商品搜索引擎---推荐系统设计
版权声明:本文为博主原创文章,转载注明出处 https://blog.csdn.net/u013142781/article/details/51119242
一、前言
结合目前已存在的商品推荐设计(如淘宝、京东等),推荐系统主要包含系统推荐和个性化推荐两个模块。
系统推荐: 根据大众行为的推荐引擎,对每个用户都给出同样的推荐,这些推荐可以是静态的由系统管理员人工设定的,或者基于系统所有用户的反馈统计计算出的当下比较流行的物品。
个性化推荐:对不同的用户,根据他们的口味和喜好给出更加精确的推荐,这时,系统需要了解需推荐内容和用户的特质,或者基于社会化网络,通过找到与当前用户相同喜好的用户,实现推荐。
下面具体介绍系统推荐和个性化推荐的设计方案。
二、系统推荐
2.1、系统推荐目的
针对所有用户推荐,当前比较流行的商品(必选) 或 促销实惠商品(可选) 或 新上市商品(可选),以促进商品的销售量。
PS:根据我们的应用情况考虑是否 选择推荐 促销实惠商品 和 新上市商品。(TODO1)
2.2、实现方式
实现方式包含:系统自动化推荐 和 人工设置推荐。
(1)系统自动化推荐考虑因素有:商品发布时间、商品分类、库存余量、历史被购买数量、历史被加入购物车数量、历史被浏览数量、降价幅度等。根据我们当前可用数据,再进一步确定(TODO2)
(2)人工设置:提供运营页面供运营人员设置,设置包含排行位置、开始时间和结束时间、推荐介绍等等。
由于系统推荐实现相对简单,因此不作过多的文字说明,下面详细介绍个性化推荐的设计。
三、个性化推荐
3.1、个性化推荐目的
对不同的用户,根据他们的口味和喜好给出更加精确的推荐,系统需要了解需推荐内容和用户的特质,或者基于社会化网络,通过找到与当前用户相同喜好的用户,实现推荐,以促进商品的销售量。
3.2、三种推荐模式的介绍
据推荐引擎的数据源有三种模式:基于人口统计学的推荐、基于内容的推荐、基于协同过滤的推荐。
(1)基于人口统计学的推荐:针对用户的“性别、年龄范围、收入情况、学历、专业、职业”进行推荐。
(2)基于内容的推荐:如下图,这里没有考虑人对物品的态度,仅仅是因为电影A月电影C相似,因此将电影C推荐给用户A。这是与后面讲到的协同过滤推荐最大的不同。
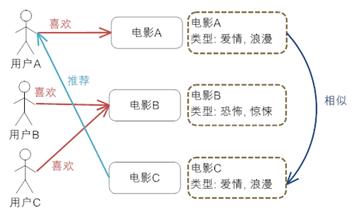
(3)基于协同过滤的推荐:如下图,这里我们并不知道物品A和物品D是否相似,仅仅考虑人对物品的喜好进行推荐。

模式采用:这三种模式可以单独使用,也可结合使用。结合我们实际情况,采用基于协同过滤的推荐更加合适,看后期情况是否结合另外两种模式实现推荐。但基于协同过滤的推荐这种模式,会引发“冷启动”问题。关于,冷启动问题,后续会讨论解决方案。
3.4、Mahout介绍
目前选择采用协同过滤框架Mahout进行实现。
Mahout 是一个很强大的数据挖掘工具,是一个分布式机器学习算法的集合,包括:被称为Taste的分布式协同过滤的实现、分类、聚类等。Mahout最大的优点就是基于hadoop实现,把很多以前运行于单机上的算法,转化为了MapReduce模式,这样大大提升了算法可处理的数据量和处理性能。
Mahout 是一个布式机器学习算法的集合,但是这里我们只使用到它的推荐/协同过滤算法。
3.5、Mahout实现协同过滤实例
协同过滤在mahout里是由一个叫taste的引擎提供的, 它提供两种模式,一种是以jar包形式嵌入到程序里在进程内运行,另外一种是MapReduce Job形式在hadoop上运行。这两种方式使用的算法是一样的,配置也类似。
这里我们采用第一种引入jar包的单机模式。
3.5.1、依赖

 浙公网安备 33010602011771号
浙公网安备 33010602011771号