
数据采集第一次作业
**作业一:爬取网站大学排名**
代码如下:
`
import requests
from bs4 import BeautifulSoup
import bs4
import urllib
from bs4 import UnicodeDammit
url ="http://www.shanghairanking.cn/rankings/bcur/2020"
try:
headers={"User-Agent":"Mozilla/5.0"}
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup = BeautifulSoup(data, "html.parser")
trs=soup.select("tbody tr") #仿照书上的数据处理过程
print("排名\t学校名称\t省市\t学校类型\t总分")
for tr in trs:#soup.find('tbody').children:
try:
rank = tr.select('td')[0].text.strip()
name = tr.select('td a')[0].text.strip()
address = tr.select('td')[2].text.strip()
kinds = tr.select('td')[3].text.strip()
grade = tr.select('td')[4].text.strip()
print(rank,name,address,kinds,grade)
except Exception as err:
print(err)
except Exception as err:
print(err)`
运行结果:
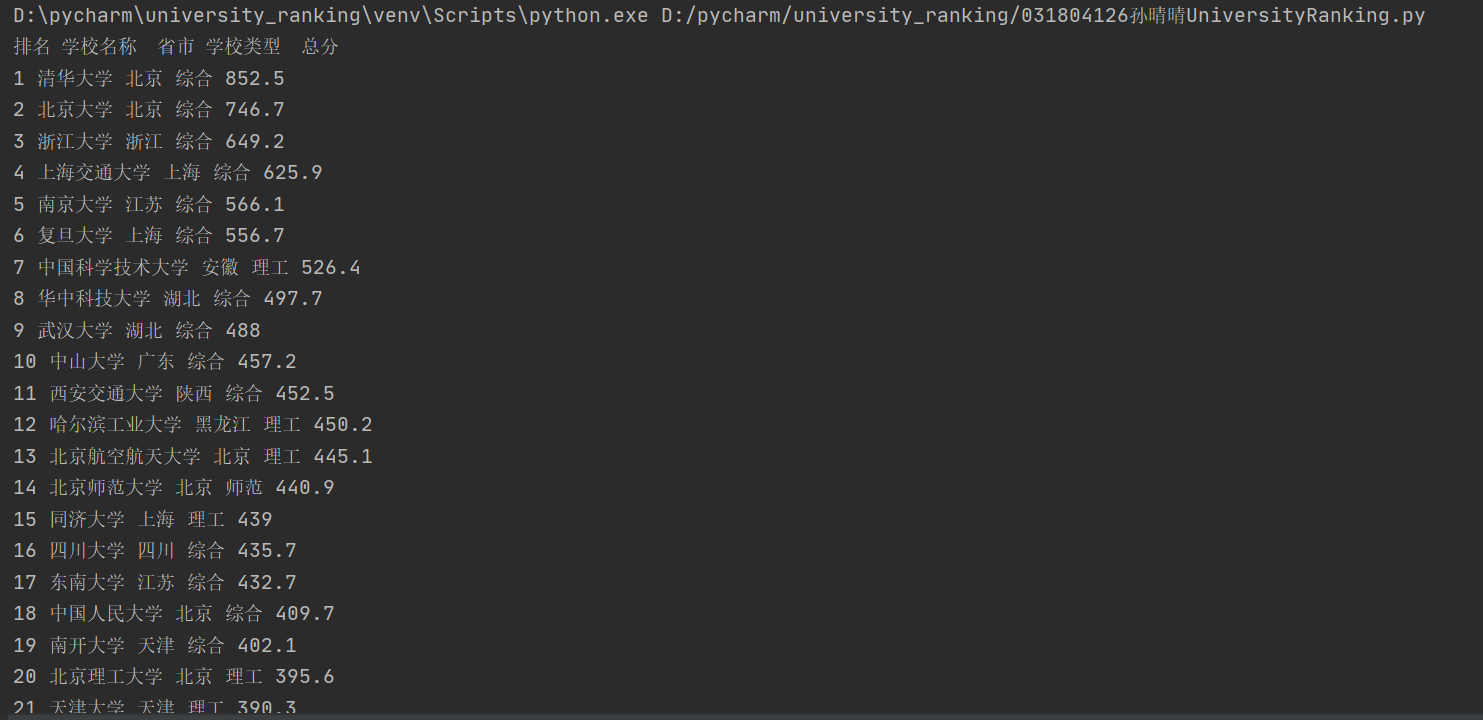
心得体会:刚开始拿到题目的时候有点无从下手,不过仔细研究了一下书上的例子,分析网站的源代码,照葫芦画瓢,到最后竟然写出来了。也遇到了很多问题,比如输出的格式不对,一行数据输出三行,看起来很不美观,经过查资料,运用strip函数解决。以后还是要多练习。
**作业二:爬取购物网站商品信息**
代码部分:
`
import requests
from bs4 import BeautifulSoup
import bs4
import urllib
from bs4 import UnicodeDammit
url ="https://search.jd.com/Search?keyword=%E6%B5%B7%E5%B0%94%E6%B4%97%E8%A1%A3%E6%9C%BA&enc=utf- 8&wq=%E6%B5%B7%E5%B0%94%E6%B4%97%E8%A1%A3%E6%9C%BA&pvid=e0045f183a7c4f358d3d45f2e8f56eae"
try:
headers={"User-Agent":"Mozilla/5.0"}
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup = BeautifulSoup(data, "html.parser")
print("序号\t商品名\t价格")
lis=soup.select("ul[class='gl-warp clearfix'] li")
i=0
for li in lis:
i=i+1
if i<=50: #商品太多,选了前五十个
try:
names=li.select('div[class="p-name p-name-type-2"] em')[0].text.strip()
prices=li.select('div[class="p-price"] i')[0].text.strip()
print(i,names,prices)
except Exception as err:
print(err)
except Exception as err:
print(err)
`
运行结果:
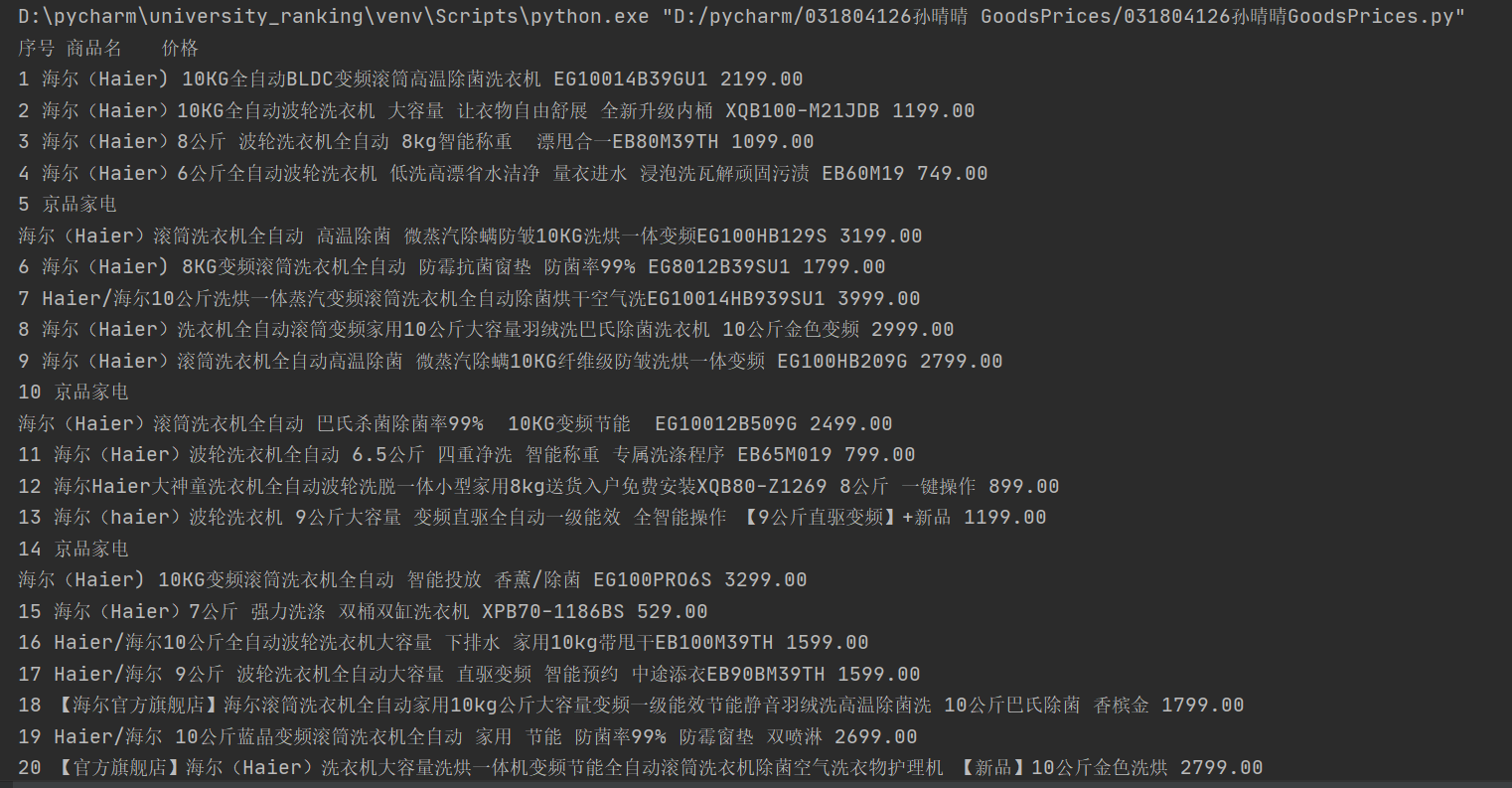
心得体会:
淘宝有反爬系统,这里爬取了京东的商品页,爬取了海尔洗衣机的前50个商品。这道题跟第一题很类似,但是刚开始的时候出现了商品名称数组越界的情况,应该是商品页的介绍过于冗杂所致,换了个商品就成功实现了。
**作业三:爬取某网站的所有JPG形式图片**
代码部分:
`
import requests
import re
import os
class GetImage(object):
def __init__(self,url):
self.url = url
self.headers = { 'User-Agent': 'Mozilla/5.0'}
self.path = 'D:\pycharm\pictures'
def download(self,url):
try:
res = requests.get(url,headers=self.headers)
return res
except Exception as E:
print(url+'下载失败,原因:'+E)
def parse(self,res):
content = res.content.decode()
# print(content)
img_list = re.findall(r'<img.*?src="(.*?)"',content,re.S)#正则表达式的运用,通过img标签的src属性筛选
img_list = ['http://xcb.fzu.edu.cn/'+url for url in img_list]
return img_list
def save(self,res_img,file_name):
if res_img:
with open(file_name,'wb') as f:
f.write(res_img.content)
print(url+'下载成功')
def run(self):
# 下载
res = self.download(self.url)
# 解析
url_list = self.parse(res)
# 下载图片
for url in url_list:
res_img = self.download(url)
name = url.strip().split('/').pop()
file_name = self.path+'/'+name
# 保存
self.save(res_img,file_name)
if __name__ == '__main__':
url_list = ['http://xcb.fzu.edu.cn/']
for url in url_list:
text = GetImage(url)
text.run()
`
运行结果:
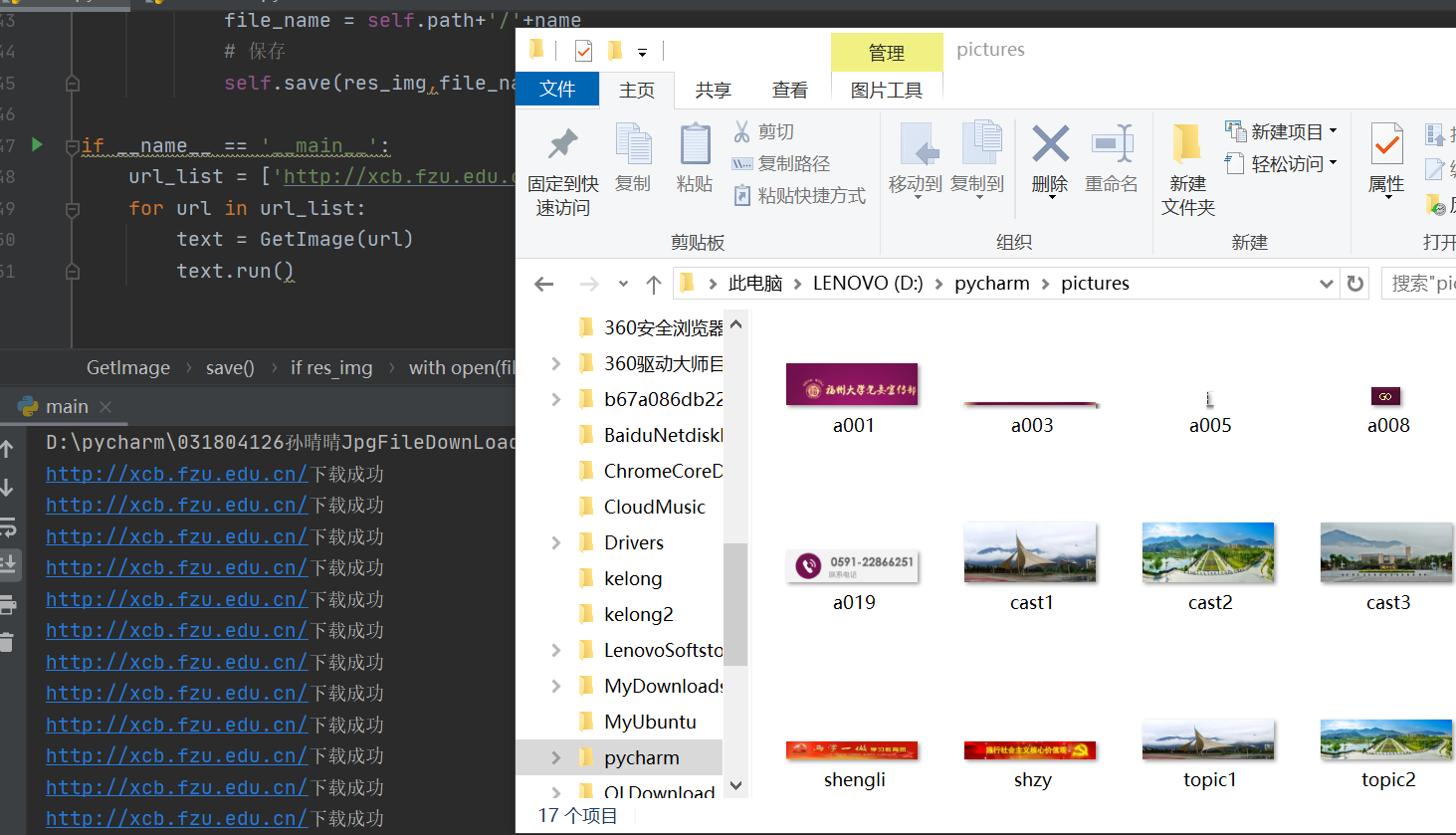
心得体会:这个虽然跟前两次作业还是有有相似之处的,新加入了正则表达式的内容,主要是筛选JPG图片,通过正则表达式运用img标签的src属性,做完之后感觉还是很有意思的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号