长连接及心跳保活原理简介
本文简要的分析了长连接产生的背景以及所解决的问题,并对比了keep-alive与心跳机制对长连接保活的影响,最后详细的介绍了心跳保活的两个关键因素–DHCP协议与NAT原理。如有不当之处,欢迎批评和指正。
1.短连接,并行连接,持久连接与长连接
(1) 短连接简介
在互联网发展过程中,最为普及的应用就是HTTP超文本传输协议,而在早期–HTTP1.0的协议都是建立在TCP协议基础上,其特点就是传输完数据后,立马就释放掉该TCP链接,所以就有了形象的短连接这个称号。下图形象的展示出了在一个事务的处理过程中,各个阶段的处理时长:
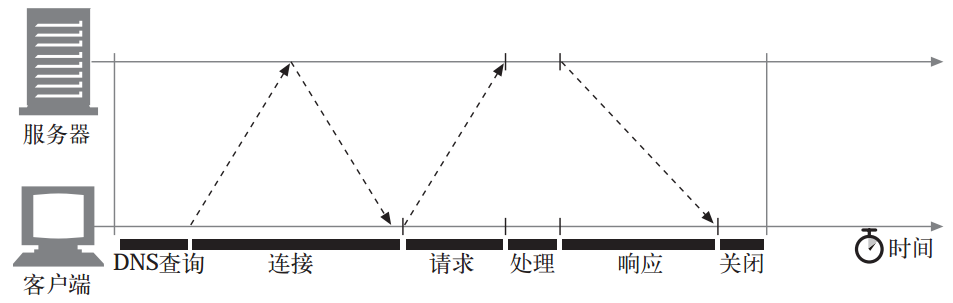
可以看到,与建立TCP连接,以及传输请求和响应报文的时间相比,事务处理时间可能是很短的。短连接的性能瓶颈主要集中在如下几个方面:
a.TCP连接的握手时延
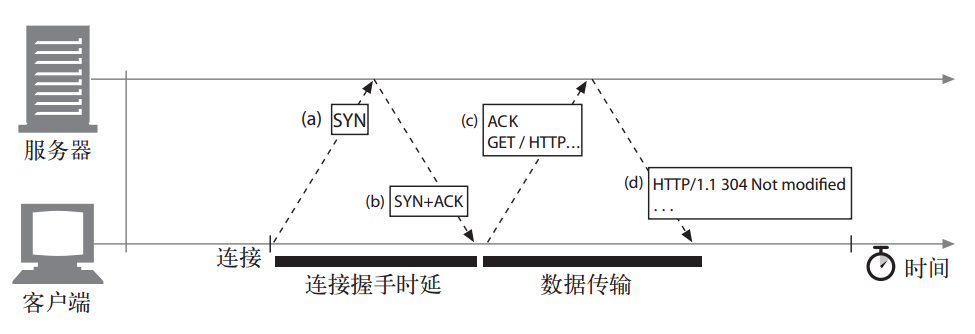
在发送数据之前,TCP要传送两个分组来建立连接(现代的TCP栈都允许客户端在确认分组中发送数据),此时,SYN/SYN+ACK握手会产生一个可测量的时延。
b.延迟确认
每个TCP段都有一个序列号和数据完整性校验和。每个段的接收者收到完好的段时,都会向发送者回送小的确认分组。如果发送者没有在指定的窗口时间内收到确认信息,发送者就认为分组已被破坏或损毁,并重发数据。
由于确认报文很小,所以TCP允许在发往相同方向的输出数据分组中对其进行“捎带”。TCP将返回的确认信息与输出的数据分组结合在一起,可以更有效地利用网络。为了增加确认报文找到同向传输数据分组的可能性,很多TCP栈都实现了一种“延迟确认”算法。延迟确认算法会在一个特定的窗口时间(通常是100~200毫秒)内将输出确认存放在缓冲区中,以寻找能够捎带它的输出数据分组。如果在那个时间段内没有输出数据分组,就将确认信息放在单独的分组中传送。
c.TCP慢启动
TCP连接会随着时间进行自我“调谐”,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度,这种调谐被称为TCP慢启动,用于防止因特网的突然过载和拥塞。
由于存在这种拥塞控制特性,所以新连接的传输速度会比已经交换过一定量数据的、“已调谐”连接慢一些。
(2) 短连接的适用场景与优缺点
短连接多用于操作频繁,点对点的通讯,而且连接数不能太多的情况。每个TCP连接的建立都需要三次握手,每个TCP连接的断开要四次挥手。适用于并发量大,但是每个用户又不需频繁操作的情况。
但是在用户需要频繁操作的业务场景下(如新用户注册,网购提交订单等),频繁的使用短连接则会使性能时延产生叠加,如下如:
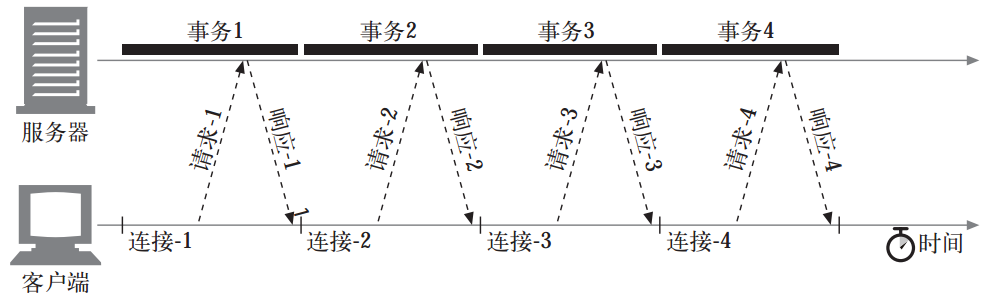
因此就产生了一些列关于连接性能的改进方案。
(3) 并行连接
并行连接允许客户端打开多条连接,并行地执行多个事务,每个事务都有自己的TCP连接。这样可以克服单条连接的空载时间和带宽限制,时延可以重叠起来,而且如果单条连接没有充分利用客户端的网络带宽,可以将未用带宽分配来装载其他对象。
在PC时代,利用并行连接来充分利用现代浏览器的多线程并发下载能力的场景非常广泛。
但是并行连接也会产生一定的问题,首先并行连接不一定更快,因为带宽资源有限,每个连接都会去竞争这有限的带宽,这样带来的性能提升就很小,甚至没什么提升。另外打开大量连接会消耗很多内存资源,从而引发自身的性能问题,因此每个浏览器,允许对每个域名的连接数一般是有上限的,如下图所示:
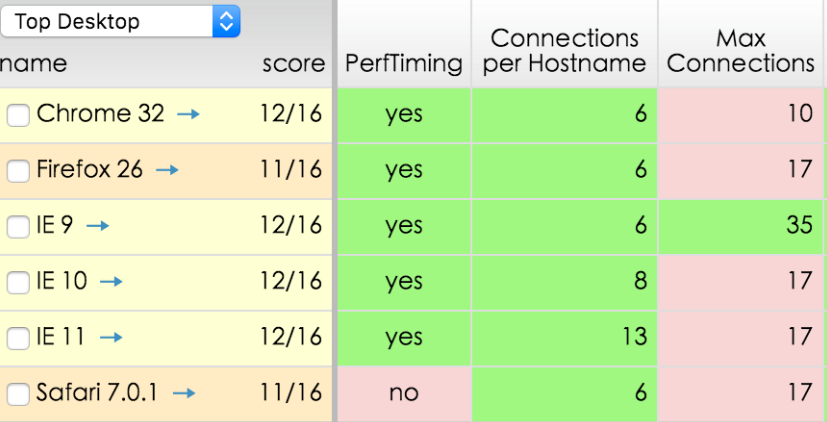
(4) 持久连接
HTTP1.0版本以后,允许HTTP设备在事务处理结束之后将TCP连接保持在打开状态,以便为未来的HTTP请求重用现存的连接。在事务处理结束之后仍然保持在打开状态的TCP连接被称为持久连接。非持久连接会在每个事务结束之后关闭。持久连接会在不同事务之间保持打开状态,直到客户端或服务器决定将其关闭为止。
现在很多方案都会采用持久连接+新连接结合的方式,这种方式尽可能的减少了新建连接的浪费,同时当现有连接没有办法满足需求的时候,可以建立新连接满足需求,比较灵活。
持久连接的时间参数,通常由服务器设定,比如nginx的keepalivetimeout,keepalive timout时间值意味着:一个http产生的tcp连接在传送完最后一个响应后,还需要hold住keepalive_timeout秒后,才开始关闭这个连接;
持久连接与并行连接相比,带来的优势如下:
- 避免了每个事务都会打开/关闭一条新的连接,造成时间和带宽的耗费;
- 避免了TCP慢启动特性的存在导致的每条新连接的性能降低;
- 可打开的并行连接数量实际上是有限的,持久连接则可以减少建立的连接的数量;
(5) 长连接
长连接与持久连接本质上非常的相似,持久连接侧重于HTTP应用层,特指一次请求结束之后,服务器会在自己设置的keepalivetimeout时间到期后才关闭已经建立的连接。长连接则是client方与server方先建立连接,连接建立后不断开,然后再进行报文发送和接收,直到有一方主动关闭连接为止。
长连接的适用场景也非常的广泛:
- 监控系统:后台硬件热插拔、LED、温度、电压发生变化等;
- IM应用:收发消息的操作;
- 即时报价系统:例如股市行情push等;
- 推送服务:各种App内置的push提醒服务;
像以上这些连接,如果每次操作都要建立连接然后再操作的话处理速度会降低,并且时效性也不高。通过长连接,第一次连接上以后每次直接发送数据就可以了,不用再建立TCP连接。
2.长连接保活,Keep-Alive与心跳保活技术
(1) 为何需要长连接保活
上一节的分析可以看到,对于客户端而言,使用TCP长连接来实现业务的好处在于:在当前连接可用的情况下,每一次请求都只是简单的数据发送和接受,免去了DNS解析,连接建立,TCP慢启动等时间,大大加快了请求的速度,同时也有利于接收服务器的实时消息。
在使用TCP长连接的业务场景下,保持长连接的可用性非常重要。如果长连接无法很好地保持,在连接已经失效的情况下继续发送请求会导致迟迟收不到响应直到超时,又需要一次连接建立的过程,其效率甚至还不如直接使用短连接。而连接保持的前提必然是检测连接的可用性,并在连接不可用时主动放弃当前连接并建立新的连接。
(2) 心跳保活
App实现长连接保活的方式通常是采用应用层心跳,通过心跳包的超时和其他条件(网络切换)来执行重连操作。心跳一般是指某端(绝大多数情况下是客户端)每隔一定时间向对端发送自定义指令,以判断双方是否存活,因其按照一定间隔发送,类似于心跳,故被称为心跳指令。
(3) Keep-Alive可否实现保活?
a.HTTP中的Keep-Alive
实现HTTP/1.0 keep-alive连接的客户端可以通过包含Connection:Keep-Alive首部请求将一条连接保持在打开状态,如果服务器愿意为下一条请求将连接保持在打开状态,就在响应中包含相同的首部。如果响应中没有Connection: Keep-Alive首部,客户端就认为服务器不支持keep-alive,会在发回响应报文之后关闭连接。HTTP/1.1以后Keep-Alive是默认打开的。
c.TCP中的Keep-Alive
TCP协议的实现中,提供了KeepAlive报文,用来探测连接的对端是否存活。在应用交互的过程中,可能存在以下几种情况:
- 客户端或服务器意外断电,死机,崩溃,重启;
- 中间网络已经中断,而客户端与服务器并不知道;
利用保活探测功能,可以探知这种对端的意外情况,从而保证在意外发生时,可以释放半打开的TCP连接。TCP保活报文交互过程如下:
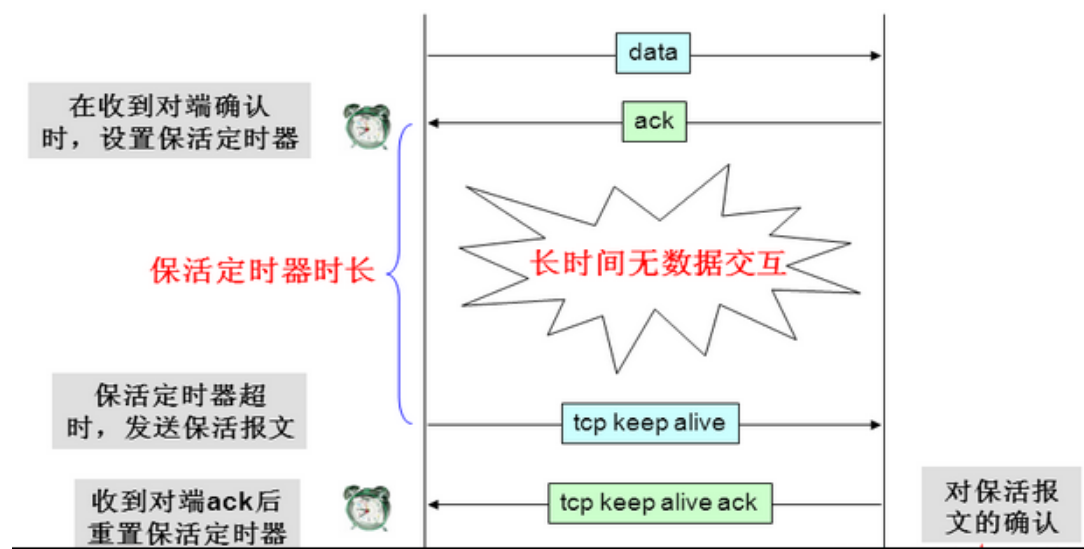
虽然TCP提供了KeepAlive机制,但是并不能替代应用层心跳保活。原因主要如下:
- (1) Keep Alive机制开启后,TCP层将在定时时间到后发送相应的KeepAlive探针以确定连接可用性。默认时间为7200s(两小时),失败后重试10次,每次超时时间75s。显然默认值无法满足移动网络下的需求;
- (2) 即便修改了(1)中的默认值,也不能很好的满足业务需求。TCP的KeepAlive用于检测连接的死活而不能检测通讯双方的存活状态。比如某台服务器因为某些原因导致负载超高,无法响应任何业务请求,但是使用TCP探针则仍旧能够确定连接状态,这就是典型的连接活着但业务提供方已死的状态,对客户端而言,这时的最好选择就是断线后重新连接其他服务器,而不是一直认为当前服务器是可用状态,一直向当前服务器发送些必然会失败的请求。
- (3) socks代理会让Keep Alive失效。socks协议只管转发TCP层具体的数据包,而不会转发TCP协议内的实现细节的包。所以,一个应用如果使用了socks代理,那么TCP的KeepAlive机制就失效了。
- (4) 部分复杂情况下Keep Alive会失效,如路由器挂掉,网线直接被拔除等;
因此,KeepAlive并不适用于检测双方存活的场景,这种场景还得依赖于应用层的心跳。应用层心跳也具备着更大的灵活性,可以控制检测时机,间隔和处理流程,甚至可以在心跳包上附带额外信息。
(4) 影响心跳频率的关键因素
通过上一节的分析可以看到应用层心跳是检测连接有效性以及判断双方是否存活的有效方式。但是心跳过于频繁会带来耗电和耗流量的弊病,心跳频率过低则会影响连接检测的实时性。业内关于心跳时间的设置和优化,主要基于如下几个因素:
- 1.NAT超时–大部分移动无线网络运营商在链路一段时间没有数据通讯时,会淘汰 NAT表中的对应项,造成链路中断;
- 2.DHCP租期–DHCP租期到了需要主动续约,否则会继续使用过期IP导致长连接偶然的断连;
- 3.网络状态变化–手机网络和WIFI网络切换、网络断开和连上等情况有网络状态的变化,也会使长连接变为无效连接;
网络状态变化导致长连接变为无效连接的原因很容易理解。但是NAT超时和DHCP租期的问题对长连接保活存在的影响就涉及到网络协议底层的细节了。后续会对这两个原理进行相应的分析。
3.DHCP原理浅析及其对心跳保活的影响
(1) DHCP协议简介
DHCP协议全称为Dynamic Host Configuration Protocol– 动态主机配置协议,主要用于在一个局域网里为主机动态的分配IP地址。DHCP有三种分配IP地址方式:
- 自动分配:DHCP给客户端分配永久性的IP地址;
- 动态分配:DHCP给客户端分配的IP地址过一段时间后会过期,或者客户端可以主动释放该地址(最常用的方式);
- 手动配置:由用户手动为客户端指定IP地址;
(2) DHCP工作流程详解
DHCP协议为客户端分配IP的过程大致如下:

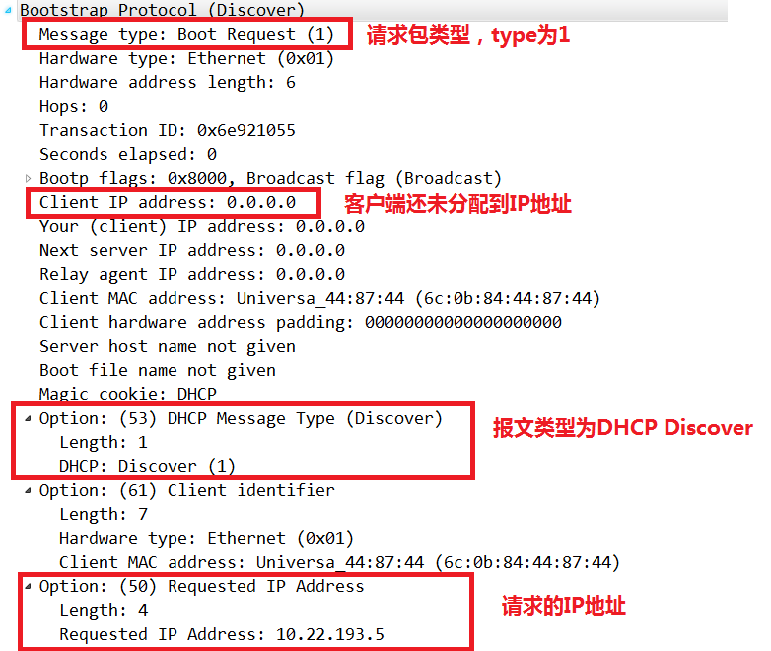
1.DHCP Discover
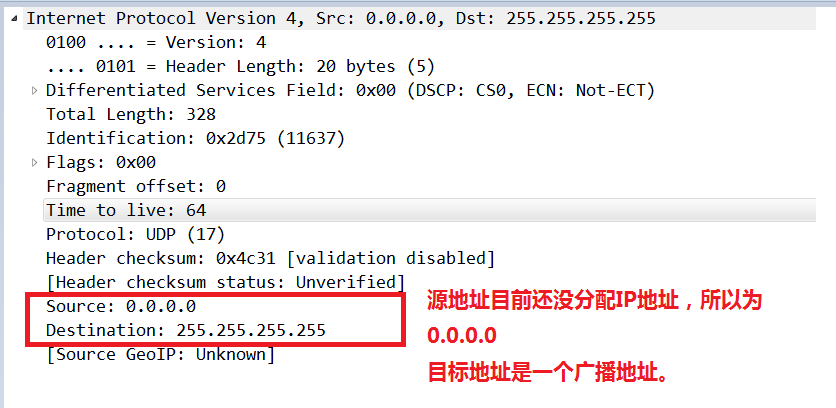
DHCP客户端(需要上网的设备)以广播(因为客户端还不知道DHCP服务器的IP地址)的方式发送DHCP Discover包,来寻找DHCP服务器,即向地址255.255.255.255发送特定的广播信息。网络上每一台安装了TCP/IP协议的主机都会收到该广播消息,但只有DHCP服务器才会做出响应。
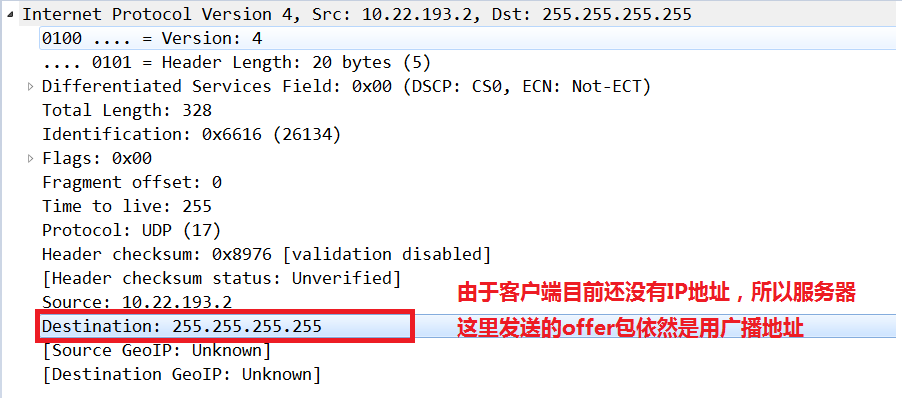
2.DHCP Offer
在该阶段,DHCP服务器提供IP地址。在网络中接收到DHCP Discover包的DHCP服务器,都会做出响应。这些DHCP服务器从尚未出租的IP地址中挑选一个给客户端,向客户端发送一个包含IP地址和其他设置的DHCP Offer包。
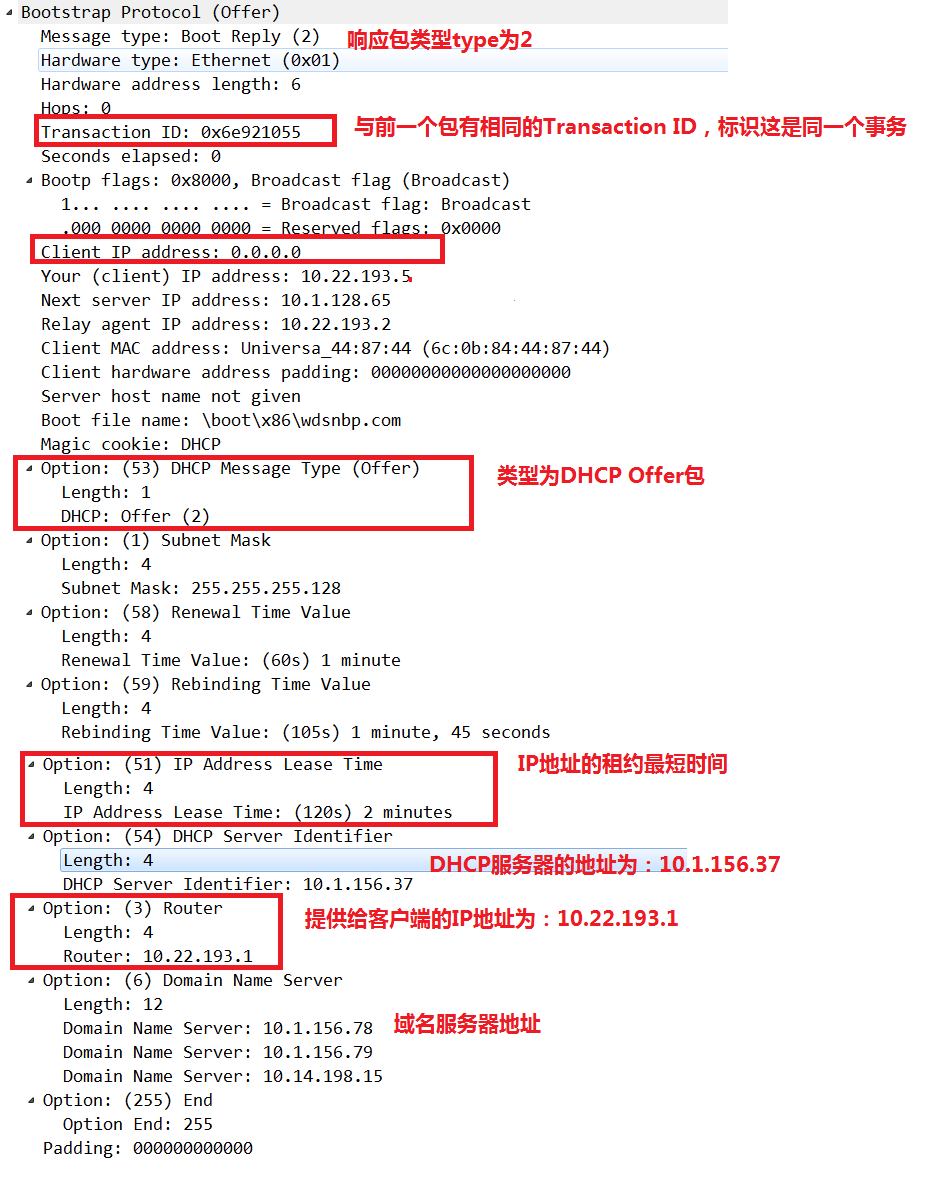
3.DHCP Request
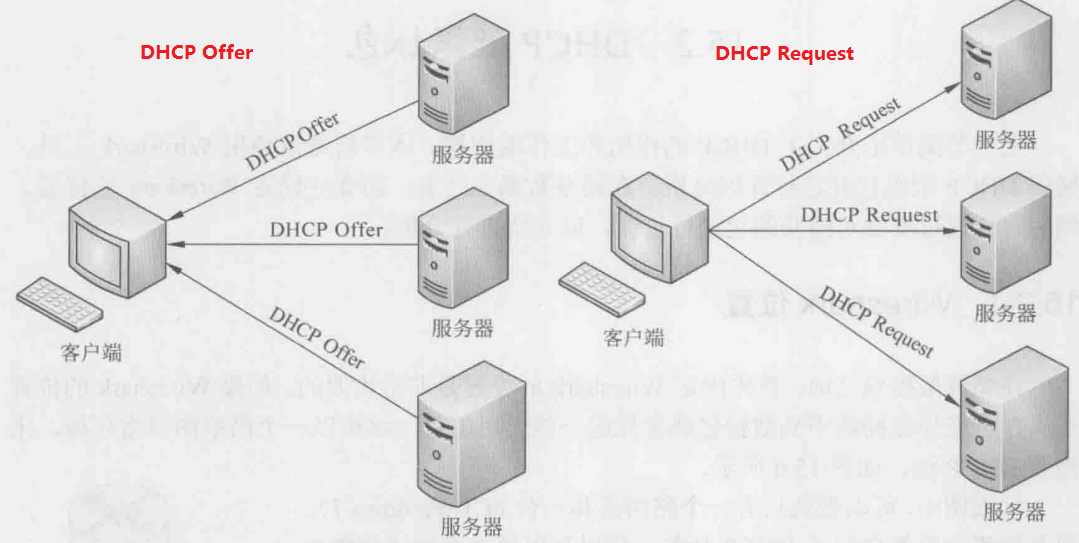
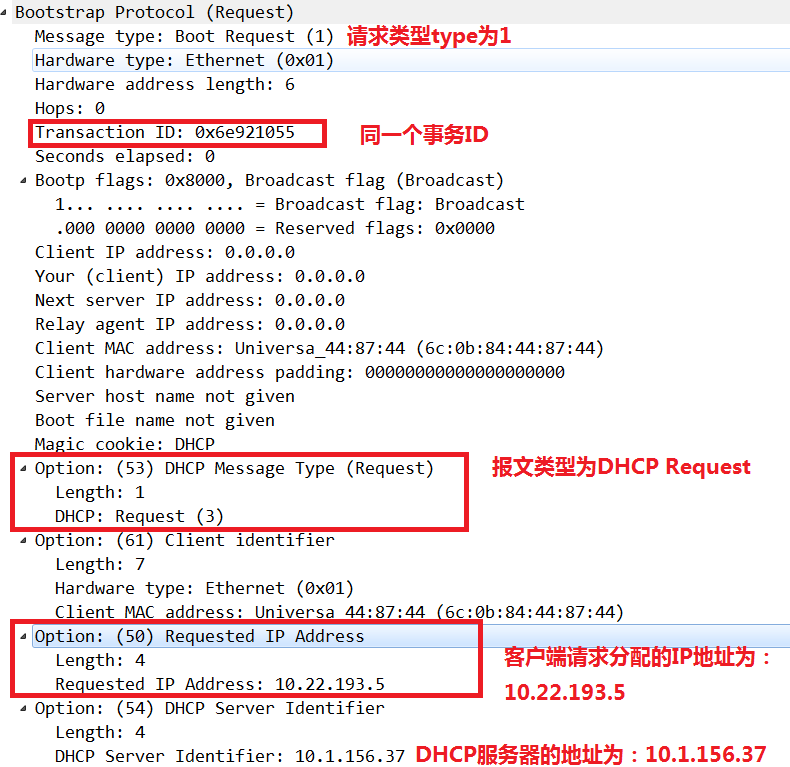
该阶段需要DHCP客户端选择某台DHCP服务器提供的IP地址,如上图所示,可以看到3台DHCP服务器都向客户端发送了DHCP Offer,此时,DHCP客户端只能接受第一个收到的DHCP Offer包信息。然后,以广播的方式回答一个DHCP Request请求信息,该信息中包含它所选定的DHCP服务器请求IP地址的内容。
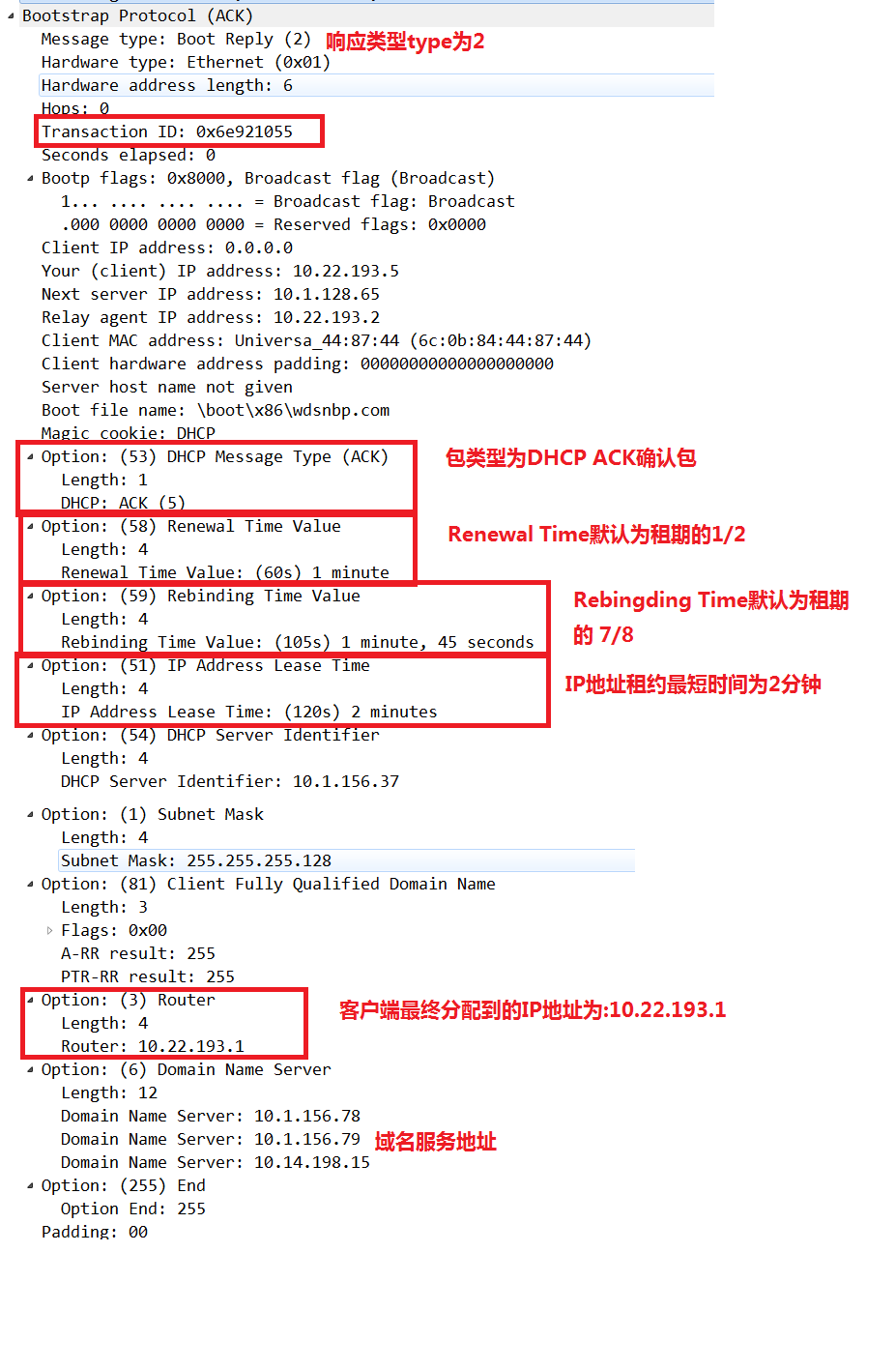
4.DHCP ACK
确认阶段,DHCP服务器确认所提供的的IP地址阶段,告诉DHCP客户端可以使用它所提供的IP地址。
(3) DHCP的续租问题
在DHCP ACK报文中,有3个关于续租时间相关的字段:
- Lease Time:
IP地址租约时间,超过了这个时间后,IP地址被DHCP服务器收回;- Renewal Time:
默认为Lease Time的1/2,表示客户端需要进行续约的时间。客户端发送一个DHCP REQUEST消息给原始的DHCP服务器,并等待回复。DHCP服务器返回DHCP ACK则表示同意续期,客户端更新自己的Renewal Time与Rebinding Time即可。- Rebinding Time:
默认为Lease Time的7/8,客户端在续期失败的情况下,Rebinding Time到期时,会向局域网内广播发送一条DHCP REQUEST消息,如果还没有DHCP服务器响应直至租约Lease Time到期,将恢复到初始状态。
DHCP完成的状态变迁流程如下:

(4) DHCP租期问题对心跳保活的影响
在设计心跳频率时,DHCP租期是一个不确定因素,但是原则是心跳的最大间隔应该低于DHCP的租期时间。
另外,在Android的一些版本上,存在DHCP租期到了不会主动续约并且会继续使用过期IP的bug。这个问题导致的问题表象是,在超过租期的某个时间点(没有规律)会导致IP过期,老的TCP连接不能正常收发数据。并且系统没有网络变化事件,只有等应用判断主动建立新的TCP连接才引起安卓设备重新向DHCP Server申请IP租用。详情可见–Android 2.1 - 4.1.1 Allows DHCP Lease to Expire, Keeps Using IP Address。
4.NAT原理浅析及其对心跳保活的影响
(1) NAT技术产生的背景
在网络协议制定的初期设计网络地址的时候,32bits位长即2的32次幂台终端设备连入互联网已经是一个非常大的数量了,再加上增加ip的长度(即使是从4字节增到6字节)对当时设备的计算、存储、传输成本也是相当巨大的。因此IP地址设计为了32位,并且在早期所有需要上网的设备都有自己的IP地址,也就是说那个时候没有内网和外网的区别,所有客户端都是直接连接到互联网的。
进入20世纪90年代之后,互联网逐步向公众普及,接入互联网的设备数量也快速增长,如果还用原来的方法接入,过不了多久,可分配的地址就用光了。如果不能保证每台设备有唯一不重复的地址,就会从根本上影响网络包的传输,这是一个非常严重的问题。如果任由这样发展下去,不久的将来,一旦固定地址用光,新的设备就无法接入了。在这个背景下NAT技术诞生了(虽然ipv6也是解决办法,但始终普及不开来,而且未来到底ipv6够不够用仍是未知)。
(2) NAT技术的基本工作原理
a.NAT技术的本质
NAT技术主要是为了解决公网IP地址不足的问题,所以才会采取这种地址转换的策略。本质上就是让一群机器公用同一个IP,这样就暂时解决了IP短缺的问题。
b.私有地址与公有地址
不同内网之间是完全独立的。内网之间不会有网络包流动,即使内网A的某台服务器和内网B的某台客户端具有相同的IP地址也没关系,因为它们之间不会进行通信。只要在每个内网自己的范围内,能够明确判断网络包的目的地就可以了,是否和其他局域网中的内网地址重复无关紧要,只要每个局域网自己的网络是相互独立的,
就不会出现问题。
解决地址不足的问题,利用的就是这样的原理,即局域网的内部设备的地址不一定要和其他局域网中的内部设备地址不重复。这样一来,局域网的内部设备就不需要分配固定地址了,从而大幅节省了IP地址。内部设备分配IP地址的方式,就是通过上一节的DHCP协议进行。内网地址的分配有相应的规则,规定某些地址是用于内网的,这些地址叫作私有地址,而原来的固定地址则叫作公有地址。
在内网中可用作私有地址的范围仅限以下这些:
- 10.0.0.0~10.255.255.255
- 172.16.0.0~172.31.255.255
- 192.168.0.0~192.168.255.255
在制定私有地址规则时,这些地址属于公有地址中还没有分配的范围。换句话说,私有地址本身并没有什么特别的结构,只不过是将公有地址中没分配的一部分拿出来规定只能在内网使用它们而已。
c.地址转换(NAT)机制的加入
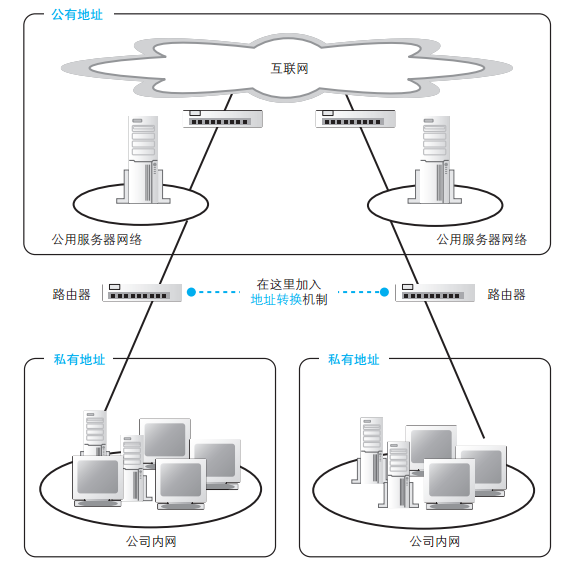
当内网和互联网之间需要传输包的时候,问题就出现了,因为如果很多地方都出现相同的地址,包就无法正确传输了。因此当公司内网和互联网连接的时候,需要采用下图这样的结构,即将公司内网分成两个部分,一部分是对互联网开放的服务器,另一部分是公司内部设备。其中对互联网开放的部分分配公有地址,可以和互联网直接进行通信。相对地,内网部分则分配私有地址,内网中的设备不能和互联网直接收发网络包,而是通过一种特别的机制进行连接,这个机制就叫地址转换。
d.地址转换(NAT)的基本原理
地址转换的基本原理是在转发网络包时对IP头部中的IP地址和端口号进行改写,如下图所示:TCP连接操作的第一个包被转发到互联网时,会将发送方IP地址从私有地址改写成公有地址。这里使用的公有地址是地址转换设备的互联网接入端口的地址。与此同时,端口号也需要进行改写,地址转换设备会随机选择一个空闲的端口。然后,改写前的私有地址和端口号,以及改写后的公有地址和端口号,会作为一组相对应的记录保存在地址转换设备内部的一张表(NAT表)中。

改写发送方IP地址和端口号之后,包就被发往互联网,最终到达服务器,然后服务器会返回一个包。服务器返回的包的接收包是原始包的发送方,因此返回的包的接收方就是改写后的公有地址和端口号。这个公有地址其实是地址转换设备的地址,因此这个返回包就会到达地址转换设备。接下来,地址转换设备会从地址对应表中通过公有地址和端口号找到相对应的私有地址和端口号,并改写接收方信息,然后将包发给局域网的内部设备,这样包就能够到达原始的发送方了。
e.为什么需要改写端口号?
早期的地址转换机制是只改写地址,不改写端口号的。使用这种方法的前提是私有地址和公有地址必须一一对应,也就是说,有多少台设备需要同时访问互联网,就需要多少个公有地址。访问动作结束后可以删除对应表中的记录,这时同一个公有地址可以分配给其他设备使用。
后续随着互联网的发展,同一个局域网里的设备也越来越多。改写端口号正是为了解决这个问题。客户端一方的端口号本来就是从空闲端口中随机选择的,因此改写了也不会有问题。端口号是一个16比特的数值,总共可以分配出几万个端口,因此如果用公有地址加上端口的组合对应一个私有地址,一个公有地址就可以对应几万个私有地址,这种方法提高了公有地址的利用率。
(3) NAT技术带来的弊端
首先,NAT使IP会话的保持时效变短。因为NAT表中的每一条记录,在会话静默的这段时间,NAT网关会进行老化操作。这是任何一个NAT网关必须做的事情,因为IP和端口资源有限,通信的需求无限,所以必须在会话结束后回收资源。通常TCP会话通过协商的方式主动关闭连接,NAT网关可以跟踪这些报文,但总是存在例外的情况,要依赖自己的定时器(NAT超时机制)去回收资源。通过NAT超时机制回收会带来一个问题,如果应用需要维持连接的时间大于NAT网关的设置,通信就会意外中断。因为网关回收相关转换表资源以后,新的数据到达时就找不到相关的转换信息,必须建立新的连接。
其次,NAT在实现上将多个内部主机发出的连接复用到一个IP上,这就使依赖IP进行主机跟踪的机制都失效了。基于用户行为的日志分析也变得困难,因为一个IP被很多用户共享,如果存在恶意的用户行为,很难定位到发起连接的那个主机。NAT隐蔽了通信的一端,把简单的事情复杂化了。
NAT一下对IP端到端模型产生了破坏。NAT通过修改IP首部的信息变换通信的地址。但是在这个转换过程中只能基于一个会话单位。当一个应用需要保持多个双向连接时,麻烦就很大。NAT不能理解多个会话之间的关联性,无法保证转换符合应用需要的规则。当NAT网关拥有多个公有IP地址时,一组关联会话可能被分配到不同的公网地址,这通常是服务器端无法接受的。更为严重的是,当公网侧的主机要主动向私网侧发送数据时,NAT网关没有转换这个连接需要的关联表,这个数据包无法到达私网侧的主机。这些反方向发送数据的连接总有应用协议的约定或在初始建立的会话中进行过协商。
(4) NAT超时机制对心跳保活
上一节已经分析到,NAT超时机制会带来一个问题,如果应用需要维持连接的时间大于NAT网关的设置,通信就会意外中断。因为网关回收相关转换表资源以后,新的数据到达时就找不到相关的转换信息,必须建立新的连接。当这个新数据是由公网侧向私网侧发送时,就会发生无法触发新连接建立,也不能通知到私网侧的主机去重建连接的情况。这时候通信就会中断,不能自动恢复。即使新数据是从私网侧发向公网侧,因为重建的会话表往往使用不同于之前的公网IP和端口地址,公网侧主机也无法对应到之前的通信上,导致用户可感知的连接中断。
所以普遍的一个做法就是使用心跳保活,在一段时间没有数据需要发送时,主动发送一个NAT能感知到而又没有实际数据的保活消息–心跳,这么做的主要目的就是重置NAT的会话定时器。理想的情况下,客户端应当以略小于NAT超时时间的间隔来发送心跳包。根据微信团队测试的一些数据,一些常用网络的NAT超时时间如下表所示:
| 地区/网络 | NAT超时时间 |
|---|---|
| 中国移动3G和2G | 5分钟 |
| 中国联通2G | 5分钟 |
| 中国电信3G | 大于28分钟 |
| 美国3G | 大于28分钟 |
| 台湾3G | 大于28分钟 |
5.小结
本文简单的总结了一些短连接的劣势,以及几种改进的连接方案,并引出长连接的概念和相关的使用场景,并详细对比了keep-alive和心跳机制的不同之处,强调心跳机制对长连接保活的重要意义。并对影响心跳时间的两个关键–DHCP与NAT进行了简单的介绍。现在动态心跳的方案也越来越普及,网上已经有不少文章做了相关的分享,本文参考文献部分也有相关的链接。如有不当之处,敬请批评指正。
参考文献
1. TCP Keepalive HOWTO
2. 移动端IM开发需要面对的技术问题
3. 为什么说基于TCP的移动端IM仍然需要心跳保活
4. DHCP General Operation and Client Finite State Machine
5. dhcp.figure
6. Android 2.1 - 4.1.1 Allows DHCP Lease to Expire, Keeps Using IP Address。
7. 《网络是怎么连接的》–3.4.2节:地址转换的基本原理
8. 《HTTP权威指南》–第4章:连接管理
9. 前端性能–浅谈域名发散与域名收敛
10. Tcp Keepalive 和 HTTP Keepalive详解
11.Android端消息推送总结:实现原理、心跳保活、遇到的问题等
12.P2P技术详解(一):NAT详解——详细原理、P2P简介
13.知乎问答–NAT与DHCP的区别
14.一种Android端IM智能心跳算法的设计与实现探讨
本文来自博客园,作者:sunsky303,转载请注明原文链接:https://www.cnblogs.com/sunsky303/p/10414146.html

