
Apache Storm 官方文档 —— Trident API 概述
转载自并发编程网 – ifeve.com本文链接地址: Apache Storm 官方文档 —— Trident API 概述
窗口部分的内容是我自己翻译的
Trident 的核心数据模型是“流”(Stream),不过与普通的拓扑不同的是,这里的流是作为一连串 batch 来处理的。流是分布在集群中的不同节点上运行的,并且对流的操作也是在流的各个 partition 上并行运行的。
Trident 中有 5 类操作:
- 针对每个小分区(partition)的本地操作,这类操作不会产生网络数据传输;
- 针对一个数据流的重新分区操作,这类操作不会改变数据流中的内容,但是会产生一定的网络传输;
- 通过网络数据传输进行的聚合操作;
- 针对数据流的分组操作;
- 融合与联结操作。
本地分区操作
本地分区操作是在每个分区块上独立运行的操作,其中不涉及网络数据传输。
函数
函数负责接收一个输入域的集合并选择输出或者不输出 tuple。输出 tuple 的域会被添加到原始数据流的输入域中。如果一个函数不输出 tuple,那么原始的输入 tuple 就会被直接过滤掉。否则,每个输出 tuple 都会复制一份输入 tuple 。假设你有下面这样的函数:
public class MyFunction extends BaseFunction { public void execute(TridentTuple tuple, TridentCollector collector) { for(int i=0; i < tuple.getInteger(0); i++) { collector.emit(new Values(i)); } } }
再假设你有一个名为 “mystream” 的数据流,这个流中包含下面几个 tuple,每个 tuple 中包含有 “a”、“b”、“c” 三个域:
[1, 2, 3] [4, 1, 6] [3, 0, 8]
如果你运行这段代码:
mystream.each(new Fields("b"), new MyFunction(), new Fields("d")))
那么最终输出的结果 tuple 就会包含有 “a”、“b”、“c”、“d” 4 个域,就像下面这样:
[1, 2, 3, 0] [1, 2, 3, 1] [4, 1, 6, 0]
过滤器
过滤器负责判断输入的 tuple 是否需要保留。以下面的过滤器为例:
public class MyFilter extends BaseFilter { public boolean isKeep(TridentTuple tuple) { return tuple.getInteger(0) == 1 && tuple.getInteger(1) == 2; } }
通过使用这段代码:
mystream.each(new Fields("b", "a"), new MyFilter())
mystream.each(new MyFilter())
就可以将下面这样带有 “a”、“b”、“c” 三个域的 tuple
[1, 2, 3] [2, 1, 1] [2, 3, 4]
最终转化成这样的结果 tuple:
//第一行代码输出
[2, 1, 1]
//第二行代码输出
[1, 2, 3]
map和 flatMap
map 返回一个由 组成的Stream
这可以被应用在对于tuple进行1对1的转换
例如,如果有一个单词流,你想把它转换成一个全部大写的单词流,你可以这样定义mapping 函数
public class UpperCase extends MapFunction { @Override public Values execute(TridentTuple input) { return new Values(input.getString(0).toUpperCase()); } }
这个mapping function可以被应用在单词流上用于产生大写的单词流
mystream.map(new UpperCase())
flatMap 和 map 相似,不同的是它可以对流中的values进行1对多的转换,然后把输入流中的生成结果的元素扁平化放到一个新的流中。
例如,如果一个流中含有语句,你想把它转换成含有单词的流,你可以这样定义flatMap函数
public class Split extends FlatMapFunction { @Override public Iterable<Values> execute(TridentTuple input) { List<Values> valuesList = new ArrayList<>(); for (String word : input.getString(0).split(" ")) { valuesList.add(new Values(word)); } return valuesList; } }
这个flatMap函数可以被应用在一个语句流中用于产生单词流
mystream.flatMap(new Split())
当然,这些操作可以进行链式处理,一个全大写的单词流可以从一个语句流转换而来
mystream.flatMap(new Split()).map(new UpperCase())
如果没有传入输出域(Field)参数,map 和 flatMap以输入域作为输出域
如果想在应用 MapFunction和 FlatMapFunction时用新的输出域替换旧的域,可以在调用 map/flatMap时添加 Fields对象做参数
mystream.map(new UpperCase(), new Fields("uppercased"))
输出流只有uppercased这一个域,不论输入流的域是什么。在flatMap上的应用也一样
mystream.flatMap(new Split(), new Fields("word"))
Peek
peek 返回一个由原有流中的trident tuple组成的新的流,但是peek方法中的Consumer action参数会被应用在输入流的每一个trident tuple上。
这个可以用来调试查看tuple
例如:以下代码可以打印 把单词转换成全大写的结果在传入groupBy之前打印出来
mystream.flatMap(new Split()) .map(new UpperCase()) .peek(new Consumer() { @Override public void accept(TridentTuple input) { System.out.println(input.getString(0)); } })
.groupBy(new Fields("word")) .persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"))
min 和 minBy
min 和 minBy操作返回一个trident stream中一批tuple的每一个Partition中的最小value
假如一个trident流包含域 ["device-id", "count"] 和以下tuple的分区
Partition 0: [123, 2] [113, 54] [23, 28] [237, 37] [12, 23] [62, 17] [98, 42] Partition 1: [64, 18] [72, 54] [2, 28] [742, 71] [98, 45] [62, 12] [19, 174] Partition 2: [27, 94] [82, 23] [9, 86] [53, 71] [74, 37] [51, 49] [37, 98]
minBy操作可以被应用于以上tuple的流中,发送出的tuple是每一个Partition中count域的最小值。
mystream.minBy(new Fields("count"))
以上代码应用在以上Partition上的结果是
Partition 0: [123, 2] Partition 1: [62, 12] Partition 2: [82, 23]
在Stream中其他的min和minBy方法有
public <T> Stream minBy(String inputFieldName, Comparator<T> comparator) public Stream min(Comparator<TridentTuple> comparator)
下面的例子展示了这些API如何在一个tuple上使用各自的Comparator来查找最小值
FixedBatchSpout spout = new FixedBatchSpout(allFields, 10, Vehicle.generateVehicles(20)); TridentTopology topology = new TridentTopology(); Stream vehiclesStream = topology.newStream("spout1", spout)
.each(allFields, new Debug("##### vehicles")); Stream slowVehiclesStream = vehiclesStream .min(new SpeedComparator()) // Comparator w.r.t speed on received tuple. .each(vehicleField, new Debug("#### slowest vehicle")); vehiclesStream .minBy(Vehicle.FIELD_NAME, new EfficiencyComparator()) // Comparator w.r.t efficiency on received tuple. .each(vehicleField, new Debug("#### least efficient vehicle"));
这些API的示例程序在TridentMinMaxOfDevicesTopology 和 TridentMinMaxOfVehiclesTopology
max 和 maxBy
max 和 maxBy 操作返回一个trident stream中一批tuple的每一个Partition中的最大value。
依然以min和minBy小节中提到的含有域["device-id", "count"]的trident stream为例
max 和 maxBy操作可以被应用于以上tuple的流中,发送出的tuple是每一个Partition中count域的最大值。
mystream.maxBy(new Fields("count"))
结果是
Partition 0: [113, 54] Partition 1: [19, 174] Partition 2: [37, 98]
在Stream中其他的max和maxBy方法有
public <T> Stream maxBy(String inputFieldName, Comparator<T> comparator) public Stream max(Comparator<TridentTuple> comparator)
下面的例子展示了这些API如何在一个tuple上使用各自的Comparator来查找最大值
FixedBatchSpout spout = new FixedBatchSpout(allFields, 10, Vehicle.generateVehicles(20)); TridentTopology topology = new TridentTopology(); Stream vehiclesStream = topology.newStream("spout1", spout). each(allFields, new Debug("##### vehicles")); Stream slowVehiclesStream = vehiclesStream .min(new SpeedComparator()) // Comparator w.r.t speed on received tuple. .each(vehicleField, new Debug("#### slowest vehicle")); vehiclesStream .minBy(Vehicle.FIELD_NAME, new EfficiencyComparator()) // Comparator w.r.t efficiency on received tuple. .each(vehicleField, new Debug("#### least efficient vehicle"));
这些API的示例程序在TridentMinMaxOfDevicesTopology 和 TridentMinMaxOfVehiclesTopology
Windowing
Trident流可以处理属于同一个滑动窗口里成批的tuple,然后发送出聚合的结果到下一个操作。
Storm中,支持基于处理时间的或tuple的个数的滑动窗口有两种:
1. Tumbling window
2. Sliding window
Tumbling window
一组Tuple被包含在一个基于处理时间或Tuple个数的窗口里,任意一个Tuple仅属于一个窗口。
/** * Returns a stream of tuples which are aggregated results of a tumbling window with every {@code windowCount} of tuples.
* 返回的流中的tuple是由基于Tuple数量形成的滚动窗口内tuple聚合的结果 */ public Stream tumblingWindow(int windowCount, WindowsStoreFactory windowStoreFactory, Fields inputFields, Aggregator aggregator, Fields functionFields); /** * Returns a stream of tuples which are aggregated results of a window that tumbles as duration of {@code windowDuration}.
* 返回的流中的tuple是由基于处理时间滚动形成的窗口内tuple聚合的结果 */ public Stream tumblingWindow(BaseWindowedBolt.Duration windowDuration, WindowsStoreFactory windowStoreFactory,
Fields inputFields, Aggregator aggregator, Fields functionFields);
Sliding window
一组Tuple被包含在一个个窗口里,随着滑动间隔窗口不断滑动。一个Tuple属于多个窗口。
/** * Returns a stream of tuples which are aggregated results of a sliding window with every {@code windowCount} of tuples * and slides the window after {@code slideCount}.
* 返回的流中的tuple是由一个基于tuple个数形成的滑动窗口中聚合的结果,并且在达到slideCount的值后,滑动窗口 */ public Stream slidingWindow(int windowCount, int slideCount, WindowsStoreFactory windowStoreFactory, Fields inputFields, Aggregator aggregator, Fields functionFields); /** * Returns a stream of tuples which are aggregated results of a window which slides at duration of {@code slidingInterval} * and completes a window at {@code windowDuration}
* 返回的流中的tuple是一个基于窗口滑动时间周期形成的窗口中聚合的结果,并且在达到windowDuration的值后,滑动窗口 */ public Stream slidingWindow(BaseWindowedBolt.Duration windowDuration, BaseWindowedBolt.Duration slidingInterval, WindowsStoreFactory windowStoreFactory, Fields inputFields, Aggregator aggregator, Fields functionFields);
滚动窗口和滑动窗口的示例在这里
普通windowing API
以下的普通windowing API,使用了支持的窗口的配置 WindowConfig
public Stream window(WindowConfig windowConfig, WindowsStoreFactory windowStoreFactory, Fields inputFields, Aggregator aggregator, Fields functionFields)
windowConfig 可以使以下任意一种:
SlidingCountWindow.of(int windowCount, int slidingCount) SlidingDurationWindow.of(BaseWindowedBolt.Duration windowDuration, BaseWindowedBolt.Duration slidingDuration) TumblingCountWindow.of(int windowLength) TumblingDurationWindow.of(BaseWindowedBolt.Duration windowLength)
Trident 窗口 API需要 WindowsStoreFactory来存储收到的tuple并聚合生成结果。当前对HBase基本的实现使用HBaseWindowsStoreFactory。
对特定的应用场景它可以进行很大程度的扩展。关于滑动窗口使用HBaseWindowsStoreFactory的例子:
// window-state table should already be created with cf:tuples column HBaseWindowsStoreFactory windowStoreFactory = new HBaseWindowsStoreFactory(
new HashMap<String, Object>(), "window-state",
"cf".getBytes("UTF-8"), "tuples".getBytes("UTF-8")); FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3,
new Values("the cow jumped over the moon"),new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"), new Values("how many apples can you eat"), new Values("to be or not to be the person")); spout.setCycle(true); TridentTopology topology = new TridentTopology(); Stream stream = topology.newStream("spout1", spout).parallelismHint(16).each(new Fields("sentence"), new Split(), new Fields("word")) .window(TumblingCountWindow.of(1000), windowStoreFactory, new Fields("word"), new CountAsAggregator(), new Fields("count")) .peek(new Consumer() { @Override public void accept(TridentTuple input) { LOG.info("Received tuple: [{}]", input); } }); StormTopology stormTopology = topology.build();
对于以上所有API详细的描述在这里
示例程序
这些API的示例程序在TridentHBaseWindowingStoreTopology 和 TridentWindowingInmemoryStoreTopology
partitionAggregate
partitionAggregate 会在一批 tuple 的每个分区上执行一个指定的功能操作。与上面的函数不同,由 partitionAggregate发送出的 tuple 会将输入 tuple 的域替换。以下面这段代码为例:
mystream.partitionAggregate(new Fields("b"), new Sum(), new Fields("sum"))
假如输入流中包含有 “a”、“b” 两个域并且有以下几个 tuple 块:
Partition 0: ["a", 1] ["b", 2] Partition 1: ["a", 3] ["c", 8] Partition 2: ["e", 1] ["d", 9] ["d", 10]
经过上面的代码之后,输出就会变成带有一个名为 “sum” 的域的数据流,其中的 tuple 就是这样的:
Partition 0: [3] Partition 1: [11] Partition 2: [20]
Storm 有三个用于定义聚合器的接口:CombinerAggregator,ReducerAggregator 以及 Aggregator。
这是 CombinerAggregator 接口:
public interface CombinerAggregator<T> extends Serializable { T init(TridentTuple tuple); T combine(T val1, T val2); T zero(); }
CombinerAggregator 会将带有一个域的一个单独的 tuple 返回作为输出。CombinerAggregator 会在每个输入 tuple 上运行初始化函数,然后使用组合函数来组合所有输入的值。如果在某个分区中没有 tuple, CombinerAggregator 就会输出zero 方法的结果。例如,下面是 Count 的实现代码:
public class Count implements CombinerAggregator<Long> { public Long init(TridentTuple tuple) { return 1L; } public Long combine(Long val1, Long val2) { return val1 + val2; } public Long zero() { return 0L; } }
如果你使用 aggregate 方法来代替 partitionAggregate 方法,你就会发现 CombinerAggregator 的好处了。在这种情况下,Trident 会在发送 tuple 之前通过分区聚合操作来优化计算过程。
ReducerAggregator 的接口实现是这样的:
public interface ReducerAggregator<T> extends Serializable { T init(); T reduce(T curr, TridentTuple tuple); }
ReducerAggregator 会使用 init 方法来产生一个初始化的值,然后使用该值对每个输入 tuple 进行遍历,并最终生成并输出一个单独的 tuple,这个 tuple 中就包含有我们需要的计算结果值。例如,下面是将 Count 定义为 ReducerAggregator 的代码:
public class Count implements ReducerAggregator<Long> { public Long init() { return 0L; } public Long reduce(Long curr, TridentTuple tuple) { return curr + 1; } }
ReducerAggregator 同样可以用于 persistentAggregate,你会在后面看到这一点。
最常用的聚合器接口还是下面的 Aggregator 接口:
public interface Aggregator<T> extends Operation { T init(Object batchId, TridentCollector collector); void aggregate(T state, TridentTuple tuple, TridentCollector collector); void complete(T state, TridentCollector collector); }
Aggregator 聚合器可以生成任意数量的 tuple,这些 tuple 也可以带有任意数量的域。聚合器可以在执行过程中的任意一点输出tuple,他们的执行过程是这样的:
- 在处理一批数据之前先调用 init 方法。init 方法的返回值是一个代表着聚合状态的对象,这个对象接下来会被传入 aggregate 方法和 complete 方法中。
- 对于一个区块中的每个 tuple 都会调用 aggregate 方法。这个方法能够更新状态并且有选择地输出 tuple。
- 在区块中的所有 tuple 都被 aggregate 方法处理之后就会调用 complete 方法。
下面是使用 Count 作为聚合器的代码:
public class CountAgg extends BaseAggregator<CountState> { static class CountState { long count = 0; } public CountState init(Object batchId, TridentCollector collector) { return new CountState(); } public void aggregate(CountState state, TridentTuple tuple, TridentCollector collector) { state.count+=1; } public void complete(CountState state, TridentCollector collector) { collector.emit(new Values(state.count)); } }
有时你可能会需要同时执行多个聚合操作。这个过程叫做链式处理,可以使用下面这样的代码来实现:
mystream.chainedAgg() .partitionAggregate(new Count(), new Fields("count")) .partitionAggregate(new Fields("b"), new Sum(), new Fields("sum")) .chainEnd()
这段代码会在每个分区上分别执行 Count 和 Sum 聚合器,而输出中只会包含一个带有 [“count”, “sum”] 域的单独的 tuple。
stateQuery 与 partitionPersist
stateQuery 与 partitionPersist 会分别查询、更新 state 数据源。你可以参考 Trident State 文档 来了解如何使用它们。
projection
projection 方法只会保留操作中指定的域。如果你有一个带有 [“a”, “b”, “c”, “d”] 域的数据流,通过执行这段代码:
mystream.project(new Fields("b", "d"))
就会使得输出数据流中只包含有 [“b”, “d”] 域。
重分区操作
重分区操作会执行一个用来改变在不同的任务间分配 tuple 的方式的函数。在重分区的过程中分区的数量也可能会发生变化(例如,重分区之后的并行度就有可能会增大)。重分区会产生一定的网络数据传输。下面是重分区操作的几个函数:
- shuffle:通过随机轮询算法来重新分配目标区块的所有 tuple。
- broadcast:每个 tuple 都会被复制到所有的目标区块中。这个函数在 DRPC 中很有用 —— 比如,你可以使用这个函数来获取每个区块数据的查询结果。
- partitionBy:该函数会接收一组域作为参数,并根据这些域来进行分区操作。可以通过对这些域进行哈希化,并对目标分区的数量取模的方法来选取目标区块。partitionBy 函数能够保证来自同一组域的结果总会被发送到相同的目标区间。
- global:这种方式下所有的 tuple 都会被发送到同一个目标分区中,而且数据流中的所有的块都会由这个分区处理。
- batchGlobal:同一个 batch 块中的所有 tuple 会被发送到同一个区块中。当然,在数据流中的不同区块仍然会分配到不同的区块中。
- partition:这个函数使用自定义的分区方法,该方法会实现
backtype.storm.grouping.CustomStreamGrouping接口。
聚类操作
Trident 使用 aggregate 方法和 persistentAggregate 方法来对数据流进行聚类操作。其中,aggregate 方法会分别对数据流中的每个 batch 进行处理,而 persistentAggregate 方法则会对数据流中的所有 batch 执行聚类处理,并将结果存入某个 state 中。
在数据流上执行 aggregate 方法会执行一个全局的聚类操作。在你使用 ReducerAggregator 或者 Aggregator 时,数据流首先会被重新分区成一个单独的分区,然后聚类函数就会在该分区上执行操作。而在你使用 CombinerAggregator 时,Trident 首先会计算每个分区的部分聚类结果,然后将这些结果重分区到一个单独的分区中,最后在网络数据传输完成之后结束这个聚类过程。CombinerAggregator 比其他的聚合器的运行效率更高,在聚类时应该尽可能使用CombinerAggregator。
下面是一个使用 aggregate 来获取一个 batch 的全局计数值的例子:
mystream.aggregate(new Count(), new Fields("count"))
与 partitionAggregate 一样,aggregate 的聚合器也可以进行链式处理。然而,如果你在一个处理链中同时使用了CombinerAggregator和非 CombinerAggregator,Trident 就不能对部分聚类操作进行优化了。
想要了解更多使用 persistentAggregate 的方法,可以参考 Trident State 文档 一文。
对分组数据流的操作
通过对指定的Field执行 partitionBy 操作后产生新的数据流,groupBy 操作可以将这个数据流进行重分区,使得相同的域的 tuple 分组可以聚集在一起。例如,下面是一个 groupBy 操作的示例:
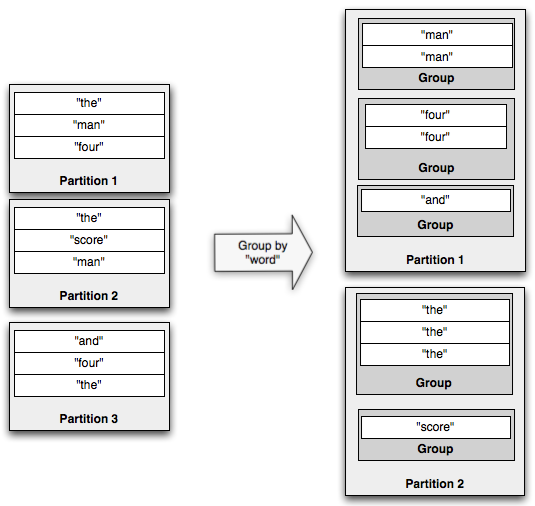
如果你在分组数据流上执行聚合操作,聚合器会在每个分组(而不是整个区块)上运行。persistentAggregate 同样可以在一个分组数据里上运行,这种情况下聚合结果会存储在 MapState 中,其中的 key 就是分组的域名。
和其他操作一样,对分组数据流的聚合操作也可以以链式的方式执行。
融合(Merge)与联结(join)
Trident API 的最后一部分是联结不同的数据流的操作。联结数据流最简单的方式就是将所有的数据流融合到一个流中。你可以使用 TridentTopology 的 merge 方法实现该操作,比如这样:
topology.merge(stream1, stream2, stream3);
Trident 会将融合后的新数据流的域命名为为第一个数据流的输出域。
联结数据流的另外一种方法是使用 join。像 SQL 那样的标准 join 操作只能用于有限的输入数据集,对于无限的数据集就没有用武之地了。Trident 中的 join 只会应用于每个从 spout 中输出的小 batch。
下面是两个流的 join 操作的示例,其中一个流含有 [“key”, “val1”, “val2”] 域,另外一个流含有 [“x”, “val1”] 域:
topology.join(stream1, new Fields("key"), stream2, new Fields("x"), new Fields("key", "a", "b", "c"));
上面的例子会使用 “key” 和 “x” 作为 join 的域来联结 stream1 和 stream2。Trident 要求先定义好新流的输出域,因为输入流的域可能会覆盖新流的域名。从 join 中输出的 tuple 中会包含:
- join 域的列表。在这个例子里,输出的 “key” 域与 stream1 的 “key” 域以及 stream2 的 “x” 域对应。
- 来自所有流的非 join 域的列表。这个列表是按照传入 join 方法的流的顺序排列的。在这个例子里,“ a” 和 “b” 域与 stream1 的 “val1” 和 “val2” 域对应;而 “c” 域则与 stream2 的 “val1” 域相对应。
在对不同的 spout 发送出的流进行 join 时,这些 spout 上会按照他们发送 batch 的方式进行同步处理。也就是说,一个处理中的 batch 中含有每个 spout 发送出的 tuple。
到这里你大概仍然会对如何进行窗口 join 操作感到困惑。窗口操作(包括平滑窗口、滚动窗口等 —— 译者注)主要是指将当前的 tuple 与过去若干小时时间段内的 tuple 联结起来的过程。
你可以使用 partitionPersist 和 stateQuery 来实现这个过程。过去一段时间内的 tuple 会以 join 域为关键字被保存到一个 state 源中。然后就可以使用 stateQuery 查询 join 域来实现这个“联结”(join)的过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号