分布式任务系统gearman的python实战
Gearman是一个用来把工作委派给其他机器、分布式的调用更适合做某项工作的机器、并发的做某项工作在多个调用间做负载均衡、或用来在调用其它语言的函数的系统。Gearman是一个分发任务的程序框架,可以用在各种场合,开源、多语言支持、灵活、快速、可嵌入、可扩展、无消息大小限制、可容错,与Hadoop相比,Gearman更偏向于任务分发功能。它的任务分布非常简单,简单得可以只需要用脚本即可完成。Gearman最初用于LiveJournal的图片resize功能,由于图片resize需要消耗大量计算资 源,因此需要调度到后端多台服务器执行,完成任务之后返回前端再呈现到界面。
gearman的任务传递模式是一对一的,不能实现一对多,一个client通过job server最后只能够到达一个worker上。如果需要一对多,需要定义多个worker的function,依次向这些worker进行发送,非常的不方便。这一点就不如ZeroMQ,ZeroMQ支持的模式很多,能够满足各种消息队列需求。他们用在不同的场合,Gearman是分布式任务系统,而ZeroMQ是分布式消息系统,任务只需要做一次就行。
1. Server
1.1 Gearman工作原理
Gearman 服务有很多要素使得它不仅仅是一种提交和共享工作的方式,但是主要的系统只由三个组件组成: gearmand 守护进程(server),用于向 Gearman 服务提交请求的 client ,执行实际工作的 worker。其关系如下图所示:
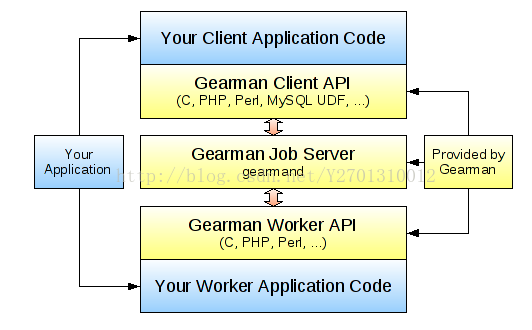
Gearmand server执行一个简单的功能,即从client收集job请求并充当一个注册器,而worker可以在此提交关于它们支持的job和操作类型的信息,这样server实际上就充当了Client和Worker的中间角色。Client将job直接丢给server,而server根据worker提交的信息,将这些job分发给worker来做,worker完成后也可返回结果,server将结果传回client。举个例子,在一个公司里面,有老板1、老板2、老板3(client),他们的任务就是出去喝酒唱歌拉项目(job),将拉来的项目直接交给公司的主管(server),而主管并不亲自来做这些项目,他将这些项目分给收手下的员工(worker)来做,员工做完工作后,将结果交给主管,主管将结果报告给老板们即可。
要使用gearman,首先得安装server,下载地址:https://launchpad.net/gearmand。当下载安装完成后,可以启动gearmand,启动有很多参数选项,可以man gearmand来查看,主要的 选项有:
- -b, --backlog=BACKLOG Number of backlog connections for listen.
- -d, --daemon Daemon, detach and run in the background.
- -f, --file-descriptors=FDS Number of file descriptors to allow for the process
- (total connections will be slightly less). Default is max allowed for user.
- -h, --help Print this help menu.
- -j, --job-retries=RETRIES Number of attempts to run the job before the job server removes it. Thisis helpful to ensure a bad job does not crash all available workers. Default is no limit.
- -l, --log-file=FILE Log file to write errors and information to. Turning this option on also forces the first verbose level to be enabled.
- -L, --listen=ADDRESS Address the server should listen on. Default is INADDR_ANY.
- -p, --port=PORT Port the server should listen on.
- -P, --pid-file=FILE File to write process ID out to.
- -r, --protocol=PROTOCOL Load protocol module.
- -R, --round-robin Assign work in round-robin order per workerconnection. The default is to assign work in the order of functions added by the worker.
- -q, --queue-type=QUEUE Persistent queue type to use.
- -t, --threads=THREADS Number of I/O threads to use. Default=0.
- -u, --user=USER Switch to given user after startup.
- -v, --verbose Increase verbosity level by one.
- -V, --version Display the version of gearmand and exit.
- -w, --worker-wakeup=WORKERS Number of workers to wakeup for each job received. The default is to wakeup all available workers.
启动gearmand:
- sudo gearmand --pid-file=/var/run/gearmand/gearmand.pid --daemon --log-file=/var/log/gearman.log
1.2 实例化queue与容错
Gearman默认是将queue保存在内存中的,这样能够保障速速,但是遇到宕机或者server出现故障时,在内存中缓存在queue中的任务将会丢失。Gearman提供了了queue实例化的选项,能够将queue保存在数据库中,比如:SQLite3、Drizzle、MySQL、PostgresSQL、Redis(in dev)、MongoDB(in dev).在执行任务前,先将任务存入持久化队列中,当执行完成后再将该任务从持久化队列中删除。要使用db来实例化queue,除了在启动时加入-q参数和对应的数据库之外,还需要根据具体的数据库使用相应的选项,例如使用sqlit3来实例化queue,并指明使用用来存储queue的文件:
- gearmand -d -q libsqlite3 --libsqlite3-db=/tmp/demon/gearman.db --listen=localhost --port=4370
再如使用mysql来实例化queue,选项为:
- <pre name="code" class="plain">/usr/local/gearmand/sbin/gearmand -d -u root \
- –queue-type=MySQL \
- –mysql-host=localhost \
- –mysql-port=3306 \
- –mysql-user=gearman \
- –mysql-password=123456 \
- –mysql-db=gearman \
- –mysql-table=gearman_queue
还要创建相应的数据库和表,并创建gearman用户,分配相应的权限:
- CREATE DATABASE gearman;
- CREATE TABLE `gearman_queue` (
- `id` int(10) unsigned NOT NULL AUTO_INCREMENT,
- `unique_key` varchar(64) NOT NULL,
- `function_name` varchar(255) NOT NULL,
- `when_to_run` int(10) NOT NULL,
- `priority` int(10) NOT NULL,
- `data` longblob NOT NULL,
- PRIMARY KEY (`id`),
- UNIQUE KEY `unique_key_index` (`unique_key`,`function_name`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- create USER gearman@localhost identified by ’123456′;
- GRANT ALL on gearman.* to gearman@localhost;
可以在gearman的配置文件中加入相关配置,以免每次启动都需要写一堆东西:
- # /etc/conf.d/gearmand: config file for /etc/init.d/gearmand
- # Persistent queue store
- # The following queue stores are available:
- # drizzle|memcache|mysql|postgre|sqlite|tokyocabinet|none
- # If you do not wish to use persistent queues, leave this option commented out.
- # Note that persistent queue mechanisms are mutally exclusive.
- PERSISTENT="mysql"
- # Persistent queue settings for drizzle, mysql and postgre
- #PERSISTENT_SOCKET=""
- PERSISTENT_HOST="localhost"
- PERSISTENT_PORT="3306"
- PERSISTENT_USER="gearman"
- PERSISTENT_PASS="your-pass-word-here"
- PERSISTENT_DB="gearman"
- PERSISTENT_TABLE="gearman_queue"
- # Persistent queue settings for sqlite
- #PERSISTENT_FILE=""
- # Persistent queue settings for memcache
- #PERSISTENT_SERVERLIST=""
- # General settings
- #
- # -j, --job-retries=RETRIES Number of attempts to run the job before the job
- # server removes it. Thisis helpful to ensure a bad
- # job does not crash all available workers. Default
- # is no limit.
- # -L, --listen=ADDRESS Address the server should listen on. Default is
- # INADDR_ANY.
- # -p, --port=PORT Port the server should listen on. Default=4730.
- # -r, --protocol=PROTOCOL Load protocol module.
- # -t, --threads=THREADS Number of I/O threads to use. Default=0.
- # -v, --verbose Increase verbosity level by one.
- # -w, --worker-wakeup=WORKERS Number of workers to wakeup for each job received.
- # The default is to wakeup all available workers.
- GEARMAND_PARAMS="-L 127.0.0.1 --verbose=DEBUG"
这其实并不是一个很好的方案,因为当使用数据库来实例化queue时,会增加两个步骤:Client和worker必须连接到server上去读写job,并且数据库在处理的速度上也会大大降低。在大并发任务量的情况下,性能会受到直接影响,你会发现SQLite或者mysql并不能满足处理大量BLOB的性能要求,job会不断地积攒而得不到处理,给一个任务犹如石牛如一样海毫无反应。归根结底,需要根据自己的应用场景,合理设计一些测试用例和自动化脚本,通过实际的运行状态进行参数的调整。
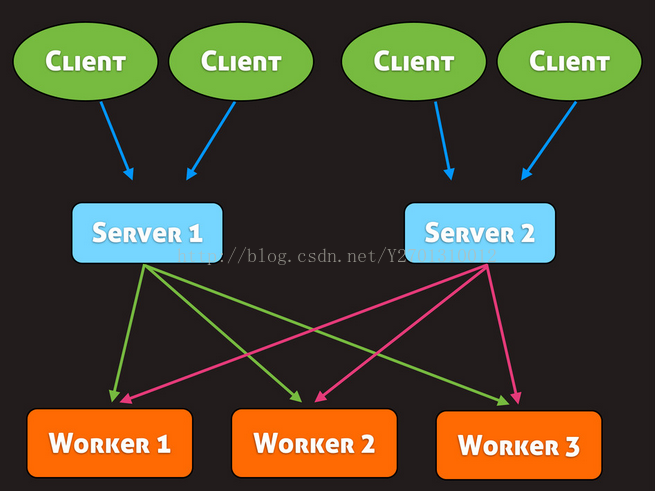
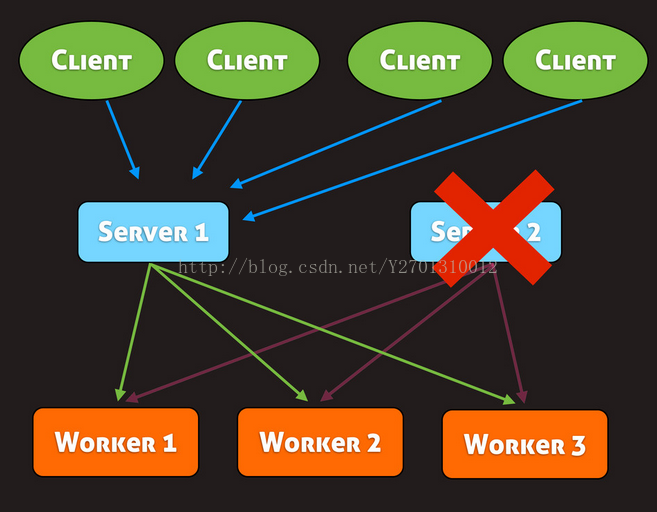
job分布式系统一个基本的特点就是要有单点容错能力(no single point failure),还不能有单点性能瓶颈(no single point of bottleneck)。即:一个节点坏了不影响整个系统的业务,一个节点的性能不能决定整个系统的性能。那如果server挂了该怎么办?解决方法是使用多个server:
- gearmand -d -q libsqlite3 --listen=localhost --port=4370
- gearmand -d -q libsqlite3 --listen=localhost --port=4371
每个client连接多个server,并使用负载最低的那个server,当该server挂掉之后,gearman会自动切换到另一个server上,如下图所示:
1.3 轮询调度
当job不断地增加时,我们可能需要增加worker服务器来增加处理能力,但你可能会发现任务并不是均匀地分布在各个worker服务器上,因为server分配任务给worker的方式默认按照循序分配的,比如你现有worker-A,在server上注册了5个worker进程,随着任务的增加,又加了一台worker-B,并向同一个server注册了5个worker进程。默认情况下,server会按照worker注册的先后顺序进行调度,即:只有给worker-A分配满任务后才会给worker-B分配任务,即分配方式是wA, wA,wA, wA,wA,wB, wB,wB, wB, wB。为了能够给worker-A和worker-B均匀地分配任务,server可以采用轮询的方式给worker服务器分配任务,即分配方式为: wA, wB, wA, wB ...,那么在启动server时加上选项:-R或者--round-robin
1.4 受限唤醒
根据gearman协议的设计,Worker 如果发现队列中没有任务需要处理,是可以通过发送 PRE_SLEEP 命令给服务器,告知说自己将进入睡眠状态。在这个状态下,Worker 不会再去主动抓取任务,只有服务器发送 NOOP 命令唤醒后,才会恢复正常的任务抓取和处理流程。因此 Gearmand 在收到任务时,会去尝试唤醒足够的 Worker 来抓取任务;此时如果 Worker 的总数超过可能的任务数,则有可能产生惊群效应。而通过 –worker-wakeup 参数,则可以指定收到任务时,需要唤醒多少个 Worker 进行处理,避免在 Worker 数量非常大时,发送大量不必要的 NOOP 报文,试图唤醒所有的 Worker。
1.6 线程模型
Gearman中有三种线程:
- 监听和管理线程。只有一个(负责接收连接,然后分配给I/O线程来处理,如果有多个I/O线程的话,同时也负责启动和关闭服务器,采用libevent来管理socket和信号管道)
- I/O线程。可以有多个(负责可读可写的系统调用和对包初步的解析,将初步解析的包放入各自的异步队列中,每个I/O线程都有自己的队列,所以竞争很少,通过-t选项来指定I/O线程数)
- 处理线程。只有一个(负责管理各种信息列表和哈希表,比如跟踪唯一键、工作跟踪句柄、函数、工作队列等。将处理结果信息包返回给I/O线程,I/O线程将该包挑选出来并向该连接发送数据)
进程句柄数
- flier@debian:~$ ulimit -n
- 1024
- flier@debian:~$ ulimit -HSn 4096 // 设置进程句柄数的最大软硬限制
- 4096
- flier@debian:~$ cat /proc/sys/fs/file-max
- 24372
- flier@debian:~# sysctl -w fs.file-max=100000
- 100000
CAP_SYS_RESOURCE capability) may make arbitrary changes to either limit value."
2. Client
- import gearman
- import time
- from gearman.constants import JOB_UNKNOWN
- def check_request_status(job_request):
- """check the job status"""
- if job_request.complete:
- print 'Job %s finished! Result: %s - %s' % (job_request.job.unique, job_request.state, job_request.result)
- elif job_request.time_out:
- print 'Job %s timed out!' % job_request.unique
- elif job_request.state == JOB_UNKNOWN:
- print "Job %s connection failed!" % job_request.unique
- gm_client = gearman.GearmanClient(['localhost:4730','localhost:4731'])
- complete_job_request = gm_client.submit_job("reverse", "Hello World!")
- check_request_status(complete_job_request)
2.1 task与job
- Task是一组job,在下发后会执行并返回结果给调用方
- Task内的子任务悔下发给多个work并执行
- client下放给server的任务为job,而整个下方并返回结果的过程为task,每个job会在一个work上执行
- task是一个动态的概念,而job是一个静态的概念。这有点类似“进程”和“程序”概念的区别。既然是动态的概念,就有完成(complete)、超时(time_out)、携带的job不识别(JOB_UNKNOWN)等状态
2.2 job优先级(priority)
2.3 同步与异步(background)

2.4 阻塞与非阻塞(wait_until_complete)
2.5 送多个job
- GearmanClient.submit_multiple_jobs(jobs_to_submit, background=False, wait_until_complete=True, max_retries=0, poll_timeout=None)
这里jobs_to_submit是一组job,每个job是上述格式的字典,这里解释一下unique,unique是设置task的unique key,即在小结2.1中的job_request.job.unique的值,如果不设置的话,会自动分配。
- GearmanClient.wait_until_jobs_accepted(job_requests, poll_timeout=None)
- GearmanClient.wait_until_jobs_completed(job_requests, poll_timeout=None)
- GearmanClient.submit_multiple_requests(job_requests, wait_until_complete=True, poll_timeout=None)
- GearmanClient.wait_until_jobs_accepted(job_requests, poll_timeout=None)
- GearmanClient.wait_until_jobs_completed(job_requests, poll_timeout=None)
下面是官网给的一个同步非阻塞方式发送多个job的例子,在该例子的最后,在取得server返回结果之前,用了wait_until_jobs_completed函数来等待task中的所有job返回结果:
- import time
- gm_client = gearman.GearmanClient(['localhost:4730'])
- list_of_jobs = [dict(task="task_name", data="binary data"), dict(task="other_task", data="other binary data")]
- submitted_requests = gm_client.submit_multiple_jobs(list_of_jobs, background=False, wait_until_complete=False)
- # Once we know our jobs are accepted, we can do other stuff and wait for results later in the function
- # Similar to multithreading and doing a join except this is all done in a single process
- time.sleep(1.0)
- # Wait at most 5 seconds before timing out incomplete requests
- completed_requests = gm_client.wait_until_jobs_completed(submitted_requests, poll_timeout=5.0)
- for completed_job_request in completed_requests:
- check_request_status(completed_job_request)
- import time
- gm_client = gearman.GearmanClient(['localhost:4730'])
- list_of_jobs = [dict(task="task_name", data="task binary string"), dict(task="other_task", data="other binary string")]
- failed_requests = gm_client.submit_multiple_jobs(list_of_jobs, background=False)
- # Let's pretend our assigned requests' Gearman servers all failed
- assert all(request.state == JOB_UNKNOWN for request in failed_requests), "All connections didn't fail!"
- # Let's pretend our assigned requests' don't fail but some simply timeout
- retried_connection_failed_requests = gm_client.submit_multiple_requests(failed_requests, wait_until_complete=True, poll_timeout=1.0)
- timed_out_requests = [job_request for job_request in retried_requests if job_request.timed_out]
- # For our timed out requests, lets wait a little longer until they're complete
- retried_timed_out_requests = gm_client.submit_multiple_requests(timed_out_requests, wait_until_complete=True, poll_timeout=4.0)
2.6 序列化
- import pickle
- class PickleDataEncoder(gearman.DataEncoder):
- @classmethod
- def encode(cls, encodable_object):
- return pickle.dumps(encodable_object)
- @classmethod
- def decode(cls, decodable_string):
- return pickle.loads(decodable_string)
- class PickleExampleClient(gearman.GearmanClient):
- data_encoder = PickleDataEncoder
- my_python_object = {'hello': 'there'}
- gm_client = PickleExampleClient(['localhost:4730'])
- gm_client.submit_job("task_name", my_python_object)
3 worker
3.1 主要API
- GearmanWorker.set_client_id(client_id):设置自身ID
- GearmanWorker.register_task(task, callback_function):为task注册处理函数callback_function,其中callback_function的定义格式为:
- def function_callback(calling_gearman_worker, current_job):
- return current_job.data
- GearmanWorker.unregister_task(task):注销worker上定义的函数
- GearmanWorker.work(poll_timeout=60.0): 无限次循环, 完成发送过来的job.
- GearmanWorker.send_job_data(current_job, data, poll_timeout=None): Send a Gearman JOB_DATA update for an inflight job
- GearmanWorker.send_job_status(current_job, numerator, denominator, poll_timeout=None):Send a Gearman JOB_STATUS update for an inflight job
- GearmanWorker.send_job_warning(current_job, data, poll_timeout=None):Send a Gearman JOB_WARNING update for an inflight job
3.2 简单示例
- import gearman
- gm_worker = gearman.GearmanWorker(['localhost:4730'])
- def task_listener_reverse(gearman_worker, gearman_job):
- print 'Reversing string:' + gearman_job.data
- return gearman_job.data[::-1]
- gm_worker.set_client_id("worker_revers")
- gm_worker.register_task("reverse", task_listener_reverse)
- gm_worker.work()


3.2 返回结果
- GearmanWorker.send_job_data(current_job, data, poll_timeout=None): Send a Gearman JOB_DATA update for an inflight job
- GearmanWorker.send_job_status(current_job, numerator, denominator, poll_timeout=None): Send a Gearman JOB_STATUS update for an inflight job
- GearmanWorker.send_job_warning(current_job, data, poll_timeout=None): Send a Gearman JOB_WARNING update for an inflight job
- gm_worker = gearman.GearmanWorker(['localhost:4730'])
- # See gearman/job.py to see attributes on the GearmanJob
- # Send back a reversed version of the 'data' string through WORK_DATA instead of WORK_COMPLETE
- def task_listener_reverse_inflight(gearman_worker, gearman_job):
- reversed_data = reversed(gearman_job.data)
- total_chars = len(reversed_data)
- for idx, character in enumerate(reversed_data):
- gearman_worker.send_job_data(gearman_job, str(character))
- gearman_worker.send_job_status(gearman_job, idx + 1, total_chars)
- return None
- # gm_worker.set_client_id is optional
- gm_worker.register_task('reverse', task_listener_reverse_inflight)
- # Enter our work loop and call gm_worker.after_poll() after each time we timeout/see socket activity
- gm_worker.work()
3.3 数据序列化
- import json # Or similarly styled library
- class JSONDataEncoder(gearman.DataEncoder):
- @classmethod
- def encode(cls, encodable_object):
- return json.dumps(encodable_object)
- @classmethod
- def decode(cls, decodable_string):
- return json.loads(decodable_string)
- class DBRollbackJSONWorker(gearman.GearmanWorker):
- data_encoder = JSONDataEncoder
- def after_poll(self, any_activity):
- # After every select loop, let's rollback our DB connections just to be safe
- continue_working = True
- # self.db_connections.rollback()
- return continue_working
Polling callback to notify any outside listeners whats going on with the GearmanWorker.
Return True to continue polling, False to exit the work loop
4 admin_client
前面讲了Client和Worker,对于server也提供了一些API,可以对其进行监控和设置,比如:设置queue大小、关闭连接、查看状态、查看worker等,用于操作的对象时GearmanAdminClient,其定义如下:
- GearmanAdminClient.send_maxqueue(task, max_size): Sends a request to change the maximum queue size for a given task
- GearmanAdminClient.send_shutdown(graceful=True): Sends a request to shutdown the connected gearman server
- GearmanAdminClient.get_status():Retrieves a list of all registered tasks and reports how many items/workers are in the queue
- GearmanAdminClient.get_version(): Retrieves the version number of the Gearman server
- GearmanAdminClient.get_workers():Retrieves a list of workers and reports what tasks they’re operating on
- GearmanAdminClient.ping_server(): Sends off a debugging string to execute an application ping on the Gearman server, return the response time
- gm_admin_client = gearman.GearmanAdminClient(['localhost:4730'])
- # Inspect server state
- status_response = gm_admin_client.get_status()
- version_response = gm_admin_client.get_version()
- workers_response = gm_admin_client.get_workers()
- response_time = gm_admin_client.ping_server()
5. job对象
5.1 GearmanJob
GearmanJob对象提供了发送到server的job的最基本信息,其定义如下:
class gearman.job.GearmanJob(connection, handle, task, unique, data)
server信息
- GearmanJob.connection: GearmanConnection - Server assignment. Could be None prior to client job submission
- GearmanJob.handle:string - Job’s server handle. Handles are NOT interchangeable across different gearman servers
- GearmanJob.task:string - Job’s task
- GearmanJob.unique:string - Job’s unique identifier (client assigned)
- GearmanJob.data:binary - Job’s binary payload
5.2 GearmanJobRequest
跟踪job发送
- GearmanJobRequest.gearman_job: GearmanJob - Job that is being tracked by this GearmanJobRequest object
- GearmanJobRequest.priority: PRIORITY_NONE [default]、PRIORITY_LOW、PRIORITY_HIGH
- GearmanJobRequest.background: boolean - Is this job backgrounded?
- GearmanJobRequest.connection_attempts: integer - Number of attempted connection attempts
- GearmanJobRequest.max_connection_attempts: integer - Maximum number of attempted connection attempts before raising an exception
跟踪job执行过程
- GearmanJobRequest.result: binary - Job’s returned binary payload - Populated if and only if JOB_COMPLETE
- GearmanJobRequest.exception: binary - Job’s exception binary payload
- GearmanJobRequest.state:
- GearmanJobRequest.timed_out: boolean - Did the client hit its polling_timeout prior to a job finishing?
- GearmanJobRequest.complete: boolean - Does the client need to continue to poll for more updates from this job?
- JOB_UNKNOWN - Request state is currently unknown, either unsubmitted or connection failed
- JOB_PENDING - Request has been submitted, pending handle
- JOB_CREATED - Request has been accepted
- JOB_FAILED - Request received an explicit job failure (job done but errored out)
- JOB_COMPLETE - Request received an explicit job completion (job done with results)
跟踪运行中的job状态
- GearmanJobRequest.warning_updates: collections.deque - Job’s warning binary payloads
- GearmanJobRequest.data_updates: collections.deque - Job’s data binary payloads
- GearmanJobRequest.status: dictionary - Job’s status
- handle - string - Job handle
- known - boolean - Is the server aware of this request?
- running - boolean - Is the request currently being processed by a worker?
- numerator - integer
- denominator - integer
- time_received - integer - Time last updated
本文来自博客园,作者:sunsky303,转载请注明原文链接:https://www.cnblogs.com/sunsky303/p/8779507.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号