2、django 模型
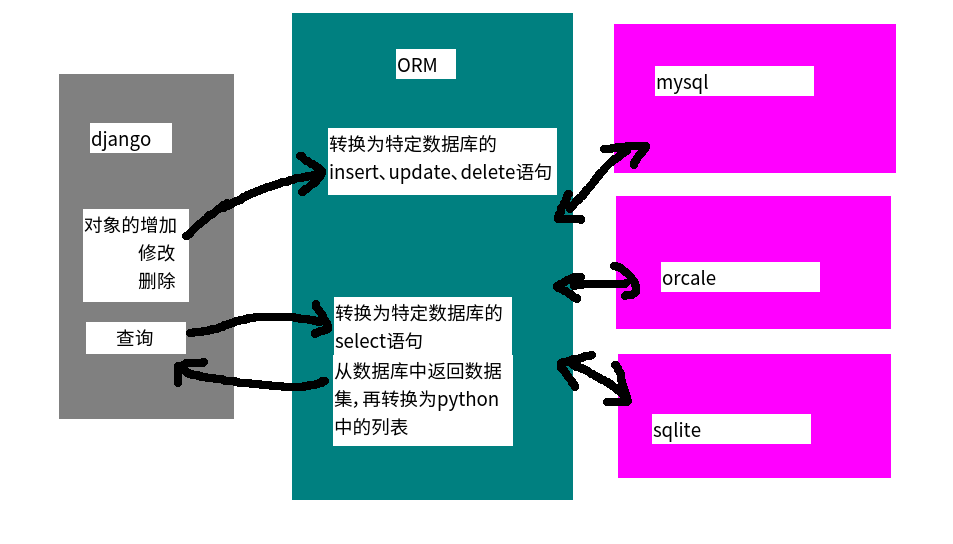
ORM 简介
- ORM 实现了模型类和数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库
- ORM是“对象-关系-映射”的简称,主要任务是:
- 根据对象的类型生成表结构
- 将对象、列表的操作,转换为sql语句
- 将sql查询到的结果转换为对象、列表
使用mysql数据库
在Django入门的时候已经配置过。
1、首先要安装 mysql-python模块。
pip install mysql-python
2、mysql中创建数据库。
create databases 数据库 charset=utf8
3、打开settings.py文件,修改DATABASES项
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': '数据库名称',
'USER': '用户名',
'PASSWORD': '密码',
'HOST': '数据库服务器ip,本地可以使用localhost',
'PORT': '端口,默认为3306',
}
}
开发流程
- 在models.py中定义模型类,要求继承自models.Model
- 把应用加入settings.py文件的installed_app项
- 生成迁移文件
- 执行迁移生成表
- 使用模型类进行crud操作
数据库生成模型类
- 在django入门的时候,使用的是写模型类,连接mysql,迁移生成数据表。
- 也可以用已有的数据表生成模型类。
python manage.py inspectdb > booktest/models.py
一、定义模型
- 模型类中定义属性,生成表字段。
- django根据属性的类型确定以下信息:
- 当前选择的数据库支持字段的类型
- 渲染管理表单时使用的默认html控件
- 在管理站点最低限度的验证
- django会为表增加自动增长的主键列,每个模型只能有一个主键列,如果使用选项设置某属性为主键列后,则django不会再生成默认的主键列
- 属性命名限制
-
- 不能是python的保留关键字
- 由于django的查询方式,不允许使用连续的下划线
定义属性:
- 定义属性时,需要字段类型
- 字段类型被定义在django.db.models.fields目录下,为了方便使用,被导入到django.db.models中
- 使用方式
- 导入from django.db import models
- 通过models.Field创建字段类型的对象,赋值给属性
- 对于重要数据都做逻辑删除,不做物理删除,实现方法是定义isDelete属性,类型为BooleanField,默认值为False
字段类型:
- AutoField:一个根据实际ID自动增长的IntegerField,通常不指定,如果不指定,一个主键字段将自动添加到模型中。
- BooleanField:true/false 字段,此字段的默认表单控制是CheckboxInput
- NullBooleanField:支持null、true、false三种值
- CharField(max_length=字符长度):字符串,默认的表单样式是 TextInput
- TextField:大文本字段,一般超过4000使用,默认的表单控件是Textarea
- IntegerField:整数
- DecimalField(max_digits=None, decimal_places=None):使用python的Decimal实例表示的十进制浮点数
- DecimalField.max_digits:位数总数
- DecimalField.decimal_places:小数点后的数字位数
- FloatField:用Python的float实例来表示的浮点数
- DateField[auto_now=False, auto_now_add=False]):使用Python的datetime.date实例表示的日期
- 参数DateField.auto_now:每次保存对象时,自动设置该字段为当前时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为false
- 参数DateField.auto_now_add:当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为false
- 该字段默认对应的表单控件是一个TextInput. 在管理员站点添加了一个JavaScript写的日历控件,和一个“Today"的快捷按钮,包含了一个额外的invalid_date错误消息键
- auto_now_add, auto_now, and default 这些设置是相互排斥的,他们之间的任何组合将会发生错误的结果
- TimeField:使用Python的datetime.time实例表示的时间,参数同DateField
- DateTimeField:使用Python的datetime.datetime实例表示的日期和时间,参数同DateField
- FileField:一个上传文件的字段
- ImageField:继承了FileField的所有属性和方法,但对上传的对象进行校验,确保它是个有效的image
models.DecimalField(max_digits=None, decimal_places=None[, **options])
max_digits:数字允许的最大位数
decimal_places:小数的最大位数
字段选项
- 通过字段选项,可以实现对字段的约束
- 在字段对象时通过关键字参数指定
- null:如果为True,Django 将空值以NULL 存储到数据库中,默认值是 False
- blank:如果为True,则该字段允许为空白,默认值是 False
- 对比:null是数据库范畴的概念,blank是表单验证证范畴的
- db_column:字段的名称,如果未指定,则使用属性的名称
- db_index:若值为 True, 则在表中会为此字段创建索引
- default:默认值
- primary_key:若为 True, 则该字段会成为模型的主键字段
- unique:如果为 True, 这个字段在表中必须有唯一值
关系
- 关系的类型包括
- ForeignKey:一对多,将字段定义在多的端中
- ManyToManyField:多对多,将字段定义在两端中
- OneToOneField:一对一,将字段定义在任意一端中
- 可以维护递归的关联关系,使用'self'指定,详见“自关联”
- 用一访问多:对象.模型类小写_set
department.staffinfo_set # 给出一个部门条件,查询部门下面所有的员工。
- 用一访问一:对象.模型类小写
staffinfo.departmentinfo # 查询员工属于哪个部门
访问id:对象.属性_id
staffinfo.department_id
元选项
- 默认表名称:
<app_name>_<model_name>
- 在模型类中定义类Meta,用于设置元信息。
- ordering:对象的默认排序字段,获取对象的列表时使用,接收属性构成的列表。
class DepartmenInfo(models.Model):
...
class Meta():
# 默认表的名字会把项目的名称加上即:commpany_departmentInfo,此处自定义表的名称。
db_table = 'department'
ordering = ['id']
- 字符串前加-表示倒序,不加-表示正序
class staffInfo(models.Model):
...
class Meta():
ordering = ['-id']
注意:排序会增加数据库的开销
二、模型成员
类的属性
- objects:是Manager类型的对象,用于与数据库进行交互
- 当定义模型类时没有指定管理器,则Django会为模型类提供一个名为objects的管理器
- 支持明确指定模型类的管理器
class DepartmentInfo(models.Model):
...
department = models.Manager()
管理器Manager
- 管理器是Django的模型进行数据库的查询操作的接口,Django应用的每个模型都拥有至少一个管理器
- 自定义管理器类主要用于两种情况
- 情况一:向管理器类中添加额外的方法:见下面“创建对象”中的方式二
- 情况二:修改管理器返回的原始查询集:重写get_queryset()方法
class DepartmentManager(models.Manager):
def get_queryset(self):
return super(DepartmentManager, self).get_queryset().filter(isDelete=False)
class StaffInfo(models.Model):
...
books = StaffInfoManager()
自定义管理器
# 自定义一个管理器
class BookInfoManager(models.Manager):
# 重写get_queryset方法,manager中有此方法
def get_queryset(self):
return super(BookInfoManager, self).get_queryset().filter(isDelet = False) # 过滤isDelete字段=False的
'''
models中定义模型类
作用1:创建表
作用2:以后对表进行操作。可以映射到数据库中进行insert select update等操作。
一个表定义一个类
'''
# 书表
class BookInfo(models.Model):
btitle = models.CharField(max_length=20)
bpub_date = models.DateTimeField(db_column='pub_date') # 自定义列名
bread = models.IntegerField(default=0)
bcommet = models.IntegerField(null=False)
isDelet = models.BooleanField(default=False)
class Meta:
db_table = 'bookinfo'
books1 = models.Manager() # 使用默认管理器
books2 = BookInfoManager() # 使用自定义管理器
"""
def __str__(self):
return self.btitle.encode('utf-8')
"""
# 英雄表
class HeroInfo(models.Model):
hname = models.CharField(max_length=10)
hgender = models.BooleanField()
hcontent = models.CharField(max_length = 10000)
# 指定外键
hbook = models.ForeignKey(BookInfo)
def __str__(self):
return self.hname.encode('utf-8')
测试,终端执行:python manage.py shell
In [1]: from booktest.models import BookInfo In [2]: BookInfo.books2.all() Out[2]: <QuerySet [<BookInfo: BookInfo object>, <BookInfo: BookInfo object>]> In [3]: BookInfo.books1.all() Out[3]: <QuerySet [<BookInfo: BookInfo object>, <BookInfo: BookInfo object>, <BookInfo: BookInfo object>]>
使用默认管理器查出来bookinfo表中的所有内容,使用自定义管理器查出来bookinfo表中isDelet=False的内容。
实例的方法
- str (self):重写object方法,此方法在将对象转换成字符串时会被调用
- save():将模型对象保存到数据表中
- delete():将模型对象从数据表中删除
django入门补充:自定义admin管理站点。
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
from django.contrib import admin
from models import *
# 添加额外信息
class HeroInfoInline(admin.TabularInline):
model = HeroInfo
extra = 2
class BookInfoAdmin(admin.ModelAdmin):
list_display = ["id","btitle","bpub_date","bread"]
# 侧边栏显示
list_filter = ["btitle"]
# 搜索功能
search_fields = ["btitle"]
# 列表页显示条数
list_per_page = 10
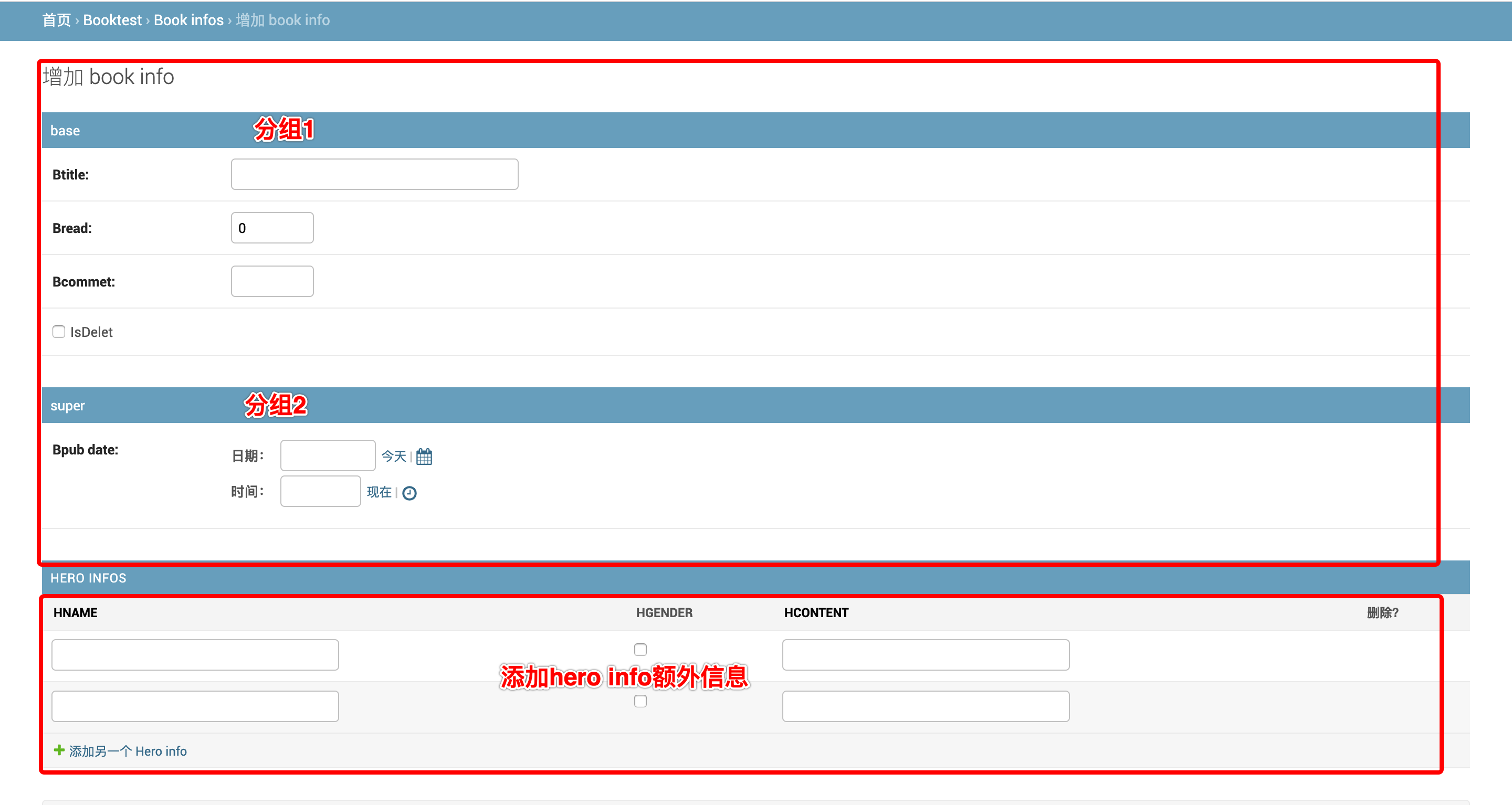
# 修改页分组,
fieldsets = [
('base',{'fields':['btitle','bread','bcommet','isDelet']}),
('super',{'fields':['bpub_date']})
]
inlines = [HeroInfoInline]
admin.site.register(BookInfo,BookInfoAdmin)
admin.site.register(HeroInfo)
添加额外信息:添加bookinfo的时候额外增加heroinfo的内容。
三、模型查询
简介
- 查询集表示从数据库中获取的对象集合
- 查询集可以含有零个、一个或多个过滤器
- 过滤器基于所给的参数限制查询的结果
- 从Sql的角度,查询集和select语句等价,过滤器像where和limit子句
- 接下来主要讨论如下知识点
- 查询集
- 字段查询:比较运算符,F对象,Q对象
查询集
- 在管理器上调用过滤器方法会返回查询集
- 查询集经过过滤器筛选后返回新的查询集,因此可以写成链式过滤
- 惰性执行:创建查询集不会带来任何数据库的访问,直到调用数据时,才会访问数据库
- 何时对查询集求值:迭代,序列化,与if合用
- 返回查询集的方法,称为过滤器
- all()
- filter()
- exclude()
- order_by()
- values():一个对象构成一个字典,然后构成一个列表返回
返回单个值的方法
- get():返回单个满足条件的对象
- 如果未找到会引发"模型类.DoesNotExist"异常
- 如果多条被返回,会引发"模型类.MultipleObjectsReturned"异常
- count():返回当前查询的总条数
- first():返回第一个对象
- last():返回最后一个对象
- exists():判断查询集中是否有数据,如果有则返回True
举例:
- 查询
from bookinfo.models import *
BookInfo.books1.values()
In [8]: BookInfo.books1.all() Out[8]: <QuerySet [<BookInfo: BookInfo object>, <BookInfo: BookInfo object>, <BookInfo: BookInfo object>, <BookInfo: BookInfo object>, <BookInfo: BookInfo object>]> In [11]: BookInfo.books1.filter(id=1) Out[11]: <QuerySet [<BookInfo: BookInfo object>]> In [14]: BookInfo.books1.exclude(id=1) Out[14]: <QuerySet [<BookInfo: BookInfo object>, <BookInfo: BookInfo object>, <BookInfo: BookInfo object>, <BookInfo: BookInfo object>]>
- 插入
from datetime import datetime
b =BookInfo.create('test',datetime(1990,1,1))
b.save()
限制查询集
- 查询集返回列表,可以使用下标的方式进行限制,等同于sql中的limit和offset子句
- 注意:不支持负数索引
- 使用下标后返回一个新的查询集,不会立即执行查询
- 如果获取一个对象,直接使用[0],等同于[0:1].get(),但是如果没有数据,[0]引发IndexError异常,[0:1].get()引发DoesNotExist异常
字段查询
- 实现where子名,作为方法filter()、exclude()、get()的参数
- 语法:属性名称__比较运算符=值
- 表示两个下划线,左侧是属性名称,右侧是比较类型
- 对于外键,使用“属性名_id”表示外键的原始值
- 转义:like语句中使用了%与,匹配数据中的%与,在过滤器中直接写,例如:filter(title__contains="%")=>where title like '%\%%',表示查找标题中包含%的
比较运算符
- exact:表示判等,大小写敏感;如果没有写“ 比较运算符”,表示判等
filter(isDelete=False)
- contains:是否包含,大小写敏感
exclude(btitle__contains='传')
- startswith、endswith:以value开头或结尾,大小写敏感
exclude(btitle__endswith='传')
- isnull、isnotnull:是否为null
filter(btitle__isnull=False)
- 在前面加个i表示不区分大小写,如iexact、icontains、istarswith、iendswith
- in:是否包含在范围内
filter(pk__in=[1, 2, 3, 4, 5])
- gt、gte、lt、lte:大于、大于等于、小于、小于等于
filter(id__gt=3)
- year、month、day、week_day、hour、minute、second:对日期间类型的属性进行运算
filter(bpub_date__year=1980)
filter(bpub_date__gt=date(1980, 12, 31))
- 跨关联关系的查询:处理join查询
- 语法:模型类名 <属性名> <比较>
- 注:可以没有__<比较>部分,表示等于,结果同inner join
- 可返向使用,即在关联的两个模型中都可以使用
filter(heroinfo_ _hcontent_ _contains='八')
- 查询的快捷方式:pk,pk表示primary key,默认的主键是id
filter(pk__lt=6)
聚合函数
- 使用aggregate()函数返回聚合函数的值
- 函数:Avg,Count,Max,Min,Sum
from django.db.models import Max
maxDate = list.aggregate(Max('bpub_date'))
- count的一般用法:
count = list.count()
F对象
- 可以使用模型的字段A与字段B进行比较,如果A写在了等号的左边,则B出现在等号的右边,需要通过F对象构造
list.filter(bread__gte=F('bcommet'))
- django支持对F()对象使用算数运算
list.filter(bread__gte=F('bcommet') * 2)
- F()对象中还可以写作“模型类__列名”进行关联查询
list.filter(isDelete=F('heroinfo__isDelete'))
- 对于date/time字段,可与timedelta()进行运算
list.filter(bpub_date__lt=F('bpub_date') + timedelta(days=1))
Q对象
- 过滤器的方法中关键字参数查询,会合并为And进行
- 需要进行or查询,使用Q()对象
- Q对象(django.db.models.Q)用于封装一组关键字参数,这些关键字参数与“比较运算符”中的相同
from django.db.models import Q
list.filter(Q(pk_ _lt=6))
- Q对象可以使用&(and)、|(or)操作符组合起来
- 当操作符应用在两个Q对象时,会产生一个新的Q对象
list.filter(pk_ _lt=6).filter(bcommet_ _gt=10)
list.filter(Q(pk_ _lt=6) | Q(bcommet_ _gt=10))
- 使用~(not)操作符在Q对象前表示取反
list.filter(~Q(pk__lt=6))
- 可以使用&|~结合括号进行分组,构造做生意复杂的Q对象
- 过滤器函数可以传递一个或多个Q对象作为位置参数,如果有多个Q对象,这些参数的逻辑为and
- 过滤器函数可以混合使用Q对象和关键字参数,所有参数都将and在一起,Q对象必须位于关键字参数的前面
四、自连接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号