Git合并时一些鲜为人知的坑
1. 反复解决同一个冲突
最常见的原因:
多人团队中开启了rebase ,对commit顺序造成破坏,使得merge 其他分支时可能找不到原始commit id的关联信息,就需要重新merge conflicts.
2. 明明合并完了,又让从头合并
当然这和用rebase有关的, 关键是已经解决了冲突,为啥还让从头再来一次。问题出在了git pull上。
就像Mark Twain Blaise Pascal的笑话里说的那样:我没有时间让它更短些。
最常说的关于git使用的一个经验就是:
不要用git pull,用git fetch和git merge代替它。
git pull 不完全等于 git fetch + git merge
fetch同pull的区别在于:
git fetch:是从远程获取最新版本到本地,不会自动merge.
而git pull是从远程获取最新版本并merge到本地仓库.
从安全角度出发,git fetch比git pull更安全,因为我们可以先比较本地与远程的区别后,选择性的合并。
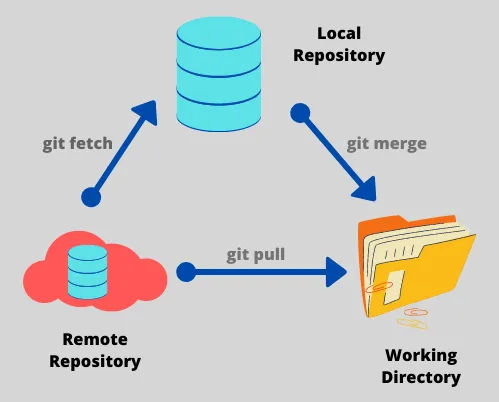
请看上图, pull不等于fetch+merge这么简单。 pull拉取远程文件直接和本地文件对比,从共同祖先提交开始回放remote的提交,而git merge是本地repo和本地文件的对比合并,这里得用到了repo的索引,这样已经Merge的文件会复用repo中已经解决冲突的信息,这样就不会有从头开始合并了。
git pull的问题是它把过程的细节都隐藏了起来,以至于你不用去了解git中各种类型分支的区别和使用方法。当然,多数时候这是没问题的,但一旦代码有问题,你很难找到出错的地方。看起来git pull的用法会使你吃惊,简单看一下git的使用文档应该就能说服你。
将下载(fetch)和合并(merge)放到一个命令里的另外一个弊端是,你的本地工作目录在未经确认的情况下就会被远程分支更新。当然,除非你关闭所有的安全选项,否则git pull在你本地工作目录还不至于造成不可挽回的损失,但很多时候我们宁愿做的慢一些,也不愿意返工重来。
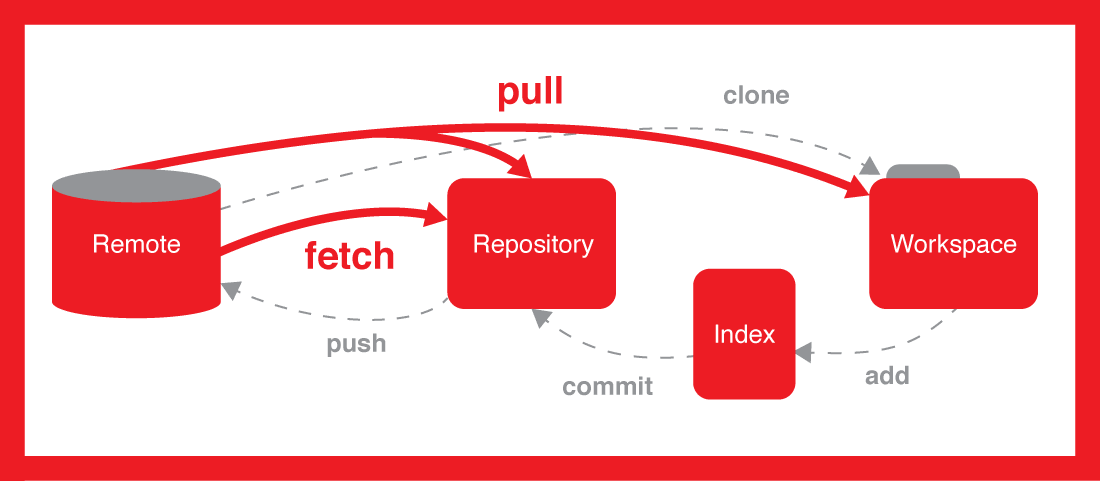
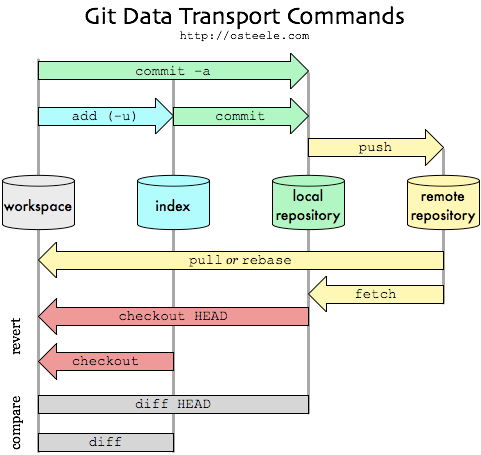
下面是Git工作流程图。

本文来自博客园,作者:sunsky303,转载请注明原文链接:https://www.cnblogs.com/sunsky303/p/17839387.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!