Linux调Bug
[kris@hadoop101 ~]$ xcall.sh ps -ef | grep zookeeper | grep -v grep | wc -l 3 [kris@hadoop101 ~]$ xcall.sh ps -ef | grep zookeeper | grep -v grep | sort -nrk2 | head -n 1 | awk {'print $2'} 3148 [kris@hadoop101 ~]$ xcall.sh ps -ef | grep zookeeper | grep -v grep | sort -nrk2 | head -n 3 | awk {'print $2'} | xargs kill -9
生产环境服务器变慢了,诊断思路和性能评估谈谈?
整机:top ;
CPU:vmstat;
内存:free;
硬盘:df;
磁盘:iostat;
网络:ifstat;
①top

top [kris@hadoop101 ~]$ top top - 00:59:49 up 6 min, 2 users, load average: 0.05, 0.20, 0.13 //load average系统的负载均衡,分别代表系统的1min、5min、15min系统的平均负载值 Tasks: 231 total, 2 running, 229 sleeping, 0 stopped, 0 zombie //(0.05+0.20+0.13)/3*100% 如果> 60% 则表示系统的负担压力过重; Cpu(s): 0.7%us, 2.2%sy, 0.0%ni, 97.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 4040608k total, 967588k used, 3073020k free, 22048k buffers Swap: 2097148k total, 0k used, 2097148k free, 200996k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND //看CPU和内存 3291 kris 20 0 3700m 56m 11m S 13.0 1.4 0:04.29 java 3001 kris 20 0 99.7m 1956 952 R 10.0 0.0 0:02.12 sshd 35 root 20 0 0 0 0 S 1.0 0.0 0:00.25 events/0 1 root 20 0 19344 1544 1232 S 0.0 0.0 0:02.00 init 2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd 不停的按1: 可以查看那个CPU慢,慢在哪 top - 01:05:02 up 12 min, 2 users, load average: 0.30, 0.14, 0.13 Tasks: 231 total, 1 running, 230 sleeping, 0 stopped, 0 zombie Cpu0 : 2.3%us, 9.7%sy, 0.0%ni, 87.3%id, 0.0%wa, 0.3%hi, 0.3%si, 0.0%st Cpu1 : 1.7%us, 0.3%sy, 0.0%ni, 98.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu2 : 1.7%us, 1.0%sy, 0.0%ni, 97.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu3 : 2.0%us, 0.0%sy, 0.0%ni, 98.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu4 : 4.7%us, 7.4%sy, 0.0%ni, 88.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu5 : 1.7%us, 0.0%sy, 0.0%ni, 98.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu6 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu7 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 4040608k total, 960612k used, 3079996k free, 22120k buffers Swap: 2097148k total, 0k used, 2097148k free, 201116k cached [kris@hadoop101 ~]$ uptime ##Top简洁版 01:06:45 up 13 min, 2 users, load average: 0.08, 0.12, 0.12
②CPU
[kris@hadoop101 ~]$ vmstat -n 2 3 //查看总的进程、内存、交换空间、IO、系统、CPU;头procs尾cpu比较重要 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 3062044 23008 201156 0 0 19 1 139 407 0 1 98 0 0 0 0 0 3061904 23008 201160 0 0 0 0 2357 10885 1 2 97 0 0 2 0 0 3061904 23008 201160 0 0 0 8 2498 8112 1 2 98 0 0 r--runtime运行,b--blocking阻塞 cpu 看 us用户 sy系统 id是CPU空闲率 每2s采样一次 [kris@hadoop101 ~]$ mpstat -P ALL 2 Linux 2.6.32-642.el6.x86_64 (hadoop101) 2019年05月03日 _x86_64_ (8 CPU) 01时22分54秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle 01时22分56秒 all 1.31 0.00 2.94 0.00 0.19 0.12 0.00 0.00 95.44 01时22分56秒 0 2.48 0.00 11.88 0.00 1.49 0.50 0.00 0.00 83.66 01时22分56秒 1 0.50 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.50 01时22分56秒 2 0.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 99.01 01时22分56秒 3 7.07 0.00 11.11 0.00 0.00 0.00 0.00 0.00 81.82 01时22分56秒 4 0.50 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.50 01时22分56秒 5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 01时22分56秒 6 0.50 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.50 01时22分56秒 7 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 01时22分56秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle 01时22分58秒 all 2.19 0.00 2.51 0.00 0.00 0.00 0.00 0.00 95.30 01时22分58秒 0 3.02 0.00 11.56 0.00 0.00 0.00 0.00 0.00 85.43 01时22分58秒 1 1.49 0.00 0.50 0.00 0.00 0.00 0.00 0.00 98.01 01时22分58秒 2 1.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.99 01时22分58秒 3 6.03 0.00 8.54 0.00 0.00 0.00 0.00 0.00 85.43 01时22分58秒 4 2.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 97.50 01时22分58秒 5 2.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 97.99 01时22分58秒 6 1.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.99 01时22分58秒 7 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 [kris@hadoop101 ~]$ ps -ef | grep java kris 3440 3002 20 01:23 pts/1 00:00:01 java JavaDemo kris 3461 3003 1 01:24 pts/0 00:00:00 grep java [kris@hadoop101 ~]$ pidstat -u 1 -p 3440 Linux 2.6.32-642.el6.x86_64 (hadoop101) 2019年05月03日 _x86_64_ (8 CPU) 01时25分04秒 PID %usr %system %guest %CPU CPU Command 01时25分05秒 3440 2.97 7.92 0.00 10.89 5 java 01时25分06秒 3440 4.00 5.00 0.00 9.00 5 java 01时25分07秒 3440 28.00 10.00 0.00 38.00 5 java 01时25分08秒 3440 4.00 9.00 0.00 13.00 5 java 01时25分09秒 3440 5.00 8.00 0.00 13.00 5 java 01时25分10秒 3440 15.00 7.00 0.00 22.00 5 java 01时25分11秒 3440 6.00 9.00 0.00 15.00 5 java 01时25分11秒 PID %usr %system %guest %CPU CPU Command 01时25分12秒 3440 5.00 8.00 0.00 13.00 5 java 01时25分13秒 3440 4.00 8.00 0.00 12.00 5 java 01时25分14秒 3440 19.00 10.00 0.00 29.00 5 java 01时25分15秒 3440 5.00 8.00 0.00 13.00 5 java
vmstat工具 的使用是通过两个数字参数来完成,第一个参数是采样的时间间隔单位是秒,第二个参数是采样的次数;
- procs r:运行和等待CPU时间片的进程数,原则上1核的CPU的运行队列不要超过2,整个系统的运行队列不能超过总核数的2倍,否则代表系统压力过大;
b:等待资源的进程数,比如正在等待磁盘I/O、网络I/O等;
-CPU
us:用户进程消耗CPU时间百分比,us值高,用户进程消耗CPU时间多,如果长期大于50%,优化程序;
sy:内核进程消耗的CPU时间百分比;
us + sy参考值为80%,如果us + sy大于80%,说明可能存在CPU不足。
id:处于空闲的CPU百分比;
wa:系统等待IO的CPU时间百分比;
st:来自于一个虚拟机偷取的CPU时间的百分比;
查看额外:
查看所有cpu核信息:mpstat -P ALL 2
每个进程使用cpu的用量分解信息:pidstat -u 1 -p 进程编号
③内存
##应用程序可用内存free
[kris@hadoop101 ~]$ free -m total used free shared buffers cached Mem: 3945 902 3043 1 22 196 -/+ buffers/cache: 682 3263 Swap: 2047 0 2047 [kris@hadoop101 ~]$ free -g //给四舍五入了,一般用-m total used free shared buffers cached Mem: 3 0 2 0 0 0 -/+ buffers/cache: 0 3 Swap: 1 0 1
经验值:
应用程序可用内存/ 系统物理内存 > 70%内存充足;
应用程序可用内存/ 系统物理内存 < 20% 内存不足,需要增加内存;
20% < 应用程序可用内存/ 系统物理内存 < 70% 内存基本够用;
##查看额外:pidstat -p 进程号 -r 采样间隔秒数
[kris@hadoop101 ~]$ pidstat -p 3467 -r 2 Linux 2.6.32-642.el6.x86_64 (hadoop101) 2019年05月03日 _x86_64_ (8 CPU) 01时31分17秒 PID minflt/s majflt/s VSZ RSS %MEM Command 01时31分19秒 3467 2.50 0.00 3788816 59624 1.48 java 01时31分21秒 3467 0.00 0.00 3788816 59624 1.48 java 01时31分23秒 3467 1.50 0.00 3788816 59624 1.48 java 01时31分25秒 3467 1.50 0.00 3788816 59624 1.48 java 01时31分27秒 3467 0.00 0.00 3788816 59624 1.48 java 01时31分29秒 3467 2.50 0.00 3788816 59624 1.48 java 01时31分31秒 3467 0.50 0.00 3788816 59624 1.48 java 01时31分33秒 3467 0.00 0.00 3788816 59624 1.48 java
④硬盘
##查看磁盘剩余空间数
[kris@hadoop101 ~]$ df -h Filesystem Size Used Avail Use% Mounted on /dev/sda3 47G 16G 29G 36% / tmpfs 2.0G 72K 2.0G 1% /dev/shm /dev/sda1 190M 39M 142M 22% /boot
⑤磁盘IO iostat
磁盘块设备分布:
rkB/ s每秒读取数据量KB; wKB/s每秒写入数据量KB;
svctm I/O请求的平均服务时间,单位毫秒;
await I/O请求的平均等待时间,单位毫秒,值越小,性能越好;
util 一秒中有百分几的时间用于I/O操作。接近100%时,表示磁盘宽带跑满,需要优化程序或者增加磁盘;
rKB/s、wKB/s根据系统应用不同会有不同的值,但有规律遵循:长期、超大数据读写,肯定不正常,需要优化程序读取。
svctm的值与await的值很接近,表示几乎没有I/O等待,磁盘性能好,如果await的值远高于svctm的值,则表示I/O队列等待太长,需要优化程序或者更换更快的磁盘。
###磁盘I/O性能评估
[kris@hadoop101 ~]$ iostat -xdk 2 3 Linux 2.6.32-642.el6.x86_64 (hadoop101) 2019年05月03日 _x86_64_ (8 CPU) Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util scd0 0.00 0.00 0.02 0.00 0.06 0.00 8.00 0.00 0.91 0.91 0.00 0.91 0.00 sda 1.62 0.86 2.48 0.49 79.98 5.42 57.53 0.07 23.82 8.62 100.49 5.36 1.59 Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sda 0.00 4.00 0.50 2.50 4.00 26.00 20.00 0.03 8.33 15.00 7.00 4.83 1.45 Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
######查看额外:pidstat -d 采样间隔秒数 -p 进程号 [kris@hadoop101 ~]$ pidstat -d 2 -p 3505 Linux 2.6.32-642.el6.x86_64 (hadoop101) 2019年05月03日 _x86_64_ (8 CPU) 01时42分27秒 PID kB_rd/s kB_wr/s kB_ccwr/s Command 01时42分29秒 3505 0.00 0.00 0.00 java 01时42分31秒 3505 0.00 0.00 0.00 java 01时42分33秒 3505 0.00 0.00 0.00 java 01时42分35秒 3505 0.00 0.00 0.00 java 01时42分37秒 3505 0.00 0.00 0.00 java 01时42分39秒 3505 0.00 0.00 0.00 java
⑥网络ifstat
默认本地没有,下载ifstat wget http://gael.roualland.free.fr/ifstat/ifstat-1.1.tat.gz tat xzvf ifstat-1.1.tar.gz cd ifstat-1.1 ./configure make make install
[root@hadoop101 kris]# yum install -y gcc cc wget http://gael.roualland.free.fr/ifstat/ifstat-1.1.tar.gz [root@hadoop101 kris]# cd ifstat-1.1 [root@hadoop101 ifstat-1.1]# ./configure loading cache ./config.cache checking for a BSD compatible install... /usr/bin/install -c checking for gcc... gcc checking whether the C compiler (gcc ) works... yes checking whether the C compiler (gcc ) is a cross-compiler... no checking whether we are using GNU C... yes checking whether gcc accepts -g... yes checking for ranlib... ranlib checking how to run the C preprocessor... gcc -E checking for ANSI C header files... yes checking for sys/time.h... yes checking whether time.h and sys/time.h may both be included... yes checking for unistd.h... yes checking for ctype.h... yes ... [root@hadoop101 ifstat-1.1]# make gcc -I. -g -O2 -DHAVE_CONFIG_H -c ifstat.c -o ifstat.o gcc -I. -g -O2 -DHAVE_CONFIG_H -c drivers.c -o drivers.o gcc -I. -g -O2 -DHAVE_CONFIG_H -c data.c -o data.o gcc ifstat.o drivers.o data.o -o ifstat [root@hadoop101 ifstat-1.1]# make install /usr/bin/install -c -d -m 755 /usr/local/bin /usr/bin/install -c -s -m 755 ifstat /usr/local/bin/ifstat /usr/bin/install -c -d -m 755 /usr/local/man/man1 /usr/bin/install -c -m 644 ifstat.1 /usr/local/man/man1/ifstat.1
[kris@hadoop101 ~]$ ifstat 2 eth0 KB/s in KB/s out 18.16 830.89 19.19 850.78 17.71 827.96 20.00 888.12 19.19 841.46 18.20 828.43 18.96 842.16 19.93 853.10 19.21 825.14 18.73 844.84 16.89 811.36 20.12 864.89
各个网卡的in、out,观察网络负载情况,程序网络读写是否正常,
-程序网络I/O优化
-增加网络I/O宽带
假设生产环境CPU占用过高,请谈谈你的分析思路和定位?
结合Linux和JDK命令一块分析:
①先用top命令找出CPU占比最高的:
[kris@hadoop101 ~]$ top top - 10:04:29 up 41 min, 2 users, load average: 0.52, 0.38, 0.20 Tasks: 231 total, 1 running, 230 sleeping, 0 stopped, 0 zombie Cpu(s): 1.6%us, 2.4%sy, 0.0%ni, 95.9%id, 0.0%wa, 0.1%hi, 0.0%si, 0.0%st Mem: 4040608k total, 1246924k used, 2793684k free, 27676k buffers Swap: 2097148k total, 0k used, 2097148k free, 417016k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 4031 kris 20 0 3700m 94m 11m S 82.3 2.4 1:15.88 java 3050 kris 20 0 99.7m 1852 864 S 11.6 0.0 0:45.41 sshd 35 root 20 0 0 0 0 S 1.0 0.0 0:04.50 events/0 36 root 20 0 0 0 0 S 0.3 0.0 0:00.33 events/1 1 root 20 0 19344 1548 1232 S 0.0 0.0 0:01.93 init
②ps -ef 或者jps进一步定位,得知是一个怎么样的一个后台程序给我们惹的事
[kris@hadoop101 ~]$ jps -l 4076 sun.tools.jps.Jps 4031 JavaDemo [kris@hadoop101 ~]$ ps -ef | grep java | grep -v grep kris 4031 3051 19 09:57 pts/1 00:01:41 java JavaDemo
③定位到具体线程或者代码 ps -mp 进程 -o THREAD,tid,time
-m显示所有的线程; -p pid进程使用cpu的时间; -o该参数后是用户自定义格式
[kris@hadoop101 ~]$ ps -mp 4031 -o THREAD,tid,time USER %CPU PRI SCNT WCHAN USER SYSTEM TID TIME kris 19.2 - - - - - - 00:02:09 kris 0.0 19 - futex_ - - 4031 00:00:00 kris 15.1 19 - - - - 4032 00:01:41 kris 0.4 19 - futex_ - - 4033 00:00:03 kris 0.4 19 - futex_ - - 4034 00:00:03
④将需要的线程ID转换成16进制格式(英文小写格式)
4302----16进制---->> FC0---fc0
printf "%x\n" 有问题的线程ID
⑤jstack进程ID | grep tid(16进制线程ID小写英文)-A60
[kris@hadoop101 ~]$ jstack 4031 | grep fc0 -A60 "main" #1 prio=5 os_prio=0 tid=0x00007faac0008800 nid=0xfc0 runnable [0x00007faac474a000] java.lang.Thread.State: RUNNABLE at java.io.FileOutputStream.writeBytes(Native Method) at java.io.FileOutputStream.write(FileOutputStream.java:326) at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82) at java.io.BufferedOutputStream.flush(BufferedOutputStream.java:140) - locked <0x00000000c240ac80> (a java.io.BufferedOutputStream) at java.io.PrintStream.write(PrintStream.java:482) - locked <0x00000000c240a230> (a java.io.PrintStream) at sun.nio.cs.StreamEncoder.writeBytes(StreamEncoder.java:221) at sun.nio.cs.StreamEncoder.implFlushBuffer(StreamEncoder.java:291) at sun.nio.cs.StreamEncoder.flushBuffer(StreamEncoder.java:104) - locked <0x00000000c240a1e8> (a java.io.OutputStreamWriter) at java.io.OutputStreamWriter.flushBuffer(OutputStreamWriter.java:185) at java.io.PrintStream.newLine(PrintStream.java:546) - eliminated <0x00000000c240a230> (a java.io.PrintStream) at java.io.PrintStream.println(PrintStream.java:737) - locked <0x00000000c240a230> (a java.io.PrintStream) at JavaDemo.main(JavaDemo.java:4) //第4行 "VM Thread" os_prio=0 tid=0x00007faac007f000 nid=0xfc9 runnable "GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007faac001d800 nid=0xfc1 runnable "GC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007faac001f800 nid=0xfc2 runnable "GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007faac0021000 nid=0xfc3 runnable "GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007faac0023000 nid=0xfc4 runnable "GC task thread#4 (ParallelGC)" os_prio=0 tid=0x00007faac0025000 nid=0xfc5 runnable "GC task thread#5 (ParallelGC)" os_prio=0 tid=0x00007faac0026800 nid=0xfc6 runnable "GC task thread#6 (ParallelGC)" os_prio=0 tid=0x00007faac0028800 nid=0xfc7 runnable "GC task thread#7 (ParallelGC)" os_prio=0 tid=0x00007faac002a800 nid=0xfc8 runnable "VM Periodic Task Thread" os_prio=0 tid=0x00007faac00d5000 nid=0xfd2 waiting on condition JNI global references: 9
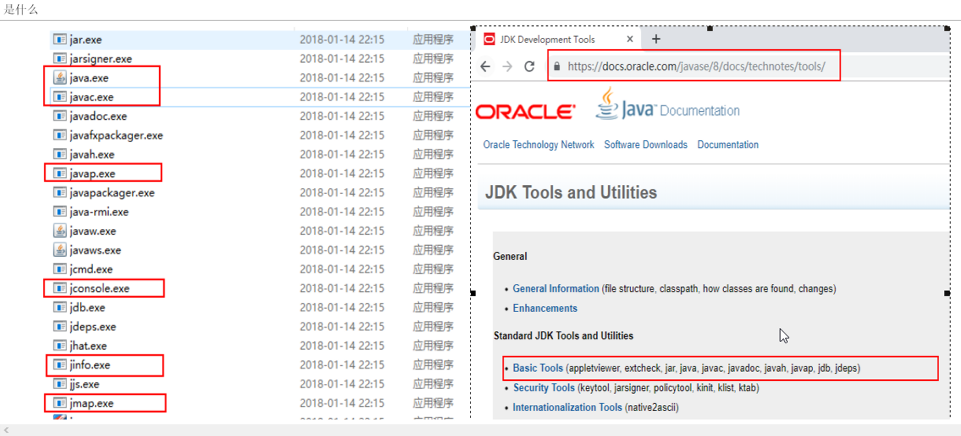
对于JDK自带的JVM监控和性能分析工具用过哪些?一般你是怎么用的? :是什么;性能监控工具
jps(虚拟机进程状况工具)
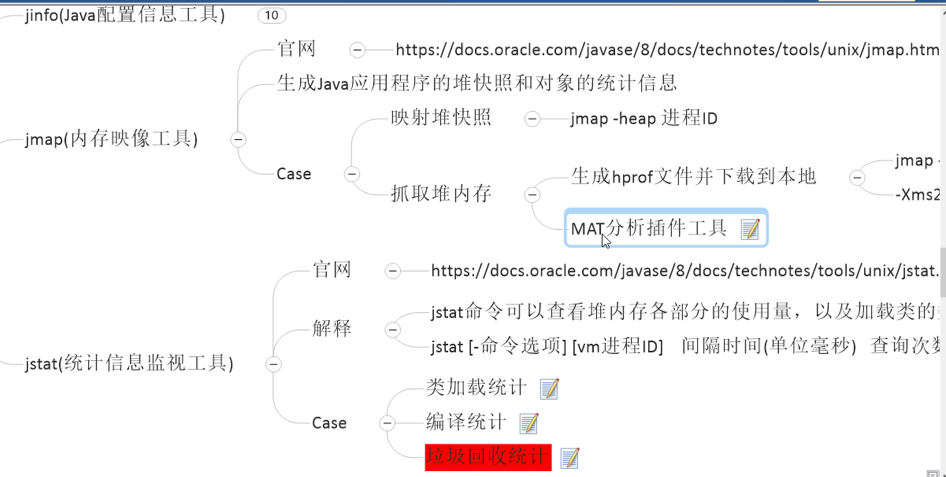
jinfo(java配置信息工具)
jmap(内存映像工具):
官网
生成java应用程序的堆快照和对象的统计信息、
Case:映射--jmap -heap 进程ID 和 抓取堆内存生成hprof文件并下载到本地、MAT分析插件工具;
https://docs.oracle.com/javase/8/doc/technotes/tools/unix/jmap.html
一般出故障了,你如何调试+排查+检索
检索:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号