
20180918-1 词频统计
作业要求参见[https://edu.cnblogs.com/campus/nenu/2018fall/homework/2126]
作业代码地址[https://coding.net/u/shishishaonian/p/word_count/git]
功能一:
需要正确区分单词,在控制台实现命令行输入,打开目标文件,对单词进行词频排序。用fopen函数去找目标路径的txt文件。区分单词我的想法是:单词只能由字母、"'"、"-"以及数字组成,并且数字不能在第一个位置上。部分代码如下:
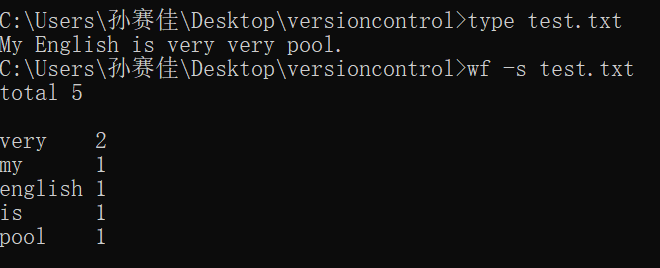
while(ch!=EOF){ //这儿我是认为单词只有字母、"'"、"-"以及数字组成,并且数字不能放在开头 //判断是不是组成单词的元素 if(isalpha(ch)!=0||(ch=='\''&&len>0)||ch=='-'||(ch>='0'&&ch<='9'&&len>0)){ //将大写字母转换为小写字母 if(ch>='A'&&ch<='Z'){ ch=ch-'A'+'a'; } //将符合条件的元素加入当前单词尾部 str+=ch; //单词长度+1; len++; //遇到空格之类字符,判断当前单词长度len是否大于零,若大于零,说明当前存有单词 }else if(len>0){ //如果当前单词出现次数为零 if(mp[str]==0){ //把新单词存入s中 s.push_back(str); //单词出现次数加一 mp[str]++; //词汇量加一 totalword++; //如果不是新单词,只需单词出现次数加一 }else{ mp[str]++; } //记录完单词后把str,len清空,进行下一轮的存储 str=""; len=0; } }
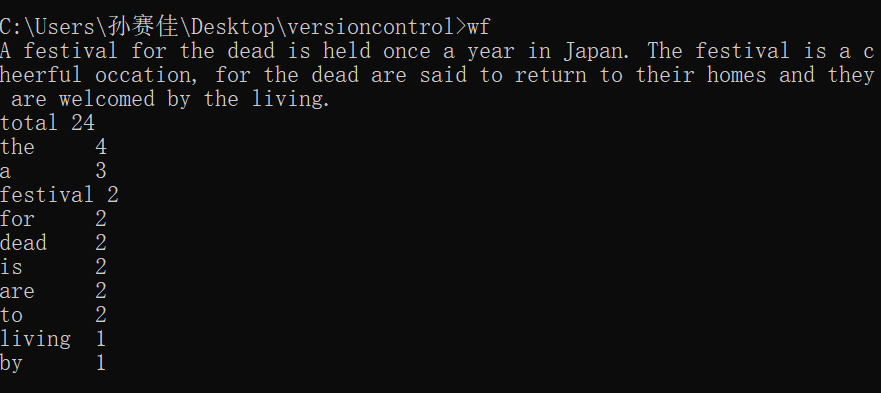
执行后效果如下图所示:
功能二和功能三和功能四:
关键在于要能区分输入的第二个参数是文件夹名还是文件名还是重定向。先判断argv[1]是不是"-s",是的话就是重定向。将重定向到"-s"里的文件输入到功能一里的函数即可进行输出。如果不是"-s",再利用判断文件夹路径是否存在来判断是文件名还是文件夹名 。如果是文件名就在末尾加上”.txt“,利用功能一的函数就能实现,如果是文件夹名就进入文件夹,遍历搜索所有txt文件。
这部分的代码如下:
if(argc==2){ //如果第二个参数是"-s",说明是重定向 if(strcmp(argv[1],"-s")==0){ char ch; int len=0; long totalword=0; string str=""; map<string,int>mp; vector<string>s; vector<pair<string,int> >pa; //将重定向的指定文本内容按序输入,直至为空 while((ch=getchar())!= EOF){ ... } ... }else{ //定义一个buf,用于记录当前路径 char buf[80]; //用getcwd获取当前路径并存入buf中 //记录当前路径的指针 char *myFileBasePath=getcwd(buf,sizeof(buf)); //将输入的文件名或文件夹名加入当前路径 strcat(buf,"\\"); strcat(buf,argv[1]); //判断是不是文件夹 int judgeDirResultCode=is_dir_exist(myFileBasePath); //如果是文件夹 if(judgeDirResultCode==0){ //搜索路径文件夹里的txt文档 ... } } //如果不是文件夹,按之前功能一的文件功能进行寻找 strcat(argv[1],".txt"); FILE *fp=NULL; fp=fopen(argv[1],"r"); //不是文件 if(fp==NULL){ printf("该文件/文件夹不存在!\n"); return 0; } else{ //是文件且存在 ... } }
执行效果如下:
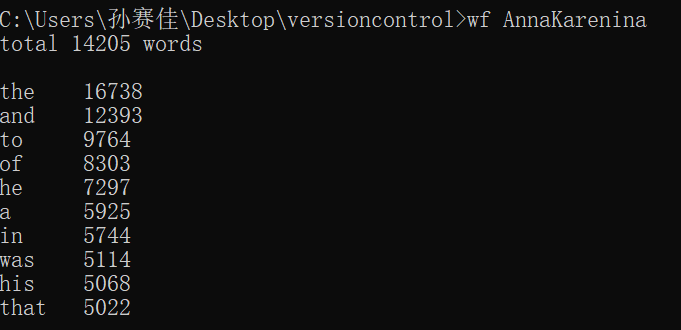
功能二:
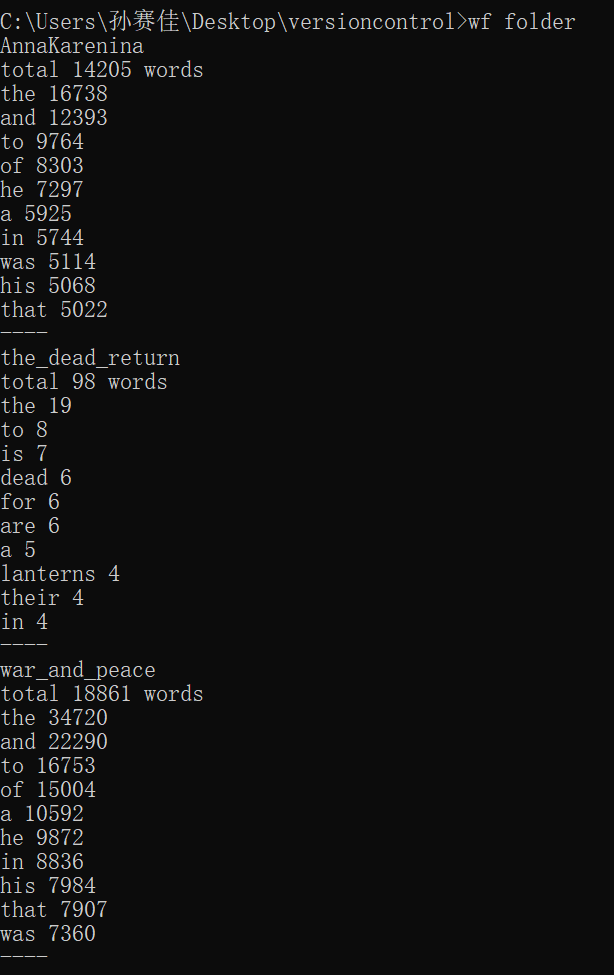
功能三:
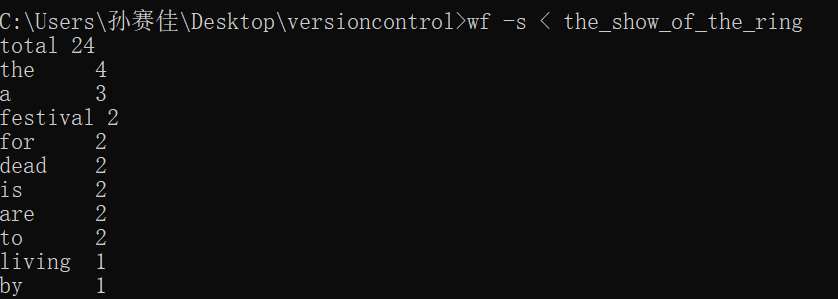
功能四:
PSP阶段表格:
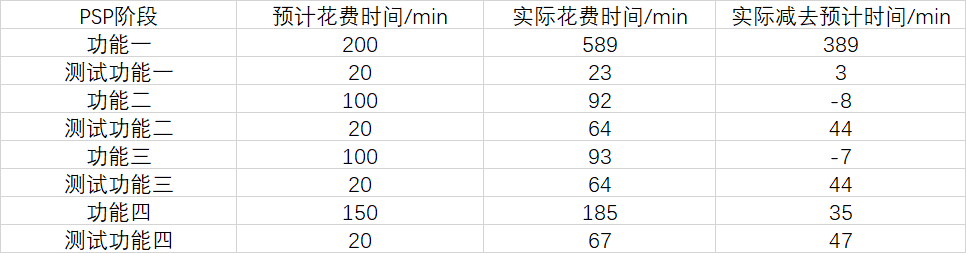
功能一是其他三个功能的基础,编写的时候也是在学习命令行操作,不会输入,也不会访问文件,频繁去查怎么实现这些功能,去理解特定函数的意思。所以功能一上花的时间是最多的。但是实现之后去测试运行花的时间是最少的,和预计的差不多。其他功能是在功能一基础上编写的,就比较快,但是在测试上就很花时间,一开始,我没注意到功能二和功能三之间要进行判断区分,测试的时候就花了大量时间去修改判断条件。功能四的重定向也查了好久资料,测试时还遇到了乱码,一步一步去找哪里出了问题,也比较花时间。

