Gearman介绍、原理分析、实践改进
gearman是什么?
它是分布式的程序调用框架,可完成跨语言的相互调用,适合在后台运行工作任务。最初是2005年perl版本,2008年发布C/C++版本。目前大部分源码都是(Gearmand服务job Server)C++,各个API实现有各种语言的版本。PHP的Client API与Worker API实现为C扩展,在PHP官方网站有此扩展的中英文文档。
gearman架构中的三个角色
client:请求的发起者,工作任务的需求方(可以是C、PHP、Java、Perl、Mysql udf等等)
Job Server:请求的调度者,负责将client的请求转发给相应的worker(gearmand服务进程创建)
worker:请求的处理者(可以是C、PHP、Java、Perl等等)
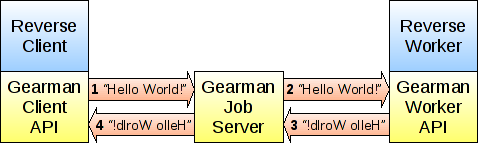
gearman是如何工作的?

从上图可以看出,Gearman Client API,Gearman Worker API,Gearman Job Server都是由gearman本身提供,我们在应用中只需要调用即可。目前client与worker api都很丰富。
gearman的吞吐能力
经过的测试,结果如下:
系统环境:ubuntu-14.0.4 1个CPU 4核 2G内存 (虚拟机)
默认启动:./gearmand -d
client.php
<?php echo "starting...", microtime(true), "\n"; $gmc = new GearmanClient(); $gmc->setCompleteCallBack(function($task){ //echo $task->data(), "\n"; }); $gmc->addServer("127.0.0.1", 4730); for ($i = 0; $i < 100000; $i++) { $gmc->addTaskBackground("reserve", "just test it", null, $i); } $gmc->runTasks(); echo "end...", microtime(true), "\n";
worker.php
<?php $gmw = new GearmanWorker(); $gmw->addServer("127.0.0.1", 4730); $gmw->addFunction("reserve", function($job) { if ($job->unique() == 99999) { echo microtime(true), "\n"; } return strrev($job->workload()); }); while($gmw->work());
启动一个job server实例:job server IP:127.0.0.1 PORT:4730
启动一个worker: php worker.php
worker注册reserve函数,将client的job字符串反转后返回。
client工作任务的消息为:just test it(12字节)
同步:4100/s异步:25700/s
memcached内存准持久化的吞吐能力测试./gearmand -d -q libmemcached --libmemcached-servers=127.0.0.1:11211
client投递100000个工作任务:16400/s
gearman典型的部署结构
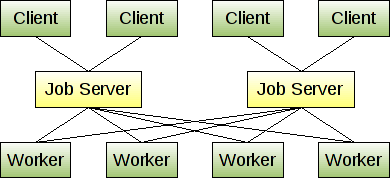
从上图可以看出,gearman支持的特性:
1.高可用
启动两个job server,他们是独立的服务进程,有各自的内存队列。当一个job server进程出现故障,另一个job server可以正常调度。(worker api与client api可以完成job server故障的切换)。在任何时候我们可以关闭某个worker,即使那个worker正在处理工作任务(Gearman不会让正在被执行的job丢失的,由于worker在工作时与Job server是长连接,所以一旦worker发生异常,Job server能够迅速感知并重新派发这个异常worker刚才正在执行的工作)
2.负载均衡(附gearman协议会详细解释)
job server并不主动分派工作任务,而是由worker从空闲状态唤醒之后到job server主动抓取工作任务。
3.可扩展
松耦合的接口和无状态的job,只需要启动一个worker,注册到Job server集群即可。新加入的worker不会对现有系统有任何的影响。
4.分布式
gearman是分布式的任务分发框架,worker与job server,client与job server通信基于tcp的socket连接。
5.队列机制
gearman内置内存队列,默认情况队列最大容量为300W,可以配置最大支持2^32-1,即4 294 967 295。
6.高性能
作为Gearman的核心,Job server的是用C/C++实现的,由于只是做简单的任务派发,因此系统的瓶颈不会出在Job server上。
两种工作任务
后台工作任务Background job——时序图
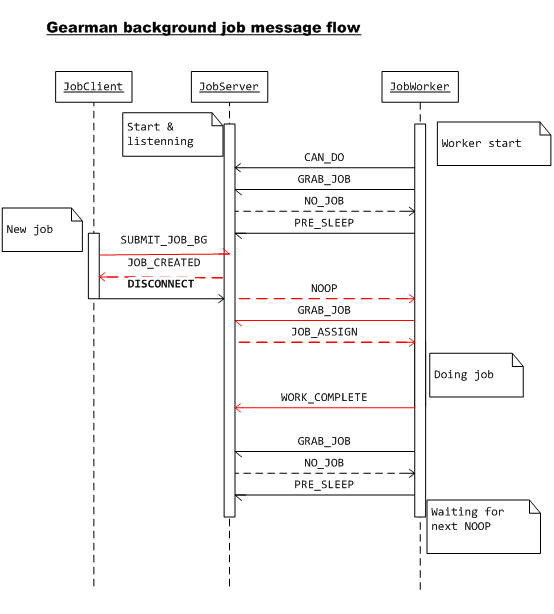
由图可知,client提交完job,job server成功接收后返回JOB_CREATED响应之后,client就断开与job server之间的链接了。后续无论发生什么事情,client都是不关心的。同样,job的执行结果client端也没办法通过Gearman消息框架 获得。
一般工作任务Non-background job——时序图
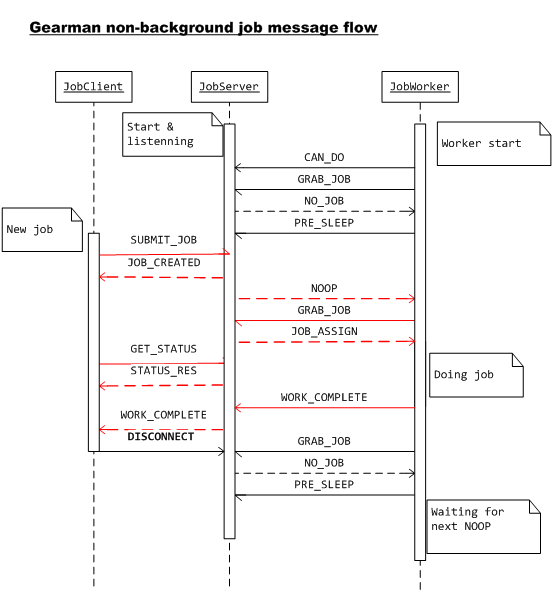
由图可知,client端在job执行的整个过程中,与job server端的链接都是保持着的,这也给job完成后job server返回执行结果给client提供了通路。同时,在job执行过程当中,client端还可以发起job status的查询。当然,这需要worker端的支持的。
关于持久化
对于队列持久化的问题,是一个值得考虑的问题。持久化必然影响高性能。gearman支持后台工作任务的持久化,支持drizzle、mysql、memcached的持久化。对于client提交的background job,Job server除了将其放在内存队列中进行派发之外,还会将其持久化到外部的持久化队列中。一旦Job server发生问题重启,外部持久化队列中的background job将会被恢复到内存中,参与Job server新的派发当中。这保证了已提交未执行的background job不会由于Job server发生异常而丢失。并且我测试发现如果开启了持久化,那么后台工作任务会先将工作任务写到持久化介质,然后在入内存队列,再执行。非后台工作任务,由于client与job server是保持长连接的状态,如果工作任务执行异常,client可以灵活处理,所以无须持久化。
gearman框架中的一个问题
从典型部署结构看出,两个Job server之间是没有连接的。也就是Job server间是不共享background job的。如果通过让两个Job server指向同一个持久化队列,可以让两个Job serer互相备份。但实际上,这样是行不通的。因为Job server只有在启动时才会将持久化队列中的background job转入到内存队列。也就是说,Job server1如果宕机且永远不启动,Job server2一直正常运行,那么Job server1宕机前被提交到Job server1的未被执行的background job将永远都呆在持久化队列中,得不到执行。另外如果多个job server实例指向同一个持久化队列,同时重启多个job server实例会导致持久队列中的工作任务被多次载入,从而导致消息重复处理。
我建议的部署结构
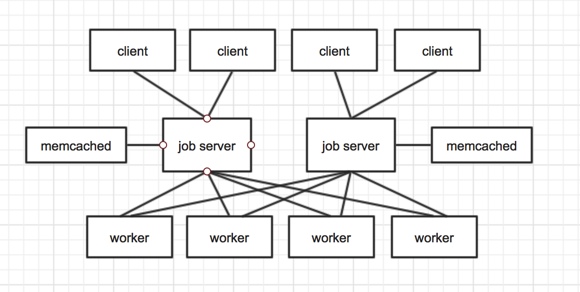
采用memcached做后台工作任务的准持久化队列,最好memcached和job server在内网的不同机器。两个机器的两个服务同时挂掉的可能性比较小,同时也保证了高性能。而且memcached应该为两个相互独立实例,防止其上述的gearman框架中的问题。我们可以做一个监控脚本,如果某个job server异常退出,可以重启,也最大化的保证了job server的高可用。
关于gearman的管理工具
目前有一个现在的管理工具,https://github.com/brianlmoon/GearmanManager,但是只支持php-5.2,不过可以自行修改支持php-5.4,我建议如果使用PHP作为worker进程,使用php-5.4以上的版本。该工具的设计方法可以借鉴,可以比较好的管理gearman worker。时间有限,还没有深入研究。
应用场景
1.结合linux crontab,php脚本负责产生job,将任务分发到多台服务器周期性的并发执行。可以取代目前我们比较多的crontab的工作任务。
2.邮件短信发送
3.异步log
4.跨语言相互调用(对于密集型计算的需求,可以用C实现,PHP直接调用)
5.其他耗时脚本
gearman安装(unbuntu)
1.下载
#wget https://launchpadlibrarian.net/165674261/gearmand-1.1.12.tar.gz
2.安装依赖包
#sudo apt-get install libboost1.55-all-dev gperf libevent libevent-dev uuid libmemcached-dev
#tar zxvf gearmand-1.1.12.tar.gz
#cd gearmand-1.1.12.tar.gz
#./configure --prefix=/home/phpboy/Server/gearman
#make & make install
3.启动
a)默认启动
./gearman -d
b)支持memcached准持久化
./gearmand -d -q libmemcached --libmemcached-servers=127.0.0.1:11211
4.安装php的gearman扩展
#wget http://pecl.php.net/get/gearman-1.1.2.tgz
#tar zxvf gearman-1.1.2.tgz#cd gearman-1.1.2
#phpize
#./configure --with-php-config=php-config
#make & make install
5.php client api与php worker api的测试,可以用上面我的测试的示例
附gearmand(job server的启动参数简单说明)
-b, –backlog=BACKLOG 连接请求队列的最大值
-d, –daemon Daemon 守护进程化
-f, –file-descriptors=FDS 可打开的文件描述符数量
-h, –help
-l, –log-file=FILE Log 日志文件
-L, –listen=ADDRESS 开启监听的地址
-p, –port=PORT 开启监听的端口
-P, –pid-file=FILE File pid file
-r,–protocol=PROTOCOL 使用的协议
-q, –queue-type=QUEUE 持久化队列类型
-t, –threads=THREADS I/O线程数量
-u, –user=USER 进程的有效用户名
libdrizzle Options:
--libdrizzle-host=HOST Host of server.
--libdrizzle-port=PORT Port of server.
--libdrizzle-uds=UDS Unix domain socket for server.
--libdrizzle-user=USER User name for authentication.
--libdrizzle-password=PASSWORD Password for authentication.
--libdrizzle-db=DB Database to use.
--libdrizzle-table=TABLE Table to use.
--libdrizzle-mysql Use MySQL protocol.
libmemcached Options:
--libmemcached-servers=SERVER_LIST List of Memcached servers to use.
libsqlite3 Options:
--libsqlite3-db=DB Database file to use.
--libsqlite3-table=TABLE Table to use.
libpq Options:
--libpq-conninfo=STRING PostgreSQL connection information string.
--libpq-table=TABLE Table to use.
http Options:
--http-port=PORT Port to listen on.
附gearman通信协议,个人翻译与理解:
总括
Gearman工作在TCP上,默认端口为4730,client与job server、worker与job server的通信都基于此tcp的socket连接。client是工作任务的发起者,worker是可以注册处理函数的工作任务执行者,job server为工作的调度者。协议包含请求报文与响应报文两个部分,所有发向job server的数据包(TCP报文段的数据部分)认为是请求报文,所有从job server发出的数据包(TCP报文段的数据部分)认为是响应报文。worker或者client与job server间的通信是基于二进制数据流的,但在管理client也有基于行文本协议的通信。
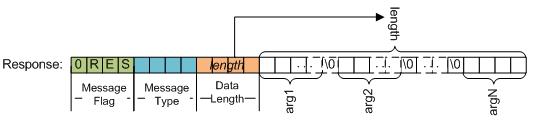
请求的报文体
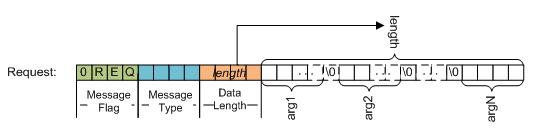
响应的报文体
 、
、
二进制包
请求报文与响应报文是由二进制包封装。一个二进制包由头header和可选的数据部分data组成。
header的组成
a.报文类别,请求报文或者响应报文,4个字节
"\0REQ" 请求报文
"\0RES" 响应报文
b.包类型,高(大)字节序(网络字节序),4个字节可能的类型有
类型值 名称 报文类型 发送者
1 CAN_DO REQ Worker
2 CANT_DO REQ Worker
3 RESET_ABILITIES REQ Worker
4 PRE_SLEEP REQ Worker
5 (unused) - -
6 NOOP RES Worker
7 SUBMIT_JOB REQ Client
8 JOB_CREATED RES Client
9 GRAB_JOB REQ Worker
10 NO_JOB RES Worker
11 JOB_ASSIGN RES Worker
12 WORK_STATUS REQ Worker
13 WORK_COMPLETE REQ Worker
14 WORK_FAIL REQ Worker
15 GET_STATUS REQ Client
16 ECHO_REQ REQ Client/Worker
17 ECHO_RES RES Client/Worker
18 SUBMIT_JOB_BG REQ Client
19 ERROR RES Client/Worker
20 STATUS_RES RES Client
21 SUBMIT_JOB_HIGH REQ Client
22 SET_CLIENT_ID REQ Worker
23 CAN_DO_TIMEOUT REQ Worker
24 ALL_YOURS REQ Worker
25 WORK_EXCEPTION REQ Worker
26 OPTION_REQ REQ Client/Worker
27 OPTION_RES RES Client/Worker
28 WORK_DATA REQ Worker
29 WORK_WARNING REQ Worker
30 GRAB_JOB_UNIQ REQ Worker
31 JOB_ASSIGN_UNIQ RES Worker
32 SUBMIT_JOB_HIGH_BG REQ Client
33 SUBMIT_JOB_LOW REQ Client
34 SUBMIT_JOB_LOW_BG REQ Client
35 SUBMIT_JOB_SCHED REQ Client
36 SUBMIT_JOB_EPOCH REQ Client
c.可选数据部分长度,高(大)字节序(网络字节序),4个字节,可表示的值为4294967295
数据部分,数据部分的各个部分为null字符分隔。
具体各包类型的说明
client和worker都可以发送的请求报文:
ECHO_REQ
当job server收到此包类型的请求报文时,就简单的产生一个包类型为ECHO_RES,同时将请求报文的数据部分作为响应报文的数据部分的报文。主要用于测试或者调试
如:
Client -> Job Server
00 52 45 51 \0REQ 报文类型
00 00 00 a0 16 (Packet type: ECHO_ERQ)
00 00 00 04 4 (Packet length)
74 65 73 74 test (Workload)
client和worker都可以接收的响应报文:
ECHO_RES
当job server响应ECHO_REQ报文时发送的包类型为ECHO_RES的响应报文
如:
Job Server -> Client
00 52 45 53 \0RES 报文类型
00 00 00 a1 17 (Packet type: ECHO_ERS)
00 00 00 04 4 (Packet length)
74 65 73 74 test (Workload)
ERROR
当job server发生错误时,需要通知client或者worker
client发送的请求报文:(仅能由client发送的请求报文)
SUBMIT_JOB, SUBMIT_JOB_BG,SUBMIT_JOB_HIGH, SUBMIT_JOB_HIGH_BG,SUBMIT_JOB_LOW, SUBMIT_JOB_LOW_BG
当client有一个工作任务需要运行,就会提交相应的请求报文,job server响应包类型为JOB_CREATED数据部分为job handle的响应报文。SUBMIT_JOB为普通的工作任务,client得到状态更新及通知任务已经完成的响应;SUBMIT_JOB_BG为异步的工作任务,client不关心任务的完成情况;SUBMIT_JOB_HIGH为高优先级的工作任务,SUBMIT_JOB_HIGH_BG为高优先级的异步任务;SUBMIT_JOB_LOW为低优先级的工作任务,SUBMIT_JOB_LOW_BG为低优先级的异步任务。
如:
Client -> Job Server
00 52 45 51 \0REQ (报文类型)
00 00 00 07 7 (Packet type: SUBMIT_JOB)
00 00 00 0d 13 (Packet length)
72 65 76 65 72 73 65 00 reverse\0 (Function)
00 \0 (Unique ID)
74 65 73 74 test (Workload)
SUBMIT_JOB_SCHED
和SUBMIT_JOB_BG类似,此类型的工作任务不会立即执行,而在设置的某个时间运行。
如:
Client -> Job Server
00 52 45 51 \0REQ (报文类型)
00 00 00 23 35 (Packet type: SUBMIT_JOB_SCHED)
00 00 00 0d 13 (Packet length)
72 65 76 65 72 73 65 00 reverse\0 (Function)
00 \0 (Unique ID)
01 \0 (minute 0-59)
01 \0 (hour 0-23)
01 \0 (day of month 1-31)
01 \0 (day of month 1-12)
01 \0 (day of week 0-6)
74 65 73 74 test (Workload)
SUBMIT_JOB_EPOCH
和SUBMIT_JOB_SCHED作用一样,只是将设置的时间定为了uinx时间戳GET_STATUS获取某个工作任务执行的状态信息
OPTION_REQ
设置client与job server连接的选项
client获取的响应报文:
JOB_CREATED响应包类型为SUBMIT_JOB*的请求报文,数据部分为job handle
WORK_DATA, WORK_WARNING, WORK_STATUS, WORK_COMPLETE,WORK_FAIL, WORK_EXCEPTION
对于后台运行的工作任务,任务执行信息可以通过包类型为上面的值来查看。
STATUS_RES
响应包类型为GET_STATUS的请求报文,通常用来查看一个后台工作任务是否已经完成,以及完成的百分比。
OPTION_RES
响应包类型为OPTION_REQ的请求报文
worker发送的请求报文:
CAN_DO
通知job server可以执行给定的function name的任务,此worker将会放到一个链表,当job server收到一个function name的工作任务时,worker为被唤醒。
CAN_DO_TIMEOUT
和CAN_DO类似,只是针对给定的function_name的任务设置了一个超时时间。
CANT_DO
worker通知job server已经不能执行给定的function name的任务
RESET_ABILITIES
worker通知job server不能执行任何function name的任务
PRE_SLEEP
worker通知job server它将进入sleep阶段,而之后此worker会被包类型为NOOP的响应报文唤醒。
GRAB_JOB
worker向job server抓取工作任务,job server将会响应NO_JOB或者JOB_ASSIG
NGRAB_JOB_UNIQ
和GRAB_JOB类似,但是job server在有工作任务时将会响应JOB_ASSIGN_UNIQ
WORK_DATA
worker请求报文的数据部分更新client
WORK_WARNING
worker请求报文代表一个warning,它应该被对待为一个WARNING
WORK_STATU
Sworker更新某个job handle的工作状态,job server应该储存这些信息,以便响应之后client的GET_STATUS请求
WORK_COMPLETE
通知job server及所有连接的client,数据部分为返回给client的数据
WORK_FAIL
通知job server及所有连接的client,工作任务执行失败
WORK_EXCEPTION
通知job server及所有连接的client,工作任务执行失败并给出相应的异常
SET_CLIENT_ID
设置worker ID,从而job server的控制台及报告命令可以标识各个worker,数据部分为worker实例的标识
ALL_YOURS
暂未实现
worker获取的响应报文:
NOOP
job server唤醒sleep的worker,以便可以开始抓取工作任务
NO_JOB
job server响应GRAB_JOB的请求,通知worker没有等待执行的工作任务
JOB_ASSIGN
job server响应GRAB_JOB的请求,通知worker有需要执行的工作任务
JOB_ASSIGN_UNIQ
job server响应GRAB_JOB_UNIQ的请求,和JOB_ASSIGN一样,只是为client传递了一个唯一标识
基于上述的协议描述一个完整的例子
worker注册可以执行的工作任务
Worker -> Job Server
00 52 45 51 \0REQ (Magic)
00 00 00 01 1 (Packet type: CAN_DO)
00 00 00 07 7 (Packet length)
72 65 76 65 72 73 65 reverse (Function)
worker检测或者抓取工作任务
Worker -> Job Server
00 52 45 51 \0REQ (Magic)
00 00 00 09 9 (Packet type: GRAB_JOB)
00 00 00 00 0 (Packet length)
job server响应worker的抓取工作(没有工作任务)
00 52 45 53 \0RES (Magic)
00 00 00 0a 10 (Packet type: NO_JOB)
00 00 00 00 0 (Packet length)
worker通知job server开始sleep
00 52 45 51 \0REQ (Magic)
00 00 00 04 4 (Packet type: PRE_SLEEP)
00 00 00 00 0 (Packet length)
client提交工作任务
Client -> Job Server
00 52 45 51 \0REQ (Magic)
00 00 00 07 7 (Packet type: SUBMIT_JOB)
00 00 00 0d 13 (Packet length)
72 65 76 65 72 73 65 00 reverse\0 (Function)
00 \0 (Unique ID)
74 65 73 74 test (Workload)
job server响应client的SUBMIT_JOB请求,返回job handle
00 52 45 53 \0RES (Magic)
00 00 00 08 8 (Packet type: JOB_CREATED)
00 00 00 07 7 (Packet length)
48 3a 6c 61 70 3a 31 H:lap:1 (Job handle)
job server唤醒worker
Job Server -> Worker
00 52 45 53 \0RES (Magic)
00 00 00 06 6 (Packet type: NOOP)
00 00 00 00 0 (Packet length)
worker的抓取工作任务
Worker -> Job Server
00 52 45 51 \0REQ (Magic)
00 00 00 09 9 (Packet type: GRAB_JOB)
00 00 00 00 0 (Packet length)
job server分配工作任务给worker
Job Server -> Worker
00 52 45 53 \0RES (Magic)
00 00 00 0b 11 (Packet type: JOB_ASSIGN)
00 00 00 14 20 (Packet length)
48 3a 6c 61 70 3a 31 00 H:lap:1\0 (Job handle)
72 65 76 65 72 73 65 00 reverse\0 (Function)
74 65 73 74 test (Workload)
worker完成工作任务通知job server
00 52 45 51 \0REQ (Magic)
00 00 00 0d 13 (Packet type: WORK_COMPLETE)
00 00 00 0c 12 (Packet length)
48 3a 6c 61 70 3a 31 00 H:lap:1\0 (Job handle)
74 73 65 74 tset (Response)
job server通知client完成了工作任务
Job Server -> Client
00 52 45 53 \0RES (Magic)
00 00 00 0d 13 (Packet type: WORK_COMPLETE)
00 00 00 0c 12 (Packet length)
48 3a 6c 61 70 3a 31 00 H:lap:1\0 (Job handle)
74 73 65 74 tset (Response)
每个client与job server是全双工通信,在一个socket可以完成多个工作任务的投递,但是收到任务的执行结果的顺序可能与投递的顺序不一致。
总结worker的工作流程:
1. Worker通过CAN_DO消息,注册到Job server上。
2. 随后发起GRAB_JOB,主动要求分派任务。
3. Job server如果没有job可分配,就返回NO_JOB。
4. Worker收到NO_JOB后,进入空闲状态,并给Job server返回PRE_SLEEP消息,告诉Job server:”如果有工作来的话,用NOOP请求我先。”
5. Job server收到worker的PRE_SLEEP消息后,明白了发送这条消息的worker已经进入了空闲态。
6. 这时如果有job提交上来,Job server会给worker先发一个NOOP消息。
7. Worker收到NOOP消息后,发送GRAB_JOB向Job server请求任务。
8. Job server把工作派发给worker。
9. Worker干活,完事后返回WORK_COMPLETE给Job server。
上述典型部署结构带来的问题思考
从典型部署结构看出,两个Job server之间是没有连接的。也就是Job server间是不共享background job的。如果通过让两个Job server指向同一个持久化队列,可以让两个Job serer互相备份。但实际上,这样是行不通的。因为Job server只有在启动时才会将持久化队列中的background job转入到内存队列。也就是说,Job server1如果宕机且永远不启动,Job server2一直正常运行,那么Job server1宕机前被提交到Job server1的未被执行的background job将永远都呆在持久化队列中,得不到执行。另外如果多个job server实例指向同一个持久化队列,同时重启多个job server实例会导致持久队列中的工作任务被多次载入,从而导致消息重复处理。
优化改进后的部署结构
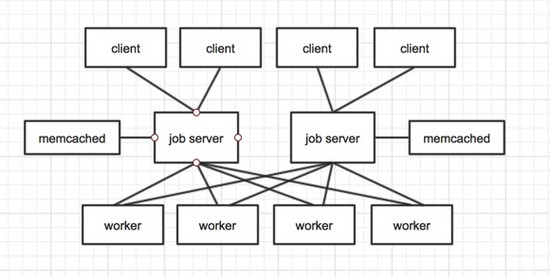
采用memcached做后台工作任务的准持久化队列,最好memcached和job server在内网的不同机器。两个机器的两个服务同时挂掉的可能性比较小,同时也保证了高性能。而且memcached应该为两个相互独立实例,防止其上述的gearman框架中的问题。我们可以做一个监控脚本,如果某个job server异常退出,可以重启,也最大化的保证了job server的高可用。
关于gearman的分布式任务处理架构的认识总结:
1. 其实每一个任务处理的时间并没有降低,相反会稍稍有所增加,主要是数据在网络上传输的一些时间。
2. 前端Client(通常是web服务器)的负载降低了,但是转移到了后端Worker上。计算不可能凭空消失,只不过从一台机器转移到了另外一台机器。
3. 同步阻塞方式的任务,前端Client(通常是Web服务器)等待的时间与后端Worker的数量与当前任务数有关。如果当前任务数量<=Worker数量,前端Client等待的时间约等于一个任务处理的时间。但是当前任务数>=Worker数量时,就会出现某些Client等待的情况,某个Client只有等到一个空闲的Worker,才会将任务交给它进行处理。
设想一下,在任务数<=Worker数量的时候,使用gearman是可以提高响应时间的。如果采用单机话,N个任务还是在一台机器上运行,每个任务需要
现在有N个任务(Client),M个Worker,每个任务执行时间为t。如果不是用gearman的话,需要的时间为N*t,平均等待时间为N*t/2。
如果使用了gearman的话,并且N<=M,需要的时间为t,平均等待时间为t;如果N>M的话,需要的时间为(N/M)*t or (N/M+1)*t。
4. 异步方式的话,任务交给后端Worker后,前端Client就返回了,这样用户体验比较好。但是,存在任务执行失败或者是任务结果反馈的问题。
一般采用数据库作为存储,将任务执行的状态信息、结果等存入数据库;前端Client定期检查数据库中的结果,再进一步进行操作,是向用户呈现结果还是重新执行任务。
总体来看,gearman适合于那种task数量远远大于worker数量的应用。理论上来看,将计算开销转移到Worker上,从而实现任务的并发执行,表现为client计算负载减轻,用户的等待时间减少。
—————————–其他结构图分享————————————–
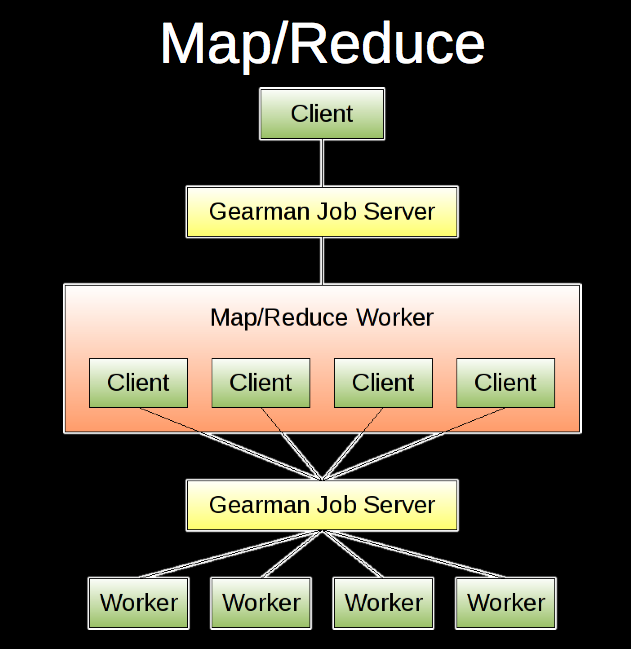
Map/Reduce构架图
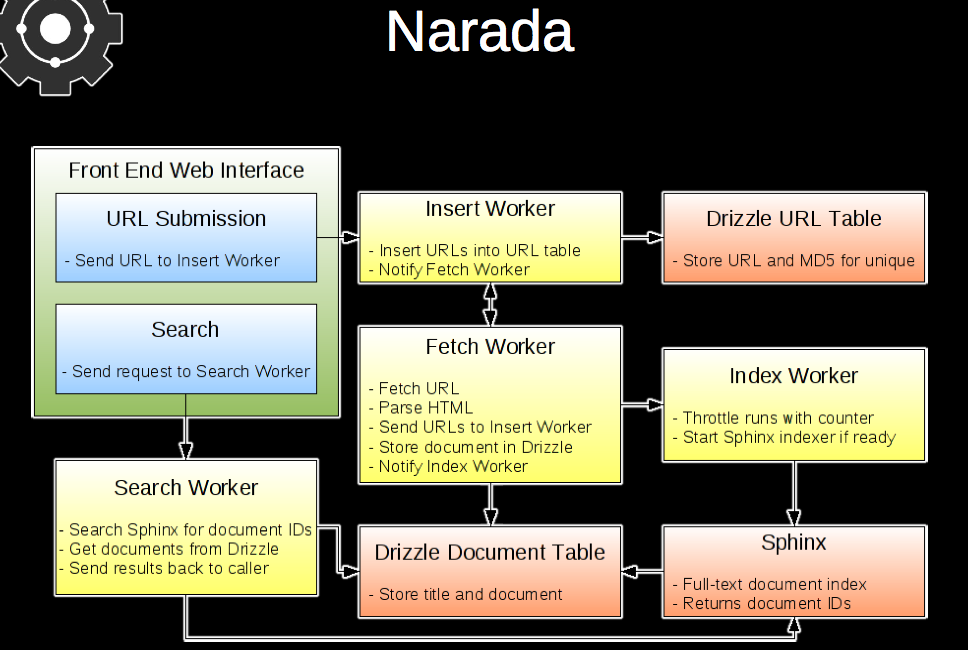
Narada开源搜索架构图
日志聚集和检索日志处理

本文来自博客园,作者:sunsky303,转载请注明原文链接:https://www.cnblogs.com/sunsky303/p/11134222.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号