
数据采集第二次作业
作业一:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
代码如下:
`
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers1.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table weathers ( wcount varchar(16),wCity varchar(16),wDate varchar(16),wWeather
varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
#self.con.close()
def insert(self,count, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers ( wcount,wCity,wDate,wWeather,wTemp) values (?,?,?,?,?)",( count,city, date,
weather, temp))
except Exception as err1:
print(err1,3)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-16s%-32s%-16s" % ("序号","地区", "日期", "天气", "温度"))
for row in rows:
print("%-16s%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3],row[4]))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"郑州": "101180101", "合肥": "101220101", "青岛": "101120201", "福州": "101230101"}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + " code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "html.parser")
lis = soup.select("ul[class='t clearfix'] li")
count=0
for li in lis:
try:
count+=1
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
self.db.insert(count,city, date, weather, temp)
except Exception as err2:
print(err2,1)
except Exception as err3:
print(err3,2)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
self.db.show()
self.db.closeDB()
ws=WeatherForecast()
ws.process(["郑州", "合肥", "青岛", "福州"])
`
结果:
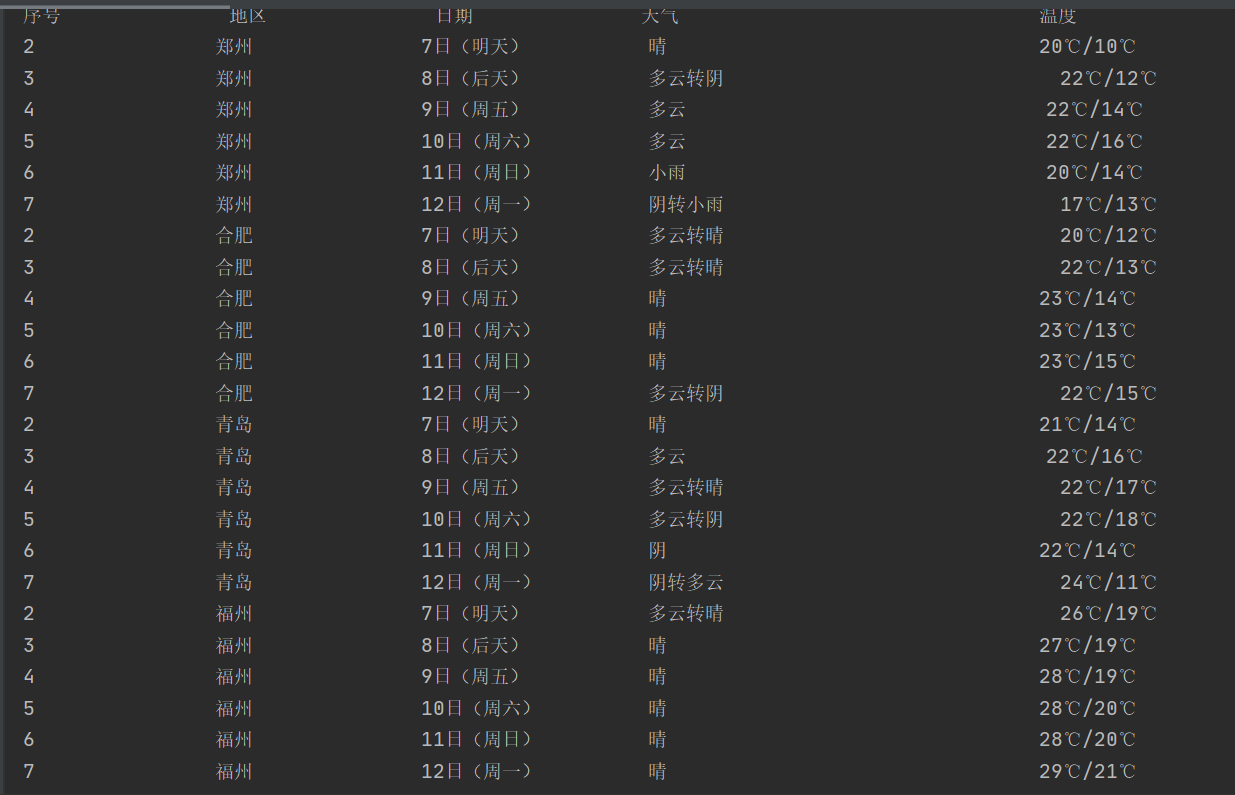
实验心得:这次作业书本上有差不多的例子,有了参照后就简单了很多,在课本的基础上这次输出了四个城市的天气,加深了对beautiful的理解与运用。
作业二:用requests和BeautifulSoup库方法定向爬取股票相关信息。
代码如下:
`
import re
import requests
def getHtml(fs, pn):
url = "http://58.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409968248217612661_1601548126340&pn=" + str(pn) + "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=" + fs + "&fields=f12,f14,f2,f3,f4,f5,f6,f7"
r = requests.get(url)
pat = '"diff":\[\{(.*?)\}\]'
data = re.compile(pat, re.S).findall(r.text)
return data
# 获取股票数据
print("序号\t代码\t名称\t最新价\t涨跌幅\t跌涨额\t成交量\t成交额\t涨幅")
def getOnePageStock(sort, fs, pn):
data = getHtml(fs, pn)
datas = data[0].split("},{")
for i in range(len(datas)):
line = datas[i].replace('"', "").split(",") # 去掉双引号并通过","切片
print(sort, line[6][4:], line[7][4:], line[0][3:], line[1][3:], line[2][3:], line[3][3:], line[4][3:], line[5][3:]) # 输出每行数据,数据可通过括号内部的数字加以调整。
sort += 1
return sort
def main():
sort = 1# 代码序号
pn = 1 #页数
fs = {
"沪深A股": "m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23",
"上证A股": "m:1+t:2,m:1+t:23",
"深证A股": "m:0+t:6,m:0+t:13,m:0+t:80",
"新股": "m:0+f:8,m:1+f:8",
"中小板": "m:0+t:13",
"创业板": "m:0+t:80",
"科技版": "m:1+t:23"
} # 设置爬取哪些股票
for i in fs.keys():
sort = getOnePageStock(sort, fs[i], pn)
main()
`
实验结果:
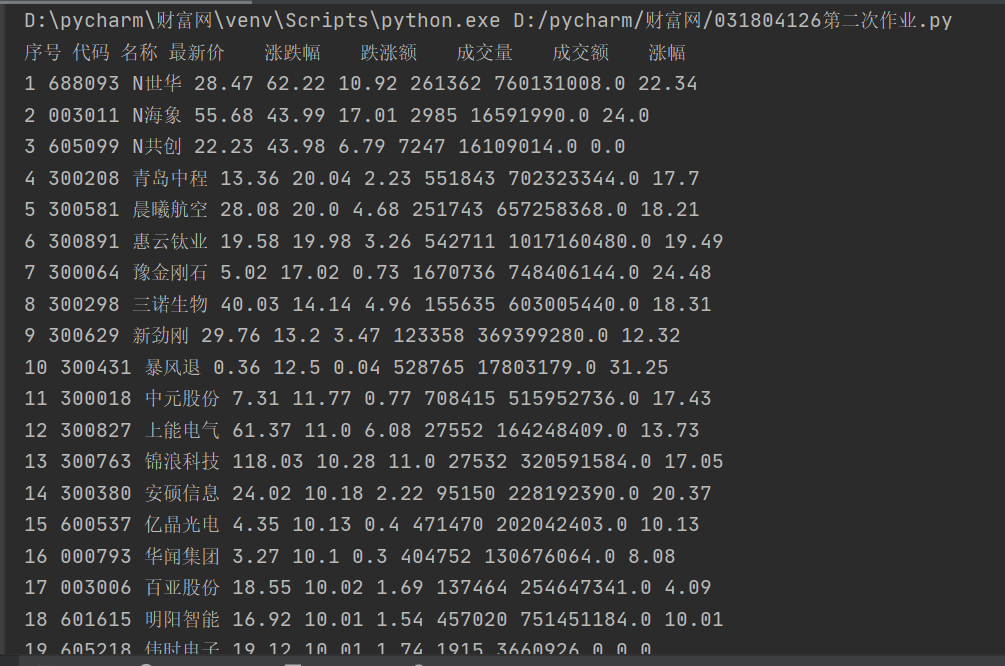
实验心得:
刚开始觉得这个作业跟第一次作业差不多,采用的还是原来爬取静态网页地方法,但是没有输出结果,结合老师给的参考链接,才发现这次是js爬取动态网页,由于要获取的数据是表格的形式,因此采用二维数组的方法输出,观察URL发现只要控制每页的标识变量pn可以实现翻页,通过fs变量可以控制不同的股票,这样一来,再加上参考链接,问题就简单了很多。
作业三:根据自选3位数+学号后3位选取股票,获取印股票信息。抓包方法同作②
代码如下:
`
import re
import requests
def getHtml(sort):
url = "http://push2.eastmoney.com/api/qt/stock/get? ut=fa5fd1943c7b386f172d6893dbfba10b&invt=2&fltt=2&fields=f44,f45,f46,f57,f58&secid=0."+sort+"&cb=jQuery112409396991179940428_1601692476366"
r = requests.get(url)
data = re.findall('{"f.*?}', r.text)
return data
# 获取股票数据
print("代码\t名称\t今日开\t今日最高\t今日最低")
def getOnePageStock(sort):
data = getHtml(sort)
datas = data[0].split("},{") #字符切片
for i in range(len(datas)):
line = datas[i].replace('"', "").split(",") # 去掉双引号并通过","切片
print(line[3][4:], line[4][4:8], line[2][4:], line[0][5:], line[1][4:]) # 按数组位置输出数据
def main():
sort = "300" + "126" # 输入选择的股票代码
try:
getOnePageStock(sort)
except:
print("该股票不存在!") # 不是每一个代码都有相对应的股票
main()
`
结果:

实验心得:
这次跟作业二内容相差不大,不同的是加入了筛选条件,筛出需要的股票序号,就不赘述了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号