记录写sql的套路
(题目顺序不代表难度高低,只是按我记录的时间顺序)
同表同逻辑,不同区的union all改进
遇到聚合逻辑相同,对同一张表的不同分区聚合,可以考虑将行标号来进行分区
eg:最近n日新增用户统计,dwd_user_register_inc是用户域用户注册事务事实表,以`dt`作为分区字段
看到这个需求我的初步逻辑是将1d的聚合,7d的聚合,30d的聚合
--1d
select
1 as recent_days,
count(*) as count_register
from dwd_user_register_inc
where dt = '2020-06-14'
union all
--7d
select
7,
count(*)
from dwd_user_register_inc
where dt >= date_sub('2020-06-14',6)
union all
--30d
select
30,
count(*)
from dwd_user_register_inc
where dt >= date_sub('2020-06-14',29)但是明显这个sql聚合逻辑相同,可以简化
--将这张表原本的每一行数据扩展成三行,随后再对其用where来筛选达到相同标识为一整体的内容对应分区表的不容内容,最后用group by分组来实现分区的效果
select
recent_days,
count(*) count_register
from dwd_user_register_inc lateral view explode(`array`(1,7,30)) tmp as recent_days
where dt >= date_sub('2020-06-14',recent_days - 1)
group by recent_days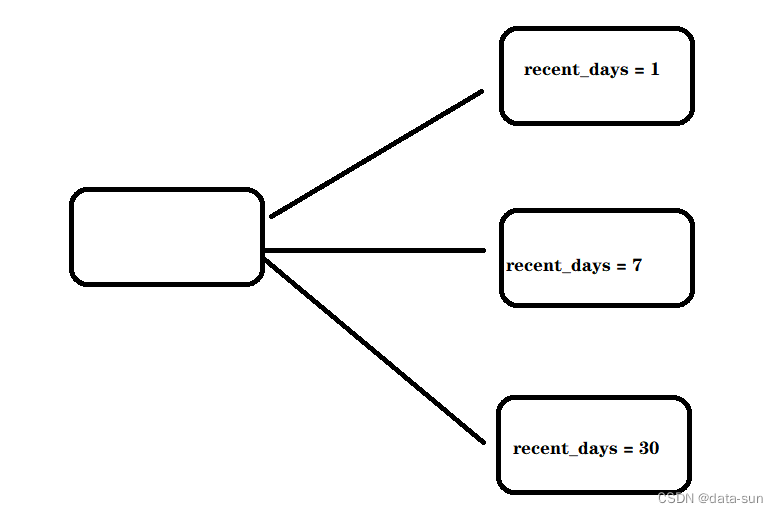
我用炸裂函数来将原有数据复制成三份(每一行数据都被炸裂函数炸成了三块),这三份的内容一样,但是recent_days这个标识不一样(如图所示,我只是按标识形象上划分成三块)
然后我用where来将这三份相同的内容变成不一样的内容(图中的同一组recent_days相同,所以where其实就是对这图中三个组来不同的筛选内容),对应不同的分区内容
最后group by来彻底分组以此达到不同组的聚合效果对应不同分区的聚合效果.
长表变为宽表
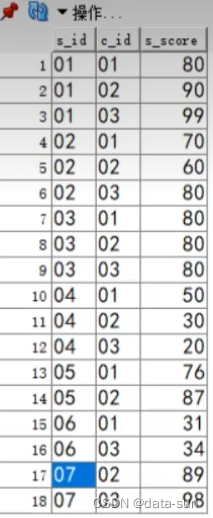

select
s_id,
max(case when c_id = '01' then s_score end) s01,
max(case when c_id = '02' then s_score end) s02
from score
group by s_id;
代替full join
由于mysql里没有full join,可以使用left join 和 right join之后union all的方式来代替
SELECT *
FROM table1
LEFT JOIN table2 ON table1.id = table2.id
UNION ALL
SELECT *
FROM table1
RIGHT JOIN table2 ON table1.id = table2.id;not exits 代替 not in
NOT EXISTS的性能不如NOT IN,开发中最好使用NOT EXISTS
#NOT IN
SELECT *
FROM orders
WHERE order_id NOT IN (SELECT order_id FROM cancelled_orders);#NOT EXISTS
SELECT *
FROM orders AS o
WHERE NOT EXISTS (
SELECT 1
FROM cancelled_orders AS c
WHERE o.order_id = c.order_id
);但是NOT EXISTS性能高于NOT IN是不一定的
当处理大型集合时,NOT IN可能会导致性能下降,因为它需要构建一个包含所有值的集合,然后执行比较。NOT EXISTS不需要构建这样的集合,因此在处理大型数据集时可能更有效。
对于小型数据集和特定情况,NOT IN可能与NOT EXISTS一样有效或更有效,因为数据库优化器可能会选择适当的执行计划
NOT EXISTS和NOT IN在语义上是有区别的。NOT EXISTS检查子查询是否为空,而NOT IN检查左侧集合中的值是否不在右侧集合中。这意味着如果右侧集合中有NULL值,NOT IN可能不会按预期工作,而NOT EXISTS通常会更可靠
举个例子说明NON IN 效率是有可能高于NOT EXISTS的
leetcode1965可以使用两种方法来测试效率
#这是使用NOT EXISTS
select employee_id
from (
select employee_id from employees
union
select employee_id from salaries
)tt
where not exists (
select 1
from (
select employees.employee_id
from employees
inner join salaries
on employees.employee_id = salaries.employee_id
)t
where tt.employee_id = t.employee_id
)
order by employee_id#这是使用NOT IN
select employee_id
from (
select employee_id from employees
union
select employee_id from salaries
)tt
where employee_id not in (
select employees.employee_id
from employees
inner join salaries
on employees.employee_id = salaries.employee_id
)
order by employee_idin是把外表和内表作hash连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询,一直以来认为exists比in效率高的说法是不准确的。
如果查询的两个表大小相当,那么用in和exists差别不大;如果两个表中一个较小一个较大,则子查询表大的用exists,子查询表小的用in;
用开窗解决全值后加聚合
注意mysql版本,8.0后才引入开窗函数
开窗函数:允许你在不破坏原表的基础上,加上一列聚合函数(不局限于聚合函数)
#笨办法
select a1.*,a2.avg_s
from
(select * from score)a1,
(select a.s_id,round(avg(s_score),2) avg_s from score a group by s_id)a2
where a1.s_id = a2.s_id
order by avg_s desc; #开窗
select a.*,avg(s_score) over (partition by a.s_id) as avg_s
from score非数值型统计
用sum(case when 条件 then 1 else 0)统计非数值型满足mou条件个数
eg:统计班级同学的及格率
select round(sum(case when s_score >= 60 then 1 else 0 end)/count(1),2) pass_rate
from course a
left join score b
left join a.s_id = b.s_id排名开窗函数的不同
-
ROW_NUMBER():无论是否有相同的比较值,它都会按顺序分配唯一的行号。如果有多个行具有相同的比较值,它们将分配不同的行号,每个行号都会递增。例如,如果有三个行具有相同的比较值,它们的行号将分别是 1、2 和 3。 -
RANK():当有相同的比较值时,RANK()会分配相同的排名,并在下一个值出现时跳过相同排名数量的值。例如,如果有三个行具有相同的比较值,并且在排名时分别获得第 1 名,那么下一个行将被分配第 4 名。这意味着在相同排名值之后会跳过排名。 -
DENSE_RANK():与RANK()不同,DENSE_RANK()也会分配相同的排名,但它不会跳过排名,而是继续分配下一个较低的排名。例如,如果有三个行具有相同的比较值,并且在排名时分别获得第 1 名,那么下一个行将被分配第 2 名,而不会跳过排名。
SELECT
salesperson_id,
sale_date,
sale_amount,
ROW_NUMBER() OVER (PARTITION BY salesperson_id ORDER BY sale_date) AS row_number,
RANK() OVER (PARTITION BY salesperson_id ORDER BY sale_amount DESC) AS rank,
DENSE_RANK() OVER (PARTITION BY salesperson_id ORDER BY sale_amount DESC) AS dense_rank
FROM
sales
ORDER BY
salesperson_id, sale_date;
#提供一个子查询实现同样效果
select a.*,(select count(s_score)
from score b
where a.c_id = b.c_id
and a.s_score < b.s_score)+1 as rk
from score a
order by c_id,s_score desc;日期时间的数字加减(interval)
SELECT NOW() + INTERVAL 1 DAY; -- 将当前日期时间增加一天
SELECT NOW() - INTERVAL 2 HOUR; -- 将当前日期时间减少两小时
SELECT DATE_ADD('2023-09-14', INTERVAL 3 MONTH); -- 在日期上添加3个月
SELECT DATE_SUB(NOW(), INTERVAL 1 WEEK); -- 从当前日期时间减去一周
SELECT NOW() + INTERVAL 2 YEAR; -- 增加两年
SELECT NOW() - INTERVAL 30 MINUTE; -- 减少30分钟
SELECT NOW() + INTERVAL 1 HOUR + 30 MINUTE; -- 增加1小时30分钟
#比较日期和时间,检查一个日期是否在另一个日期的一定时间间隔内
SELECT *
FROM events
WHERE event_date >= '2023-09-14'
AND event_date <= '2023-09-14' + INTERVAL 7 DAY;
补充小知识点
group by 1,2,3,4...默认是按照表的第一个,第二个,第三个,第四个字段....分组
year(日期时间) 函数返回年份
month(日期时间) 函数返回月份
day(日期时间) 函数返回天
now()返回当前日期时间
dayofyear(日期时间)返回日期对应年份的当年第几天
weekofyear(日期时间)返回日期对应年份的当年第几周
dateformat(日期时间,'格式')
%Y:四位年份(例如:2023)%y:两位年份(例如:23)%m:月份(01-12)%d:月中的天数(01-31)%H:小时(00-23)%h:小时(01-12,用于12小时制时钟)%i:分钟(00-59)%s:秒(00-59)%p:AM 或 PM(仅适用于12小时制时钟)%W:星期的完整名称(例如:Sunday)%w:星期的数字表示(0 = Sunday,1 = Monday,以此类推)%M:月份的完整名称(例如:January)%b:月份的缩写(例如:Jan)%c:月份的数字表示(1-12)%D:带有日序数后缀的月中的天数(例如:1st, 2nd, 3rd, 4th)
str_to_date('string类型的日期时间','格式')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号