[K8s 1.9实践]Kubeadm 1.9 HA 高可用 集群 本地离线镜像部署

k8s介绍
- k8s 发展速度很快,目前很多大的公司容器集群都基于该项目,如京东,腾讯,滴滴,瓜子二手车,北森等等。

- kubernetes1.9版本发布2017年12月15日,每是那三个月一个迭代, Workloads API成为稳定版本,这消除了很多潜在用户对于该功能稳定性的担忧。还有一个重大更新,就是测试支持了Windows了,这打开了在kubernetes中运行Windows工作负载的大门。
- CoreDNS alpha可以使用标准工具来安装CoreDNS
- kube-proxy的IPVS模式进入beta版,为大型集群提供更好的可扩展性和性能。
- kube-router的网络插件支持,更方便进行路由控制,发布,和安全策略管理
k8s 核心架构

如架构图
- k8s 高可用2个核心 ==apiserver master== and ==etcd==
- ==apiserver master==:(需高可用)集群核心,集群API接口、集群各个组件通信的中枢;集群安全控制;
- ==etcd== :(需高可用)集群的数据中心,用于存放集群的配置以及状态信息,非常重要,如果数据丢失那么集群将无法恢复;因此高可用集群部署首先就是etcd是高可用集群;
- kube-scheduler:调度器 (内部自选举)集群Pod的调度中心;默认kubeadm安装情况下–leader-elect参数已经设置为true,保证master集群中只有一个kube-scheduler处于活跃状态;
- kube-controller-manager: 控制器 (内部自选举)集群状态管理器,当集群状态与期望不同时,kcm会努力让集群恢复期望状态,比如:当一个pod死掉,kcm会努力新建一个pod来恢复对应replicas set期望的状态;默认kubeadm安装情况下–leader-elect参数已经设置为true,保证master集群中只有一个kube-controller-manager处于活跃状态;
- kubelet: agent node注册apiserver
- kube-proxy: 每个node上一个,负责service vip到endpoint pod的流量转发,老版本主要通过设置iptables规则实现,新版1.9基于kube-proxy-lvs 实现
部署示意图
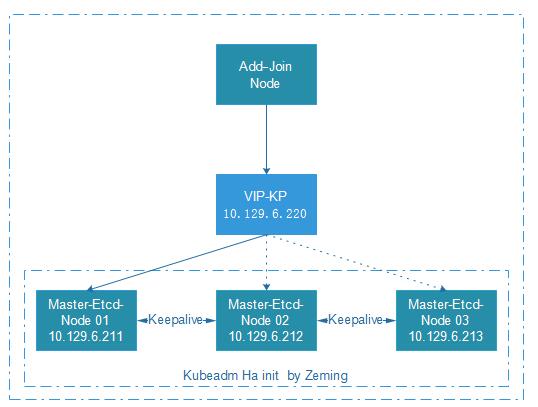
- 集群ha方案,我们力求简单,使用keepalive 监听一个vip来实现,(当节点不可以后,会有vip漂移的切换时长,取决于我们设置timeout切换时长,测试会有10s空档期,如果对高可用更高要求 可以用lvs或者nginx做 4层lb负载 更佳完美,我们力求简单够用,可接受10s的api不可用)
部署环境
最近在部署k8s 1.9集群遇到一些问题,整理记录,或许有助需要的朋友。
因为kubeadm 简单便捷,所以集群基于该项目部署,目前bete版本不支持ha部署,github说2018年预计发布ha 版本,可我们等不及了 呼之欲来。。。| 环境 | 版本 |
|---|---|
| Centos | CentOS Linux release 7.3.1611 (Core) |
| Kernel | Linux etcd-host1 3.10.0-514.el7.x86_64 |
| yum base repo | http://mirrors.aliyun.com/repo/Centos-7.repo |
| yum epel repo | http://mirrors.aliyun.com/repo/epel-7.repo |
| kubectl | v1.9.0 |
| kubeadmin | v1.9.0 |
| docker | 1.12.6 |
| docker localre | devhub.beisencorp.com |
| 主机名称 | 相关信息 | 备注 |
|---|---|---|
| etcd-host1 | 10.129.6.211 | master和etcd |
| etcd-host2 | 10.129.6.212 | master和etcd |
| etcd-host3 | 10.129.6.213 | master和etcd |
| Vip-keepalive | 10.129.6.220 | vip用于高可用 |
环境部署 (我们使用本地离线镜像)
环境预初始化
- Centos Mini安装 每台机器root
- 设置机器名
hostnamectl set-hostname etcd-host1- 停防火墙
systemctl stop firewalld
systemctl disable firewalld
systemctl disable firewalld- 关闭Swap
swapoff -a
sed 's/.*swap.*/#&/' /etc/fstab- 关闭防火墙
systemctl disable firewalld && systemctl stop firewalld && systemctl status firewalld- 关闭Selinux
setenforce 0
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/sysconfig/selinux
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/sysconfig/selinux
sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/selinux/config
getenforce- 增加DNS
echo nameserver 114.114.114.114>>/etc/resolv.conf- 设置内核
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl -p /etc/sysctl.conf
#若问题
执行sysctl -p 时出现:
sysctl -p
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-ip6tables: No such file or directory
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-iptables: No such file or directory
解决方法:
modprobe br_netfilter
ls /proc/sys/net/bridge配置keepalived
- VIP Master 通过控制VIP 来HA高可用(常规方案)
- 到目前为止,三个master节点 相互独立运行,互补干扰. kube-apiserver作为核心入口, 可以使用keepalived 实现高可用, kubeadm join暂时不支持负载均衡的方式,所以我们
- 安装
yum install -y keepalived- 配置keepalived.conf
cat >/etc/keepalived/keepalived.conf <<EOL
global_defs {
router_id LVS_k8s
}
vrrp_script CheckK8sMaster {
script "curl -k https://10.129.6.220:6443"
interval 3
timeout 9
fall 2
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface ens32
virtual_router_id 61
# 主节点权重最高 依次减少
priority 120
advert_int 1
#修改为本地IP
mcast_src_ip 10.129.6.211
nopreempt
authentication {
auth_type PASS
auth_pass sqP05dQgMSlzrxHj
}
unicast_peer {
#注释掉本地IP
#10.129.6.211
10.129.6.212
10.129.6.213
}
virtual_ipaddress {
10.129.6.220/24
}
track_script {
CheckK8sMaster
}
}
EOL- 启动
systemctl enable keepalived && systemctl restart keepalived- 结果
[root@etcd-host1 k8s]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availabilitymonitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled)
Active: active (running) since Fri 2018-01-19 10:27:58 CST; 8h ago
Main PID: 1158 (keepalived)
CGroup: /system.slice/keepalived.service
├─1158 /usr/sbin/keepalived -D
├─1159 /usr/sbin/keepalived -D
└─1161 /usr/sbin/keepalived -D
Jan 19 10:28:00 etcd-host1 Keepalived_vrrp[1161]: Sending gratuitous ARP on ens32 for 10.129.6.220
Jan 19 10:28:05 etcd-host1 Keepalived_vrrp[1161]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on ens32 for 10.129.6.220- 依次配置 其他2台从节点master 配置 修改对应节点 ip
- master01 priority 120
- master02 priority 110
- master03 priority 100
Etcd https 集群部署
Etcd 环境准备
#机器名称
etcd-host1:10.129.6.211
etcd-host2:10.129.6.212
etcd-host3:10.129.6.213
#部署环境变量
export NODE_NAME=etcd-host3 #当前部署的机器名称(随便定义,只要能区分不同机器即可)
export NODE_IP=10.129.6.213 # 当前部署的机器 IP
export NODE_IPS="10.129.6.211 10.129.6.212 10.129.6.213" # etcd 集群所有机器 IP
# etcd 集群间通信的IP和端口
export ETCD_NODES=etcd-host1=https://10.129.6.211:2380,etcd-host2=https://10.129.6.212:2380,etcd-host3=https://10.129.6.213:2380
Etcd 证书创建(我们使用https方式)
创建 CA 证书和秘钥
- 安装cfssl, CloudFlare 的 PKI 工具集 cfssl 来生成 Certificate Authority (CA) 证书和秘钥文件
- 如果不希望将cfssl工具安装到部署主机上,可以在其他的主机上进行该步骤,生成以后将证书拷贝到部署etcd的主机上即可。本教程就是采取这种方法,在一台测试机上执行下面操作。
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
chmod +x cfssl_linux-amd64
mv cfssl_linux-amd64 /usr/local/bin/cfssl
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
chmod +x cfssljson_linux-amd64
mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x cfssl-certinfo_linux-amd64
mv cfssl-certinfo_linux-amd64 /usr/local/bin/cfssl-certinfo生成ETCD的TLS 秘钥和证书
- 为了保证通信安全,客户端(如 etcdctl) 与 etcd 集群、etcd 集群之间的通信需要使用 TLS 加密,本节创建 etcd TLS 加密所需的证书和私钥。
- 创建 CA 配置文件:
cat > ca-config.json <<EOF { "signing": { "default": { "expiry": "8760h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "8760h" } } } } EOF - ==ca-config.json==:可以定义多个 profiles,分别指定不同的过期时间、使用场景等参数;后续在签名证书时使用某个 profile;
- ==signing==:表示该证书可用于签名其它证书;生成的 ca.pem 证书中 CA=TRUE;
- ==server auth==:表示 client 可以用该 CA 对 server 提供的证书进行验证;
- ==client auth==:表示 server 可以用该 CA 对 client 提供的证书进行验证;
cat > ca-csr.json <<EOF { "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "BeiJing", "L": "BeiJing", "O": "k8s", "OU": "System" } ] } EOF - “CN”:Common Name,kube-apiserver 从证书中提取该字段作为请求的用户名 (User Name);浏览器使用该字段验证网站是否合法;
- “O”:Organization,kube-apiserver 从证书中提取该字段作为请求用户所属的组 (Group);
- ==生成 CA 证书和私钥==:
cfssl gencert -initca ca-csr.json | cfssljson -bare ca
ls ca*==创建 etcd 证书签名请求:==
cat > etcd-csr.json <<EOF
{
"CN": "etcd",
"hosts": [
"127.0.0.1",
"10.129.6.211",
"10.129.6.212",
"10.129.6.213"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF- hosts 字段指定授权使用该证书的 etcd 节点 IP;
- 每个节点IP 都要在里面 或者 每个机器申请一个对应IP的证书
生成 etcd 证书和私钥:
cfssl gencert -ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes etcd-csr.json | cfssljson -bare etcd
ls etcd*
mkdir -p /etc/etcd/ssl
cp etcd.pem etcd-key.pem ca.pem /etc/etcd/ssl/
#
#其他node
rm -rf /etc/etcd/ssl/*
scp -r /etc/etcd/ssl root@10.129.6.211:/etc/etcd/
scp -r root@10.129.6.211:/root/k8s/etcd/etcd-v3.3.0-rc.1-linux-amd64.tar.gz /root将生成好的etcd.pem和etcd-key.pem以及ca.pem三个文件拷贝到目标主机的/etc/etcd/ssl目录下。
下载二进制安装文件
到 https://github.com/coreos/etcd/releases 页面下载最新版本的二进制文件:
wget http://github.com/coreos/etcd/releases/download/v3.1.10/etcd-v3.1.10-linux-amd64.tar.gz
tar -xvf etcd-v3.1.10-linux-amd64.tar.gz
mv etcd-v3.1.10-linux-amd64/etcd* /usr/local/bin创建 etcd 的 systemd unit 文件
mkdir -p /var/lib/etcd # 必须先创建工作目录
cat > etcd.service <<EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
ExecStart=/usr/local/bin/etcd \\
--name=${NODE_NAME} \\
--cert-file=/etc/etcd/ssl/etcd.pem \\
--key-file=/etc/etcd/ssl/etcd-key.pem \\
--peer-cert-file=/etc/etcd/ssl/etcd.pem \\
--peer-key-file=/etc/etcd/ssl/etcd-key.pem \\
--trusted-ca-file=/etc/etcd/ssl/ca.pem \\
--peer-trusted-ca-file=/etc/etcd/ssl/ca.pem \\
--initial-advertise-peer-urls=https://${NODE_IP}:2380 \\
--listen-peer-urls=https://${NODE_IP}:2380 \\
--listen-client-urls=https://${NODE_IP}:2379,http://127.0.0.1:2379 \\
--advertise-client-urls=https://${NODE_IP}:2379 \\
--initial-cluster-token=etcd-cluster-0 \\
--initial-cluster=$