
二叉树遍历方法大全(包含莫里斯遍历)
前言
二叉树的遍历可能大家都比较熟悉了,这篇文章主要介绍了三种二叉树的遍历方法——递归、迭代和莫里斯遍历,他们各自有各自的特点。其中最重要的是莫里斯遍历,相对于前两种方法比较少见,只需要固定的空间就可以完成迭代遍历。这篇文章将会结合动图,带你了解关于树遍历的知识。
简介
我们通常希望通过访问树的每个节点来处理二叉树,每次执行特定的操作,例如打印节点的内容、得到树的所有节点的总和或者要找到最大的值。以某种顺序访问所有节点的过程称为遍历,仅遍历树中每个节点一次的遍历称为树节点的枚举。某些应用不需要以任何特定顺序访问节点,只要每个节点被精确访问一次即可;有些应用,必须按保留某些关系的顺序访问节点。
线性数据结构(如数组、堆栈、队列和链表)只有一种读取数据的方法,但是像树这样的分层数据结构可以以不同的方式遍历。
遍历种类
根据我们遍历树的顺序,我们把遍历分成三种,分别是:
- 中序遍历
- 前序遍历
- 后序遍历
这些遍历方式和树的结构有关。
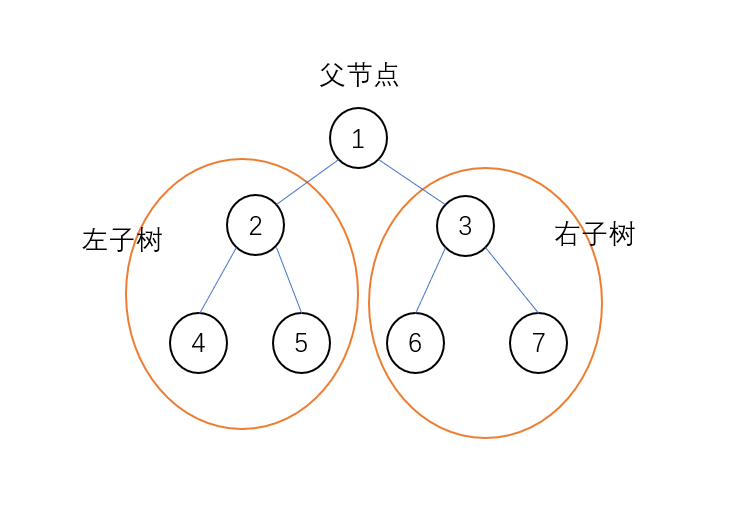
中序遍历
- 先遍历左子树
- 再遍历父节点
- 最后遍历右子树
图片中的中序遍历结果应该是[4,2,5,1,6,3,7]
前序遍历
- 先遍历父节点
- 再遍历左子树
- 最后遍历右子树
图片中的前序遍历结果应该是[1,2,4,5,3,6,7]
后序遍历
- 先遍历左子树
- 再遍历右子树
- 最后遍历父节点
图中的后序遍历结果应该是[4,5,2,6,7,3,1]
代码实现
首先定义树的结构
public class TreeNode {
public int val;
public TreeNode left;
public TreeNode right;
public TreeNode(int x) { val = x; }
}
在代码实现里面我们要返回按照特定遍历顺序依次遍历的节点
中序实现
中序递归
按照中序遍历的定义可以很容易用递归来实现
public List<Integer> inorderTraversal(TreeNode root) {
if (root == null) {
return new ArrayList<>();
}
List<Integer> res = new ArrayList<>(); // 保存最后的结果
inorderTraversal(root, res);
return res;
}
public void inorderTraversal(TreeNode root, List<Integer> res) {
if (root == null) {
return;
}
inorderTraversal(root.left, res); // 遍历左子树
res.add(root.val); // 遍历父节点
inorderTraversal(root.right, res); // 遍历右子树
}
中序迭代
采用迭代的方法就有点复杂了,需要借助额外的数据结构——栈。
这个方法的思路是:
先从父结点遍历左子节点,一直遍历到不再存在左子节点,然后从栈顶开始检查,对刚才遍历的节点进行逆向遍历,找到每一个节点的右子节点,如果这些右子节点有左节点就继续压入栈中(相当于下次遍历要从这个右子节点的左子树开始),继续上面的过程。
整个相当于深度优先遍历,从每个节点的左节点遍历,遍历父节点,最后遍历右节点。栈的作用相当于记住了上次遍历的位置,用来保存下次应该开始遍历的节点。
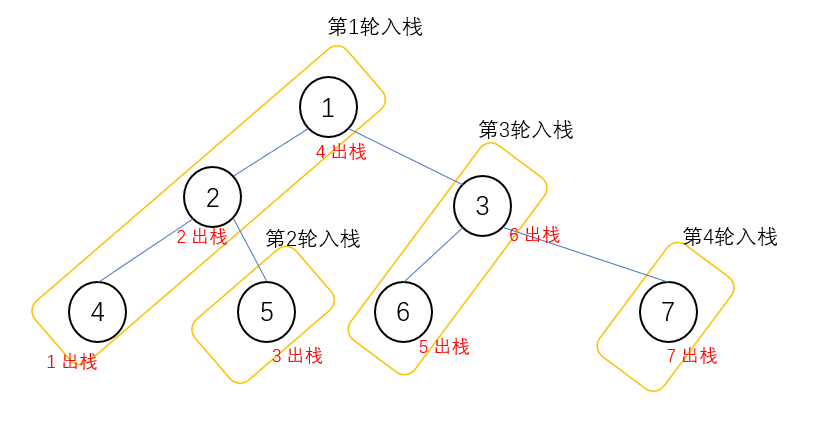
public List<Integer> inorderTraversal(TreeNode root) {
if (root == null) {
return new ArrayList<>();
}
Stack<TreeNode> stack = new Stack<>();
List<Integer> res = new ArrayList<>(); // 遍历结果
stack.push(root);
TreeNode cur = root.left;
while (!stack.isEmpty() || cur != null) {
while (cur != null) { // 先将所有的左节点的内容压入栈中
stack.push(cur);
cur = cur.left;
}
cur = stack.pop(); // 出栈的时候进行遍历
res.add(cur.val);
cur = cur.right; // 代表开始遍历右子树
}
return res;
}
中序莫里斯迭代
莫里斯遍历不需要递归或者临时的栈空间就可以完成遍历,空间复杂度是常数。但是为了解决从子节点找到父节点的问题,需要临时修改树的结构,在遍历完成之后复原成原来的树结构。
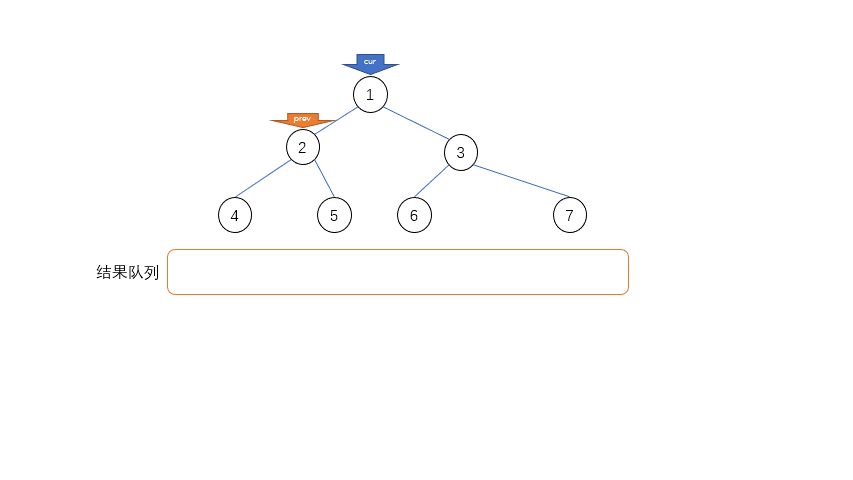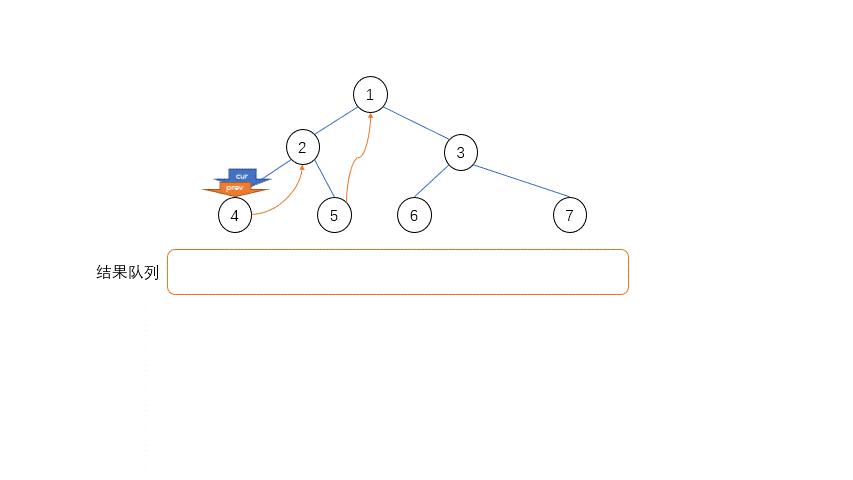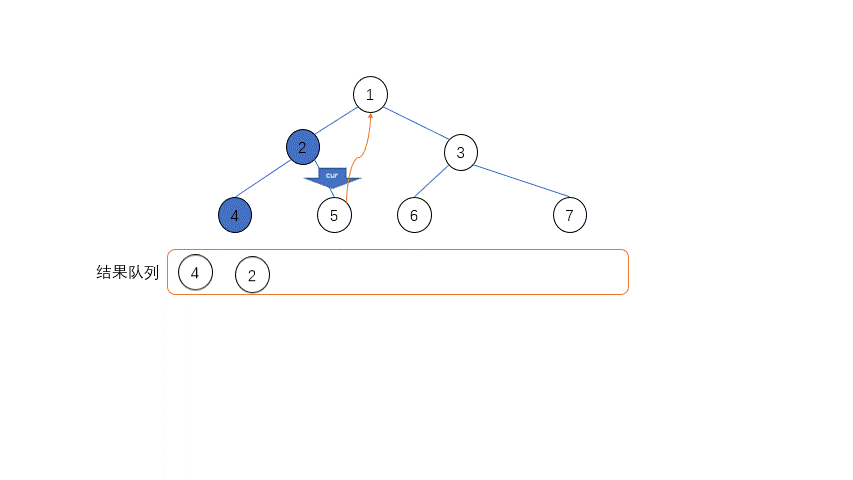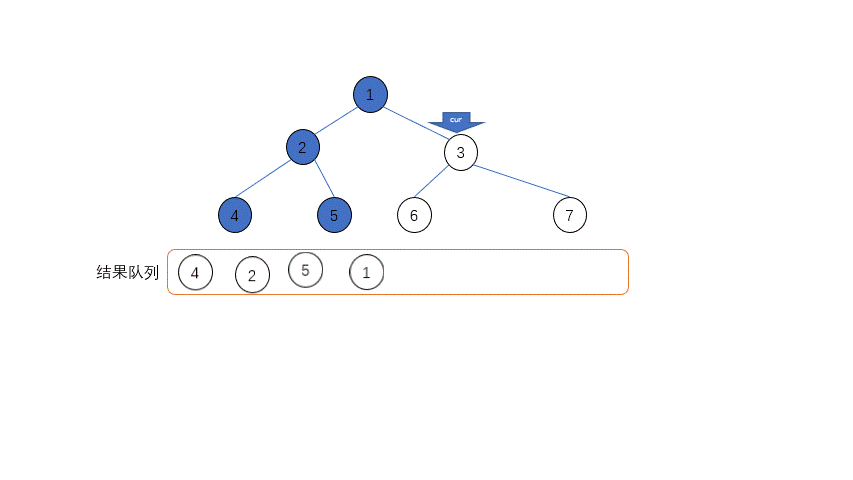
整个遍历的过程中只需要两个指针——当前指针cur和临时前驱指针prev,具体的过程如下
- 如果左子节点是空,录入当前节点,当前指针
cur指向右子节点 - 如果左子节点不是空,遍历左子节点的最右侧右子节点,找到最右侧叶节点,在寻找的过程中可能出现两种情况:
- 如果遍历到的叶节点的右子节点是空,把叶节点的右子节点指向
cur节点,cur移向左子节点 - 如果遍历到的叶节点的右子节点是
cur节点,表示原来的叶节点到cur节点连接已经存在,现在遍历结束了,需要复原,置节点的右子节点为空,在录入了cur节点之后,cur移到自己的右子节点
- 如果遍历到的叶节点的右子节点是空,把叶节点的右子节点指向
- 重复上面两步直到当前节点为空
其中最不好理解的是第二步,遍历左子树的右节点的过程中,只有当左子树没有建立到父节点的连接的时候,才能最后遍历到尽头,达到尽头之后需要和父节点连接起来,当cur遍历到这个叶节点的时候才能回到正确的父节点的位置。
当当前节点cur遍历完了左子树回到父节点的时候,多余的连接还是存在的,需要移除这个连接,而方法就是和建立连接一样遍历左子树找到最右侧节点,这个时候判断的依据就不能是右节点为空,必须是左子节点的最右节点等于当前节点,相当于找到循环的起点,然后在这个地方切断联系。
代码实现:
public List<Integer> inorderTraversal(TreeNode root) {
if (root == null) {
return new ArrayList<>();
}
TreeNode cur = root; // 记录当前节点位置
List<Integer> res = new ArrayList<>();
while (cur != null) {
if (cur.left == null) { // 左节点为空,移到右子节点
res.add(cur.val);
cur = cur.right;
} else {
TreeNode prev = cur.left;
while (prev.right != null && prev.right != cur) { // 遍历到左子树的最右侧节点
prev = prev.right;
}
if (prev.right == null) { // 建立返回父节点连接
prev.right = cur;
cur = cur.left;
} else { // 左子树建立了连接,说明遍历完了,可以拆除连接
res.add(cur.val); // 中序遍历录入当前节点
prev.right = null;
cur = cur.right;
}
}
}
return res;
}
时间复杂度分析:莫里斯遍历的空间复杂度是常数,这个比较好理解,但是时间复杂度为什么是O(n)呢?明明在代码里面有个嵌套的循环可能会提高时间复杂度:
while (prev.right != null && prev.right != cur) { // 遍历到左子树的最右侧节点
prev = prev.right;
}
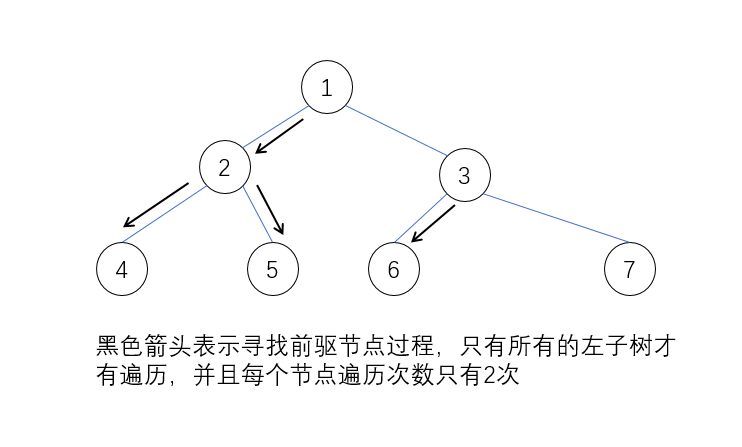
可是如果在图中模拟一下这个循环就会发现其实在寻找前驱节点的过程中,所有的节点其实最多只被遍历了两遍!比如对于节点1,在寻找前驱节点的时候遍历了2和5;当cur从5回到1之后,又遍历了一遍2和5,至此2和5在所有寻找前驱节点的过程中各遍历了两边,而在寻找2..7的前驱节点的时候,都没有遍历到2和5(除去了从2和5本身开始查找前驱节点时对自己的遍历),所以2和5总体在前驱搜索的过程中只有两次,加上他们自身的遍历,也就只有3次。综合来说,树的每个节点的遍历次数最多都是3次,所以时间复杂度是O(n)级别的。
前序实现
前序递归
和中序的递归差不多,只有一行代码的区别:
public List<Integer> preorderTraversal(TreeNode root) {
if (root == null) {
return new ArrayList<>();
}
List<Integer> res = new ArrayList<>(); // 保存最后的结果
preorderTraversal(root, res);
return res;
}
public void preorderTraversal(TreeNode root, List<Integer> res) {
if (root == null) {
return;
}
res.add(root.val); // 遍历父节点 注意这行代码提前了
preorderTraversal(root.left, res); // 遍历左子树
preorderTraversal(root.right, res); // 遍历右子树
}
前序迭代
直接根据中序迭代的方法,将记录遍历元素的时机改为了在入栈的时候就记录,也就是将父节点计入数组的时间提前了。
public List<Integer> preorderTraversal3(TreeNode root) {
if (root == null) {
return new ArrayList<>();
}
Stack<TreeNode> stack = new Stack<>();
List<Integer> res = new ArrayList<>(); // 遍历结果
stack.push(root);
TreeNode cur = root.left;
res.add(root.val); // 记录根节点元素
while (!stack.isEmpty() || cur != null) {
while (cur != null) { // 先将所有的左节点的内容压入栈中
stack.push(cur);
res.add(cur.val); // 这里在入栈的时候就要记录遍历的元素
cur = cur.left;
}
cur = stack.pop();
cur = cur.right; // 代表开始遍历右子树
}
return res;
}
前序莫里斯
和中序莫里斯遍历的代码也基本一样,只不过当左子节点存在的时候,添加节点元素的位置从拆除多余连接的时候变成了建立连接的时候,也就是在移动cur指针之前就得记录节点,保证当前指向的节点是最先记录的,左右子树的节点要靠后,并且不能重复记录元素。
public List<Integer> preorderTraversal(TreeNode root) {
if (root == null) {
return new ArrayList<>();
}
TreeNode cur = root; // 记录当前节点位置
List<Integer> res = new ArrayList<>();
while (cur != null) {
if (cur.left == null) { // 左节点为空,移到右子节点
res.add(cur.val);
cur = cur.right;
} else {
TreeNode prev = cur.left;
while (prev.right != null && prev.right != cur) { // 遍历到左子树的最右侧节点
prev = prev.right;
}
if (prev.right == null) { // 建立返回父节点连接
prev.right = cur;
res.add(cur.val); // 注意添加元素到数组的代码位置移到了这里
cur = cur.left;
} else { // 左子树建立了连接,说明遍历完了,可以拆除连接
prev.right = null;
cur = cur.right;
}
}
}
return res;
}
后序实现
后序递归
后序递归和前中递归的实现差不多,只需要把录入元素的时机放在遍历左右子树之后就行了
public List<Integer> postorderTraversal(TreeNode root) {
if (root == null) {
return new ArrayList<>();
}
List<Integer> res = new ArrayList<>(); // 保存最后的结果
postorderTraversal(root, res);
return res;
}
public void postorderTraversal(TreeNode root, List<Integer> res) {
if (root == null) {
return;
}
postorderTraversal(root.left, res); // 遍历左子树
postorderTraversal(root.right, res); // 遍历右子树
res.add(root.val); // 遍历父节点
}
还有另外一种递归可能会对我们后序迭代算法略有启发:我们可以通过将遍历父节点操作放在最前面,然后交换遍历左右子树的顺序,得到反转的后序遍历结果,最后反转一下就能得到正确的遍历结果。
public List<Integer> postorderTraversal(TreeNode root) {
if (root == null) {
return new ArrayList<>();
}
List<Integer> res = new ArrayList<>(); // 保存最后的结果
postorderTraversal(root, res);
Collections.reverse(res); // 反转数组
return res;
}
public void postorderTraversal(TreeNode root, List<Integer> res) {
if (root == null) {
return;
}
res.add(root.val); // 遍历父节点
postorderTraversal(root.right, res); // 遍历右子树
postorderTraversal(root.left, res); // 遍历左子树
}
后序迭代
后序迭代就比较巧妙了,利用上面讲到的修改前序遍历的遍历左右子树的顺序,移植到迭代过程中的栈的操作,把原来的所有的right改成left,原来的left改成right
public List<Integer> postorderTraversal(TreeNode root) {
if (root == null) {
return new ArrayList<>();
}
Stack<TreeNode> stack = new Stack<>();
List<Integer> res = new ArrayList<>(); // 遍历结果
stack.push(root);
TreeNode cur = root.right;
res.add(root.val); // 添加根节点,反转后变成最后元素
while (!stack.isEmpty() || cur != null) {
while (cur != null) { // 先将所有的右节点的内容压入栈中
stack.push(cur);
res.add(cur.val); // 添加当前遍历的节点
cur = cur.right;
}
cur = stack.pop();
cur = cur.left; // 代表开始遍历左子树
}
Collections.reverse(res); // 反转最后的结果
return res;
}
后序莫里斯迭代
修改后序莫里斯迭代的思路其实和上面修改后序迭代的思路一样
- 把前序莫里斯遍历的代码粘贴过来
- 把原来所有的
right改成left,把原来所有的left改成right - 返回结果之前反转一下数组
这种后序迭代遍历的核心思路都是通过交换前序遍历中遍历左右子树的顺序,达到完全逆转后序遍历的结果,最后反转得到正确的结果。
public List<Integer> postorderTraversal(TreeNode root) {
if (root == null) {
return new ArrayList<>();
}
TreeNode cur = root; // 记录当前节点位置
List<Integer> res = new ArrayList<>();
while (cur != null) {
if (cur.right == null) { // 右节点为空,移到左子节点
res.add(cur.val);
cur = cur.left;
} else {
TreeNode prev = cur.right;
while (prev.left != null && prev.left != cur) { // 遍历右子树的最左侧节点
prev = prev.left;
}
if (prev.left == null) { // 建立返回父节点连接
prev.left = cur;
res.add(cur.val); // 添加元素到数组
cur = cur.right;
} else { // 右子树建立了连接,说明遍历完了,可以拆除连接
prev.left = null;
cur = cur.left;
}
}
}
Collections.reverse(res); // 最后要反转数组得到最后的结果
return res;
}
总结
总的来说二叉树的遍历是非常重要也是非常基础的知识,大部分人都能够轻松的写出递归的做法,递归的代码是最简洁明了容易理解的。
迭代的解决方法比较少见,需要额外的数据结构,循环的逻辑也不是那么容易理解,但是在面试或者OJ系统里面可能会出现的比较多。
关于莫里斯遍历,可能大多数人都没有听说过这种巧妙的遍历方法,需要修改树的结构以降低空间开销,同时在遍历结束之后还要复原树的结构。这种遍历相对于上面的迭代更加难以理解,但是它只需要两个变量就可以完成遍历的特点令人影响深刻。
参考
Morris Traversal方法遍历二叉树(非递归,不用栈,O(1)空间)
What is Morris traversal?
二叉树的前序、中序、后序遍历—迭代方法
更多精彩内容请看我的个人博客


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义