Paddle图神经网络训练-PGLBox代码阅读笔记
| 图存储部分 | ||
|---|---|---|
| paddle/fluid/framework/fleet/heter_ps | graph_gpu_wrapper.h | GPU图主入口 |
| graph_gpu_ps_table.h | GPU图的主要存储结构,neighbor采样等都在这里完成 | |
| gpu_graph_node.h | 节点,边,邻居等数据结构定义 | |
| paddle/fluid/distributed/ps/table/ | common_graph_table.h | CPU图存储 |
| 图游走部分 | ||
| paddle/fluid/framework/ | data_feed.h/data_feed.cu | SlotRecordInMemoryDataFeed 使用的datafeedGraphDataGenerator 图游走,准备输入数据的封装 |
| data_set.h | SlotRecordDataset 使用的dataset |
整体流程:
数据结构
- 读入图数据到内存
cpu_graph_table_, 即node和edge, 分别如下格式:
# edge
"0\t1",
"0\t9",
"1\t2",
# node
"user\t37\ta 0.34\tb 13 14\tc hello\td abc",
"item\t111\ta 0.21",
user和item读到不同的GraphFeature结构里面, 加载时会把user/item 通过node_to_id转成int类型
图存储转换适配显存存储
make_gpu_ps_graph 把cpu的node结构打平存储, 通过多线程的方式把每个节点的邻居存储到 egde数组里, 每个节点通过neighbor_offset和neighbor_size, 就能在edge_array里拿到自己的所有邻居. 下面是一个neighbor具体的存储例子
suppose we have a graph like this
0----3-----5----7
\ |\ |\
17 8 9 1 2
we save the nodes in arbitrary order,
in this example,the order is
[0,5,1,2,7,3,8,9,17]
let us name this array u_id;
we record each node's neighbors:
0:3,17
5:3,7
1:7
2:7
7:1,2,5
3:0,5,8,9
8:3
9:3
17:0
by concatenating each node's neighbor_list in the order we save the node id.
we get [3,17,3,7,7,7,1,2,5,0,5,8,9,3,3,0]
this is the neighbor_list of GpuPsCommGraph
given this neighbor_list and the order to save node id,
we know,
node 0's neighbors are in the range [0,1] of neighbor_list
node 5's neighbors are in the range [2,3] of neighbor_list
node 1's neighbors are in the range [4,4] of neighbor_list
node 2:[5,5]
node 7:[6,6]
node 3:[9,12]
node 8:[13,13]
node 9:[14,14]
node 17:[15,15]
...
by the above information,
we generate a node_list and node_info_list in GpuPsCommGraph,
node_list: [0,5,1,2,7,3,8,9,17]
node_info_list: [(2,0),(2,2),(1,4),(1,5),(3,6),(4,9),(1,13),(1,14),(1,15)]
内存->显存的图存储
build_graph_from_cpu 构建GPUPSTable, 边的类型也有多种, 通过edge_idx来区分.
- 先把所有node_id MemCPY 到VRAM
- 根据每个node的sparse feature数量, build_ps
- 把所有节点对应的邻居节点copy到VRAM
注意: GpuPsGraphTable里的table类型分为EDGE_TABLE和FEA_TABLE, 根据table类型和idx获取对应的table, fea_table只有一个, 而EDGE_TABLE有type类型个
邻居采样
graph_neighbor_sample(int gpu_id, uint64_t *device_keys, int walk_degree, int len) walk_degree指的是邻居节点采样后的个数, 比如要给100个节点采样邻居,每个采样10个邻居, 这里就是 (0, keys, 10, 100), TODO: 待确认这个函数是否使用
NeighborSampleResult用于存储deepwalk结果, 在显存里.split_input_to_shard, 把要查的node分配到对应的显卡上. 并按照显卡序号重排, 把相同显卡的key排到一块. left就是起始, right就是结束fill_shard_key: 把每张卡里存的node_id填到d_shard_keys里面walk_to_dest: 把各自卡的shard_keys copy到对应卡的显存里- 每张卡各自异步进行neighbor_sample, 把采样的结果填到node.val_storage里面. 最后move_result_to_source_gpu 再copy回原卡上.
fill_dvalues: 因为之前重排序过, 根据之前重排的idx, 还原原始顺序, 把d_shard_vals赋值给val- 求actual_sample_size前缀和: cumsum_actual_sample_size
- 把val中的空位置给去掉, 把不等长的actual_sample填充到actual_val里面 (需要开启压缩, compress入参=true)
- 采样图示:
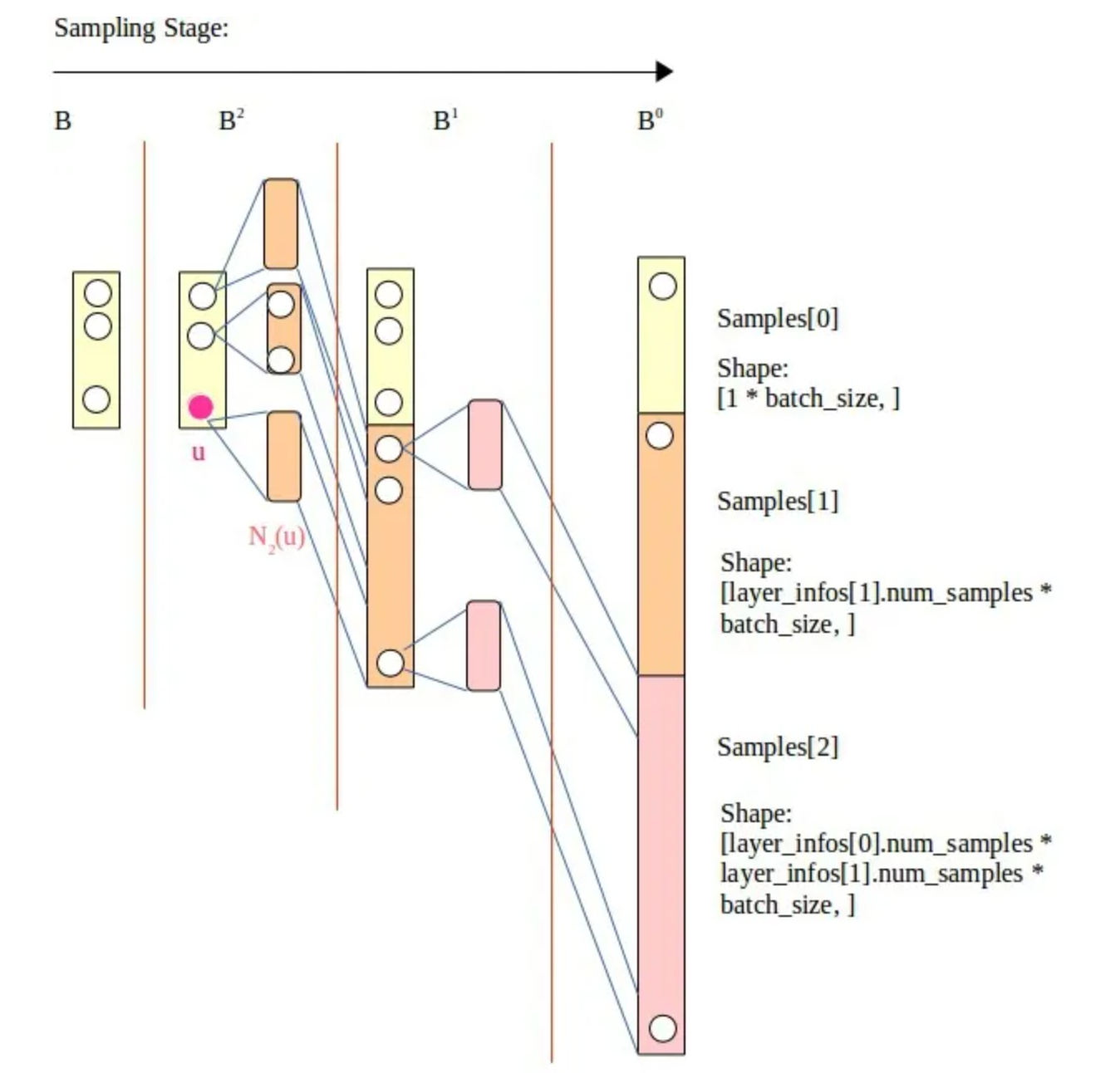
图游走
GraphDataGenerator核心函数: DoWalkandSage
各个成员解释:
once_sample_startid_len_: 其实就是batch_size, 控制每次游走的样本数量, 使显存能够尽可能放下
walk_degree_(就是配置里的walk_times): 每个起始节点重复n次游走,这样可以尽可能把一个节点的所有邻居游走一遍,使得训练更加均匀
walk_len: metapath 游走路径深度
meta_path: 控制user和item交叉游走
一. FillWalkBuf 进行邻居节点游走后填充到显存buf中
- 根据起始节点类型, 把对应的节点找到
d_type_keys, 总长度batch_size * 游走深度 * 游走次数 * repeat_time; repeat_time的计算方式(python里)如下: 用来控制游走占用显存的大小
#第一步: 根据显卡当前的显存大小和分配比例, 算出来最大单次游走的去重后node个数
allocate_memory_bytes = total_gpu_memory_bytes * allocate_rate
train_pass_cap = max_unique_nodes = int(allocate_memory_bytes / (emb_size * 4 * 2))
#第二步: sample_size: 一层邻居,二层邻居采样的个数
train_chunk_nodes = int(config.walk_len * config.walk_times * config.batch_size)
train_chunk_nodes *= np.prod(config.samples) * config.win_size
#第三步: 算大概去重前的大小, 这里uniq_factor=0.4是咋定的?
train_sample_times_one_chunk = int(train_pass_cap / train_chunk_nodes / uniq_factor)
#满意子图上这个计算的结果
repeat_time_ = 40G * 0.1 / (100 * 4 * 2) / (8 * 10 * batch_size) * (3 * 2 * 2) / 0.4
-
进行邻居采样, 即调用
graph_neighbor_sample_v3, 如果采样结果为空跳过这个batch, 每次FillOneStep前都要重新邻居采样 -
FillOneStep重要函数-
根据meta_path获取游走方式, 比如
meta_path: "u2t-t2u;t2u-u2t", 表示从u类型node->t类型node->u类型node, 解析配置时把u和t转成了int类型的id, 通过src_node_id << 32 | dst_node_id 的方式存储扩展关系 -
根据每个node对应的邻居实际长度actual_sample_size, 求出前缀和, 用于定位每个node在neighbor数组里对应的起始偏移量.
-
第一次游走
GraphFillFirstStepKernel, 按照下图的格式填到游走结果: walk&walk_ntype里面. 另外记录下sample_key(长度 sum(actual_sample_size) * len), 后续轮次的游走就不填walk了, 只记录sample_key(这个用于后续游走轮数的key记录), 这个kernel只填walk[off+1], 即第一次的结果. -
node: 0, 1, 2, 3, 4 ... //id neighbor: 0, 0, 1, 1, 1 ...//每个id对应的邻居列表 actual_size: 2, 3, ... //各个id对应的邻居列表的长度 prefix_sum: 0, 2, 5, ... //邻居长度前缀和 --> walk: | | |0(key)---walk_len-1次游走id---|...邻居个数个| 1(key)---walk_len-1次游走id---|...邻居个| ...batch_size个| 总长度: (walk_len + 1) * 每个key对应的actual_sample_size * batch_size walk_ntype: 存储walk中每个位置上对应的node类型 -
GraphDoWalkKernel根据d_sampleidx2row聚合walk. 把第二次游走到最后一次游走直接的所有d_walk填充好
-
-
第一次游走单独执行后, for循环进行图的深度迭代(类似bfs), 如下图. 也是先采样, 然后继续FillOneStep
-
更新全局采样状态, 更新起始节点到下一个batch, cursor用于记录当前游走到了哪个类型的node(u还是t)
-
做一次全局shuffle(total_sample_size * walk_len)
-
游走步骤图示:
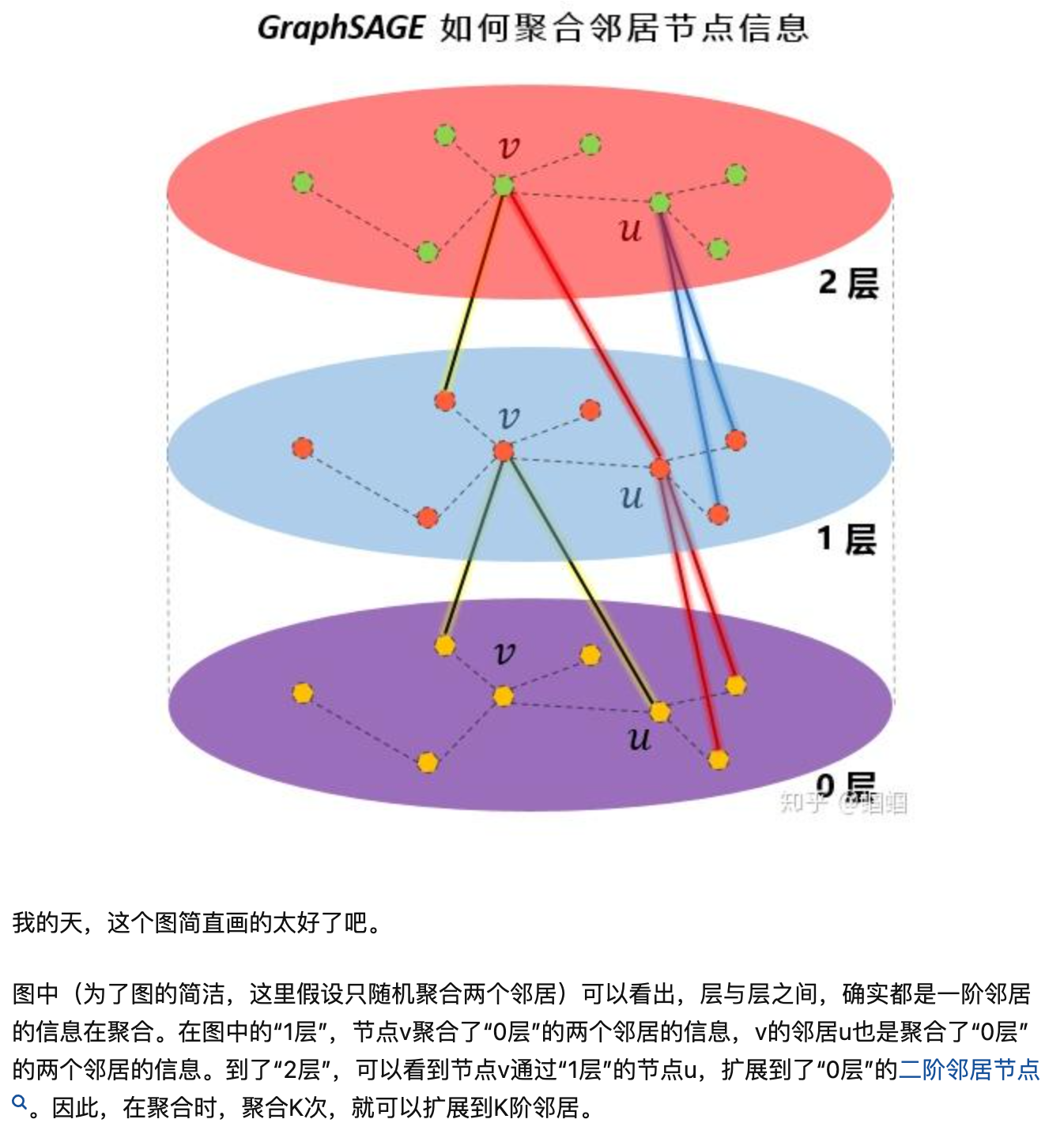
二. FillInsBuf 构造训练样本
struct BufState {
int left;
int right;
int central_word; //正中间在哪, 初始值-1
int step; //初始值0
engine_wrapper_t random_engine_; //
int len; //初始值0
int cursor; //光标, 用来记录在所有样本长度上处理到了第几个batch
int row_num;
int batch_size;
int walk_len; //游走深度
std::vector<int>* window; //窗口, 如果win_size=2 里面存储 -2, -1, 1, 2
}
样本采样之所以有central_word, 并且从中心开始左右扩展进行随机的原理如下:
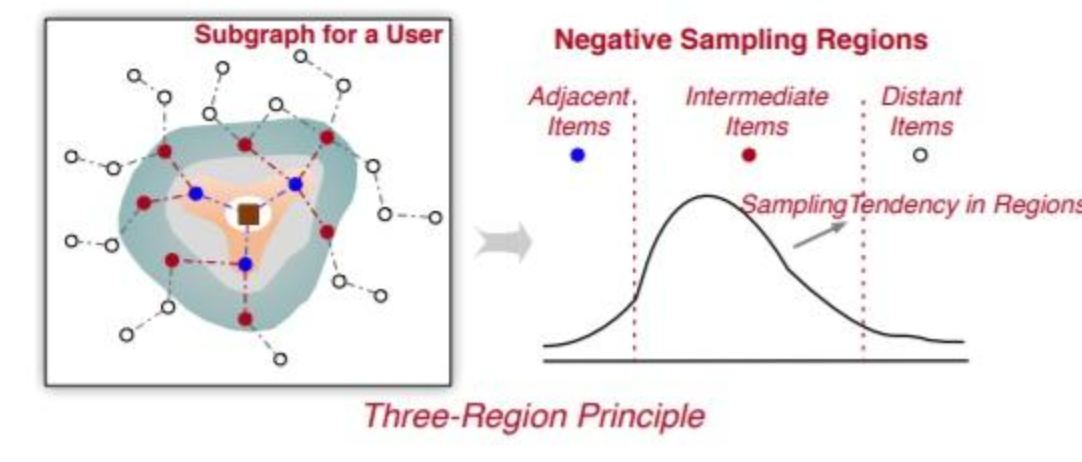
- 邻接区域:在基于图的推荐中,相邻区域中的商品通常用于为中心用户 u 传播特征信息。因此,这些商品代表了用户的积极偏好,不应作为消极偏好进行采样。
- 中间区域:与相邻商品不同的是,中间区域的这些商品被认为是可以为模型训练带来更多信息的近似正样本的难样本。这些中间节点离中心用户 u 有点远,当它们作为相邻商品在用户-项目图中传播信息时,会降低(或略微提高)推荐性能。与相邻商品相比,这些中间商品在性能上的提升有限,有时甚至会降低性能。此外,将这些中间项传播到中心节点可能会导致大量内存消耗。因此,中间项目应该被充分采样为负样本以增强负样本。
- 更远区域:距离中心用户u很远的商品节点,可以看做是易负样本,这些样本是很容易拟合的,在这上面过多的负采样对性能提升帮助不大。
上面这个BufState就是用来记录采样位置的. (TODO: 这里PGL用的平均分布, 可能有效果优化空间)
MakeInsPair: 核心逻辑是(GraphFillIdKernel)
- 先过滤不在meta_path里的pair对
- |src/src+step|...这种形式存储到id_tensor, random_row应该是用来打乱节点顺序的, 可能是想避免节点总是从0-n导致影响效果.
三 GenerateSampleGraph
第一步, 根据cursor算出当前batch的ins_buf偏移量
第二步, 对游走序列进行去重dedup_keys_and_fillidx, 猜测例子是1->2->1->2, 这种把反复游走的序列给删掉. 只保留一个1->2, 具体步骤:
-
填充好去重前的idx:
fill_idx -
根据key排序key和idx:
cub_sort_pairs -
统计相同key的数量:
cub_runlength_encode -
求key数量的前缀和:
cub_exclusivesum -
根据重复率不同分别走不同的重填充kernel, 重复率高的时候用二分查找:
kernel_fill_restore_idx
接下来根据邻居采样的层数进行循环
第三步, SampleNeighbors
graph_neighbor_sample_all_edge_type从GraphTable里查询每个meta_graph对应的edge_type表, 这个函数hipo实现时要重写- 把key copy到对应的卡上
neighbor_sample_kernel_all_edge_type: 在每个edge_type对应的GpuPsCommGraph获取edge权重. 如果邻居个数超过sample_size, 从中随机选取size个.- 把结果从存储卡上copy回来:
move_result_to_source_gpu_all_edge_type, node.val_storage->d_shard_vals_ptr 并且填充value(根据actual_sample_size) neighbor_sample_kernel_all_edge_type, 把按卡进行重新排序的shard_vals根据之前存储的索引, 给填回到NeighborSampleResultV2.val里面
- 求各个edge结果actual_size的前缀和, 总长度: uniq_node的个数 * edge_type个数, 把各个type的总长度存储到edges_split_num里面
FillActualNeighbors: 之前查询edge_type的结果里存在空值, 因为每个node对应的邻居为sample_size个, 有些不满长度的后面有空值, 根据actual_size把空值删掉.
第四步: GetReindexResult 主要目的是对输入的中心节点信息和邻居信息进行从 0 开始的重新编号(同时去重邻居节点),以方便后续的图模型子图训练 API解释
第五步: GetNodeDegree: 获取各个node的neighbor_size
第六步: CopyUniqueNodes: 如果不是全显存的存储方式, 需要copy回内存.
四 GenerateBatch.Next() 填充slot/show/clk
FillGraphIdShowClkTensor: 直接全填1, 图模型应该没用这两个字段, 仅用于sparse更新
FillGraphSlotFeature:
get_feature_info_of_nodes: 依然是把node发到对应的卡上查- 从tables_里查到node key对应的
GpuPsFeaInfo指针后, 从这个里面读取出feature_size - 计算每个node的feature_size的前缀和
get_features_kernel: 根据feature_offset 在GpuPsCommGraphFea里面, 从feature_list和slot_list里读出来- copy回原卡
move_result_to_source_gpu fill_feature_and_slot: 根据原来的idx把按卡号排序后的val填到排序前的位置里面.
- 从tables_里查到node key对应的
PGL配置
# ---------------------------数据配置-------------------------------------------------#
# 每种边类型对应的文件或者目录, 这里u2t_edges目录对应graph_data_hdfs_path目录下的u2u_edges目录, 其它的以此类推。
# 如果u和t之间既有点击关系,有可能有关注关系,那么可以用三元组表示,即用:u2click2t 和 u2focus2t 来表示点击和关注这两种不同的关系
# 下面的示例表示u2t的边保存在 ${graph_data_hdfs_path}/u2t_edges/目录
etype2files: "u2a2i:s_1,u2b2i:s_2"
# 每种节点类型对应的文件或目录, 不同类型的节点可以放在同个文件,读取的时候会自动过滤的。
# 下面的示例表示节点保存在 ${graph_data_hdfs_path}/node_types/目录
ntype2files: "u:nodes.txt,i:nodes.txt"
# the pair specified by 'excluded_train_pair' will not be trained, eg "w2q;q2t"
excluded_train_pair: ""
# only infer the node(s) specified by 'infer_node_type', eg "q;t"
infer_node_type: ""
# 目前使用graph_shard 的功能, 对数据进行分片,必须分片为1000 个part文件
#hadoop_shard: True
auto_shard: True
num_part: 1000
# 是否双向边(目前只支持双向边)
symmetry: True
# ---------------------------图游走配置-------------------------------------------------#
# meta_path 元路径定义。 注意跟etype2files变量的边类型对应。用“-”隔开
# 按照下面的设置可以设置多条metapath, 每个";"号是一条用户定义的metapath
meta_path: "u2a2i-i2a2u;i2a2u-u2a2i;u2b2i-i2b2u;i2b2u-u2b2i"
# 游走路径的正样本窗口大小
win_size: 2
# neg_num: 每对正样本对应的负样本数量
neg_num: 5
# walk_len: metapath 游走路径深度
walk_len: 8
# walk_times: 每个起始节点重复n次游走,这样可以尽可能把一个节点的所有邻居游走一遍,使得训练更加均匀。
walk_times: 10
# ---------------------------模型参数配置---------------------------------------------#
# 模型类型选择
model_type: GNNModel
# embedding 维度,需要和hidden_size保持一样。
emb_size: 100
# sparse_type: 稀疏参数服务器的优化器,目前支持adagrad, shared_adam
sparse_type: adagrad_v2
# sparse_lr: 稀疏参数服务器的学习率
sparse_lr: 0.1
# dense_lr: 稠密参数的学习率
dense_lr: 0.0005 #001
# slot_feature_lr: slot特征的学习率
slot_feature_lr: 0.001
init_range: 0.1
# loss_type: 损失函数,目前支持hinge; sigmoid; nce
loss_type: sigmoid
margin: 2.0 # for hinge loss
# 如果slot 特征很多(超过5个), 建议开启softsign,防止数值太大。
softsign: False
# 对比学习损失函数选择: 目前支持 simgcl_loss
gcl_loss: simgcl_loss
# sage 模型设置开关
sage_mode: True
# sage_layer_type: sage 模型类型选择
sage_layer_type: "LightGCN"
sage_alpha: 0.8
samples: [3,2]
infer_samples: [10,10]
sage_act: "relu"
hcl: True
use_degree_norm: True
# 带权采样开关,同时作用于游走和sage子图采样阶段。
weighted_sample: True
# 是否返回边权重,仅用于sage_mode=True模式,如边不带权则默认返回1。
return_weight: False
# 是否要进行训练,如果只想单独热启模型做预估(inference),则可以关闭need_train
need_train: True
# 是否需要进行inference. 如果只想单独训练模型,则可以关闭need_inference
need_inference: True
# 预估embedding的时候,需要的参数,保持默认即可.
dump_node_name: "src_node___id"
dump_node_emb_name: "src_node___emb"
# 是否需要dump游走路径
need_dump_walk: False
# ---------------------------train param config---------------------------------------------#
epochs: 3
# 训练样本的batch_size
batch_size: 50000
infer_batch_size: 30000
chunk_num: 1
# 1 for debug
debug_mode: 0
# 大致设置gpups的显存占用率 默认 0.25
gpups_memory_allocated_rate: 0.05
# 训练模式,可填WHOLE_HBM/MEM_EMBEDDING/SSD_EMBEDDING,默认为MEM_EMBEDDING
train_storage_mode: MEM_EMBEDDING
jupyter: False
version: v_refactor_0104
# ---------------------------例行训练和预测------------------------------#
# 若修改为"online_train",则表示需要进行例行训练,否则默认为普通训练模式。
train_mode: "online_train"
# 例行训练的第一次图数据起始时间。(注意,天级别更新的时候,日期的格式也一定要是20230217/00, 不能省略小时的单位)
start_time: 20230814/00
# 例行训练的小时级间隔(当train_mode=online_train时生效),time_delta=1表示每次训练一个小时数据,然后换到下一个小时。如果是天级别更新,则time_delta=24。
time_delta: 24
# ---------------------------save config---------------------------------------------#
# 为了加快训练速度,可以设置每隔多少个epochs才保存一次模型。默认最后一个epoch训练完一定会保存模型。
save_model_interval: 10
# 触发ssd cache的频率
save_cache_frequency: 4
# 内存中缓存多少个pass
mem_cache_passid_num: 4
# 是否保存为二进制模式,仅在SSD模式下生效
save_binary_mode : False
# 保存模型前,是否需要根据threshold删除embedding
need_shrink: True
newest_time: 20230904/00
参考资料:
GraphSage原理: https://zhuanlan.zhihu.com/p/336195862
Graph4Rec论文: https://arxiv.org/pdf/2112.01035.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号