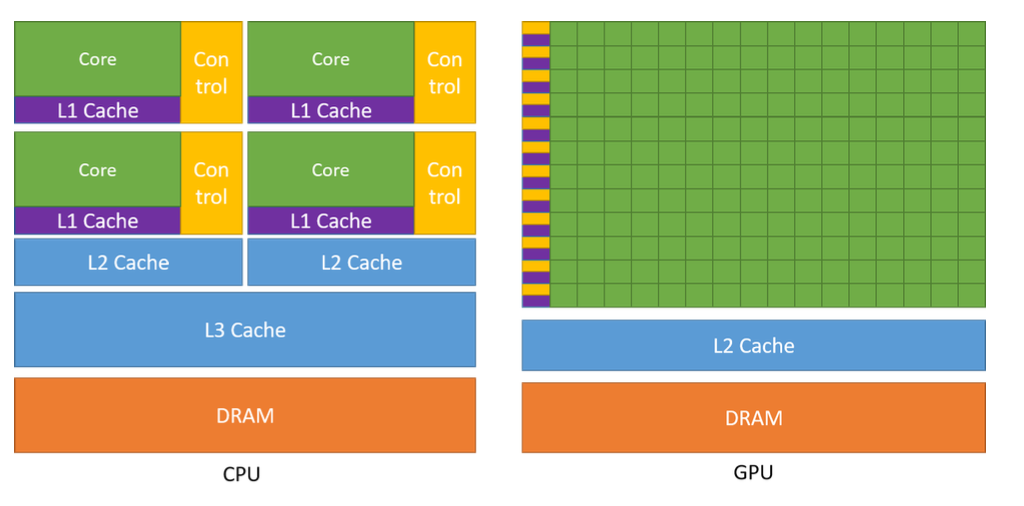
以当前较主流的硬件i9-14900k和A100为例:
i9-14900k: 24核心, 32线程(只能在16个能效核上进行超线程), L2: 32MB, L3: 36MB, 内存通信带宽 89.6GB/s
A100: 108 SM, 6912 CUDA core, 192KB L1, 60MB L2, 40GB DRAM.
我个人的理解, GPU的运算核心之所以远多于CPU, 是因为远少于CPU的控制逻辑. GPU每个core内不需要考虑线程调度的情况, 不需要保证严格一致的运算顺序, 另外每个sm都有自己独立的寄存器和L1, 对线程的切换重入非常友好, 所以更适合大规模数据的并行运算. 而这种设计方式也会对程序员提出更高的要求, 纯CPU程序可能写的最好的代码和最差的情况有个2/3倍的性能差距就很大了, 而CUDA kernel可能会相差几十倍甚至几百倍.
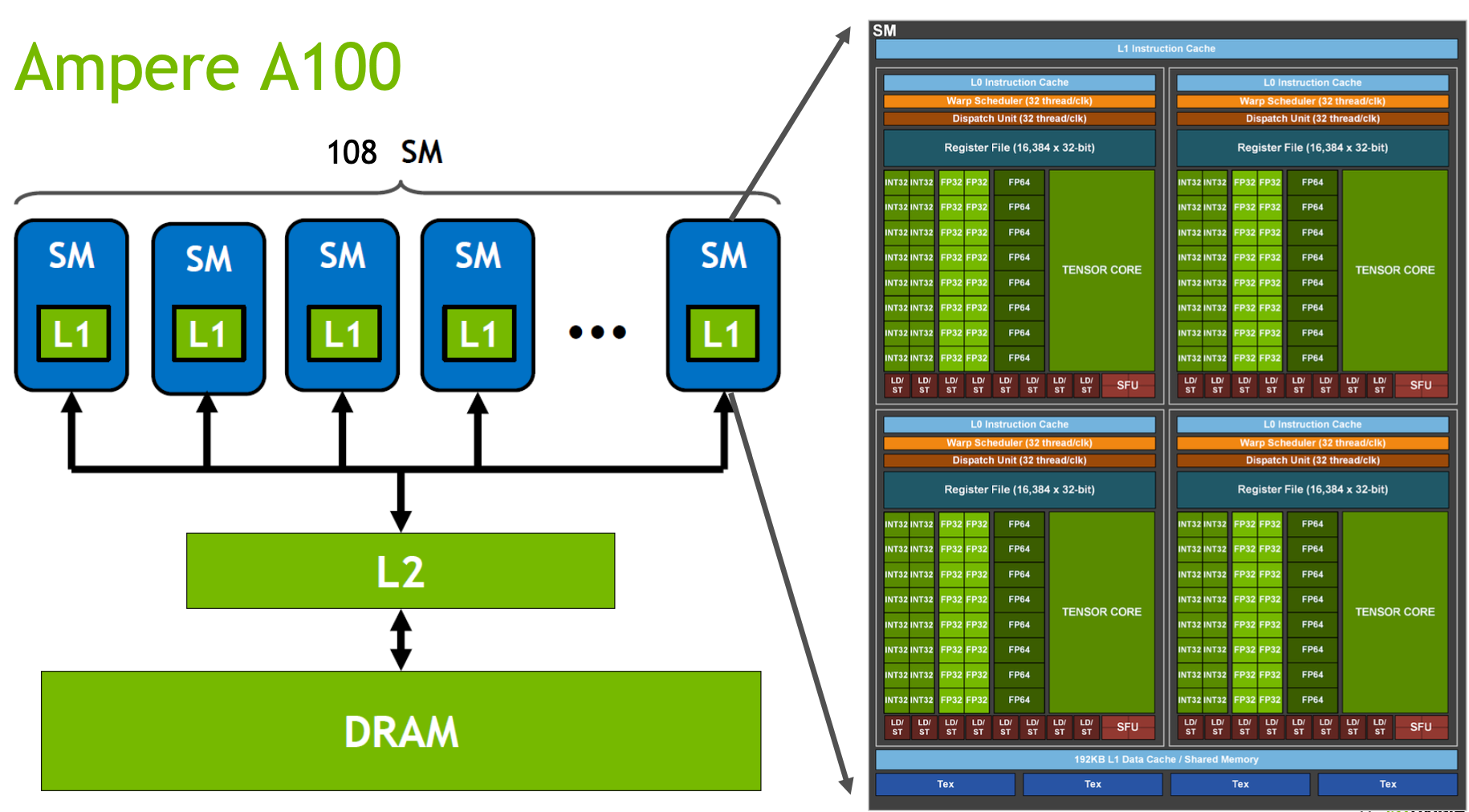
HBM(High-Bandwidth Memory) :HBM是高带宽内存,也就是常说的显存, 这张图里的DRAM。 带宽: 1.5TB/s
L2 Cache:L2 Cache是GPU中更大容量的高速缓存层,可以被多个SM访问。L2 Cache还可以用于协调SM之间的数据共享和通信。 带宽: 4TB/s
SM(Streaming Multiprocessor) :GPU的主要计算单元,负责执行并行计算任务。每个SM都包含多个CUDA core,也就是CUDA里Block执行的地方, 关于block_size如何设置可以参考block_size设置, 跟随硬件不同而改变, 通常为128/256
L1 Cache/SMEM:, 也叫shared_memory, 每个SM独享一个L1 Cache,CUDA里常用于单个Block内部的临时计算结果的存储, 比如cub里的Block系列方法就经常使用, 带宽: 19TB/s
SMP(SM partition): A100中有4个. 每个有自己的warp调度器, 寄存器等.
CUDA Core: 图里绿色的FP32/FP64/INT32等就是, 是thread执行的基本单位
Tensor Core: Volta架构之后新增的单元, 主要用于矩阵运算的加速
WARP(Wavefront Parallelism) :WARP指的是一组同时执行的Thread,固定32个, 不够32时也会按32分配. warp一个线程对内存操作后, 其他warp内的线程是可见的.
Dispatch Unit: 从指令队列中获取和解码指令,协调指令的执行和调度
Register File: 寄存器用于存储临时数据、计算中间结果和变量。GPU的寄存器比CPU要多很多
2. cuda基础
cuda基础语法上和c/c++是一致的. 引入了host/device定义, host指的是cpu端, device指的是gpu端
个人感觉最难的部分在于并行的编程思想和cpu编程的思想差异比较大. 我们以一个向量相加的demo程序举例:
__global__ void add_kernel(int *a, int *b, int *c, int n) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
if (index < n) {
c[index] = a[index] + b[index];
}
}
int main() {
int *a, *b, *c;
int *d_a, *d_b, *d_c;
int n = 10000;
int size = n * sizeof(int);
cudaMalloc((void**)&d_a, size);
cudaMalloc((void**)&d_b, size);
cudaMalloc((void**)&d_c, size);
a = (int*)malloc(size);
random_ints(a, n);
b = (int*)malloc(size);
random_ints(b, n);
c = (int*)malloc(size);
cudaMemcpy(d_a, a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, size, cudaMemcpyHostToDevice);
//cuda kernel
add_kernel<<<(n + threads_per_block - 1)/threads_per_block, threads_per_block>>>(d_a, d_b, d_c, n);
cudaMemcpy(c, d_c, size, cudaMemcpyDeviceToHost);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
描述符
cuda新增了三个描述符:
__global__: 在device上运行, 可以从host/device上调用, 返回值必须是void, 异步执行.
__device__: 在device上运行和调用
__host__: 只能在host上执行和调用
CUDA Kernel
cuda_kernel是由<<<>>>围起来的, 里面主要有4个参数用来配置这个kernel <<<grid_size, block_size, shared_mem_size, stream>>>
grid_size: 以一维block为例, grid_size计算以 (thread_num + block_size - 1) / block_size 计算大小
block_size: 见上面SM部分介绍
shared_mem_size: 如果按 __shared__ int a[] 方法声明共享内存, 需要在这里填需要分配的共享内存大小. 注意不能超过硬件限制, 比如A100 192KB
stream: 异步多流执行时的cuda操作队列, 在这个流上的所有kernel是串行执行的, 多个流之间是异步执行的. 后续会在异步章节里详细介绍
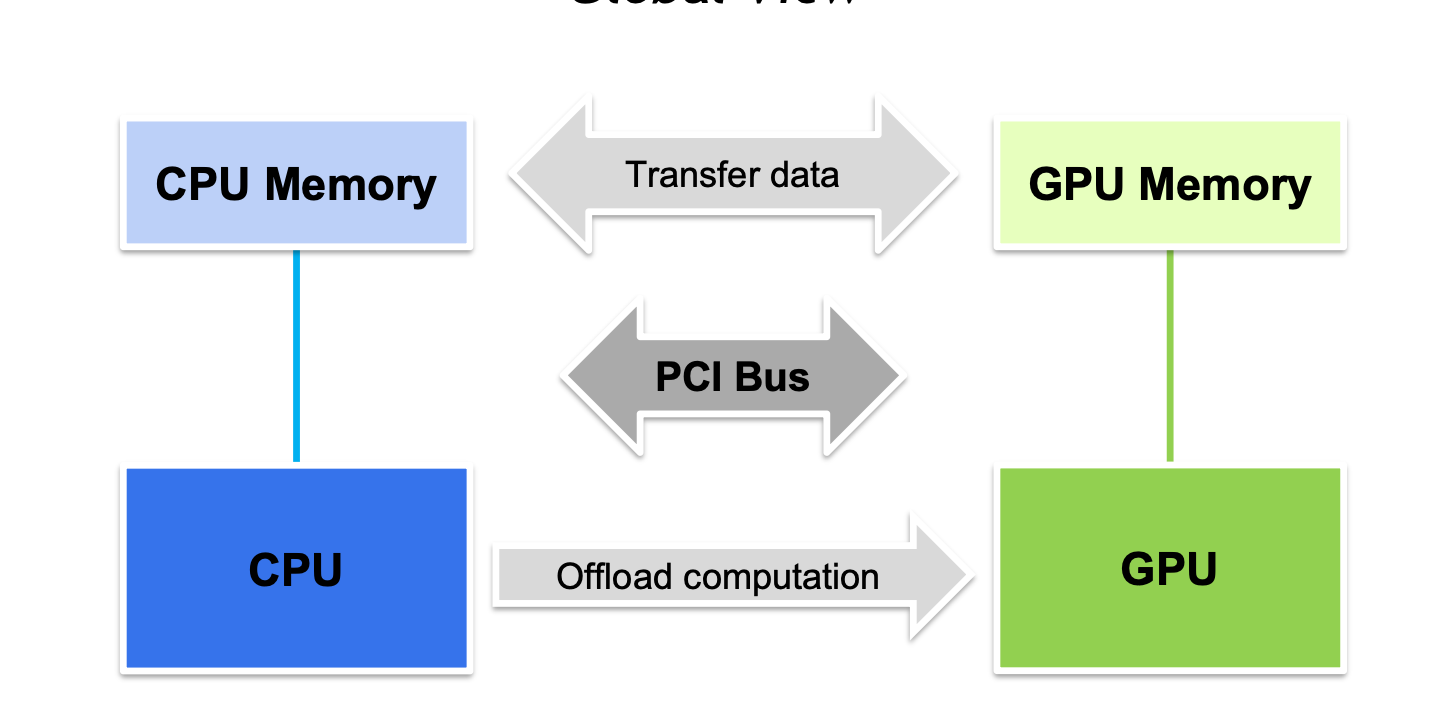
整个过程如下图, 先通过cudaMemcpy 把输入数据copy到显存->cpu提交kernel->gpu kernel_launch->结果写回线程->DeviceToHost copy回内存.
add_kernel 相当于我们将for循环拆分为了每个线程只处理一个元素的相加的并行执行. 通过nvcc编译后就完成了第一个kernel的编写. 下一篇会以一个具体的例子来讲如何进行kernel的性能分析和调优.
常用库
thrust: cuda中类似于c++ STL的定位, 一些类似于STL的常见算法可以在这里找到现成的实现, 比如sort/reduce/unique/random 等. 文档: https://nvidia.github.io/cccl/thrust/api/namespace_thrust.html
cudnn: 神经网络加速的常用库. 包含卷积/pooling/softmax/normalization 等常见op的优化实现.
cuBlas: 线性代数相关的库. 进行矩阵运算时可以考虑使用, 比如非常经典的矩阵乘法实现cublasSgemm
Cub: warp/block/device级的编程组件, 非常常用. 文档: https://nvidia.github.io/cccl/cub/
nccl: 集合通信库. 用于卡间通信/多机通信
相关资料
cuda编程指导手册: https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#programming-model
性能分析工具Nsight-System & Nsight-Compute: https://docs.nvidia.com/nsight-systems/index.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号