
【论文笔记】BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
摘要:
解决长尾分布问题主要的方法是类重平衡策略(re-sample、re-weight)。本文首次发现这些重平衡方法能取得不错的效果是得益于它们提升深度网络的分类器学习,但同时它们会一定程度上损害所学习特征的表示能力。论文提出统一的双边分支网络(BBN),同时考虑表示学习和分类器学习,每一个分支分别执行自己的任务。BBN网络进一步采用了新型的累积学习策略,首先学习通用模式,然后逐渐关注尾部数据。在四个基准数据集(包括大规模不自然数据集)上进行的大量实验证明,所提出的BBN可以显著优于最先进的方法。此外,验证实验可以证明我们在BBN中的初步发现和跟踪设计的有效性。
核心思路:
一、提出论点
作者首先分析了主流的解决长尾分布问题的方法。类重平衡策略可以调整网络训练,通过对一个mimi-batch重采样或者重加权损失,实质是期望训练数据分布更接近测试数据分布。因此,类重平衡可以直接影响深度网络分类器权值的更新,从而促进分类器的学习。这就是为什么重新平衡可能发生的原因在长尾数据上实现令人满意的识别精度。
然而,尽管重平衡方法具有良好的准确率,但这些方法仍然具有不利影响,即它们也会在一定程度上意外地损害所学习深层特征的表征能力(即表示学习)。具体地说,当数据不平衡严重时,重采样有过度拟合尾部数据(过采样)的风险,也有欠拟合整个数据分布(欠采样)的风险。对于重新加权,它将通过直接更改甚至反转数据来扭曲原始分布出现频率。
二、证明论点
进行实验以证明“重平衡策略会一定程度损害特征的表示能力”这一论点。
为了弄清楚重平衡策略是如何工作的,吧深度网络的训练过程分为两个阶段,分开表示学习和分类器学习。在一阶段的表示学习,我们采用CE(交叉损失),RW(重加权),RS(重采样),三种学习方式来获得相应的学习表示。在后一阶段的分类器学习,首先固定一阶段收敛的表示学习(back-bone layers)的参数,然后也使用三种学习CE、RW、RS重新训练这些网络(fully-connected layers)的分类器。
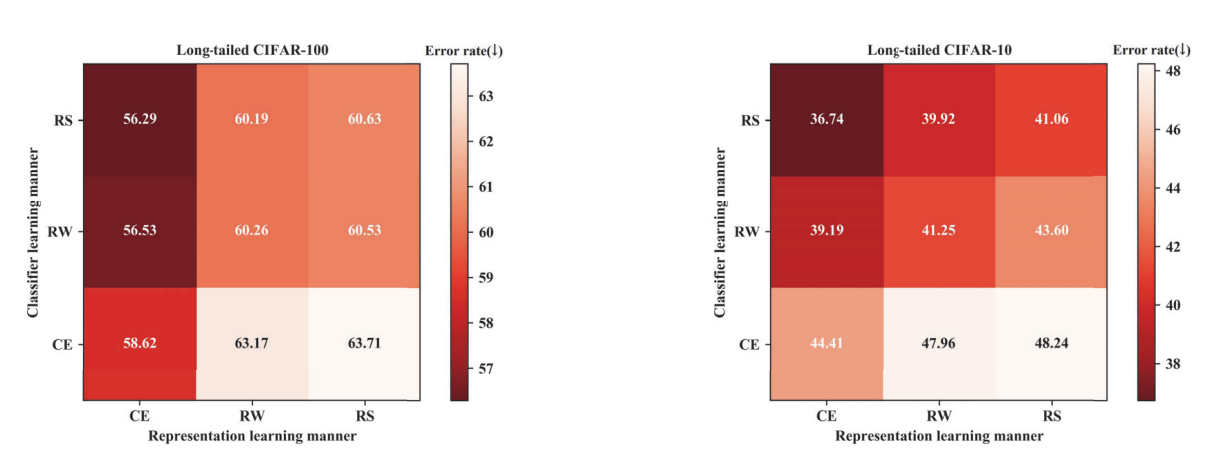
纵向比较:对于同一种表示学习方式,RS/S相对于CE取得更低的误差率,这是由于重平衡操作调整分类器权重更新以符合测试分布。
横向比较:对于同一种分类器学习方式,正好相反,CE相对于RS/RE取得更低的误差。这意味着CE取得更好的特征。RW/RE学习到的特征比较差(学习到的深层特征的辨别能力差)。证明了类重平衡策略会一定程度上损害特征的表示学习能力。
三、解决方案
类平衡损失策略分类器对于长尾分布问题有较大的改善,但是在一定程度上损特征的表示学习,所以应该采取将二者结合的方案,即兼顾特征的表示能力和平衡策略的优点。
作者提出BBN网络结构,其包含两个分支,“conventional learning branch”和“re-balanceing branch”。
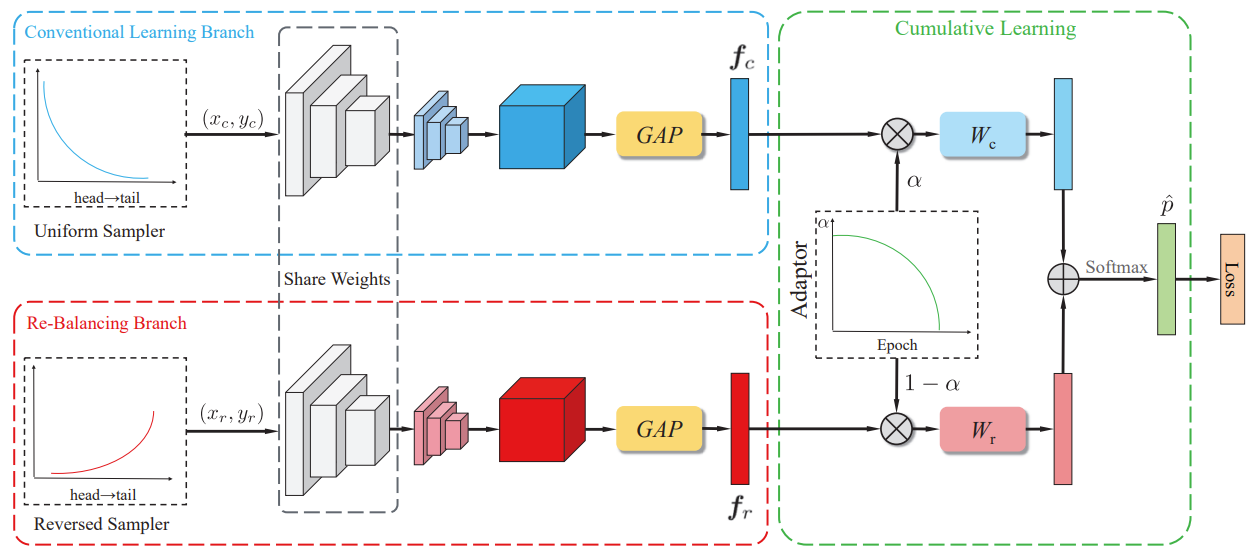
“Conventional Learning Branch”,传统卷积学习分支,得到表示学习能力。输入(Xc,Yc)来自uniform sampler,训练集样本均匀采样,每个样本概率相同。然后,通过残差网络提取特征,得到特征向量Fc。
“Re-balanceing Branch”,重平衡分支,得到分类能力。输入(Xr,Yr)来自reversed sampler,每一类别入样概率与类别比重成反比,即尾部类入样比例高。然后,通过残差网络提取特征,得到特征向量Fr。
“Cumulation Learning”,累积学习将双边分支的预测输出聚合起来。累积学习使用了一个自适应权衡参数 α,它通过适应器(Adaptor)根据当前训练 epoch 的数量自动生成,可以调节整个 BBN首先从原始分布学习通用的特征,然后再逐渐关注尾部数据。参数α控制fc和fr的权重,加权特征向量αfc和(1− α) fr将被发送到分类器Wc∈ RD×C和Wr∈ 分别为RD×C,输出将通过元素加法集成在一起。
![]()
使用softmax函数
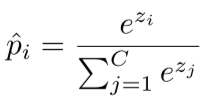
损失函数使用交叉熵
![]()
此外,α 并没有阶跃式地从1变为0,而是逐渐降低,使得两个分支在整个训练过程可以同时维持学习状态,让模型在迭代后期关注尾部数据的同时不损害已习得的通用表征,计算方式如下:
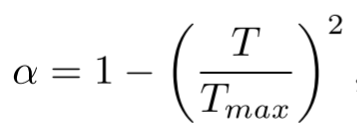
再看一遍算法流程:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号