
elk搭建
ELK日志平台搭建
整体架构
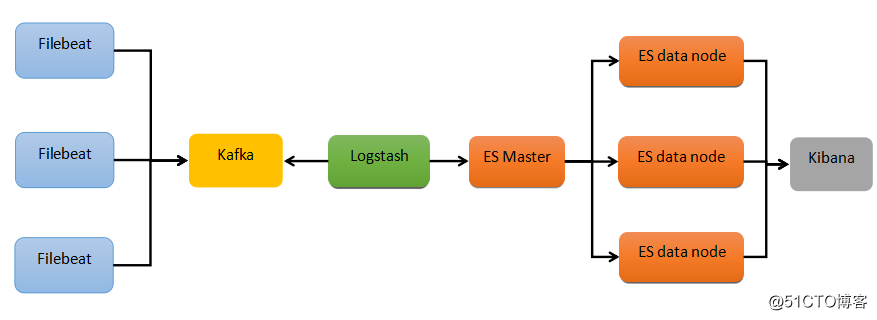
整体架构主要分为5个模块,分别提供不同的功能:
Filebeat:轻量级数据收集引擎。基于原先 Logstash-fowarder 的源码改造出来。是 ELK Stack 在 Agent 的第一选择。<br><br>
Kafka:数据缓冲队列。作为消息队列解耦了处理过程,同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。<br><br>
Logstash:数据收集处理引擎。支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储以供后续使用。<br><br>
Elasticsearch:分布式搜索引擎。具有高可伸缩、高可靠、易管理等特点。可以用于全文检索、结构化检索和分析,并能将这三者结合起来。Elasticsearch 基于 Lucene 开发,现在使用最广的开源搜索引擎之一。<br><br>
Kibana:可视化化平台。它能够搜索、展示存储在 Elasticsearch 中索引数据。使用它可以很方便的用图表、表格、地图展示和分析数据。
版本说明
系统版本: CentOS 7.2
Filebeat: 6.0.1
Kafka: 2.11-1.0.0
Logstash: 6.0.1
Elasticsearch: 6.0.1
Kibana: 6.0.1
JDK: 1.8.0_171友情提示:最好使用对应对的版本进行配置准备工作
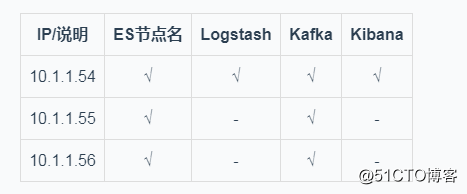
1. 服务器说明
filebeat 部署在每一台线上应用的机器上<br><br>
2. 环境准备
由于Filebeat、Elasticsearch、Logstash、Kibana均不能以root账号运行;所以我们需要创建ELK专用用户,并且修改ELK相关的目录的权限
创建elk用户:useradd elk
修改权限:chown -R elk:elk /usr/local/[目录]
- JDK:
yum install -y java-1.8.0-openjdk - 修改文件限制
vi /etc/security/limits.conf
# 增加内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 2048
* hard nproc 4096- 调整进程数
vi /etc/security/limits.d/20-nproc.conf
# 调整成以下配置
* soft nproc 4096
root soft nproc unlimited- 调整虚拟内存&最大并发连接
vi /etc/sysctl.conf # 增加的内容 vm.max_map_count=655360 fs.file-max=655360 # 保存后,输入命令使其生效:sysctl -p3. 开放相应的端口
# 增加端口 firewall-cmd --add-port=9200/tcp --permanent firewall-cmd --add-port=9300/tcp --permanent firewall-cmd --add-port=5601/tcp --permanent # 重新加载防火墙规则 firewall-cmd --reload搭建过程
@(使用elk用户进行搭建)
Filebeat
filebeat支持收集本地目录的应用日志,并输出日志到kafka集群中
解压:
tar zxf filebeat-6.0.1-linux-x86_64.tar.gz
mv filebeat-6.0.1 /usr/local/filebeat
cd /usr/local/filebeat修改配置:
vi /usr/local/filebeat/filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /home/logs/erp-web/sys.log
# 多行日志配置
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
multiline.negate: true
multiline.match: after
multiline.timeout: 10s
# 定义kafka.topics名称
fields:
log_topics: erp-web
processors:
# 去除filebeat不需要显示的字段
- drop_fields:
fields: ["beat.name", "beat.version", "offset", "prospector.type", "source"]
output.kafka:
enabled: true
hosts: ["10.1.1.54:9092","10.1.1.55:9092","10.1.1.56:9092"]
topic: "%{[fields][log_topics]}"使用elk用户启动:
$ ./filebeat -e -c filebeat.yml
# 如果没有报错的话,使用下面的命令后台运行
$ nohup ./filebeat -e -c filebeat.yml &Kafka
生产环境中 Kafka 集群节点数量建议为(2N + 1 )个,本次是 3 个节点的集群
ZK 集群建议采用 Kafka 自带,减少网络相关的因素干扰
解压:
tar zxf kafka_2.11-1.0.0.tgz
mv kafka_2.11-1.0.0 /usr/local/kafka
cd /usr/local/kafka修改zookeeper配置:
vi config/zookeeper.properties
dataDir=/home/datas/zookeeper
clientPort=2181
maxClientCnxns=50
tickTime=2000
initLimit=10
syncLimit=5
server.54=10.1.1.54:2888:3888
server.55=10.1.1.55:2888:3888
server.56=10.1.1.56:2888:3888Zookeeper data 目录下面添加 myid 文件,内容为代表 Zooekeeper 节点 id (54,55,56),并保证不重复
vi /home/datas/zookeeper/myid
54启动zookeeper:
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &修改kafka配置:
vi config/server.properties
broker.id=54
port=9092
host.name=10.1.1.54
num.replica.fetchers=1
queued.max.requests=16
fetch.purgatory.purge.interval.requests=100
producer.purgatory.purge.interval.requests=100
delete.topic.enable=true
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://10.1.1.54:9092
num.network.threads=8
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/home/logs/kafka-logs
num.partitions=3
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=10.1.1.54:2181,10.1.1.55:2181,10.1.1.56:2181
zookeeper.connection.timeout.ms=6000
zookeeper.sync.time.ms=2000
group.initial.rebalance.delay.ms=0启动kafka:
nohup bin/kafka-server-start.sh config/server.properties &kafka常用命令:
# 创建topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic kafka-test
# 查看创建的topic
bin/kafka-topics.sh -list -zookeeper localhost:2181
# 删除topic
bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic xxx
# 生产消息测试
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic xxx
# 消费消息测试
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic xxx --from-beginning推荐使用kafka-manager进行管理kafka集群可以在 Github 上下载安装:https://github.com/yahoo/kafka-manager
Logstash
解压:
tar zxf logstash-6.0.1.tar.gz
mv logstash-6.0.1 /usr/local/logstash
cd /usr/local/logstash修改配置:
vi conf/erp-web.conf
input {
kafka {
bootstrap_servers => "10.1.1.54:9092,10.1.1.55:9092,10.1.1.56:9092"
group_id => "erp-web"
topics => ["erp-web"]
consumer_threads => 4
decorate_events => true
codec => "json"
type => "erp-web"
}
}
filter {
grok {
patterns_dir => [ "/usr/local/logstash/patterns" ]
match => { "message" => "%{LOG_FAT}" }
overwrite => [ "message" ]
}
date {
match => ["logtime","ISO8601", "yyyy-MM-dd'T'HH:mm:ss.SSS" ]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
remove_field => ["fields","prospector","@version"]
}
}
output {
if [type] == "erp-web" {
elasticsearch {
hosts => ["10.1.1.54:9200","10.1.1.55:9200","10.1.1.56:9200"]
index => "erp-web-%{+YYYY-MM-dd}"
}
#stdout { codec => rubydebug }
}
}# 上面使用了自定义正则匹配的,添加下面的配置
vi patterns/applog
LOG_TIME %{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{HOUR}:?%{MINUTE}(?::?%{SECOND})
SPACE \s*
LOG_THREAD [A-Za-z0-9\-\[\]\.\:]+
LOG_LEVEL ([Aa]lert|ALERT|[Tt]race|TRACE|[Dd]ebug|DEBUG|[Nn]otice|NOTICE|[Ii]nfo|INFO|[Ww]arn?(?:ing)?|WARN?(?:ING)?|[Ee]rr?(?:or)?|ERR?(?:OR)?|[Cc]rit?(?:ical)?|CRIT?(?:ICAL)?|[Ff]atal|FATAL|[Ss]evere|SEVERE|EMERG(?:ENCY)?|[Ee]merg(?:ency)?)
LOG_CLASS ([a-zA-Z0-9-]+\.)+[A-Za-z0-9\(\)]+
LOG_MSG .*
LOG_FAT %{TIMESTAMP_ISO8601:logtime}%{SPACE}%{LOG_THREAD:thread}%{SPACE}%{LOG_LEVEL:level}%{SPACE}%{LOG_CLASS:class}%{SPACE}-%{SPACE}%{LOG_MSG:message}使用elk用户启动:
# 测试配置语法是否正确
bin/logstash -f config/erp-web.conf -t
# 指定配置文件启动
nohup bin/logstash -f config/erp-web.conf &
# 多配置文件启动:
nohup bin/logstash -f config/ &Elasticsearch
解压:
tar zxf elasticsearch-6.0.1.tar.gz
mv elasticsearch-6.0.1 /usr/local/elasticsearch
cd /usr/local/elasticsearch修改配置:
vi config/elasticsearch.yml # 统一下面配置,修改部分会给出说明
cluster.name: btr-es01
node.name: node-54 # 节点名不能相同
node.master: true
node.data: true
path.data: /home/apps/elasticsearch
path.logs: /home/logs/elasticsearch
network.host: 0.0.0.0
network.publish_host: 10.1.1.54 # host也需要修改对用的IP
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["10.1.1.54", "10.1.1.55", "10.1.1.56"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow-origin: "*"切换elk启动:
$ bin/elasticsearch
# 如果没有报错的话,使用下面的命令后台运行
nohup bin/elasticsearch &测试结果:
浏览器输入:http://10.1.1.54:9200/ ,出现一下信息说明配置成功
{
"name" : "node-54",
"cluster_name" : "btr-es01",
"cluster_uuid" : "qAsLXddUQDSoOg-I2eT5AQ",
"version" : {
"number" : "6.0.1",
"build_hash" : "601be4a",
"build_date" : "2017-12-04T09:29:09.525Z",
"build_snapshot" : false,
"lucene_version" : "7.0.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
其他两台机器类似上面的配置,搭建好了elasticsearch分布式集群!
Kibana
解压:
tar zxf kibana-6.0.1-linux-x86_64.tar.gz
mv kibana-6.0.1-linux-x86_64 /usr/local/kibana
cd /usr/local/kibana修改配置:
vi config/kibana.yml
server.port: 5601
server.host: 10.1.1.54
elasticsearch.url: "http://10.1.1.54:9200"启动:
nohup bin/kibana &浏览器访问: http://10.1.1.54:5601

 浙公网安备 33010602011771号
浙公网安备 33010602011771号