《MySQL实战45讲》学习笔记1——MySQL的基础架构
在《极客时间》订阅了《MySQL实战45讲》专栏,总觉得看完和没看一样🤦♀️
想了想还是决定输出一下,好记性不如烂笔头嘛!
题外话结束,正文开始👇
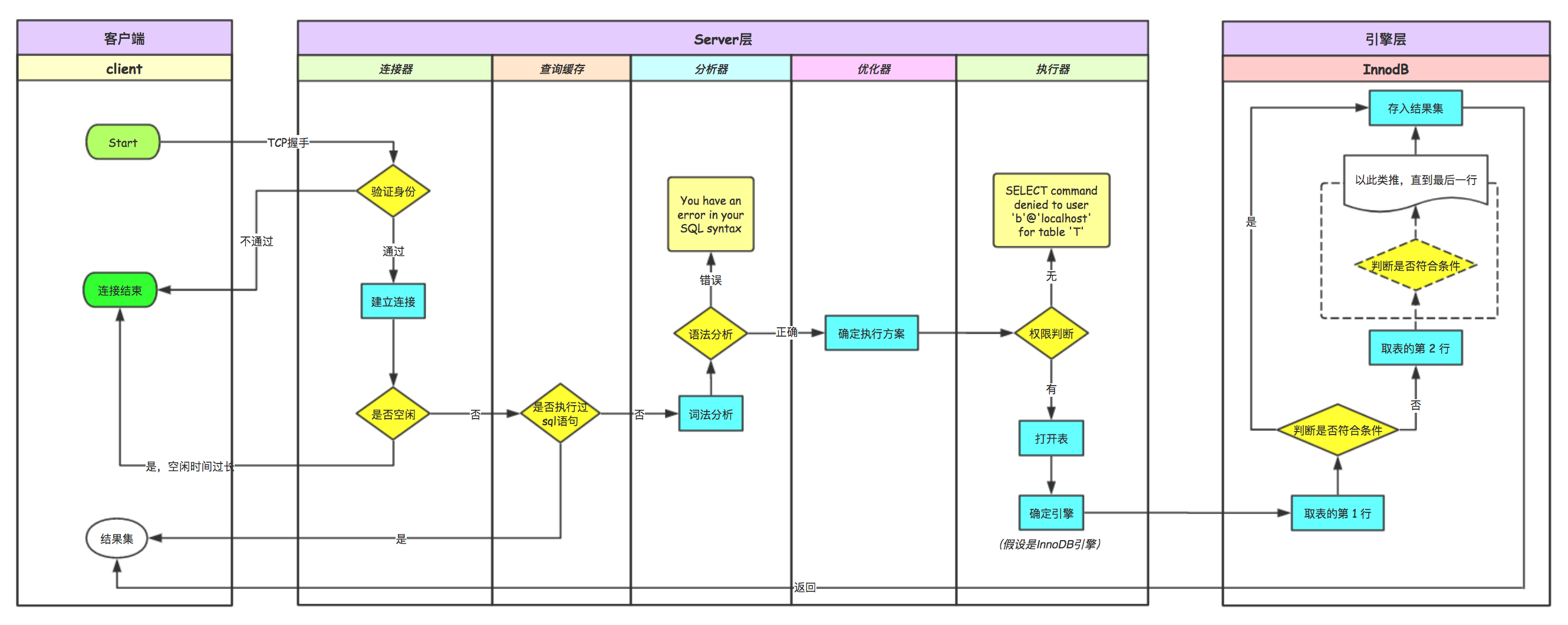
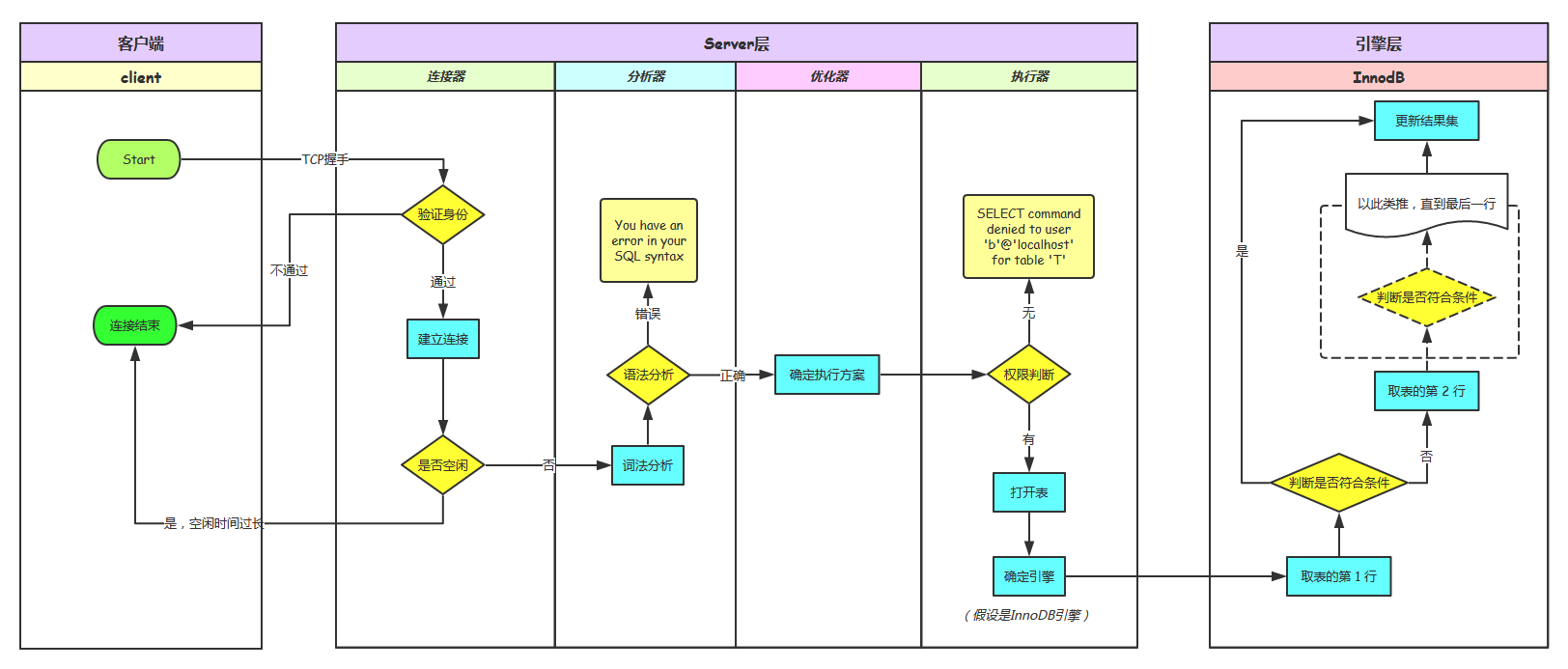
MySQL的基础架构分为两大部分:Server层和引擎层。
Server层:包括包括连接器、查询缓存、分析器、优化器、执行器等。
作用:① 内置函数、
② 跨存储引擎的功能,如存储过程、触发器、视图等。
引擎层:支持 InnoDB、MyISAM、Memory 等多个存储引擎。
作用:负责数据的存储和提取。
客户端
mysql -h ip -P port -u username -p
客户端通过上述命令与 Server 层建立连接,即通过 TCP 握手与 Server 层的连接器建立连接。
连接器
连接器会校验身份,当用户名和密码都正确时,会从权限表里查出对应的权限,与客户端建立连接、获取权限、维持和管理连接。
当连接成功建立后,如果没有后续操作,会处于空闲状态,8小时后自动断开,非交互连接的超时时间依赖于 wait_timeout 参数,默认是28800,就是8小时。
由于建立连接的过程比较复杂,会耗费时间和性能,因此应该尽量减少建立连接的动作,使用长连接。但使用长连接可能导致内存占用过大,被系统强行杀掉,异常重启。因此可以定期断开长连接,或者使用MySQL 5.7+ 版本,当执行一个比较大的操作后,通过执行mysql_reset_connection 来重新初始化连接资源。
查询缓存
当连接建立后,若执行 select * from t where id=10; SQL语句,MySQL会先去查询缓存,若先前执行过该语句,则会以 key-value 对的形式把结果存储在缓存中,其中,key 是查询语句,value 是查询结果。那么再次查询时会去查找这个 key,若找到,则将 value 返回给客户端。
大多数情况下不建议查询缓存,因为只要有对一个表的更新,查询缓存就会被清空,这就会导致查询缓存的命中率很低,可以通过将 query_cache_type 设置成 DEMAND 的方式,默认不使用查询缓存。MySQL 8.0 版本不再有查询缓存这一功能了。
分析器
如果没有从查询缓存中查到结果,则进行词法分析,MySQL会将 SQL 语句中的关键字,如“select”、“from”等识别出来,将 t 识别成表名,将 id 识别成列名,然后进行语法分析,判断SQL语句语法是否正确。
优化器
当 t 表使用了多个索引,优化器会决定使用哪个索引;或者有多表联表查询(join)的时候,优化器决定各个表的连接顺序。优化器会确定这个 SQL 语句的执行方案。
执行器
MySQL先去校验对 t 表的执行查询权限,若没有,则返回没有权限的错误,反之则打开表,按照表的引擎提供的接口执行 SQL 语句。
存储引擎
存储引擎负责提供数据,先取表的第 1 行,判断id是否等于10,如果是则将结果存在结果集中,并返回给客户端。否则,继续取表的下一行,直到表的最后一行。
以上就是MySQL的基础架构,也是一条 SQL 查询语句的执行过程。
如果是 SQL 更新语句,流程与 SQL 查询语句的执行过程大同小异。前面在“查询缓存”中提到,对一个表的更新就会清空查询缓存,因此不建议使用缓存。
流程如下图所示:
分类:
数据库与缓存
标签:
MySQL实战45讲



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现