Phoenix |安装配置| 命令行操作| 与hbase的映射| spark对其读写
Phoenix
Phoenix是HBase的开源SQL皮肤。可以使用标准JDBC API代替HBase客户端API来创建表,插入数据和查询HBase数据。
1.特点
1) 容易集成:如Spark,Hive,Pig,Flume和Map Reduce。
2) 性能好:直接使用HBase API以及协处理器和自定义过滤器,可以为小型查询提供毫秒级的性能,或者为数千万行提供数秒的性能。
3) 操作简单:DML命令以及通过DDL命令创建表和版本化增量更改。
4) 安全功能: 支持GRANT和REVOKE 。
5) 完美支持Hbase二级索引创建。
架构:

作用:

2. Phoenix安装部署
CDH集成phoenix https://my.oschina.net/hblt147/blog/3016196
官方网址: http://phoenix.apache.org/index.html
https://archive.apache.org/dist/phoenix/?C=M;O=A
下载与HBase版本兼容的Phoenix
下载地址:http://archive.apache.org/dist/phoenix/
上传jar包到/opt/software/
解压到/opt/module 改名为phoenix
[kris@hadoop101 module]$ tar -zxvf /opt/software/apache-phoenix-4.14.1-HBase-1.3-bin.tar.gz -C /opt/module [kris@hadoop101 module]$ mv apache-phoenix-4.14.1-HBase-1.3-bin phoenix
复制server和client这俩个包拷贝到各个节点的hbase/lib
在phoenix目录下
[kris@hadoop101 module]$ cd /opt/module/phoenix/
向每个节点发送server jar
[kris@hadoop101 phoenix]$ cp phoenix-4.14.1-HBase-1.3-server.jar /opt/module/hbase-1.3.1/lib/ [kris@hadoop101 phoenix]$ scp phoenix-4.14.1-HBase-1.3-server.jar hadoop102:/opt/module/hbase-1.3.1/lib/ [kris@hadoop101 phoenix]$ scp phoenix-4.14.1-HBase-1.3-server.jar hadoop103:/opt/module/hbase-1.3.1/lib/
向每个节点发送client jar
[kris@hadoop101 phoenix]$ cp phoenix-4.14.1-HBase-1.3-client.jar /opt/module/hbase-1.3.1/lib/ [kris@hadoop101 phoenix]$ scp phoenix-4.14.1-HBase-1.3-client.jar hadoop102:/opt/module/hbase-1.3.1/lib/ [kris@hadoop101 phoenix]$ scp phoenix-4.14.1-HBase-1.3-client.jar hadoop103:/opt/module/hbase-1.3.1/lib/
在root权限下给/etc/profile 下添加如下内容
#phoenix export PHOENIX_HOME=/opt/module/phoenix export PHOENIX_CLASSPATH=$PHOENIX_HOME export PATH=$PATH:$PHOENIX_HOME/bin
开启schema对应namespace
http://phoenix.apache.org/namspace_mapping.html
在Phoenix中是没有Database的概念的,所有的表都在同一个命名空间。当然,Phoenix4.8开始支持多个命名空间了,如果要用自定义的namespace,Phoenix中与之对应的是schema的概念,但是默认是关闭的,需要单独配置。
- 在
hbase/conf/hbase-site.xml、phoenix/bin/hbase-site.xml两个文件中增加以下代码:

<property> <name>phoenix.schema.isNamespaceMappingEnabled</name> <value>true</value> </property> <property> <name>phoenix.schema.mapSystemTablesToNamespace</name> <value>true</value> </property>
2. 如果HBase是分布式,则需要将文件分发到其他节点
(最好是将该文件也复制到phoenix/bin/保证客户端与服务端的一致性)
3. Phoenix其他相关配置参照:https://phoenix.apache.org/tuning.html
重启HBase,重新连接
stop-hbase.sh start-hbase.sh
启动Zookeeper,Hadoop,Hbase(bin/start-hbase.sh)
启动Phoenix
./sqlline.py hadoop101:2181
[kris@hadoop101 module]$ cd phoenix/ [kris@hadoop101 phoenix]$ bin/sqlline.py hadoop101,hadoop102,hadoop103:2181
Setting property: [incremental, false] Setting property: [isolation, TRANSACTION_READ_COMMITTED] issuing: !connect jdbc:phoenix:hadoop101,hadoop102,hadoop103:2181 none none org.apache.phoenix.jdbc.PhoenixDriver Connecting to jdbc:phoenix:hadoop101,hadoop102,hadoop103:2181 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/phoenix/phoenix-4.14.1-HBase-1.3-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. 19/07/12 23:57:53 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Connected to: Phoenix (version 4.14) Driver: PhoenixEmbeddedDriver (version 4.14) Autocommit status: true Transaction isolation: TRANSACTION_READ_COMMITTED Building list of tables and columns for tab-completion (set fastconnect to true to skip)... 133/133 (100%) Done Done sqlline version 1.2.0 0: jdbc:phoenix:hadoop101,hadoop102,hadoop103>
3. 基本操作(常用命令)
----HBase是大小写敏感,Phoenix操作时需要添加双引号,如果不添加双引号的话会统一转换成大写
//显示所有表:
!table 或者 !tables
//列出所有列
$sqlline> !columns test.stu
//创建schema(相当于数据库)
$sqlline> create schema test;
use test;
//删除表结构
$sqlline> drop table stu;
//创建表
create table stu(id integer primary key ,name varchar,age integer);
//创建表并指定列族
create table stu2(id integer primary key ,"cf1".name varchar,"cf1".age integer) ;
//插入数据和更新数据
在Phoenix中是没有Insert语句的,取而代之的是Upsert语句。Upsert有两种用法,分别是:UPSERT INTO和 UPSERT SELECT
UPSERT INTO类似于insert into的语句,旨在单条插入外部数据
UPSERT SELECT类似于Hive中的insert select语句,旨在批量插入其他表的数据。
UPSERT INTO stu (id,name,age) SELECT id,name,age FROM sty2 WHERE id < 400;
upsert into stu2 values(1,'tom',12);
upsert into stu(id,name,age) values(1,'alex',22);
注意:在phoenix中插入语句并不会像传统数据库一样存在重复数据。因为Phoenix是构建在HBase之上的,也就是必须存在一个主键。
由于HBase的主键设计,相同rowkey的内容可以直接覆盖,这就变相的更新了数据。
//删除数据
$sqlline> delete from stu where id = 1 ;
DELETE FROM stu;
//删除表 删除表和其他的数据库类似。不同的是可以加上CASCADE关键字,用于删除表的同时删除基于该表的所有视图。
DROP TABLE my_schema.my_table;DROP TABLE my_schema.my_table CASCADE;
//条件查询
Phoenix作为SQL On HBase引擎必不可少的就是SQL查询语句了,他能兼容大部分的SQL查询语句,比如UNION ALL GROUP BY ORDER BY LIMIT
$sqlline> select * from stu where name like 'a%' ;
创建视图

CREATE VIEW test_view AS SELECT * FROM test where description in ('S1','S2','S3') 除此之外,我们还能在视图上创建视图 CREATE VIEW test_view1 AS SELECT * FROM test_view where description != 'S1'; //视图没办法只获取一部分数据的数据的,只能select *
删除视图:
DROP VIEW my_view DROP VIEW IF EXISTS my_schema.my_view DROP VIEW IF EXISTS my_schema.my_view CASCADE
创建表:
CREATE TABLE IF NOT EXISTS us_population ( State CHAR(2) NOT NULL, City VARCHAR NOT NULL, Population BIGINT CONSTRAINT my_pk PRIMARY KEY (state, city));
在phoenix中,默认情况下,表名等会自动转换为大写,若要小写,使用双引号,如"us_population"。
插入记录: upsert into us_population values('NY','NewYork',8143197); 查询记录: 0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> select * from us_population; +--------+----------+-------------+ | STATE | CITY | POPULATION | +--------+----------+-------------+ | NY | NewYork | 8142197 | +--------+----------+-------------+ 1 row selected (0.083 seconds) 0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> select * from us_population where state='NY'; +--------+----------+-------------+ | STATE | CITY | POPULATION | +--------+----------+-------------+ | NY | NewYork | 8142197 | +--------+----------+-------------+ 删除记录 delete from us_population wherestate='NY'; 删除表 drop table us_population; 退出命令行 !quit
0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> !describe test +------------+--------------+-------------+--------------+------------+------------+--------------+----------------+-+ | TABLE_CAT | TABLE_SCHEM | TABLE_NAME | COLUMN_NAME | DATA_TYPE | TYPE_NAME | COLUMN_SIZE | BUFFER_LENGTH | | +------------+--------------+-------------+--------------+------------+------------+--------------+----------------+-+ +------------+--------------+-------------+--------------+------------+------------+--------------+----------------+-+
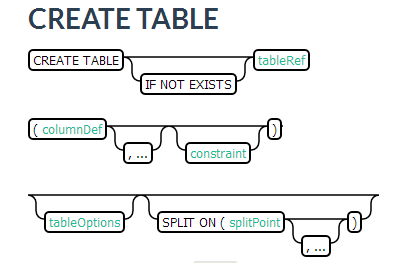
Phoenix建表的时候可以定义表的属性(包括了HBase的一些属性)以及预分区操作。
我们进入到tableOption下面可以看到SALT_BUCKETS, DISABLE_WAL, IMMUTABLE_ROWS, MULTI_TENANT, DEFAULT_COLUMN_FAMILY, STORE_NULLS, TRANSACTIONAL, and UPDATE_CACHE_FREQUENCY这些属性
①SALT_BUCKETS(加盐?)
Salting能够通过预分区(pre-splitting)数据到多个region中来显著提升读写性能。
Salting 翻译成中文是加盐的意思,本质是在hbase中,rowkey的byte数组的第一个字节位置设定一个系统生成的byte值,这个byte值是由主键生成rowkey的byte数组做一个哈希算法,计算得来的。Salting之后可以把数据分布到不同的region上,这样有利于phoenix并发的读写操作。关于SaltedTable的说明在 http://phoenix.apache.org/salted.html
CREATE TABLE test (host VARCHAR NOT NULL PRIMARY KEY, description VARCHAR) SALT_BUCKETS=16;
SALT_BUCKETS的值范围在(1 ~ 256);
salted table可以自动在每一个rowkey前面加上一个字节,这样对于一段连续的rowkeys,它们在表中实际存储时,就被自动地分布到不同的region中去了。当指定要读写该段区间内的数据时,也就避免了读写操作都集中在同一个region上。
简而言之,如果我们用Phoenix创建了一个saltedtable,那么向该表中写入数据时,原始的rowkey的前面会被自动地加上一个byte(不同的rowkey会被分配不同的byte),使得连续的rowkeys也能被均匀地分布到多个regions。 在每条rowkey前面加了一个Byte,这里显示为了16进制。也正是因为添加了一个Byte,所以SALT_BUCKETS的值范围在必须再1 ~ 256之间
在使用SALT_BUCKETS的时候需要注意以下两点:
-
创建salted table后,应该使用Phoenix SQL来读写数据,而不要混合使用Phoenix SQL和HBase API
-
如果通过Phoenix创建了一个salted table,那么只有通过Phoenix SQL插入数据才能使得被插入的原始rowkey前面被自动加上一个byte,通过HBase shell插入数据无法prefix原始的rowkey
2 Pre-split(预分区)
Salting能够自动的设置表预分区,但是你得去控制表是如何分区的,所以在建phoenix表时,可以精确的指定要根据什么值来做预分区,比如:
CREATE TABLE test (host VARCHAR NOT NULL PRIMARY KEY, description VARCHAR) SPLIT ON (1,2,3);
3 使用多列族
列族包含相关的数据都在独立的文件中,在Phoenix设置多个列族可以提高查询性能。例如:
CREATE TABLE test (key VARCHAR NOT NULL PRIMARY KEY, cf1.name VARCHAR,cf1.age VARCHAR, cf2.score VARCHAR);
4 使用压缩
在数据量大的表上使用压缩算法来提高性能。
CREATE TABLE test (host VARCHAR NOT NULL PRIMARY KEY, description VARCHAR) COMPRESSION='Snappy';; //在hbase中查看详情: describe 'TEST:TEST'
4. phoenix表映射
Phoenix和Hbase表的关系
默认情况下,直接在hbase中创建的表,通过phoenix是查看不到的。如图1和图2,US_POPULATION是在phoenix中直接创建的,而kylin相关表是在hbase中直接创建的,在phoenix中是查看不到kylin等表的。
hbase命令行中查看所有表:
[kris@hadoop101 bin]$ hbase shell
hbase(main):001:0> list
phoenix命令行中查看所有表: 0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> !tables
如果要在phoenix中操作直接在hbase中创建的表,则需要在phoenix中进行表的映射。
映射方式有两种:视图映射和表映射
Hbase命令行中创建表test
Hbase 中test的表结构如下,两个列簇name、company.
[kris@hadoop101 bin]$ hbase shell hbase(main):002:0> create 'test','name','company' 0 row(s) in 1.3380 seconds
映射方式一:视图映射
Phoenix创建的视图是只读的,所以只能用来做查询,无法通过视图对源数据进行修改等操作。
在phoenix中创建视图test 表
0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> create view "test"(empid varchar primary key,"name"."firstname" varchar,"name"."lastname" varchar,"company"."name" varchar,"company"."address" varchar);
0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> select * from "test"; +--------+------------+-----------+-------+----------+ | EMPID | firstname | lastname | name | address | +--------+------------+-----------+-------+----------+ +--------+------------+-----------+-------+----------+
删除视图
0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> drop view "test";
映射方式二: 表映射
使用Apache Phoenix创建对HBase的表映射,有两种方法:
1) 当HBase中已经存在表时,可以以类似创建视图的方式创建关联表,只需要将create view改为create table即可。
0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> create table "test"(empid varchar primary key,"name"."firstname" varchar,"name"."lastname" varchar,"company"."name" varchar,"company"."address" varchar);
2) 当HBase中不存在表时,可以直接使用create table指令创建需要的表,系统将会自动在Phoenix和HBase中创建person_infomation的表,并会根据指令内的参数对表结构进行初始化。
0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> create table "test"(empid varchar primary key,"name"."firstname" varchar,"name"."lastname" varchar,"company"."name" varchar,"company"."address" varchar);
注意:
设置schema的时候注意加上双引号,不然的话phoenix会默认大写,导致找不到指定的表
CDH的Phoenix不支持这样创建表
CREATE TABLE MY_SCHEMA.MYTABLE (k BIGINT PRIMARY KEY, v VARCHAR);
若想在某个SCHEMA下创建表,需先使用USE SCHEMA语句切换到该SCHEMA下,再执行建表语句。
phoenix中自增id
# 1、创建一个自增序列seq,缓存大小设置为10 $sqlline> create sequence seq cache 10; # 查看序列详情 $sqlline> select * from system."SEQUENCE"; +------------+------------------+-------------------------------------+-------------+----------------+---------------+--------------+ | TENANT_ID | SEQUENCE_SCHEMA | SEQUENCE_NAME | START_WITH | CURRENT_VALUE | INCREMENT_BY | CACHE_SIZE | +------------+------------------+-------------------------------------+-------------+----------------+---------------+--------------+ | | TEST | SEQ | 1 | 1 | 1 | 10 | +------------+------------------+-------------------------------------+-------------+----------------+---------------+--------------+ upsert into stu values(next value for seq,'aa',20); //id从1开始,若之前有数据会被覆盖掉; //id超过10还会自增,但是若断开连接!quit,重新连接会导致自增id不连续;查看当前自增序列状态,发现当前值CURRENT_VALUE已经改变
5. 使用spark对phoenix的读写
http://phoenix.apache.org/phoenix_spark.html
写:
准备IDEA环境:
依赖:


<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.1.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.1.1</version> </dependency> <dependency> <groupId>org.apache.phoenix</groupId> <artifactId>phoenix-core</artifactId> <version>4.14.0-HBase-1.3</version> </dependency> <dependency> <groupId>org.apache.phoenix</groupId> <artifactId>phoenix-spark</artifactId> <version>4.14.0-HBase-1.3</version> </dependency>
hbase-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- /** * * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ --> <configuration> <property> <name>hbase.rootdir</name> <value>hdfs://hadoop101:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 0.98后的新变动,之前版本没有.port,默认端口为60000(可省略) --> <property> <name>hbase.master.port</name> <value>16000</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>hadoop101,hadoop102,hadoop103</value> </property> <!-- 参照zk的zoo.cfg文件中的dataDir值 --> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/opt/module/zookeeper-3.4.10/zkData</value> </property> <!-- phoenix regionserver 配置参数 --> <property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value> </property> <property> <name>hbase.region.server.rpc.scheduler.factory.class</name> <value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value> <description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description> </property> <property> <name>hbase.rpc.controllerfactory.class</name> <value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value> <description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description> </property> <!-- phoenix master 配置参数 --> <property> <name>hbase.master.loadbalancer.class</name> <value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value> </property> <property> <name>hbase.coprocessor.master.classes</name> <value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value> </property> <property> <name>phoenix.schema.isNamespaceMappingEnabled</name> <value>true</value> </property> <property> <name>phoenix.schema.mapSystemTablesToNamespace</name> <value>true</value> </property> </configuration>
读:
方式一:
object TestSparkPhoenix { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().master("local[*]").appName("phoenix-test").getOrCreate() var df = spark.read.format("org.apache.phoenix.spark").option("table", "fruits").option("zkUrl", "hadoop101,hadoop102,hadoop103:2181").load() /* df = df.filter("name not like 'hig%'") .filter("password like '%0%'")*/ df.show() } }
方式二:
package com.easylife.phoenix import org.apache.hadoop.conf.Configuration import org.apache.spark.sql.{DataFrame, SparkSession} //否则编辑器识别不出语法,也不会自动import。 import org.apache.phoenix.spark._ object TestSparkPhoenix { def main(args: Array[String]): Unit = { //读 val spark = SparkSession.builder().master("local[*]").appName("phoenix-test").getOrCreate() val configuration = new Configuration() configuration.set("hbase.zookeeper.quorum","hadoop101,hadoop102,hadoop103:2181") val df1: DataFrame = spark.sqlContext.phoenixTableAsDataFrame("fruits",Array("id", "info.name"), conf = configuration ) df1.show() } }
使用Zookeeper URL创建RDD
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} //否则编辑器识别不出语法,也不会自动import。 import org.apache.phoenix.spark._ //使用Zookeeper URL创建RDD val sparkConf = new SparkConf().setAppName("phoenix-test").setMaster("local[*]") val sc = new SparkContext(sparkConf) val fruitRDD: RDD[Map[String, AnyRef]] = sc.phoenixTableAsRDD("fruits",Array("id", "name"), zkUrl = Some("hadoop101,hadoop102,hadoop103")) println(fruitRDD.count()) sc.stop() } }
写:
不加"", Phoenix中会自动转换为大写;
方式一: 保存RDD到Phoenix
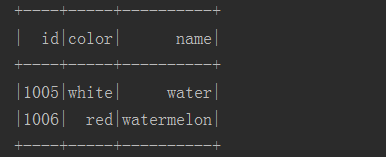
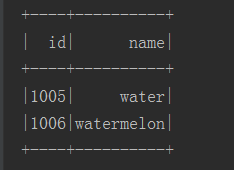
//先在Phoenix中创建表 create table fruits( "id" varchar primary key, "info"."color" varchar, "info"."name" varchar );
import org.apache.spark.SparkContext //否则编辑器识别不出语法,也不会自动import。 import org.apache.phoenix.spark._ object TestSparkPhoenix { def main(args: Array[String]): Unit = { val sc: SparkContext = new SparkContext("local", "phoenix-test") val dateSet = List(("1005", "white", "water"), ("1006", "red", "watermelon")) sc.parallelize(dateSet) .saveToPhoenix("fruits", Seq("id", "color","name"), zkUrl = Some("hadoop101,hadoop102,hadoop103:2181")) } }
在Phoenix中查看数据, 通过Spark操作Phoenix是需要区分大小写的。这点非常重要

在Hbase中查看数据
scan "FRUITS"
使用RDD的saveToPhoenix函数时必须严格按照Phoenix的Column名的大小写来输入:查看源码得
def saveToPhoenix(tableName: String, cols: Seq[String], conf: Configuration = new Configuration, zkUrl: Option[String] = None, tenantId: Option[String] = None) : Unit = { // Create a configuration object to use for saving @transient val outConfig = ConfigurationUtil.getOutputConfiguration(tableName, cols, zkUrl, tenantId, Some(conf))
RDD保存时直接将存入的column数组传进来, Phoenix的API将Column原原本本作为输出的Column名,所以使用RDD的saveToPhoenix函数时必须严格按照Phoenix的Column名的大小写来输入。
方式二: 使用DataFrame保存到phoenix
//创建表:
CREATE TABLE STUDENT (ID INTEGER NOT NULL PRIMARY KEY, "cf1".name VARCHAR, "cf1".age INTEGER, "cf1".score DOUBLE); import org.apache.hadoop.conf.Configuration import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession} //否则编辑器识别不出语法,也不会自动import。 import org.apache.phoenix.spark._ object TestSparkPhoenix { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().master("local[*]").appName("phoenix-test").getOrCreate() val dataSet = List(Student(1,"kris",18,95),Student(2,"smile",19,80),Student(3,"alice",19,100)) val df = spark.sqlContext.createDataFrame(dataSet) df.write .format("org.apache.phoenix.spark") .mode(SaveMode.Overwrite) .options(Map("table" -> "STUDENT", "zkUrl" -> "hadoop101,hadoop102,hadoop103:2181")) .save() } } case class Student(ID:Int, Name:String,Age: Int,Score:Double) 0: jdbc:phoenix:hadoop101:2181> select * from student; +-----+--------+------+--------+ | ID | NAME | AGE | SCORE | +-----+--------+------+--------+ | 1 | kris | 18 | 95.0 | | 2 | smile | 19 | 80.0 | | 3 | alice | 19 | 100.0 | +-----+--------+------+--------+
这种方式借助了org.apache.phoenix.spark里面的隐式函数
DataFrame保存时的列信息经过SchemaUtil.normalizeIdentifier(x)转化, 仅仅只是将字符串里面的引号去掉,然后转成大写。
不管我们的DataFrame的列是什么格式,最终都会转成大写。
然后Phoenix里面的列可能不是大写的,所以就可能出现列名是对的,但是大小写对应不上。
结论:
-
在使用RDD保存数据到Phoenix的时候,要严格按照Phoenix列名的大小写来输入
-
使用DataFrame保存的时候,对数据源的列名大小写无要求。但是必须保证Phoenix的表列名必须是大写的
-
HBase建表的时候,我们建议您对表名和列都使用大写
-
使用Phoenix创建表的时候,除非是已经存在了HBase的表,否则无需要建表的时候对列带引号,这样sql中即使是小写的列也会保存为大写,比如:
--创建的Phoenix表名必须和HBase表名一致 CREATE TABLE STUDENT3 ( --这句话直接写就可以了,这样的话,HBase中的RowKey转换成phoenix中的主键,列名就叫自取。 --rowkey自动会和primary key进行对应。 ID VARCHAR NOT NULL PRIMARY KEY , --将名为cf1的列族下,字段名为name的字段,写在这里。 cf1.name VARCHAR , --下面就以此类推 cf1.age VARCHAR , cf2.score VARCHAR )
phoenixTableAsDataFrame()是org.apache.phoenix.spark.SparkSqlContextFunctions中的方法,saveToPhoenix()是org.apache.phoenix.spark.DataFrameFunctions中的方法,在phoenix-spark-4.10.0-HBase-1.2.jar中。使用这两个方法时必须 import org.apache.phoenix.spark._,否则编辑器识别不出语法,也不会自动import。
通过Phoenix取数据和直接通过Hbase代码取数据性能
同样的逻辑,最开始使用Scan的时候只有50000 requests/secend,两者性能差别非常大。
以前从HBase需要4个小时才能拿完的数据,现在只需要一个小时了.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号