Netty源码—五、内存分配概述
Netty中的内存管理应该是借鉴了FreeBSD内存管理的思想——jemalloc。Netty内存分配过程中总体遵循以下规则:
- 优先从缓存中分配
- 如果缓存中没有的话,从内存池看看有没有剩余可用的
- 如果已申请的没有的话,再真正申请内存
- 分段管理,每个内存大小范围使用不同的分配策略
我们先总体上看下Netty内存分配的策略,然后再结合对应的数据结构来看看每种策略的具体实现。
总体分配策略
netty根据需要分配内存的大小使用不同的分配策略,主要分为以下几种情况(pageSize默认是8K, chunkSize默认是16m):
tiny: allocateSize<512,allocateSubpage
small: pageSize>=allocateSize >=512,allocateSubpage
normal: chunkSize >= allocateSize > pageSize ,allocateRun
huge: allocateSize > chunkSize
内存分配的调用堆栈
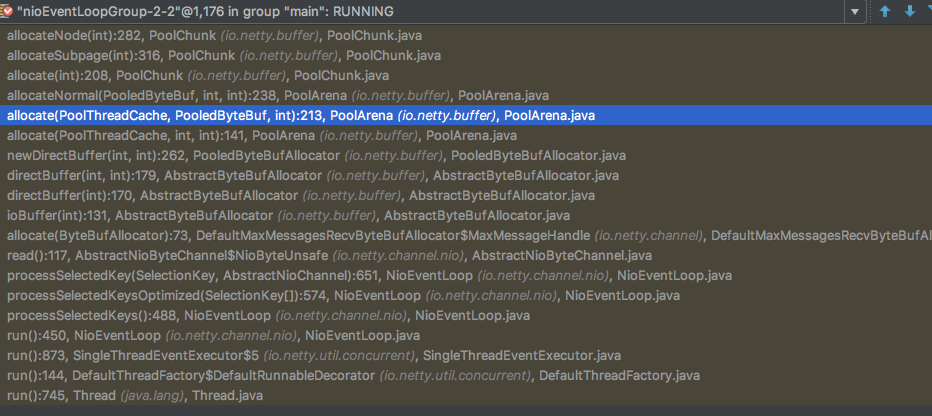
结合上面内存分配的调用堆栈看看内存分配的主要过程:
- new一个ByteBuf,如果是direct则new:PooledUnsafeDirectByteBuf
- 从缓存中查找,没有可用的缓存进行下一步
- 从内存池中查找可用的内存,查找的方式如上所述(tiny、small、normal)
- 如果找不到则重新申请内存,并将申请到的内存放入内存池
- 使用申请到的内存初始化ByteBuf
基本数据结构
PoolSubpage:一个内存页,默认是8k
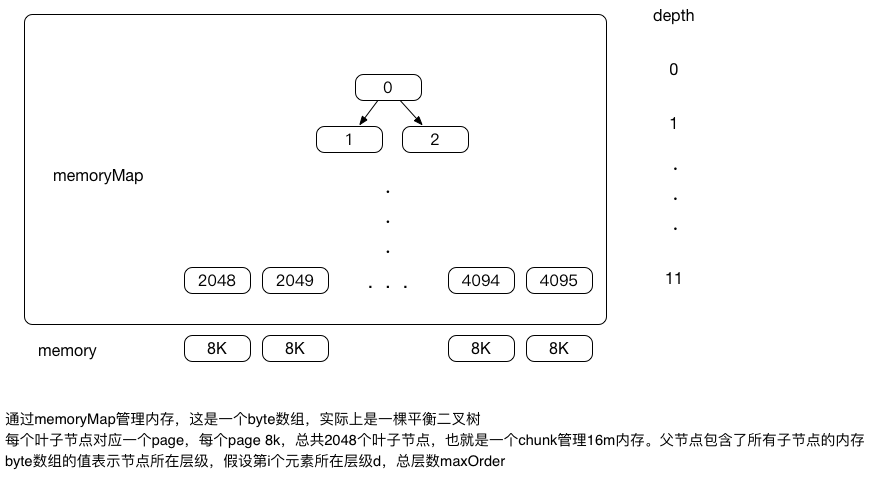
PoolChunk:有多个PoolSubpage组成,默认包含2048个subpage,即默认大小是16m
chunk内部包含一个byte数组memoryMap,默认包含4096个元素,memoryMap实际上是一棵完全二叉树,共有12层,也就是maxOrder默认是11(从0开始),所以这棵树总共有2048个叶子结点,每个叶子节点对应一个subpage,树中非叶子节点的内存大小由左子节点的内存大小加上右子节点的内存大小,memoryMap数组中存储的值是byte类型,其实就是该树节点在树中的深度(深度从0开始)。树的基本结构如下图:
PoolSubpage表示一个内存页大小,还可以继续划分成更小的内存块,以便能充分利用每一个page。
所以在分配内存的时候,如果分配的内存小于pageSIze(默认8k)大小,则会从PoolSubpage中分配;
如果需要分配的内存大于pageSize且小于chunkSize(默认16m)的内存从chunk中分配
如果大于chunkSize的内存则直接分配,Netty不做进一步管理。
normal内存申请
先看下分配内存的入口方法allocate
// 这个方法进行具体申请内存的操作
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
final int normCapacity = normalizeCapacity(reqCapacity);
// 小于pageSize(默认是8K)
if (isTinyOrSmall(normCapacity)) { // capacity < pageSize
int tableIdx;
PoolSubpage<T>[] table;
boolean tiny = isTiny(normCapacity);
if (tiny) { // < 512
// 使用缓存
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
tableIdx = tinyIdx(normCapacity);
table = tinySubpagePools;
} else {
// 512-8K
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
final PoolSubpage<T> head = table[tableIdx];
/**
* Synchronize on the head. This is needed as {@link PoolChunk#allocateSubpage(int)} and
* {@link PoolChunk#free(long)} may modify the doubly linked list as well.
*/
synchronized (head) {
final PoolSubpage<T> s = head.next;
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
// 这里为什么一定可以找到可用的内存块(handle>=0)呢?
// 因为在io.netty.buffer.PoolSubpage#allocate的时候,如果可用内存块为0了会将该page从链表中remove,所以保证了head.next一定有可用的内存
long handle = s.allocate();
assert handle >= 0;
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
if (tiny) {
allocationsTiny.increment();
} else {
allocationsSmall.increment();
}
return;
}
}
allocateNormal(buf, reqCapacity, normCapacity);
return;
}
if (normCapacity <= chunkSize) {
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
allocateNormal(buf, reqCapacity, normCapacity);
} else {
// Huge allocations are never served via the cache so just call allocateHuge
allocateHuge(buf, reqCapacity);
}
}
可以看到除了huge内存之外,其他内存申请都可能会调用到allocateNormal,我们先来看下normal内存的申请。
上文一直提到tiny、small、normal、huge,这里我们看下这些内存划分的标准是什么
// normCapacity < 512
static boolean isTiny(int normCapacity) {
// 小于512的是tiny
return (normCapacity & 0xFFFFFE00) == 0;
}
// capacity < pageSize
// subpageOverflowMask = ~(pageSize - 1);
// 所以小于8k的是small或者tiny,结合tiny的范围,small的范围就是:512-8192
boolean isTinyOrSmall(int normCapacity) {
return (normCapacity & subpageOverflowMask) == 0;
}
大于8k但是小于chunkSize(16m)的使用allocateNormal来申请内存,所以我们暂且把这个范围的称为normal
大于chunkSize使用allocateHuge来申请内存,我们暂且把这个范围的称为huge。
还需要一个铺垫,申请内存大小的规整。Netty并不是申请多少就分配多少,会根据一定的规则分配大于等于需要内存的规整过的值。上面在allocate方法刚开始就会先将reqCapacity规范化为normCapacity,使用下面的方法,规范的过程也是进行了分类,不同的内存大小类型规范化的方式不一样
// 规范化申请的内存大小为2的指数次
// io.netty.buffer.PoolArena#normalizeCapacity
int normalizeCapacity(int reqCapacity) {
if (reqCapacity < 0) {
throw new IllegalArgumentException("capacity: " + reqCapacity + " (expected: 0+)");
}
if (reqCapacity >= chunkSize) {
return reqCapacity;
}
if (!isTiny(reqCapacity)) { // >= 512
// Doubled
// 如果申请的内存大于512则规范化为大于reqCapacity的最近的2的指数次的值
int normalizedCapacity = reqCapacity;
// 当normalizedCapacity本身就是2的指数次的时候,取其本身
// 这个时候防止下面的算法再向后查找,先将normalizedCapacity-1
normalizedCapacity --;
normalizedCapacity |= normalizedCapacity >>> 1;
normalizedCapacity |= normalizedCapacity >>> 2;
normalizedCapacity |= normalizedCapacity >>> 4;
normalizedCapacity |= normalizedCapacity >>> 8;
normalizedCapacity |= normalizedCapacity >>> 16;
normalizedCapacity ++;
// 如果上面的计算结果溢出了(如果reqCapacity是Integer.MAX_VALUE),则去掉最高位
if (normalizedCapacity < 0) {
normalizedCapacity >>>= 1;
}
return normalizedCapacity;
}
// 下面之所以是16的倍数是因为用来管理tiny内存tinySubpagePools数组的大小刚好是512>>>4,32个元素
// 每个元素PoolSubpage本身会构成链表,也就是说每个元素(PoolSubpage)对应的链表内每个元素的内存块大小(elemSize)是相同的,数组内每个链表的elemSize依次是:
// 16,32,48......480,496,512
// Quantum-spaced
// 刚好是16的倍数(这个时候reqCapacity<512)
if ((reqCapacity & 15) == 0) {
return reqCapacity;
}
// 找到距离reqCapacity最近的下一个16的倍数
return (reqCapacity & ~15) + 16;
}
这里解释下上面if (!isTiny(reqCapacity))里面的位运算,由于要寻找的数是2的指数次,所以二进制表示除了最高位是1,后面的位都应该是0,假设寻找的是x // x-1的二进制所有位都是1,所以变成了寻找比x少一位的二进制全1的数
normalizedCapacity二进制表示的第一位肯定是1,右移1位之后,第二位变为了1,两者进行逻辑或的时候,前两位一定是1同理
- 继续右移2位之后,前4位肯定是1
- 继续右移4位之后,前8位肯定是1
- 继续右移8位之后,前16位肯定是1
- 继续右移16位之后,前32位一定是1
这样就找到了全是1的数,然后再加上1就是2的指数次。
总结上面的代码逻辑,规范化的过程是:
- 如果是huge,大于chunkSize直接返回reqCapacity
- 如果是small或者normal,大于512,则规范化为大于reqCapacity的最近的2的指数次的值
- 如果是tiny,小于512,则规范为16的倍数
上面这个规范化的原因和每类内存申请的数据结构有密切的关系,我们这里先只关心normal类型的被规范化为2的指数次。
下面接着看normal内存的申请
// io.netty.buffer.PoolArena#allocateNormal
private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
// 先从内存池中获取需要的内存
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
return;
}
// 如果从现有内存池中没有找到可用的内存,则重新申请一个chunk
// Add a new chunk.
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
long handle = c.allocate(normCapacity);
assert handle > 0;
// 用申请的内存初始化buffer
c.initBuf(buf, handle, reqCapacity);
// 刚刚初始化的chunk放在init链表中
qInit.add(c);
}
先看下上面用到的几个数据结构
// 每个链表存放的是已经被分配过的chunk,不同使用率的chunk被存放在不同的链表中
// 初始情况链表都是空的,刚开始从init开始,依次向后寻找,找到合适范围的list,然后add
// qinit - q000 - q025 - q050 - q075 - q100
// 注意qinit和q000之间是单向,也就是说qinit的chunk可以move到q000,但是q000的chunk不能再向前move了
// 使用率在50%-100%
private final PoolChunkList<T> q050;
// 使用率在25%-75%
private final PoolChunkList<T> q025;
// 使用率在1%-50%
private final PoolChunkList<T> q000;
// 使用率在0%-25%
private final PoolChunkList<T> qInit;
// 使用率在75%-100%
private final PoolChunkList<T> q075;
// 使用率100%
private final PoolChunkList<T> q100;
allocateNormal一开始先从已经申请过的chunk中查找有无可用内存,上面几个链表查找的顺序是q050、q025、q000、qinit、q075,关于这个顺序问题可以参考网上的一篇文章。还有一个问题,既然有了q000,为什么需要qinit?前面这篇文章也有介绍,这结合我的理解再说下:
首先qinit的内存使用率是0-25%,q000的内存使用率是1-50%,q000没有使用率是0的chunk;其次在构成链表的时候qinit.next = q000,但是q000.prev是null,如果是一个chunk的使用率变为0以后,调用io.netty.buffer.PoolChunkList#free方法来释放,由于当前使用率是0,而q000的最小使用率是1%,所以会执行下面代码的remove和move,将这个chunk移除出链表等待被回收。
// io.netty.buffer.PoolChunkList#free
boolean free(PoolChunk<T> chunk, long handle) {
chunk.free(handle);
if (chunk.usage() < minUsage) {
// 如果小于当前链表的最小利用率,将chunk从链表中移除
remove(chunk);
// Move the PoolChunk down the PoolChunkList linked-list.
// 将chunk添加到当前链表的上一个链表,,如果是当前链表是q000,没有上一个,也就是这个chunk不能再被使用,等待被GC护回收内存
return move0(chunk);
}
return true;
}
基本数据结构说了,接下来看看具体的逻辑。allocateNormal一开始是调用的PoolChunkList#allocate
// io.netty.buffer.PoolChunkList#allocate
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
if (head == null || normCapacity > maxCapacity) {
// Either this PoolChunkList is empty or the requested capacity is larger then the capacity which can
// be handled by the PoolChunks that are contained in this PoolChunkList.
// 当前链表为空或者申请内存的大小大于当前链表的利用率直接返回false
return false;
}
// 从链表头开始依次查找可用的内存
for (PoolChunk<T> cur = head;;) {
// 针对每个chunk申请内存,如果返回handle小于0表示没有符合条件的内存,继续查找下一个
long handle = cur.allocate(normCapacity);
if (handle < 0) {
cur = cur.next;
if (cur == null) {
return false;
}
} else {
// 如果找到可用的内存,用来初始化buffer
cur.initBuf(buf, handle, reqCapacity);
if (cur.usage() >= maxUsage) {
// 如果当前chunk的利用率大于当前链表的最大利用率需要移动到下一个链表
remove(cur);
nextList.add(cur);
}
return true;
}
}
}
接下来看看最终chunk是怎么分配内存的,下面这个方法其实就是计算出chunk中符合条件的内存的memoryMap数组中的index
// io.netty.buffer.PoolChunk#allocate
long allocate(int normCapacity) {
if ((normCapacity & subpageOverflowMask) != 0) { // >= pageSize
// 大于等于pageSize,8k
return allocateRun(normCapacity);
} else {
// 小于pageSize
return allocateSubpage(normCapacity);
}
}
这个里面就根据申请内存的大小使用不同的分配策略,这里先看下大于pageSize的内存分配
大于pageSize的内存申请
// io.netty.buffer.PoolChunk#allocateRun
private long allocateRun(int normCapacity) {
// 计算出所申请的内存位于树的哪一层
// Integer.numberOfLeadingZeros(pageSize)表示pageSize二进制表示的时候,前面有多个0,也就是第一个1出现的位置
// pageShift = Integer.SIZE - 1 - Integer.numberOfLeadingZeros(pageSize) = 13
// pageShift就是pageSize的最高位相对于右边的位偏移
int d = maxOrder - (log2(normCapacity) - pageShifts);
// 在d层找到可用的内存并返回对应的memoryMap数组元素的index
int id = allocateNode(d);
if (id < 0) {
// 如果小于0说明没有找到
return id;
}
// 如果找到了则更新当前chunk可用内存大小
freeBytes -= runLength(id);
return id;
}
上面代码中d的含义:要申请内存位于memoryMap数的第几层(下面是第maxOrder层)
maxOrder:表示memoryMap数总共有maxOrder层,从上到下依次是0,1,2,3,4,5,6,7,8,9,10,11,也即是默认12层
log2(normCapacity):要申请内存大小二进制最高位相对于右边的偏移
pageShift:pageSize二进制最高位相对于右边的偏移
(log2(normCapacity) - pageShifts):要申请内存的大小在树中的层数与最底层的层数(最底层的内存大小是pageSIze,8K)差,memoryMap树中,两层之间表示的内存是2倍关系,比如第10层是第11层的2倍,第11层是8k,那么第10层就是16k
maxOrder - (log2(normCapacity) - pageShifts):表示要申请的内存大小位于数的哪一层
举个例子,假如申请的内存是32k,log2(normalCapacity) = 15,32k距离8k中间隔了15-13=2层,所以要申请的内存位于第11-2=9层,验证一下,叶子节点内存大小是一个page8k,父节点16k,父节点的父节点是32k,所以申请的内存应该位于上一层的上一层,也就是第9层
那么怎么从树中找到合适的内存呢,下面这个方法就是在指定的d层找到符合条件的内存,由于每个节点的值本来是该节点所在的深度depth,如果该节点的内存(包括子节点)已经被分配过,则会被标记为不可用,所以只要从根节点开始,依次向下查找,如果当前节点没有被分配则找左子节点,如果该节点已经被分配了则找当前节点的兄弟节点,直到找到第d层依然没有可用内存的时候,
/**
* Algorithm to allocate an index in memoryMap when we query for a free node
* at depth d
*
* @param d depth 树的深度
* @return index in memoryMap
*/
// 在d层查找一个可用的节点,根据所在层数来查找盖层可用的内存的memoryMap的index
private int allocateNode(int d) {
int id = 1;
int initial = - (1 << d); // has last d bits = 0 and rest all = 1
byte val = value(id);
if (val > d) { // unusable
return -1;
}
// id < 2^d 的时候 id & initial = 0,也就是说d层所有的id&inital都是大于0的
// 所以这两个条件就限定了寻找的节点在d层,并且可用free
// 这里就是查找第d层的可用节点,为什么不直接从d层开始查找呢?
while (val < d || (id & initial) == 0) { // id & initial == 1 << d for all ids at depth d, for < d it is 0
id <<= 1;
val = value(id);
// 如果该节点的子节点已经被分配过了,那么找兄弟节点
if (val > d) {
// id = id + 1
id ^= 1;
val = value(id);
}
}
byte value = value(id);
assert value == d && (id & initial) == 1 << d : String.format("val = %d, id & initial = %d, d = %d",
value, id & initial, d);
// 将当前内存标记为不可用,也就是将该节点的数组值更新maxOrder+1
setValue(id, unusable); // mark as unusable
updateParentsAlloc(id);
return id;
}
前面说过chunk的数据结构memoryMap,申请的内存的时候也是和这个数据结构密切相关,其实就是找到这棵树中可用内存的节点的index,然后更新memoryMap中内存的使用情况。
再看一个问题:为什么不直接从d层开始查找呢,而是从根节点开始?
为了更快的查找。如果直接从d层开始查找,需要的时间是最坏是2^d(要找的节点在最右侧),最好是1(要找的节点在最左侧),因为可能存在前面的节点已经被分配的情况。使用从上往下查找的时候,如果发现子节点被分配过了,就直接查找兄弟节点,时间是log2d
上面是大于等于pageSize的内存申请,接下来看看另外一种小于pageSize的内存申请
小于pageSize的内存申请
// io.netty.buffer.PoolChunk#allocateSubpage
private long allocateSubpage(int normCapacity) {
// Obtain the head of the PoolSubPage pool that is owned by the PoolArena and synchronize on it.
// This is need as we may add it back and so alter the linked-list structure.
// 从tinySubpagePools或者smallSubpagePools中查找
PoolSubpage<T> head = arena.findSubpagePoolHead(normCapacity);
synchronized (head) {
// 由于是小于pageSize的,所以直接在最后一层,也就是树的最底层查找,因为树的最底层的节点的内存大小事pageSize
int d = maxOrder; // subpages are only be allocated from pages i.e., leaves
int id = allocateNode(d);
if (id < 0) {
return id;
}
final PoolSubpage<T>[] subpages = this.subpages;
final int pageSize = this.pageSize;
// 更新当前chunk的剩余内存大小,本次申请的是一个page,所以减去pageSize
freeBytes -= pageSize;
// memoryIdx - 2048就是page的index
int subpageIdx = subpageIdx(id);
PoolSubpage<T> subpage = subpages[subpageIdx];
if (subpage == null) {
// 该page尚未初始化过,第一次初始化
// 初始化的过程会将subpage放到链表头
subpage = new PoolSubpage<T>(head, this, id, runOffset(id), pageSize, normCapacity);
subpages[subpageIdx] = subpage;
} else {
// 重新init
subpage.init(head, normCapacity);
}
// 返回的是申请到内存的handle,包含了bitmap和memoryMapIdx信息
return subpage.allocate();
}
}
/**
* Returns the bitmap index of the subpage allocation.
* 返回的是申请到的可用内存块在bitmap数组中对应bit的index
*/
long allocate() {
if (elemSize == 0) {
return toHandle(0);
}
if (numAvail == 0 || !doNotDestroy) {
return -1;
}
// 获取下一个可用内存块的位置
final int bitmapIdx = getNextAvail();
// 右移6位,得到的是该bit对应bitmap数组中的下标
int q = bitmapIdx >>> 6;
// 逻辑与63,得到的是该bit在long型数据中的第几个bit
int r = bitmapIdx & 63;
assert (bitmap[q] >>> r & 1) == 0;
// 将该bit置为已使用
bitmap[q] |= 1L << r;
// 将可用的内存块总数减1
if (-- numAvail == 0) {
removeFromPool();
}
return toHandle(bitmapIdx);
}
private long toHandle(int bitmapIdx) {
// 2^62,高位是bitmapIdx,低位是memoryMapIdx
return 0x4000000000000000L | (long) bitmapIdx << 32 | memoryMapIdx;
}
private int getNextAvail() {
int nextAvail = this.nextAvail;
if (nextAvail >= 0) {
this.nextAvail = -1;
return nextAvail;
}
return findNextAvail();
}
private int findNextAvail() {
final long[] bitmap = this.bitmap;
final int bitmapLength = this.bitmapLength;
// 从实际使用到的标志位bitmapLength中查找
for (int i = 0; i < bitmapLength; i ++) {
long bits = bitmap[i];
// bits不全为1,表示有空余
if (~bits != 0) {
return findNextAvail0(i, bits);
}
}
return -1;
}
private int findNextAvail0(int i, long bits) {
final int maxNumElems = this.maxNumElems;
// i为数组的下标,表示第i个long数
final int baseVal = i << 6;
// 判断long的每一位是否时可用的
for (int j = 0; j < 64; j ++) {
if ((bits & 1) == 0) {
// 找到可用的后,记录可用内存块对应于bitmap中的index,j为该long数据的第j位
int val = baseVal | j;
if (val < maxNumElems) {
return val;
} else {
break;
}
}
// 查找下一位
bits >>>= 1;
}
return -1;
}
首先是从内存池中获取内存,PoolArena维护了以下两个数组,arena.findSubpagePoolHead就是从以下两个数组中查找可用的chunk的head,接下来就是从找到的chunk中查找可用内存,类似上面大于8k申请的查找方式,实际上是调用的同一个方法:io.netty.buffer.PoolChunk#allocateNode
// small内存池,数组大小是log2(pageSize>>>10),默认就是4,所以数组index的计算方式也是这样log2(reqCapacity>>>10)
// 每个元素保存的是一个PoolSubpage链表,一个PoolSubpage链表里面的subpage都是相同的块大小(8k分成小童的份数)
// 每个元素的elemSize依次是:1k,2k,4k,8k
private final PoolSubpage<T>[] smallSubpagePools
// tiny内存池,数组大小是512 >>> 4,也就是32,数组index的计算方式也就是一样:reqCapacity除以16
// 每个元素的elemSize依次是:16,32,48......480,496,512,每个PoolSubpage又是一个链表,该链表上的elemSize相同
private final PoolSubpage<T>[] tinySubpagePools;
这里也可以看出之前将申请内存的大小规范化的目的了,也能理解为什么tiny规范化为16的倍数,而small规范化为2的指数次。因为
small的内存范围是:8192 > size > 512,大于512并且是2的指数次,正好是1k、2k、4k、8k
tiny的内存范围是:size <= 512,16的倍数正好是16、32、48...
init buffer
上面一系列的方法都是计算出可用内存在memoryMap数组中的index,接下来看看怎么使用这个index初始化buffer
// io.netty.buffer.PoolChunk#initBuf
// 找到chunk信息后调用这个方法初始化buf,用分配好的内存初始化buf
void initBuf(PooledByteBuf<T> buf, long handle, int reqCapacity) {
int memoryMapIdx = memoryMapIdx(handle);
int bitmapIdx = bitmapIdx(handle);
// 如果分配的内存大于一个page,不需要使用bitmapIdx,这个时候bitmapIdx为0
if (bitmapIdx == 0) {
byte val = value(memoryMapIdx);
assert val == unusable : String.valueOf(val);
buf.init(this, handle, runOffset(memoryMapIdx), reqCapacity, runLength(memoryMapIdx),
arena.parent.threadCache());
} else {
initBufWithSubpage(buf, handle, bitmapIdx, reqCapacity);
}
}
// io.netty.buffer.PoolChunk#initBufWithSubpage(io.netty.buffer.PooledByteBuf<T>, long, int, int)
// 使用PoolSubpage初始化buf
// handle构成:2^62 | long(bitmapIdx) << 32 | memoryMapIdx
private void initBufWithSubpage(PooledByteBuf<T> buf, long handle, int bitmapIdx, int reqCapacity) {
assert bitmapIdx != 0;
// memoryMapIdx方法是直接将handler强转为int,也就是截去了高32位,低32位就是memoryMapIdx
int memoryMapIdx = memoryMapIdx(handle);
PoolSubpage<T> subpage = subpages[subpageIdx(memoryMapIdx)];
assert subpage.doNotDestroy;
assert reqCapacity <= subpage.elemSize;
// 0x3FFFFFFF是2^31-1,此刻的bitmapIdx是2^30 | bitmapIdx
// 所以bitmapIdx & 0x3FFFFFFF得到的就是原始的bitmapIdx
buf.init(
this, handle,
runOffset(memoryMapIdx) + (bitmapIdx & 0x3FFFFFFF) * subpage.elemSize, reqCapacity, subpage.elemSize,
arena.parent.threadCache());
}
// 根据memoryIdx获取对应的subpage的序号,memoryIdx一定是位于2048-4097之间才能使用此方法
private int subpageIdx(int memoryMapIdx) {
// memoryIdx位于2048-4097之间,和2048即2^11进行异或运算,相当于memoryIdx-2048
return memoryMapIdx ^ maxSubpageAllocs; // remove highest set bit, to get offset
}
上面根据不同的handle使用不同的初始化buffer的策略
- 大于pageSize返回的handle,是一个memoryMap数组的下标
- 小于pageSize返回的是handle,包含了bitmap和memoryMapIdx数组元素的下标信息
这里再说下bitmap是什么意思,由于一个PoolSubpage的大小默认是8k,如果要分割成更小的内存块需要使用一个标记来记录这个page划分成的内存块哪些已经使用,那些是可用的,io.netty.buffer.PoolSubpage#bitmap就是这个作用,PoolSubpage中相关的字段有
// 记录subpage分割后的内存块的使用情况,一个bit对应一个内存块
private final long[] bitmap;
PoolSubpage<T> prev;
PoolSubpage<T> next;
boolean doNotDestroy;
// 内存块的大小
int elemSize;
// 划分后的内存块的大小
private int maxNumElems;
// 实际使用到的bitmap数组的长度
private int bitmapLength;
// 下一个可用的内存块的位置
private int nextAvail;
private int numAvail;
allocateNormal终于申请到了内存,也初始化了buffer,但是这个方法不仅包含了分配normal内存的方法也包含了tiny和small内存的分配方法。
tiny内存分配
tiny内存分配流程:
-
如果申请的是tiny类型,会先从tiny缓存中尝试分配,如果缓存分配成功则返回
-
否则从tinySubpagePools中尝试分配
-
如果上面没有分配成功则使用allocateNormal进行分配
从缓存中分配
这里以启用了缓存为例来说明,使用到的缓存类是PoolThreadCache,缓存是通过队列实现的,一个队列中存储的内存大小都是相同的
// io.netty.buffer.PoolArena#allocate(io.netty.buffer.PoolThreadCache, io.netty.buffer.PooledByteBuf<T>, int)
// 这里的cache是PoolThreadCache
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
boolean allocateTiny(PoolArena<?> area, PooledByteBuf<?> buf, int reqCapacity, int normCapacity) {
// 缓存维护了一个队列,这个队列中存储的内存块大小都相同
// 找到缓存之后,从队列中取出一个内存块用来初始化buffer
return allocate(cacheForTiny(area, normCapacity), buf, reqCapacity);
}
// 查找缓存数组中缓存的内存
private MemoryRegionCache<?> cacheForTiny(PoolArena<?> area, int normCapacity) {
// 计算出申请内存位于缓存数组中的位置,即数组下标
int idx = PoolArena.tinyIdx(normCapacity);
if (area.isDirect()) {
// 使用直接内存的缓存
return cache(tinySubPageDirectCaches, idx);
}
// 使用堆内存的缓存
return cache(tinySubPageHeapCaches, idx);
}
static int tinyIdx(int normCapacity) {
// 由于tiny缓存数组大小是32,依次对应的内存大小是16、32...,512,所以数组的下标应该是申请内存的大小除以16
// normCapacity = normCapacity / 16
return normCapacity >>> 4;
}
从缓存中分配内存的过程
- 寻找缓存tinySubPageDirectCaches
- 使用缓存中的chunk初始化buf
关于tiny缓存的数据结构
// tiny缓存
// 是一个SubPageMemoryRegionCache数组,默认缓存数组长度:32,依次存储的内存大小是16、32、48...,512
io.netty.buffer.PoolThreadCache#tinySubPageHeapCaches
// 初始化tiny缓存数组,数组大小是32
// static final int numTinySubpagePools = 512 >>> 4;
tinySubPageHeapCaches = createSubPageCaches(
tinyCacheSize, PoolArena.numTinySubpagePools, SizeClass.Tiny);
// 初始化tiny和small缓存数组
private static <T> MemoryRegionCache<T>[] createSubPageCaches(
int cacheSize, int numCaches, SizeClass sizeClass) {
if (cacheSize > 0) {
@SuppressWarnings("unchecked")
MemoryRegionCache<T>[] cache = new MemoryRegionCache[numCaches];
for (int i = 0; i < cache.length; i++) {
// TODO: maybe use cacheSize / cache.length
cache[i] = new SubPageMemoryRegionCache<T>(cacheSize, sizeClass);
}
return cache;
} else {
return null;
}
}
缓存使用队列实现,一个队列最大元素个数
DEFAULT_TINY_CACHE_SIZE = SystemPropertyUtil.getInt("io.netty.allocator.tinyCacheSize", 512);
从tinySubpagePools中分配
上面缓存中如果没有分配到内存的话,会向内存池tinySubpagePools申请,主要逻辑是:
- 计算tinySubpagePools数组的index,右移4,除以16(该数组长度是512>>>4)
- 取出index出的subpage,也就是这个index处head
- 从head.next查找合适的内存
- 找到可用内存后使用io.netty.buffer.PoolChunk#initBufWithSubpage(io.netty.buffer.PooledByteBuf
, long, int)初始化buffer
前面已经介绍过tinySubpagePools,是一个数组,数组大小是32,每个元素是一个PoolSubpage,PoolSubpage本身是一个链表,所以要在这个里面查找可用内存,先要计算出数组下表,然后找到该位置的PoolSubpage,取出这个链表的头,然后分配内存。关键代码如下
// io.netty.buffer.PoolArena#allocate(io.netty.buffer.PoolThreadCache, io.netty.buffer.PooledByteBuf<T>, int)
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
final int normCapacity = normalizeCapacity(reqCapacity);
if (isTinyOrSmall(normCapacity)) { // capacity < pageSize
int tableIdx;
PoolSubpage<T>[] table;
boolean tiny = isTiny(normCapacity);
if (tiny) { // < 512
// 省略中间代码...
tableIdx = tinyIdx(normCapacity);
table = tinySubpagePools;
} else {
// 省略中间代码...
}
final PoolSubpage<T> head = table[tableIdx];
/**
* Synchronize on the head. This is needed as {@link PoolChunk#allocateSubpage(int)} and
* {@link PoolChunk#free(long)} may modify the doubly linked list as well.
*/
synchronized (head) {
final PoolSubpage<T> s = head.next;
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
long handle = s.allocate();
assert handle >= 0;
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
incTinySmallAllocation(tiny);
return;
}
}
// 省略中间代码...
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号