图解Metrics, tracing, and logging
Logging,Metrics 和 Tracing
最近在看Gophercon大会PPT的时候无意中看到了关于Metrics,Tracing和Logging相关的一篇文章,凑巧这些我基本都接触过,也是去年后半年到现在一直在做和研究的东西。从去年的关于Metrics的goappmonitor,到今年在排查问题时脑洞的基于log全链路(Tracing)追踪系统的设计,正好是对这三个话题的实践。这不禁让我对它们的关系进行思考:Metrics和Looging的区别是什么?Tracing还需要Logging吗?我们什么时候需要Metrics?它们之间有什么关联?
这其实也是我在设计goappmonitor的时候一直困扰我的问题,当时一直在想我要构建一个监控go程序的应用,它能够度量请求,函数调用,内存,CPU等等这些指标,无疑我需要侵入性的去打点,那么问题来了,我们的应用中是有自己的日志系统的,那么同一份数据需要记录两次吗?我该如何划分这个界线?毫无疑问,Metrcis和Logging是有数据重叠的。我们可以任务Metrics是对可观测性指标的一种度量,例如请求数,函数调用次数等,但是对于Metrcis来说,它有着自己独特的属性——聚合。另外,我们知道我们记录日志(Logging)是以事件为元数据,即记录当前发生了什么,这是Logging的关注属性。在构想产品全链路追踪系统时,类似的问题再一次出现,我在记录Tracing数据的时候,或多多少会有Logging的数据,在Tracing中我认为重要的是链路数据指标属性,例如调用了哪些函数栈,该请求处理时间是多少等等,同样我们会在函数中记录得到了哪些请求,即Logging,但Tracing也有着自己独特的属性——请求范围。
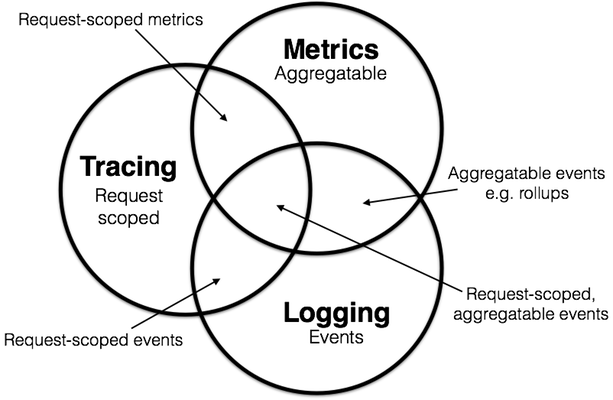
如下图:
日志,什么是日志,不知道大家有没有想过它的定义或者边界。Logging即是记录处理的离散事件,比如我们应用的调试信息或者错误信息等发送到ES;审计跟踪时间信息通过Kafka处理送到BigTable等数据仓储等等,大多数情况下记录的数据很分散,并且相互独立,也许是错误信息,也许仅仅只是记录当前的事件状态,或者是警告信息等等。
当我们想知道我们服务的请求QPS是多少,或者当天的用户登录次数等等,这时我们可能需要将一部分事件进行聚合或计数,也就是我们说的Metrics。可聚合性即是Metrics的特征,它们是一段时间内某个度量(计数器或者直方图)的原子或者是元数据。例如接收的HTTP数量可以被建模为计数器,每次的HTTP请求即是我们的度量元数据,可以进行简单的加法聚合,当持续了一段时间我们又可以建模为直方图。
Logging是处理请求范围内的信息,即可以绑定到系统中单个事务对象的生命周期的任何数据或元数据。对于每一次Tracing,例如HTTP请求的Tracing,我们只需要关注请求目前到达的节点状态,当前耗时,谁接收了这个请求等等,不用关系目前的系统日志,错误信息等等这些事件。或者像出站RPC到远程服务的持续时间; 将实际SQL查询的文本发送到数据库; 或入站HTTP请求的相关ID等等。
通过以上我们可以将重叠部分这样定义:
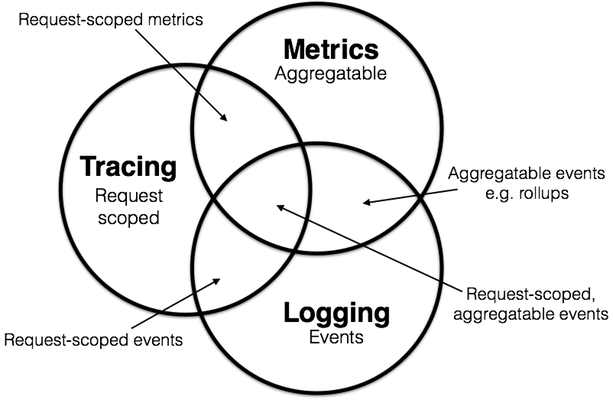
有人可能会想到,对于许多典型的云应用程序最终都将成为Tracing,因此该边界是在更广泛的跟踪背景下进行讨论。 但我们现在可以看到,并不是所有的Logging事件都是可聚合或者说可聚合的意义;并不是所有的度量都有在Tracing之中。 它们之间有相互重叠,也有绝对的覆盖。
在业界对于以上的实践可以看到现有系统进行的分类。例如,Prometheus开始专注于衡量系统,随着时间的推移可能会越来越多地追踪,从而成为Tracing的指标,但可能不会太深入到日志记录中,同时基于Dapper的各类分布式链路追踪系统也在不断出现。 ELK提供log的记录,滚动和聚合,并在其他领域不停的积累更多的特性,并集成进来。
所以,日志系统,度量系统,追踪系统这三个纬度所关注重点是不一样的。一般来说日志系统是对我们应用或者系统事件做一个记录,这些记录是我们问题排查,取证的一些依据;度量系统是对某些我们关注事件的聚合,当达到一定指标我们会设置告警,会设置自适应机制,会有容灾等等;在追踪系统我们更关注请求的质量和服务可行性,是我们优化系统,排查问题的高阶方法。一般来说,它们的优先级依次降低。
参考文献:
本文来自博客园,作者:sunsky303,转载请注明原文链接:https://www.cnblogs.com/sunsky303/p/9686459.html

